为什么程序中突然多了 200 个 Dubbo-thread 线程的说明
背景
在某次查看程序线程堆栈信息时,偶然发现有 200 个 Dubbo-thread 线程,而且大部分都处于 WAITING 状态,如下所示:
"Dubbo-thread-200" #160932 daemon prio=5 os_prio=0 tid=0x00007f5af9b54800 nid=0x79a6 waiting on condition [0x00007f5a9acd5000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000000c78f1240> (a java.util.concurrent.SynchronousQueue$TransferStack) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.SynchronousQueue$TransferStack.awaitFulfill(SynchronousQueue.java:458) at java.util.concurrent.SynchronousQueue$TransferStack.transfer(SynchronousQueue.java:362) at java.util.concurrent.SynchronousQueue.take(SynchronousQueue.java:924) at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Locked ownable synchronizers: - None
为什么会有这么多 Dubbo-thread 线程呢?这些线程有什么作用呢?带着疑问就去研究了下源码。
源码分析
Dubbo (2.7.5 版本)的线程池 ThreadPool 有四种具体的实现类型:
fixed=org.apache.dubbo.common.threadpool.support.fixed.FixedThreadPool cached=org.apache.dubbo.common.threadpool.support.cached.CachedThreadPool limited=org.apache.dubbo.common.threadpool.support.limited.LimitedThreadPool eager=org.apache.dubbo.common.threadpool.support.eager.EagerThreadPool
程序通过调用具体实现类的 getExecutor(URL url) 方法来创建线程池。而调用该方法的只有 DefaultExecutorRepository 类的 createExecutor 方法,该方法会根据 url 上的参数 threadpool=cached 来决定创建那种类型的线程池。createExecutor 是一个私有方法,调用它的有下面两个方法:
/**
* Get called when the server or client instance initiating.
*
* @param url
* @return
*/
public synchronized ExecutorService createExecutorIfAbsent(URL url) {
String componentKey = EXECUTOR_SERVICE_COMPONENT_KEY;
if (CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(SIDE_KEY))) {
componentKey = CONSUMER_SIDE;
}
Map<Integer, ExecutorService> executors = data.computeIfAbsent(componentKey, k -> new ConcurrentHashMap<>());
Integer portKey = url.getPort();
ExecutorService executor = executors.computeIfAbsent(portKey, k -> createExecutor(url));
// If executor has been shut down, create a new one
if (executor.isShutdown() || executor.isTerminated()) {
executors.remove(portKey);
executor = createExecutor(url);
executors.put(portKey, executor);
}
return executor;
}
public ExecutorService getExecutor(URL url) {
String componentKey = EXECUTOR_SERVICE_COMPONENT_KEY;
if (CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(SIDE_KEY))) {
