pytest多进程或多线程执行测试实例
目录
- 前言:
- 分布式执行用例的原则:
- 项目结构
- 测试脚本
- 多进程执行用例之pytest-xdist
- pytest-xdist分布式测试的原理:
- pytest-xdist分布式测试的流程:
- 第一步:master创建worker
- 第二步:workers收集测试项用例
- 第三步:master检测workers收集到的测试用例集
- 第四步:master分发测试用例
- 第五步:worker执行测试用例
- 第六步:测试结束
- 多线程执行用例之pytest-parallel
- 常用参数配置
- pytest-parallel与pytest-xdist对比说明:
前言:
- 实际项目中的用例数量会非常多,几百上千;如果采用
单进程串行执行的话会非常耗费时间。假设每条用例耗时2s,1000条就需要2000s $\approx$ 33min;还要加上用例加载、测试前/后置套件等耗时;导致测试执行效率会相对低。 - 想象一下如果开发改动一块代码,我们需要回归一下,这时候执行一下自动化用例需要花费大半个小时或者好几个小时的时间,这是我们无法容忍的。
- 为了节省项目测试时间,需要多个测试用例同时
并行执行;这就是一种分布式场景来缩短测试用例的执行时间,提高效率。
分布式执行用例的原则:
- 用例之间是相互独立的,没有依赖关系,完全可以独立运行;
- 用例执行没有顺序要求,随机顺序都能正常执行;
- 每个用例都能重复运行,运行结果不会影响其他用例。
项目结构

测试脚本
# test1/test_1.py import time def test1_test1(): time.sleep(1) assert 1 == 1, "1==1" def test1_test2(): time.sleep(1) assert 1 == 1, "1==1" class TestDemo1: def test_inner_1(self): time.sleep(1) assert 1 == 1, "1==1" class TestDemo2: def test_inner_2(self): time.sleep(1) assert 1 == 1, "1==1" # test1/inner/test_3.py import time def test3_test1(): time.sleep(1) assert 1 == 1, "1==1" def test3_test2(): time.sleep(1) assert 1 == 1, "1==1" # test2/test_2.py import time def test2_test1(): time.sleep(1) assert 1 == 1, "1==1" def test2_test2(): time.sleep(1) assert 1 == 1, "1==1" # test2/inner/test_3.py import time def test4_test1(): time.sleep(1) assert 1 == 1, "1==1" def test4_test2(): time.sleep(1) assert 1 == 1, "1==1"
正常执行:需要8.10s

多进程执行用例之pytest-xdist
多cpu并行执行用例,直接加个-n参数即可,后面num参数就是并行数量,比如num设置为3
pytest -v -n num
参数:
- -n auto : 自动侦测系统里的CPU数目
- -n num : 指定运行测试的处理器进程数
多进程并行执行:耗时2.66s大大的缩短了测试用例的执行时间。

pytest-xdist分布式测试的原理:
- xdist的分布式类似于一主多从的结构,master负责下发命令,控制slave;slave根据master的命令执行特定测试任务。
- 在xdist中,主是master,从是workers;xdist会产生一个或多个workers,workers都通过master来控制,每个worker相当于一个
mini版pytest执行器。 - master不执行测试任务,只对worker收集到的所有用例进行分发;每个worker负责执行测试用例,然后将执行结果反馈给master;由master统计最终测试结果。
