使用Selenium实现微博爬虫(预登录、展开全文、翻页)
前言
在CSDN发的第一篇文章,时隔两年,终于实现了爬微博的自由!本文可以解决微博预登录、识别“展开全文”并爬取完整数据、翻页设置等问题。由于刚接触爬虫,有部分术语可能用的不正确,请大家多指正!
一、区分动态爬虫和静态爬虫
1、静态网页
静态网页是纯粹的HTML,没有后台数据库,不含程序,不可交互,体量较少,加载速度快。静态网页的爬取只需四个步骤:发送请求、获取相应内容、解析内容及保存数据。
2、动态网页
动态网页上的数据会随时间及用户交互发生变化,因此数据不会直接呈现在网页源代码中,数据将以Json的形式保存起来。因此,动态网页比静态网页多了一步,即需渲染获得相关数据。
3、区分动静态网页的方法
加载网页后,点击右键,选中“查看网页源代码”,如果网页上的绝大多数字段都出现源代码中,那么这就是静态网页,否则是动态网页。

二、动态爬虫的两种方法
1.逆向分析爬取动态网页
适用于调度资源所对应网址的数据为json格式,Javascript的触发调度。主要步骤是获取需要调度资源所对应的网址-访问网址获得该资源的数据。(此处不详细讲解)
2.使用Selenium库爬取动态网页
使用Selenium库,该库使用JavaScript模拟真实用户对浏览器进行操作。本案例将使用该方法。
三、安装Selenium库及下载浏览器补丁
1.Selenium库使用pip工具进行安装即可。
2.下载与Chrome浏览器版本匹配的浏览器补丁。
Step1:查看Chrome的版本

Step2:去下载相应版本的浏览器补丁。网址:http://npm.taobao.org/mirrors/chromedriver/
Step3:解压文件,并将之放到与python.exe同一文件下

四、页面打开及预登录
1.导入selenium包
from selenium import webdriver from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By import time import pandas as pd
2.打开页面
driver = webdriver.Chrome()
print('准备登陆Weibo.cn网站...')
#发送请求
driver.get("https://login.sina.com.cn/signup/signin.php")
wait = WebDriverWait(driver,5)
#重要:暂停1分钟进行预登陆,此处填写账号密码及验证
time.sleep(60)
3.采用交互式运行,运行完上面两段程序,会弹出一个框,这个框就是用来模拟网页的交互。在这个框中完成登录(包括填写登录名、密码及短信验证等)

4.完成预登录,则进入个人主页

五、关键词搜索操作
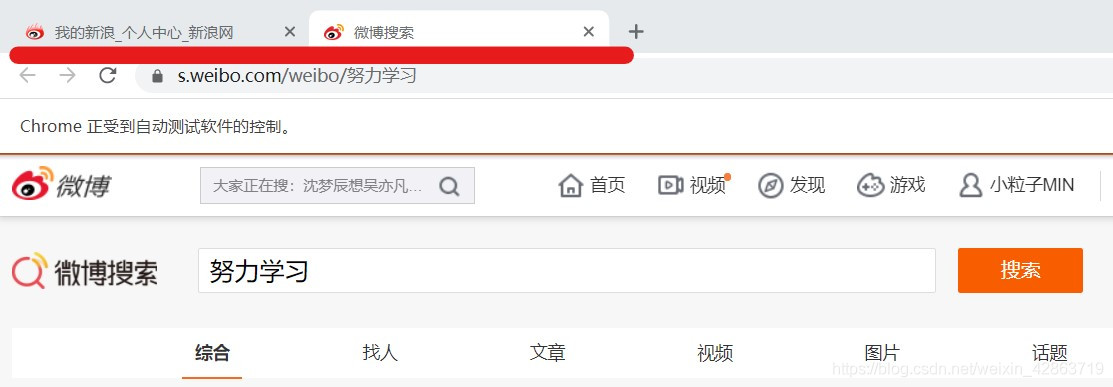
1.定位上图中的关键词输入框,并在框中输入搜索对象,如“努力学习”
#使用selector去定位关键词搜索框
s_input = driver.find_element_by_css_selector('#search_input')
#向搜索框中传入字段
s_input.send_keys("努力学习")
#定位搜索键
confirm_btn = driver.find_element_by_css_selector('#search_submit')
#点击
confirm_btn.click()
2.当完成上步的代码运行后,会弹出新的窗口,从个人主页跳到微博搜索页。但是driver仍在个人主页,需要人为进行driver的移动,将之移动到微博搜索页。
3.使用switch_to.window()方法移位
#人为移动driver driver.switch_to.window(driver.window_handles[1])
六、识别“展开全文”并爬取数据
1.了解每个元素的Selector,用以定位(重点在于唯一标识性)