componentKey = CONSUMER_SIDE;
}
Map<Integer, ExecutorService> executors = data.get(componentKey);
/**
* It's guaranteed that this method is called after {@link #createExecutorIfAbsent(URL)}, so data should already
* have Executor instances generated and stored.
*/
if (executors == null) {
logger.warn("No available executors, this is not expected, framework should call createExecutorIfAbsent first " +
"before coming to here.");
return null;
}
Integer portKey = url.getPort();
ExecutorService executor = executors.get(portKey);
if (executor != null) {
if (executor.isShutdown() || executor.isTerminated()) {
executors.remove(portKey);
executor = createExecutor(url);
executors.put(portKey, executor);
}
}
return executor;
}
对于上面第一个方法,备注已经说明在服务提供者或者服务消费者初始化的时候会调用,通过debug 可以得出:服务提供者初始化会创建线程名为 DubboServerHandler-10.12.16.67:20880-thread 的线程池,服务消费者会创建线程名为 DubboClientHandler-10.12.16.67:20880-thread 的线程池。
这里需要说明下,Dubbo 创建的线程池会存储在 Map 中共享使用:
private ConcurrentMap<String, ConcurrentMap<Integer, ExecutorService>> data = new ConcurrentHashMap<>();
外面的 key 表示服务提供方还是消费方,里面的 key 表示服务暴露的端口号,也就是说消费方对于相同端口号的服务只会创建一个线程池,共享同一个线程池进行服务请求和消息接收后一系列处理。
显然和 Dubbo-thread 名不一样,那就很有可能是通过调用第二个方法创建的线程池。第二个方法的调用往上追溯就比较分散了,找不到什么有用的信息。
再看方法具体内容,当已经创建的线程池关闭或终止时会重新创建新的线程池。然后就推测什么情况下线程池会被关闭或终止,在服务重启后输出堆栈信息并没有 Dubbo-thread 线程,然后就猜测消费方和提供方连接断开会不会触发线程池关闭,于是重启了服务提供方,果然重现了Dubbo-thread 线程。
然后在 Dubbo 的具体线程池创建方法中添加日志,输出调用栈信息(通过产生一个异常输出调用信息)。
如下图:
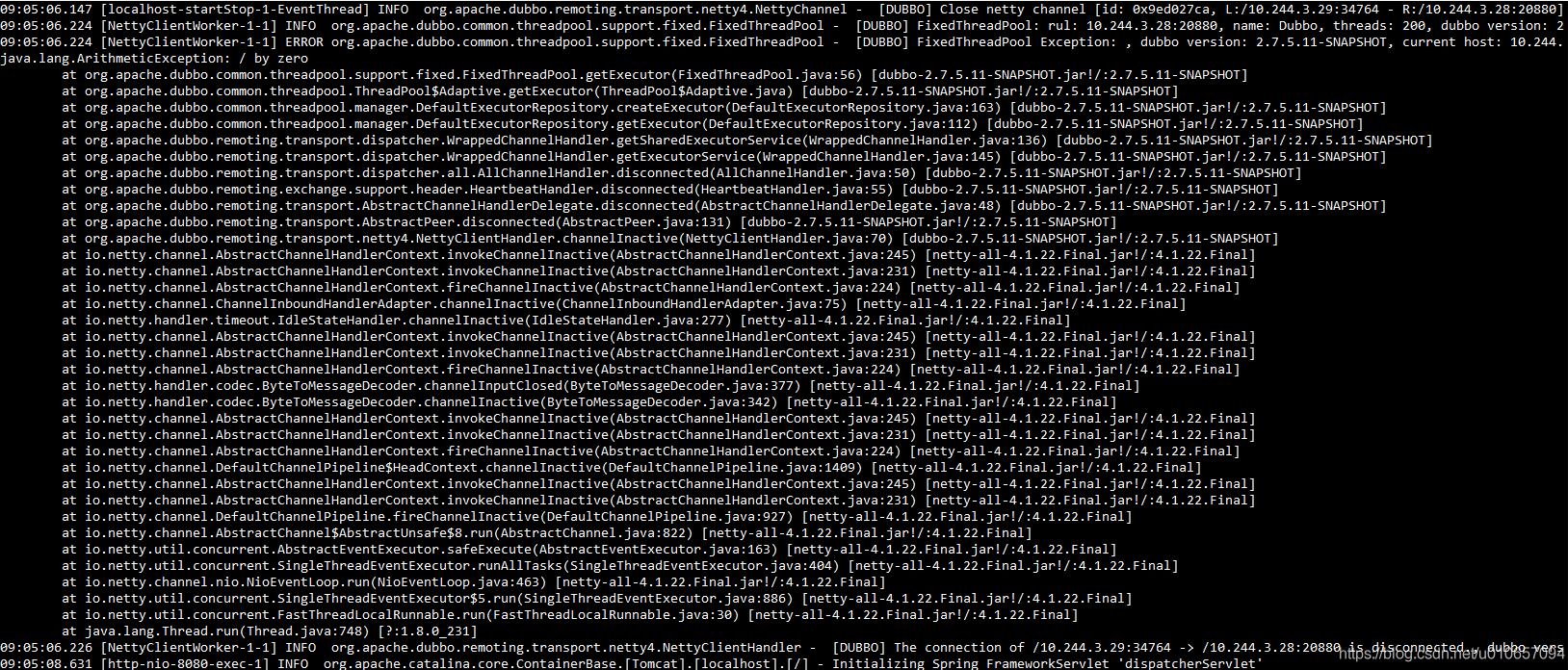
在这里插入图片描述可以看到当 channel 失效时会调用 disconnected 方法,最终会调用 DefaultExecutorRepository 类的 getExecutor 创建线程池,当服务提供者重启时,消费方相应的线程池会被shutdown。
重现创建线程池所用的 URL 是 WrappedChannelHandler 类的 URL,该值是在服务启动初始化时设置的,该值的设置要早于 AbstractClient 客户端 Executor 初始化。
因此由于 channel 断开而重新创建的线程池所用的 URL 和客户端初始创建线程池用的 URL 可能是不同的,特别是在没有配置 consumer 的线程池类型时,初始创建的 Cached 类型线程池,线程名称是 DubboClientHandler…。
而重新创建所用 URL 是没有经过下面方法设置的,因此就会创建默认类型为 fixed 的线程池,线程数为默认 200,线程名为 Dubbo…。
private void initExecutor(URL url) {
url = ExecutorUtil.setThreadName(url, CLIENT_THREAD_POOL_NAME);
url = url.addParameterIfAbsent(THREADPOOL_KEY, DEFAULT_CLIENT_THREADPOOL);
executor = executorRepository.createExecutorIfAbsent(url);
}
总结