pytest-xdist分布式测试的流程:
第一步:master创建worker
- master在
测试会话(test session)开始前产生一个或多个worker。 - master和worker之间是通过execnet和网关来通信的。
- 实际编译执行测试代码的worker可能是本地机器也可能是远程机器。
第二步:workers收集测试项用例
- 每个worker类似一个迷你型的
pytest执行器。 - worker会执行一个完整的
test collection过程。【收集所有测试用例的过程】 - 然后把测试用例的
ids返回给master。【ids表示收集到的测试用例路径】 - master不执行任何测试用例。
注意:分布式测试(pytest-xdist)方式执行测试时不会输出测试用例中的print内容,因为master并不执行测试用例。
第三步:master检测workers收集到的测试用例集
- master接收到所有worker收集的测试用例集之后,master会进行一些完整性检查,以确保所有worker都收集到一样的测试用例集(包括顺序)。
- 如果检查通过,会将测试用例的ids列表转换成简单的索引列表,每个索引对应一个测试用例的在原来测试集中的位置。
- 这个方案可行的原因是:所有的节点都保存着相同的测试用例集。
- 并且使用这种方式可以节省带宽,因为master只需要告知workers需要执行的测试用例对应的索引,而不用告知完整的测试用例信息。
第四步:master分发测试用例
有以下四种分发策略:命令行参数 --dist=mode选项(默认load)
each:master将完整的测试索引列表分发到每个worker,即每个worker都会执行一遍所有的用例。

load:master将大约$\frac{1}{n}$的测试用例以轮询的方式分发到各个worker,剩余的测试用例则会等待worker执行完测试用例以后再分发;每个用例只会被其中一个worker执行一次。

loadfile:master分发用例的策略为按ids中的文件名(test_xx.py/xx_test.py)进行分发,即同一个测试文件中的测试用例只会分发给其中一个worker;具有一定的隔离性。
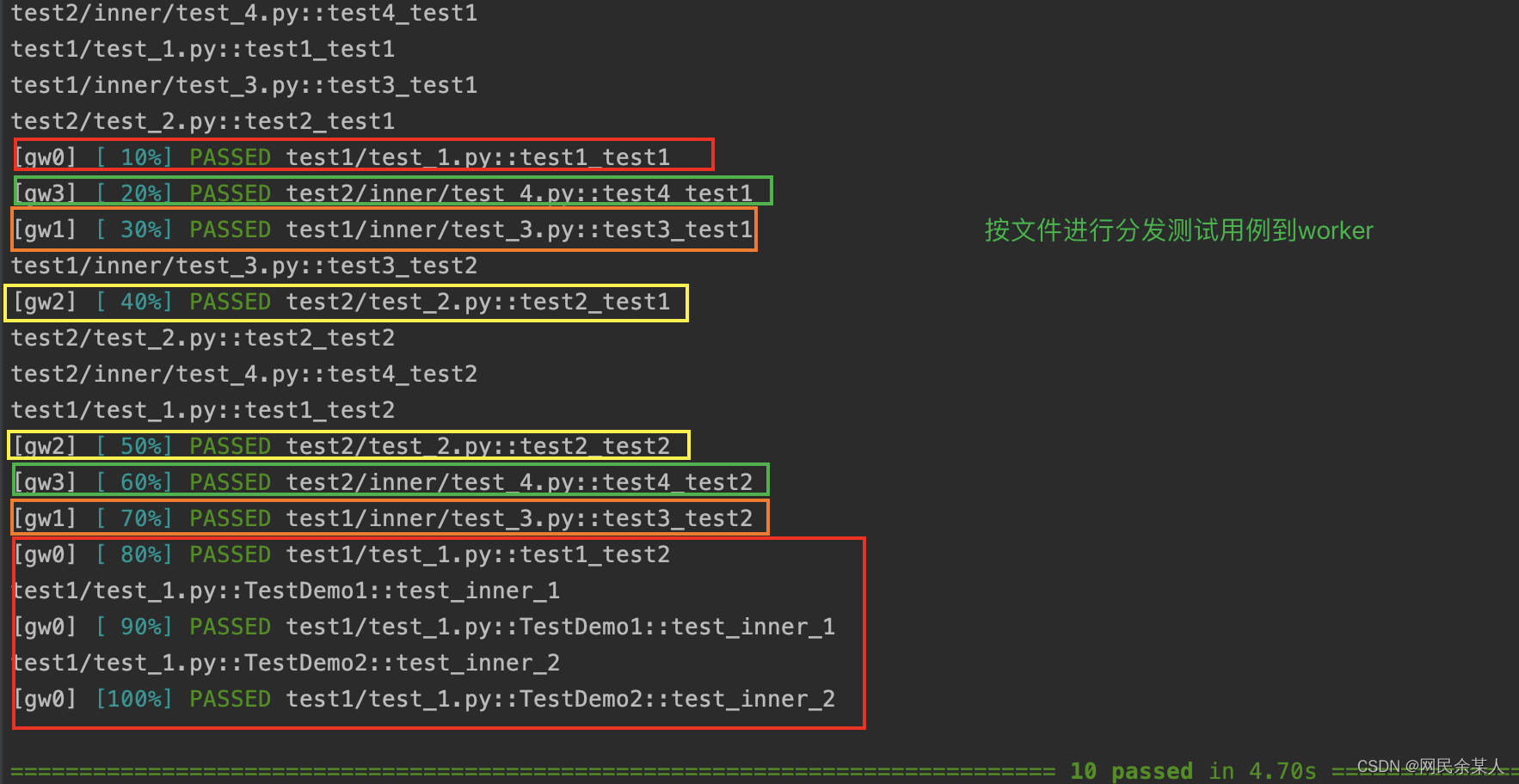
loadscope:master分发用例对策略为按作用域进行分发,同一个模块下的测试函数或某个测试类中的测试函数会分发给同一个worker来执行;即py文件中无测试类的话(只有测试function)将该模块分发给同一个worker执行,如果有测试类则会将该文件中的测试类只会分发给同一个worker执行,多个类可能分发给多个worker;目前无法自定义分组,按类 class 分组优先于按模块 module 分组。

注意:可以使用pytest_xdist_make_scheduler这个hook来实现自定义测试分发逻辑。
如:想按目录级别来分发测试用例:
from xdist.scheduler import LoadScopeScheduling
class CustomizeScheduler(LoadScopeScheduling):
def _split_scope(self, nodeid):
return nodeid.split("/", 1)[0]
def pytest_xdist_make_scheduler(config, log):
return CustomizeScheduler(config, log)
- 只需在最外层conftest中继承
xdist.scheduler.LoadScopeScheduling并重写_split_scope方法 - 重写钩子函数
pytest_xdist_make_scheduler
pytest -v -n 4 --dist=loadfile

第五步:worker执行测试用例
- workers 重写了
pytest_runtestloop:pytest的默认实现是循环执行所有在test_session这个对象里面收集到的测试用例。 - 但是在xdist里, workers实际上是等待master为其发送需要执行的测试用例。
