使用Numpy对特征中的异常值进行替换及条件替换方式
原始数据为Excel文件,由传感器获得,通过Pyhton xlrd模块读入,读入后为数组形式,由于其存在部分异常值和缺失值,所以便利用Numpy对其中的异常值进行替换或条件替换。
1. 将'nan'替换为给定值
import numpy as np
data = np.array([['nan', 1, 2, 3, 4], # 数据类型为字符串型
[10, 15, 20, 25, 'nan'],
['nan', 5, 8, 10, 20]])
print(data)
# [['nan' '1' '2' '3' '4']
# ['10' '15' '20' '25' 'nan']
# ['nan' '5' '8' '10' '20']]
data[data == 'nan'] = 100 # 将numpy中为'nan'的项替换为 100
print(data)
# [['100' '1' '2' '3' '4']
# ['10' '15' '20' '25' '100']
# ['100' '5' '8' '10' '20']]
data = data.astype(float) # 将数据由字符型转换为浮点型
print(data)
# [[100. 1. 2. 3. 4.]
# [ 10. 15. 20. 25. 100.]
# [100. 5. 8. 10. 20.]]
2. 按列进行条件替换
当利用'3σ准则'或者箱型图进行异常值判断时,通常需要对 > upper 或 < lower的值进行处理,这时就需要按列进行条件替换了。
print(data) # [[100. 1. 2. 3. 4.] # [ 10. 15. 20. 25. 100.] # [100. 5. 8. 10. 20.]] data[:, 1][data[:, 1] < 5] = 5 # 对第2列小于 5 的替换为5 print(data) # [[100. 5. 2. 3. 4.] # [ 10. 15. 20. 25. 100.] # [100. 5. 8. 10. 20.]] data[:, 2][data[:, 2] > 15] = 10 # 对第3列大于 15 的替换为10 print(data) # [[100. 5. 2. 3. 4.] # [ 10. 15. 10. 25. 100.] # [100. 5. 8. 10. 20.]]
补充知识:Python之dataframe修改异常值—按行判断值是否大于平均值的指定倍数,如果是则用均值替换
如下所示:
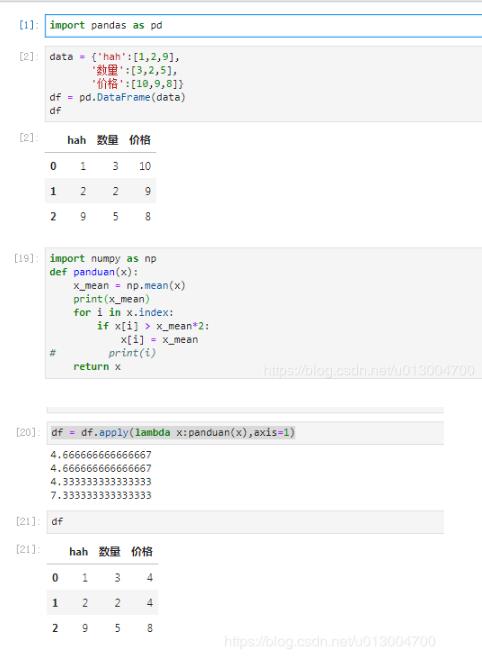
import pandas as pd
data = {'hah':[1,2,9],
'数量':[3,2,5],
'价格':[10,9,8]}
df = pd.DataFrame(data)
df
import numpy as np
def panduan(x):
x_mean = np.mean(x)
print(x_mean)
for i in x.index:
if x[i] > x_mean*2:
x[i] = x_mean
# print(i)
return x
df = df.apply(lambda x:panduan(x),axis=1)
以上这篇使用Numpy对特征中的异常值进行替换及条件替换方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
dataframe 按条件替换某一列中的值方法
如下所示: import pandas as pd content = ['T', 'F'] * 10 data = pd.DataFrame(content, columns=['Y']) print(data) Y 0 T 1 F 2 T 3 F 4 T 5 F 6 T 7 F 8 T 9 F 10 T 11 F 12 T 13 F 14 T 15 F 16 T 17 F 18 T 19 F data.loc[data['Y'] == 'T'] = 1 data.loc[data['Y']
-

利用Python进行异常值分析实例代码
前言 异常值是指样本中的个别值,也称为离群点,其数值明显偏离其余的观测值.常用检测方法3σ原则和箱型图.其中,3σ原则只适用服从正态分布的数据.在3σ原则下,异常值被定义为观察值和平均值的偏差超过3倍标准差的值.P(|x−μ|>3σ)≤0.003,在正太分布假设下,大于3σ的值出现的概率小于0.003,属于小概率事件,故可认定其为异常值. 异常值分析是检验数据是否有录入错误以及含有不合常理的数据.忽视异常值的存在是十分危险的,不加剔除地把异常值包括进数据的计算分析过程中,对结果会产生不良影响:重
-
Python替换NumPy数组中大于某个值的所有元素实例
我有一个2D(二维) NumPy数组,并希望用255.0替换大于或等于阈值T的所有值.据我所知,最基础的方法是: shape = arr.shape result = np.zeros(shape) for x in range(0, shape[0]): for y in range(0, shape[1]): if arr[x, y] >= T: result[x, y] = 255 有更简洁和pythonic的方式来做到这一点吗? 有没有更快(可能不那么简洁和/或不那么pythonic)的
-
使用Numpy对特征中的异常值进行替换及条件替换方式
原始数据为Excel文件,由传感器获得,通过Pyhton xlrd模块读入,读入后为数组形式,由于其存在部分异常值和缺失值,所以便利用Numpy对其中的异常值进行替换或条件替换. 1. 将'nan'替换为给定值 import numpy as np data = np.array([['nan', 1, 2, 3, 4], # 数据类型为字符串型 [10, 15, 20, 25, 'nan'], ['nan', 5, 8, 10, 20]]) print(data) # [['nan' '1'