那么,就可以知道 Dubbo-thread 线程池的创建是由于服务消费方和提供方之间连接断开而创建的线程池,代替程序启动初始化时创建的 DubboClientHandler 线程池。主要做一些 channel 断开后续一些处理,还有接收服务端消息后的反序列化等操作,具体的可以看类 ThreadlessExecutor(同步调用处理类) 、ChannelEventRunnable(channel 不同状态处理,包括:连接、接收到消息、断开链接等)。
还有一个要注意到点是,如果没有配置consumer.threadpool 类型、therads 等信息,那么断开连接后再创建的线程池将会是 fixed 类型的线程池,线程数为默认 200。
以上这篇为什么程序中突然多了 200 个 Dubbo-thread 线程的说明就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Java 获取两个List的交集和差集,以及应用场景操作
背景介绍 在实际项目中,特别是一些管理后台类的项目,会遇到底层数据是按照一对多关系的数据表存储的管理界面.列表页是一对多关系中一对应的数据列表,二级的详情页中是一对多关系中多对应的多条数据展示.通常二级页面是能够增.删.改数据的编辑页面,在点击保存提交数据后,服务器端需要插入新增的数据,删除要删除的数据,更新改变的数据. 例如,在汽车电商领域,如果要实现一辆车型在不同省份有不同的价格行情,就需要有一个车价管理的后台管理界面.每辆车对应的详情界面管理各省价格行情,增加该车在某个省份的行情,或者更新
-
解决dubbo错误ip及ip乱入问题的方法
问题 在本地启动dubbo时,服务注册在本地的zookeeper ,但是注册IP却不是本地的iP.产生问题,导致consumer 找不到provider ,访问不了服务. 例如 本地IP为 10.0.0.1 ,但是zookeeper上的注册ip 可能是 196.168.0.1 产生原因,随机产生,可能是你重启一下机器,或者电脑小智一段时间就会发生. 报错类似 com.alibaba.dubbo.remoting.RemotingException: client(url: dubbo://100
-
java 较大数据量取差集,list.removeAll性能优化详解
今天在优化项目中的考勤同步功能时遇到将考勤机中的数据同步到数据库, 两边都是几万条数据的样子,老代码的做法差不多半个小时,优化后我本机差不多40秒,服务器速度会更加理想. 两个数据集取差集首先想到的方法便是List.removeAll方法,但是实验发现jdk自带的List.removeAll效率很低 List.removeAll效率低原因: List.removeAll效率低和list集合本身的特点有关 : List底层数据结构是数组,查询快,增删慢 1.List.contains()效率没有h
-
如何解决IDEA使用Tomcat控制台中文出现乱码问题
如下图所示,Intellij IDEA显示中文为乱码, 根据Intellij IDEA控制台输出,Tomcat Log出现乱码,因此可以将问题定位到Tomcat上,具体解决方法: 第一步:打开Tomcat安装位置,找到:conf下的logging.properties文件,然后右击使用文本编辑器打开. 第二步:把这五个UTF-8都改为:GBK 改好后如下图所示. 之后重启tomcat后在看控制台输出,中文就没有乱码了,成功解决! 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支
-
IntelliJ IDEA里找不到javax.servlet的jar包的解决方法
今天在复习Java Web时,因为初次使用 IntelliJ IDEA 中, 当使用javax.servlet包下的类时(例:javax.servlet.http.HttpServletRequest), 你会发现在IntelliJ IDEA里无法成功编译这个程序. 问题解决: 办法1:使用Project Structure 在弹出的窗口中选择tomcat所在的目录,进入里面的lib目录,寻找servlet-api.jar这个jar包(如果JSP页面也有相关的JavaWeb对象,则还要寻找jsp
-
为什么程序中突然多了 200 个 Dubbo-thread 线程的说明
背景 在某次查看程序线程堆栈信息时,偶然发现有 200 个 Dubbo-thread 线程,而且大部分都处于 WAITING 状态,如下所示: "Dubbo-thread-200" #160932 daemon prio=5 os_prio=0 tid=0x00007f5af9b54800 nid=0x79a6 waiting on condition [0x00007f5a9acd5000] java.lang.Thread.State: WAITING (parking) at s
-
java中thread线程start和run的区别
最近看到一个题目,代码如下: 复制代码 代码如下: public static void main(String args[]) {Thread t = new Thread() {public void run() {pong();}}; t.run();System.out.println("ping");}static void pong() {System.out.println("pong");} 问,结果会输出什么? 我运行了很多次,结果都是pong p