- 当worker收到测试任务, 就顺序执行
pytest_runtest_protocol。 - 值得注意的一个细节是:workers 必须始终保持至少一个测试用例在的任务队列里, 以兼容
pytest_runtest_protocol(item, nextitem)hook的参数要求,为了将nextitem传给hook。 - master在worker执行完分配的一组测试后,基于测试执行时长以及每个worker剩余测试用例综合决定是否向这个worker发送更多的测试用例。
- worker会在执行最后一个测试项前等待master的更多指令。
- 如果它收到了更多测试项, 那么就可以安全的执行
pytest_runtest_protocol,因为这时nextitem参数已经可以确定。 - 如果它收到一个
shutdown信号, 那么就将nextitem参数设为None, 然后执行pytest_runtest_protocol
第六步:测试结束
- 当master没有更多执行测试任务时,它会发送一个
shutdown信号给所有worker。 - 当worker将剩余测试用例执行完后退出进程。
- 当workers在测试执行结束时,会将结果被发送回master,然后master将结果转发到其他
pytest hooks比如:pytest_runtest_logstart、pytest_runtest_logreport确保整个测试活动进行正常运作。 - master等待所有worker全部退出并关闭测试会话。
注意:pytest-xdist 是让每个 worker 进程执行属于自己的测试用例集下的所有测试用例。这意味着在不同进程中,不同的测试用例可能会调用同一个 scope 范围级别较高(例如session)的 fixture,该 fixture 则会被执行多次,这不符合 scope=session 的预期。
pytest-xdist 没有内置的支持来确保会话范围的 fixture 仅执行一次,但是可以通过使用锁定文件进行进程间通信来实现;让scope=session 的 fixture 在 test session 中仅执行一次。
示例:需要安装 filelock 包,安装命令pip install filelock
- 比如只需要执行一次login(或定义配置选项、初始化数据库连接等)。
- 当第一次请求这个fixture时,则会利用
FileLock仅产生一次fixture数据。 - 当其他进程再次请求这个fixture时,则不会重复执行fixture。
import pytest
from filelock import FileLock
@pytest.fixture(scope="session")
def login(tmp_path_factory, worker_id):
# 代表是单机运行
if worker_id == "master":
token = str(random())
print("fixture:请求登录接口,获取token", token)
os.environ['token'] = token
return token
# 分布式运行
# 获取所有子节点共享的临时目录,无需修改【不可删除、修改】
root_tmp_dir = tmp_path_factory.getbasetemp().parent
fn = root_tmp_dir / "data.json"
with FileLock(str(fn) + ".lock"):
if fn.is_file(): # 代表已经有进程执行过该fixture
token = json.loads(fn.read_text())
else: # 代表该fixture第一次被执行
token = str(random())
fn.write_text(json.dumps(token))
# 最好将后续需要保留的数据存在某个地方,比如这里是os的环境变量
os.environ['token'] = token
return token
多线程执行用例之pytest-parallel
用于并行和并发测试的 pytest 插件
pip install pytest-parallel
常用参数配置
