R语言求一行(列表、list)数据的平均数操作
R语言求一个列表的平均数可以使用mean() :
mean英文意思有平均数的含义
x=c(1,3,5,7,9) max(x) #这样即可求得平均数为 : 5
假如读取过一个csv文件之后,要求其中一行数据中指定某个区间内的平均数可以使用rowMeans()

data = read.csv(“input.csv",sep=",",header=T) rowMeans(data[10:17])
补充:R语言-数据框分组求平均值
【技术关键】
1、从excel把数据读到数据框
2、算法实现将数据框的一些数据合为新的数据并组成新的数据框
3、将处理结果,即新的数据框保存到excel文件(或.csv)
4、将绘图结果输出到PDF文件保存
最近在尝试分析近日的环境温湿度变化;
虽然设备只运行了48小时左右;
但收集到的有效数据有30000+(当然对于R而言这算很小意思的了);
由于环境温湿度在一小段时间内基本保持稳定;
所以在分析几日内的温湿度变化情况时可以以每10min为单位记录数据;
这就需要一个脚本,能将数据有效划分为单位后求均值再保存到表;
###################################################
# - Filename : washData.R
# - Author : Johan Version : 1.0 Date : 2018/5/3
# - Discription : 将excel表中的数据分10min计算平均值
# 并保存到excel
# - Function list :
# 1.
# - Others :
# 1.本程序可分析.xls或.csv文件
###################################################
# 引用包
library(RODBC)
# 设置工作目录
setwd("H:/mySoftware/R/myData")
# 导入数据到myDataFrame,文件名根据需要改变
# 打开th_record2.xls,并读取表Sheet1
channel <- odbcConnectExcel2007("th_record2.xls")
myDataFrame <- sqlFetch(channel, "Sheet1")
odbcClose(channel)
# 为myDataFrame增加列名
dataColName <- c("temp","humi","time","year","month","day","hour","minute","second")
names(myDataFrame) <- dataColName
# 初始化缓存向量
# 时分秒为起始量,可修改
NUM <- c() # 编号
TEMP <- c() # 温度
HUMI <- c() # 湿度
t <- 0 # 温度缓存
h <- 0 # 湿度缓存
num <- 0 # 编号缓存
dn <- 0 # 计数器
flag <- FALSE # 保存指示
# 循环处理数据
for(i in 1 : 31600){
# 当前分钟是否为10的倍数
if(myDataFrame$minute[i] %% 10 == 0){
# 计算上一组数据的均值并保存
if(flag){
t <- t / dn
h <- h / dn
TEMP <- c(TEMP, t)
HUMI <- c(HUMI, h)
num <- num + 1
NUM <- c(NUM, num)
flag <- FALSE
}
# 缓存复位
dn <- 0
t <- 0
h <- 0
# 添加记录
t <- t + myDataFrame$temp[i]
h <- h + myDataFrame$humi[i]
dn <- dn + 1
}
else{
# 添加记录
t <- t + myDataFrame$temp[i]
h <- h + myDataFrame$humi[i]
dn <- dn + 1
flag <- TRUE
}
}
# 构建新数据框
newFrame <- data.frame(NUM, TEMP, HUMI)
newName <- c("number","temp","humi")
names(newFrame) <- newName
# 写入.csv文件
write.csv(newFrame, "new_th_record.csv")
# 绘图
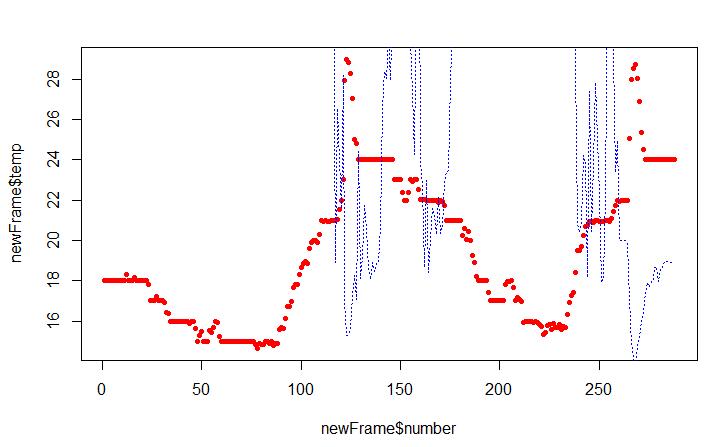
plot(newFrame$number, newFrame$temp, pch=20, lty=3, col="red")
lines(newFrame$number, newFrame$humi, pch=20, lty=3, col="blue")
把处理结果保存到新的.csv或者.xls文件即是整个脚本的目的所在,方便后面的数据分析。
运行后得到的效果如下:(由于温湿度的数值不在一个层次所以反映得不太直观,可尝试调换plot和lines的顺序,通过绘图方面的学习可以画出更好看的图)
如果想要输出为PDF保存该图片,可以运行另一个脚本:
pdf("new_th_record.pdf")
plot(newFrame$number, newFrame$humi, pch=20, lty=3, col="blue")
lines(newFrame$number, newFrame$temp, pch=20, lty=3, col="red")