2.使用Selector定位元素,并获取相应的数据
comment = []
username = []
#抓取节点:每个评论为一个节点(包括用户信息、评论、日期等信息),如果一页有20条评论,那么nodes的长度就为20
nodes = driver.find_elements_by_css_selector('div.card > div.card-feed > div.content')
#对每个节点进行循环操作
for i in range(0,len(nodes),1):
#判断每个节点是否有“展开全文”的链接
flag = False
try:
nodes[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").is_displayed()
flag = True
except:
flag = False
#如果该节点具有“展开全文”的链接,且该链接中的文字是“展开全文c”,那么点击这个要素,并获取指定位置的文本;否则直接获取文本
#(两个条件需要同时满足,因为该selector不仅标识了展开全文,还标识了其他元素,没有做到唯一定位)
if(flag and nodes[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").text.startswith('展开全文c')):
nodes[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").click()
comment.append(nodes[i].find_element_by_css_selector('p[node-type="feed_list_content_full"]').text)
else:
comment.append(nodes[i].find_element_by_css_selector('p[node-type="feed_list_content"]').text)
username.append(nodes[i].find_element_by_css_selector("div.info>div:nth-child(2)>a").text)
七、设置翻页
1.使用for循环实现翻页,重点在于识别“下一页”按钮,并点击它
for page in range(49):
print(page)
# 定位下一页按钮
nextpage_button = driver.find_element_by_link_text('下一页')
#点击按键
driver.execute_script("arguments[0].click();", nextpage_button)
wait = WebDriverWait(driver,5)
#与前面类似
nodes1 = driver.find_elements_by_css_selector('div.card > div.card-feed > div.content')
for i in range(0,len(nodes1),1):
flag = False
try:
nodes1[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").is_displayed()
flag = True
except:
flag = False
if (flag and nodes1[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").text.startswith('展开全文c')):
nodes1[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").click()
comment.append(nodes1[i].find_element_by_css_selector('p[node-type="feed_list_content_full"]').text)
else:
comment.append(nodes1[i].find_element_by_css_selector('p[node-type="feed_list_content"]').text)
username.append(nodes1[i].find_element_by_css_selector("div.info>div:nth-child(2)>a").text)
八、保存数据
1.使用DataFrame保存字段
data = pd.DataFrame({'username':username,'comment':comment})