--workers=n:多进程运行需要加此参数, n是进程数。默认为1--tests-per-worker=n:多线程需要添加此参数,n是线程数
如果两个参数都配置了,就是进程并行;每个进程最多n个线程,总线程数:进程数*线程数
【注意】
- 在windows上进程数永远为1。
- 需要使用
if name == “main” :在命令行窗口运行测试用例会报错
示例:
- pytest test.py --workers 3 :3个进程运行
- pytest test.py --tests-per-worker 4 :4个线程运行
- pytest test.py --workers 2 --tests-per-worker 4 :2个进程并行,且每个进程最多4个线程运行,即总共最多8个线程运行。
import pytest
def test_01():
print('测试用例1操作')
def test_02():
print('测试用例2操作')
def test_03():
print('测试用例3操作')
def test_04():
print('测试用例4操作')
def test_05():
print('测试用例5操作')
def test_06():
print('测试用例6操作')
def test_07():
print('测试用例7操作')
def test_08():
print('测试用例8操作')
if __name__ == "__main__":
pytest.main(["-s", "test_b.py", '--workers=2', '--tests-per-worker=4'])
pytest-parallel与pytest-xdist对比说明:
- pytest-parallel 比 pytst-xdist 相对好用,功能支持多;
- pytst-xdist 不支持多线程;
- pytest-parallel 支持python3.6及以上版本,所以如果想做多进程并发在linux或者mac上做,在Windows上不起作用(Workers=1),如果做多线程linux/mac/windows平台都支持,进程数为workers的值。
- pytest-xdist适用场景为:
- 不是线程安全的
- 多线程时性能不佳的测试
- 需要状态隔离
- pytest-parallel对于某些用例(如 Selenium)更好:
- 可以是线程安全的
- 可以对 http 请求使用非阻塞 IO 来提高性能
简而言之,pytest-xdist并行性pytest-parallel是并行性和并发性。
到此这篇关于pytest多进程或多线程执行测试的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python+pytest自动化测试函数测试类测试方法的封装
目录 前言 一.测试用例封装的一般规则 三.测试类/方法的封装 四.示例代码 总结 前言 今天呢,笔者想和大家聊聊python+pytest接口自动化中将代码进行封装,只有将测试代码进行封装,才能被测试框架识别执行. 例如单个接口的请求代码如下: import requests headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like
-
pytest多线程与多设备并发appium
1.appium+python 实现单设备的 app 自动化测试 启动 appium server,占用端口 4723 电脑与一个设备连接,通过 adb devices 获取已连接的设备 在 python 代码当中,编写启动参数,通过 pytest 编写测试用例,来进行自动化测试. 2.若要多设备并发,同时执行自动化测试,那么需要: 确定设备个数 每个设备对应一个 appium server 的端口号,并启动 appium pytest 要获取到每个设备的启动参数,然后执行自动化测试. 3.实现
-
python中Pytest常用的插件
目录 前言 1. 用例依赖 2. 失败重跑 3. 指定用例执行顺序 4. 分布式运行 5. 多重断言 6. 小结 前言 除了框架本身提供的功能外,Pytest还支持上百种第三方插件,良好的扩展性可以更好的满足大家在用例设计时的不同需求.本文将为大家详细介绍下面5项常用的插件. 1. 用例依赖 编写用例的时候,我们会注意用例之间的独立性,但部分用例之间确实存在关联,无法做到彻底独立,那么我们就可以通过使用插件pytest-dependency设置用例之间的依赖关系.当用例A依赖于用例B时,若用例B