-
linux c程序中获取shell脚本输出的实现方法
1. 前言Unix界有一句名言:"一行shell脚本胜过万行C程序",虽然这句话有些夸张,但不可否认的是,借助脚本确实能够极大的简化一些编程工作.比如实现一个ping程序来测试网络的连通性,实现ping函数需要写上200~300行代码,为什么不能直接调用系统的ping命令呢?通常在程序中通过 system函数来调用shell命令.但是,system函数仅返回命令是否执行成功,而我们可能需要获得shell命令在控制台上输出的结果.例如,执行外部命令ping后,如果执行失败,我们希望得到p
-
Python程序中设置HTTP代理
0x00 前言 大家对HTTP代理应该都非常熟悉,它在很多方面都有着极为广泛的应用.HTTP代理分为正向代理和反向代理两种,后者一般用于将防火墙后面的服务提供给用户访问或者进行负载均衡,典型的有Nginx.HAProxy等.本文所讨论的是正向代理. HTTP代理最常见的用途是用于网络共享.网络加速和网络限制突破等.此外,HTTP代理也常用于Web应用调试.Android/IOS APP 中所调用的Web API监控和分析,目前的知名软件有Fiddler.Charles.Burp Suite和mi
-

微信小程序中做用户登录与登录态维护的实现详解
总结 大家都知道,在开发中提供用户登录以及维护用户的登录状态,是一个拥有用户系统的软件应用普遍需要做的事情.像微信这样的一个社交平台,如果做一个小程序应用,我们可能很少会去做一个完全脱离和舍弃连接用户信息的纯工具软件. 让用户登录,标识用户和获取用户信息,以用户为核心提供服务,是大部分小程序都会做的事情.我们今天就来了解下在小程序中,如何做用户登录,以及如何去维护这个登录后的会话(Session)状态.下面来看看详细的介绍: 在微信小程序中,我们大致会涉及到以下三类登录方式: 自有的账号注册和登
-
微信小程序中如何使用flyio封装网络请求
Flyio简介 Fly.js 通过在不同 JavaScript 运行时通过在底层切换不同的 Http Engine来实现多环境支持,但同时对用户层提供统一.标准的Promise API.不仅如此,Fly.js还支持请求/响应拦截器.自动转化JSON.请求转发等功能,详情请参考:https://github.com/wendux/fly . 下面我们看看在微信小程序.mpvue中和中如何使用fly. Flyio 官方地址 文档 github地址 Flyio的一些特点 fly.js 是一个基于 pr
-
监控微信小程序中的慢HTTP请求过程详解
Fundebug 的微信小程序监控插件在 0.5.0 版本已经支持监控 HTTP 请求错误,在小程序中通过wx.request发起 HTTP 请求,如果请求失败,会被捕获并上报.时隔一年,微信小程序插件已经更新到 1.3.1, 而且提供了一个非常有用的功能,支持监控 HTTP 慢请求.对于轻量级的性能分析,可以说已经够用. 本文我们以一个天气微信小程序为例(由bodekjan开发),来演示如何监控慢请求.bmap-wx.js中的weather()函数调用百度地图小程序 api 提供的接口来获取天
-
微信小程序中的canvas 文字断行和省略号显示功能的处理方法
文字的多行处理在dom元素中很好办.但是canvas中没有提供方法,只有通过截取指定字符串来达到目的. 那么下面就介绍我自己处理的办法: wxml: <canvas canvas-id='word' id='test'></canvas> canvas肯定要一个画板容器啦,记得设置宽高哦,小程序中默认宽高是300px和150px js:在page中 //处理文字多出省略号显示 dealWords: function (options) { options.ctx.setFontSi
-
微信小程序中网络请求缓存的解决方法
需求 提交小程序审核时,有一个体验测评,产品让我们根据小程序的体验测评报告去优化小程序. 其中有一项是网络请求的优化,给我们出了很大的难题. 文档中是这样解释的:3分钟以内同一个url请求不出现两次回包大于128KB且一模一样的内容 看到这个问题的时候,首先想到的是在响应头上加上cache-control,经过测试发现小程序并不支持网路请求缓存.搜索发现官方明确答复,小程序不支持网络请求缓存:wx.request不支持http缓存 既然官方不支持网络请求缓存,那只能自己想办法解决这个问题了. 先
-
使用C语言实例描述程序中的内聚和耦合问题
编程时,我们讲究的是高内聚低耦合,在协同开发.代码移植.维护等环节都起到很重要的作用. 一.原理篇 而低耦合,是指模块之间尽可能的使其独立存在,模块之间不产生联系不可能,但模块与模块之间的接口应该尽量少而简单.这样,高内聚从整个程序中每一个模块的内部特征角度,低耦合从程序中各个模块之间的关联关系角度,对我们的设计提出了要求. 程序设计和软件工程发展过程中产生的很多技术.设计原则,都可以从内聚和耦合的角度进行解读.作为C语言程序设计的初学者,结合当前对于函数的理解可达到的程度,我们探讨一下如何做到