dev.off()
PDF文件的一个好处就是它里面的图片是矢量的,也就是说放大图片不会改变图片的原样,原本看上去粘在一块儿的点放大以后能看出来是分开的。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言属性知识点总结及实例
属性(attribute):R中对象具备的特性 特性描述了所代表的内容以及R解释该对象的方式 很多时候两个对象之间的唯一差别在于它们的属性不同 常见的属性 属性 描述 class 对象的类 comment 对象的注释,一般用于描述对象的含义 dim 对象的维度 dimnames 与对象的每个维度相关的名字 names 返回对象的名字属性.返回结果取决于对象的类型.对于数据框对象会返回数据框的列名;对于数组会返回数组中被命名元素的名字 row,names 对象的行名(dimnames相关) tsp
-
R语言符号知识点汇总
符号 当在R中定义一个变量时,实际上就是在环境中将一个符号赋给一个值 x <- 1 实际上就是在全局环境中将符号x赋给一个长度为1,值为1的向量对象 当R解释器对表达式求值时,它会处理所有的符号 如果将若干个符号组合成一个对象,R会解析成该对象的每个符号 > x <- 1 > y <- 2 > z <- 3 > > (v <- c(x, y, z)) [1] 1 2 3 > > #由于v已定义,更改x的值并不会使v的值也相应变化 &g
-

详解R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计
MCMC是从复杂概率模型中采样的通用技术. 蒙特卡洛 马尔可夫链 Metropolis-Hastings算法 问题 如果需要计算有复杂后验pdf p(θ| y)的随机变量θ的函数f(θ)的平均值或期望值. 您可能需要计算后验概率分布p(θ)的最大值. 解决期望值的一种方法是从p(θ)绘制N个随机样本,当N足够大时,我们可以通过以下公式逼近期望值或最大值 将相同的策略应用于通过从p(θ| y)采样并取样本集中的最大值来找到argmaxp(θ| y). 解决方法 1.1直接模拟 1.2逆CDF 1.
-
R语言向量知识点及实例讲解
有常见的六种基本的向量类型 创建向量 设定recursive = T,c函数可以从其他数据结构中递归形成向量 > v <- c(.295, .300, .250, .287, list(.102, .200, .303), recursive = T) > v [1] 0.295 0.300 0.250 0.287 0.102 0.200 0.303 > typeof(v) [1] "double" > v <- c(.295, .300, .250
-
R语言基本语法知识点
我们将开始学习R语言编程,首先编写一个"你好,世界! 的程序. 根据需要,您可以在R语言命令提示符处编程,也可以使用R语言脚本文件编写程序.让我们逐个体验不同之处. 命令提示符 如果你已经配置好R语言环境,那么你只需要按一下的命令便可轻易开启命令提示符 $ R 这将启动R语言解释器,你会得到一个提示 > 在那里你可以开始输入你的程序,具体如下. > myString <- "Hello, World!" > print ( myString) [1]
-
R语言中其它对象知识点总结
其他对象 矩阵 二维向量 矩阵操作更类似于向量,而不是向量的向量或者向量列表 下标可以用用来引用元素,但并不反应矩阵的存储方式 矩阵没有一个确定的属性 数组 具有两个以上维度的向量 数组可用来表示多个维度的同类型数据 数组的底层存储机制是向量 数组也没有确定的类属性 因子 因子型变量表示分类信息 因子型变量通常是一个有序项目的集合 因子型变量可以取得的所有值被称为因子水平 因子型变量的输出结果中各个因子水平没有加引号,且都明确显示出来了 > (eye.colors <- factor(c(&q
-
R语言时间序列知识点总结
时间序列对象:变量随着时间变化 时间序列的回归函数(例如ar或arima)通常以时间序列作为参数 许多绘图函数都有针对时间序列对象的特殊方法 ts函数创建时间序列对象 ts(data = NA, start = 1, end = numeric(0), frequency = 1, deltat = 1, ts.eps = getOption("ts.eps"), class = , names = ) data参数指定时间序列的观测值,其他参数指定观测值的起始区间 ts函数参数的含义
-
R语言数据类型知识点总结
通常,在使用任何编程语言进行编程时,您需要使用各种变量来存储各种信息. 变量只是保留值的存储位置. 这意味着,当你创建一个变量,你必须在内存中保留一些空间来存储它们. 您可能想存储各种数据类型的信息,如字符,宽字符,整数,浮点,双浮点,布尔等.基于变量的数据类型,操作系统分配内存并决定什么可以存储在保留内存中. 与其他编程语言(如 C 中的 C 和 java)相反,变量不会声明为某种数据类型. 变量分配有 R 对象,R 对象的数据类型变为变量的数据类型.尽管有很多类型的 R 对象,但经常使用的是
-
R语言求一行(列表、list)数据的平均数操作
R语言求一个列表的平均数可以使用mean() : mean英文意思有平均数的含义 x=c(1,3,5,7,9) max(x) #这样即可求得平均数为 : 5 假如读取过一个csv文件之后,要求其中一行数据中指定某个区间内的平均数可以使用rowMeans() data = read.csv("input.csv",sep=",",header=T) rowMeans(data[10:17]) 补充:R语言-数据框分组求平均值 [技术关键] 1.从excel把数据读到数