-
Pytest测试报告工具Allure用法介绍
简介 Allure Framework是一种灵活的.轻量级.多语言测试报告工具. 不仅可以以简洁的网络报告形式非常简洁地显示已测试的内容, 而且还允许参与开发过程的每个人从日常执行中提取最大程度的有用信息和测试. 从开发/测试的角度来看: Allure报告可以快速查看到缺陷点,可以将测试未通过划分为Bug和中断的测试. 还可以配置日志,步骤,固件,附件,时间,历史记录,以及与TMS的集成和Bug跟踪系统,以便掌握所有信息. 从管理者的角度来看: Allure提供了一个清晰的全局,涵盖了所涵盖的功
-
python+pytest接口自动化参数关联
目录 前言 一.什么是参数关联? 二.有哪些场景? 三.参数关联场景 四.脚本编写 1.在用例中按顺序调用 2. 使用Fixture函数 五. 总结 前言 今天呢,笔者想和大家来聊聊python+pytest接口自动化测试的参数关联,笔者这边就不多说废话了,咱们直接进入正题. 一.什么是参数关联? 参数关联,也叫接口关联,即接口之间存在参数的联系或依赖.在完成某一功能业务时,有时需要按顺序请求多个接口,此时在某些接口之间可能会存在关联关系.比如:B接口的某个或某些请求参数是通过调用A接口获取的,
-
python单元测试框架pytest介绍
pytest是python语言中一款强大的单元测试框架,用来管理和组织测试用例,可应用在单元测试.自动化测试工作中. unittest也是python语言中一款单元测试框架,但是功能有限,没有pytest灵活. 就像:苹果电脑mac air和mac pro一样.都是具备同样的功能,但是好用,和更好用. 本文包含以下几个内容点: 1)pytest的简单示例 2)pytest的安装 3)pytest的特征.与unittest的区别. 4) pytest如何自动识别用例. 5)pytest框架中,用例
-
pytest多进程或多线程执行测试实例
目录 前言: 分布式执行用例的原则: 项目结构 测试脚本 多进程执行用例之pytest-xdist pytest-xdist分布式测试的原理: pytest-xdist分布式测试的流程: 第一步:master创建worker 第二步:workers收集测试项用例 第三步:master检测workers收集到的测试用例集 第四步:master分发测试用例 第五步:worker执行测试用例 第六步:测试结束 多线程执行用例之pytest-parallel 常用参数配置 pytest-parallel
-
pytest实现多进程与多线程运行超好用的插件
目录 前言 一.pytest-parallel 二.pytest-xdist 三.对比说明 四.特别注意 前言 如果想分布式执行用例,用例设计必须遵循以下原则: 1.用例之间都是独立的,2.用例a不要去依赖用例b3.用例执行没先后顺序,4.随机都能执行每个用例都能独立运行成功每个用例都能重复运行,不影响其它用例这跟就我们平常多个人工测试一样,用例都是独立的,可以随机分配不同人员执行,互相不依赖,用例之间也不存在先后顺序 一.pytest-parallel 安装:pip install pytes
-
python 简单搭建阻塞式单进程,多进程,多线程服务的实例
我们可以通过这样子的方式去理解apache的工作原理 1 单进程TCP服务(堵塞式) 这是最原始的服务,也就是说只能处理个客户端的连接,等当前客户端关闭后,才能处理下个客户端,是属于阻塞式等待 from socket import * serSocket = socket(AF_INET, SOCK_STREAM) #重复使用绑定的信息 serSocket.setsockopt(SOL_SOCKET, SO_REUSEADDR , 1) localAddr = ('', 7788) serSoc
-
Python多进程并发与多线程并发编程实例总结