-
numpy和pandas中数组的合并、拉直和重塑实例
合并 在numpy中合并两个array numpy中可以通过concatenate,参数axis=0表示在垂直方向上合并两个数组,等价于np.vstack:参数axis=1表示在水平方向上合并两个数组,等价于np.hstack. 垂直方向: np.concatenate([arr1,arr2],axis=0) np.vstack([arr1,arr2]) 水平方向: np.concatenate([arr1,arr2],axis=1) np.hstack([arr1,arr2]) import
-
Python Numpy:找到list中的np.nan值方法
这个问题源于在训练机器学习的一个模型时,使用训练数据时提示prepare的数据中存在np.nan 报错信息如下: ValueError: np.nan is an invalid document, expected byte or unicode string. 刚开始不知道为什么会有这个,后来发现是list中存在nan值 下面是找到nan值的方法: 简单找到: import numpy as np x = np.array([2,3,np.nan,5, np.nan,5,2,3]) for
-
numpy 对矩阵中Nan的处理:采用平均值的方法
尽管我们可以将所有的NaN替换成0,但是由于并不知道这些值的意义,所以这样做是个下策.如果它们是开氏温度,那么将它们置成0这种处理策略就太差劲了. 下面我们用平均值来代替缺失值,平均值根据那些非NaN得到. from numpy import * datMat = mat([[1,2,3],[4,Nan,6]]) numFeat = shape(datMat)[1] for i in range(numFeat): meanVal = mean(datMat[nonzero(~isnan(dat
-
对numpy和pandas中数组的合并和拆分详解
合并 numpy中 numpy中可以通过concatenate,指定参数axis=0 或者 axis=1,在纵轴和横轴上合并两个数组. import numpy as np import pandas as pd arr1=np.ones((3,5)) arr1 Out[5]: array([[ 1., 1., 1., 1., 1.], [ 1., 1., 1., 1., 1.], [ 1., 1., 1., 1., 1.]]) arr2=np.random.randn(15).reshape(
-
numpy返回array中元素的index方法
如下所示: import numpy a = numpy.array(([3,2,1],[2,5,7],[4,7,8])) itemindex = numpy.argwhere(a == 7) print (itemindex) print a 以上这篇numpy返回array中元素的index方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
numpy和tensorflow中的各种乘法(点乘和矩阵乘)
点乘和矩阵乘的区别: 1)点乘(即" * ") ---- 各个矩阵对应元素做乘法 若 w 为 m*1 的矩阵,x 为 m*n 的矩阵,那么通过点乘结果就会得到一个 m*n 的矩阵. 若 w 为 m*n 的矩阵,x 为 m*n 的矩阵,那么通过点乘结果就会得到一个 m*n 的矩阵. w的列数只能为 1 或 与x的列数相等(即n),w的行数与x的行数相等 才能进行乘法运算. 2)矩阵乘 ---- 按照矩阵乘法规则做运算 若 w 为 m*p 的矩阵,x 为 p*n 的矩阵,那么通过矩阵相乘结
-
numpy按列连接两个维数不同的数组方式
合并两个维数不同的ndarray 假设我们有一个3×2 numpy数组: x = array(([[1,2], [3, 4], [5,6]])) 现在需要把它与一个一维数组: y = array(([7, 8,9])) 通过将其添加到行的末尾,连接为一个3×3 numpy数组,如下所示: array([[1,2,7], [3,4,8], [5,6,9]]) 在numpy中按列连接的方法是: hstack((x,y)) 但是这不行,会报错: ValueError: arrays must have
-
Python Pandas中缺失值NaN的判断,删除及替换
目录 前言 1. 检查缺失值NaN 2. Pandas中NaN的类型 3. NaN的删除 dropna() 3.1 删除所有值均缺失的行/列 3.2 删除至少包含一个缺失值的行/列 3.3 根据不缺少值的元素数量删除行/列 3.4 删除特定行/列中缺少值的列/行 4. 缺失值NaN的替换(填充) fillna() 4.1 用通用值统一替换 4.2 为每列替换不同的值 4.3 用每列的平均值,中位数,众数等替换 4.4 替换为上一个或下一个值 总结 前言 当使用pandas读取csv文件时,如果元
-
Pandas中根据条件替换列中的值的四种方式
目录 方法1:使用dataframe.loc[]函数 方法2:使用NumPy.where()函数 方法3:使用pandas掩码函数 方法4:替换包含指定字符的字符串 方法1:使用dataframe.loc[]函数 通过这个方法,我们可以用一个条件或一个布尔数组来访问一组行或列.如果我们可以访问它,我们也可以操作它的值,是的!这是我们的第一个方法,通过pandas中的dataframe.loc[]函数,我们可以访问一个列并通过一个条件改变它的值. 语法:df.loc[ df["column_nam