-
R语言中矩阵matrix和数据框data.frame的使用详解
本文主要介绍了R语言中矩阵matrix和数据框data.frame的一些使用,分享给大家,具体如下: "一,矩阵matrix" "创建向量" x_1=c(1,2,3) x_1=c(1:3) x_2=1:3 typeof(x_1)==typeof(x_2)#查看目标类型 x_3=seq(1,6,length=3)#将1--6分为3个数 a<-rep(1:3,each=3) #1到3依次重复 c<-rep(1:3,times=3) #1到3重复3次 d<
-
R语言变量重编码、重命名的操作
1.变量重编码 重编码涉及根据同一个变量和/或其他变量的现有值创建新值的过程,如将符合某个条件的值重新赋值等,这里主要介绍两种常见的方法: #第一种方法 per <- data.frame(name = c("张三","李四","王五","赵六"), age = c(23,45,34,1000)) per per$age[per$age == 1000] <- NA #设置缺失值 per$age1[per$age
-
R语言与格式,日期格式,格式转化的操作
R语言的基础包中提供了两种类型的时间数据,一类是Date日期数据,它不包括时间和时区信息,另一类是POSIXct/POSIXlt类型数据,其中包括了日期.时间和时区信息. 基本总结如下: 日期data,存储的是天: 时间POSIXct 存储的是秒,POSIXlt 打散,年月日不同: 日期-时间=不可运算. 一般来讲,R语言中建立时序数据是通过字符型转化而来,但由于时序数据形式多样,而且R中存贮格式也是五花八门,例如Date/ts/xts/zoo/tis/fts等等.lubridate包(后续有介
-
R语言之左连接的三种实现操作
数据处理中经常遇到表连接问题,本次介绍R语言中三种左连接方法,这三种是等价的,不过会有时间快慢问题,斟酌使用. 法一: > data0 <- merge(a,c,all.x=TRUE,by='CELLPHONE') 法二: > data1 <- sqldf('select a.*,b.* from a left join c on a.CELLPHONE=c.CELLPHONE') 法三: > data2 <- c[a,on='CELLPHONE'] 注意:第三种方法的
-
R语言数值取消科学计数法表示的操作
我就废话不多说了,大家还是直接看代码吧~ >#取消科学计数法 >options(scipen = 200) >#scipen 表示在200个数字以内都不使用科学计数法 补充:R语言去除科学计数法 保留小数位 R语言 去除科学计数法 保留小数位 options("scipen"=100, "digits"=4) 补充:R语言科学计数法数据改变/丢失/失准,取消科学计数法的原因和解决方法 问题描述 如何在R中取消科学计数法 & 对R中使用科学技
-
R语言 设置ylab每个汉字竖向排列的操作
只看标题可能不知道啥意思,所以先上图了. 从图中可以看到ylab中汉字的排列方式是从上到下的,要实现这样的效果有两个关键步骤: 一是ylab不是常规的"月工作量",而是'月\n工\n作\n量',每个汉字中间要进行换行. 二是要对ylab进行旋转. 下面给出代码: library(ggplot2) #数据 df <- data.frame( gp = factor(rep(letters[1:3], each = 10)), y = rnorm(30) ) #ggplot绘制 p0
-
R语言 实现手动设置xy轴刻度的操作
在R中,plot函数作图时会自动给出xy轴的刻度标度,如下图: 有时我们需要自己定义xy轴的刻度,这时我们可以用axis中的at和labels参数来更改. 首先,我们先令plot不要画出xy轴的标度 然后,用axis函数设置xy轴的刻度 这样xy轴的刻度就完全按照我们自己的意愿显示了,也可以设置at参数不是均匀的,总之,用这两个参数就可以完全自己控制xy轴的刻度显示了 补充:R语言自定义坐标轴示例 我就废话不多说了,大家还是直接看代码吧~ x <- c(1:10) y <- x z <-
-
R语言 实现在循环中输出图片的操作
今天在循环导出图片时,遇到了一个问题: 使用R语言导出图片的代码: setwd("E://R") jpeg(file="A.jpeg") print(plot(PEO$X, PEO$Y, pch=PEO$S)) dev.off() 但是若是将此代码运用到循环之中,则只会出来一张图A.jpeg 想了好久原因,发现--..!!!! 命名方法不对啊!!! 只有一个名字!!!当然不行啊!!! 于是搜索如何循环命名- 找到了老朋友paste() yourfilename=pa
-
R语言利用caret包比较ROC曲线的操作
说明 我们之前探讨了多种算法,每种算法都有优缺点,因而当我们针对具体问题去判断选择那种算法时,必须对不同的预测模型进行重做评估. 为了简化这个过程,我们使用caret包来生成并比较不同的模型与性能. 操作 加载对应的包与将训练控制算法设置为10折交叉验证,重复次数为3: library(ROCR) library(e1071) library("pROC") library(caret) library("pROC") control = trainControl(