本文实例总结了Python多进程并发与多线程并发.分享给大家供大家参考,具体如下: 这里对python支持的几种并发方式进行简单的总结. Python支持的并发分为多线程并发与多进程并发(异步IO本文不涉及).概念上来说,多进程并发即运行多个独立的程序,优势在于并发处理的任务都由操作系统管理,不足之处在于程序与各进程之间的通信和数据共享不方便:多线程并发则由程序员管理并发处理的任务,这种并发方式可以方便地在线程间共享数据(前提是不能互斥).Python对多线程和多进程的支持都比一般编程语言更高级
-
java利用Future实现多线程执行与结果聚合实例代码
目录 场景 解决 总结 场景 网站智能问答场景,需要对多个分类查询,结果聚合展示 由于每种分类都有自己的业务逻辑,有的需要查询数据库中间库,有的需要查询elasticsearch搜索引擎,有的需要调用第三方接口,数据查询要分开进行,没法一次查询搞定 实际上这几个查询不相关,可以同时进行,现在串行,使该场景下,智能问答返回较慢 解决 最简单的逻辑,肯定就是java多线程,将串行改为并行 这样查询返回时间,就取决于最慢的一个查询,返回时间大大缩短 页面返回一般要求三秒内,实际项目上我们要求1秒内返回
-
Python实现的多进程和多线程功能示例
本文实例讲述了Python实现的多进程和多线程功能.分享给大家供大家参考,具体如下: 听了朋友说起,他们目前开发的测试框架,用python实现的分布式系统.虽然python的执行效率没有c和c++那么高,但是依靠集群的力量,产生的压力很是牛逼啊. 了解了下大概的方式就是 1.有台主控机,负责调度,比如执行的参数等 2.有n多台执行机,每个执行机上部署一个python的xmlRPC server,主控机调用rpccall,然后执行机执行.rpccall里面会fork一些进程,每个进程再创建一些线程
-
python多进程和多线程究竟谁更快(详解)
python3.6 threading和multiprocessing 四核+三星250G-850-SSD 自从用多进程和多线程进行编程,一致没搞懂到底谁更快.网上很多都说python多进程更快,因为GIL(全局解释器锁).但是我在写代码的时候,测试时间却是多线程更快,所以这到底是怎么回事?最近再做分词工作,原来的代码速度太慢,想提速,所以来探求一下有效方法(文末有代码和效果图) 这里先来一张程序的结果图,说明线程和进程谁更快 一些定义 并行是指两个或者多个事件在同一时刻发生.并发是指两个或多个
-
Python 多进程、多线程效率对比
Python 界有条不成文的准则: 计算密集型任务适合多进程,IO 密集型任务适合多线程.本篇来作个比较. 通常来说多线程相对于多进程有优势,因为创建一个进程开销比较大,然而因为在 python 中有 GIL 这把大锁的存在,导致执行计算密集型任务时多线程实际只能是单线程.而且由于线程之间切换的开销导致多线程往往比实际的单线程还要慢,所以在 python 中计算密集型任务通常使用多进程,因为各个进程有各自独立的 GIL,互不干扰. 而在 IO 密集型任务中,CPU 时常处于等待状态,操作系统需要
-
python 多进程和多线程使用详解
进程和线程 进程是系统进行资源分配的最小单位,线程是系统进行调度执行的最小单位: 一个应用程序至少包含一个进程,一个进程至少包含一个线程: 每个进程在执行过程中拥有独立的内存空间,而一个进程中的线程之间是共享该进程的内存空间的: 计算机的核心是CPU,它承担了所有的计算任务.它就像一座工厂,时刻在运行. 假定工厂的电力有限,一次只能供给一个车间使用.也就是说,一个车间开工的时候,其他车间都必须停工.背后的含义就是,单个CPU一次只能运行一个任务.编者注: 多核的CPU就像有了多个发电厂,使多工厂
-
php数据序列化测试实例详解
php数据序列化测试实例详解 测试代码 $msg = ['test'=>23]; $start = microtime(true); for($i=0;$i<100000;$i++){ $packMsg = msgpack_pack($msg); } echo 'pack len:'.strlen($packMsg)."\r\n"; $end = microtime(true); echo 'run time:'.($end-$start).'s'."\r\n&q