2.导出到Excel
data.to_excel("weibo.xlsx")
九、完整代码
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import time
import pandas as pd
'''打开网址,预登陆'''
driver = webdriver.Chrome()
print('准备登陆Weibo.cn网站...')
#发送请求
driver.get("https://login.sina.com.cn/signup/signin.php")
wait = WebDriverWait(driver,5)
#重要:暂停1分钟进行预登陆,此处填写账号密码及验证
time.sleep(60)
'''输入关键词到搜索框,完成搜索'''
#使用selector去定位关键词搜索框
s_input = driver.find_element_by_css_selector('#search_input')
#向搜索框中传入字段
s_input.send_keys("努力学习")
#定位搜索键
confirm_btn = driver.find_element_by_css_selector('#search_submit')
#点击
confirm_btn.click()
#人为移动driver
driver.switch_to.window(driver.window_handles[1])
'''爬取第一页数据'''
comment = []
username = []
#抓取节点:每个评论为一个节点(包括用户信息、评论、日期等信息),如果一页有20条评论,那么nodes的长度就为20
nodes = driver.find_elements_by_css_selector('div.card > div.card-feed > div.content')
#对每个节点进行循环操作
for i in range(0,len(nodes),1):
#判断每个节点是否有“展开全文”的链接
flag = False
try:
nodes[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").is_displayed()
flag = True
except:
flag = False
#如果该节点具有“展开全文”的链接,且该链接中的文字是“展开全文c”,那么点击这个要素,并获取指定位置的文本;否则直接获取文本
#(两个条件需要同时满足,因为该selector不仅标识了展开全文,还标识了其他元素,没有做到唯一定位)
if(flag and nodes[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").text.startswith('展开全文c')):
nodes[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").click()
comment.append(nodes[i].find_element_by_css_selector('p[node-type="feed_list_content_full"]').text)
else:
comment.append(nodes[i].find_element_by_css_selector('p[node-type="feed_list_content"]').text)
username.append(nodes[i].find_element_by_css_selector("div.info>div:nth-child(2)>a").text)
'''循环操作,获取剩余页数的数据'''
for page in range(49):
print(page)
# 定位下一页按钮
nextpage_button = driver.find_element_by_link_text('下一页')
#点击按键
driver.execute_script("arguments[0].click();", nextpage_button)
wait = WebDriverWait(driver,5)
#与前面类似
nodes1 = driver.find_elements_by_css_selector('div.card > div.card-feed > div.content')
for i in range(0,len(nodes1),1):
flag = False
try:
nodes1[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").is_displayed()
flag = True
except:
flag = False
if (flag and nodes1[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").text.startswith('展开全文c')):
nodes1[i].find_element_by_css_selector("p>a[action-type='fl_unfold']").click()
comment.append(nodes1[i].find_element_by_css_selector('p[node-type="feed_list_content_full"]').text)
else:
comment.append(nodes1[i].find_element_by_css_selector('p[node-type="feed_list_content"]').text)
username.append(nodes1[i].find_element_by_css_selector("div.info>div:nth-child(2)>a").text)
'''保存数据'''
data = pd.DataFrame({'username':username,'comment':comment})
data.to_excel("weibo.xlsx")
到此这篇关于使用Selenium实现微博爬虫(预登录、展开全文、翻页)的文章就介绍到这了,更多相关Selenium 微博爬虫 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python selenium实现智联招聘数据爬取
一.主要目的 最近在玩Python网络爬虫,然后接触到了selenium这个模块,就捉摸着搞点有意思的,顺便记录一下自己的学习过程. 二.前期准备 操作系统:windows10 浏览器:谷歌浏览器(Google Chrome) 浏览器驱动:chromedriver.exe (我的版本->89.0.4389.128 ) 程序中我使用的模块 import csv import os import re import json import time import requests from sele
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=
-
基于python requests selenium爬取excel vba过程解析
目的:基于办公与互联网隔离,自带的office软件没有带本地帮助工具,因此在写vba程序时比较不方便(后来发现07有自带,心中吐血,瞎折腾些什么).所以想到通过爬虫在官方摘录下来作为参考. 目标网站:https://docs.microsoft.com/zh-cn/office/vba/api/overview/ 所使工具: python3.7,requests.selenium库 前端方面:使用了jquery.jstree(用于方便的制作无限层级菜单 设计思路: 1.分析目标页面,可分出两部分
-
Python + selenium + requests实现12306全自动抢票及验证码破解加自动点击功能
测试结果: 整个买票流程可以再快一点,不过为了稳定起见,有些地方等待了一些时间 完整程序,拿去可用 整个程序分了三个模块:购票模块(主体).验证码识别模块.余票查询模块 购票模块: from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.commo
-
Python+Selenium定位不到元素常见原因及解决办法(报:NoSuchElementException)
在做web应用的自动化测试时,定位元素是必不可少的,这个过程经常会碰到定位不到元素的情况(报selenium.common.exceptions.NoSuchElementException),一般可以从以下几个方面着手解决: 1.Frame/Iframe原因定位不到元素: 这个是最常见的原因,首先要理解下frame的实质,frame中实际上是嵌入了另一个页面,而webdriver每次只能在一个页面识别,因此需要先定位到相应的frame,对那个页面里的元素进行定位. 解决方案: 如果iframe
-
python+selenium小米商城红米K40手机自动抢购的示例代码
使用环境 1.python3 2.selenium selenium使用简述 1.安装selenium pip install selenium 2.安装ChromeDriver 下载地址:http://chromedriver.storage.googleapis.com/index.html 注意:下载的ChromeDriver需要与Chrome版本一致. 1)Chrome版本查看: 2)ChromeDriver对应版本下载: 3)ChromeDriver下载后解压到任意文件夹,建议可以放到
-
如何使用selenium和requests组合实现登录页面
这篇文章主要介绍了如何使用selenium和requests组合实现登录页面,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.在这里selenium的作用 (1)模拟的登录. (2)获取登录成功之后的cookies 代码 def start_login(self): chrome_options = Options() # 禁止图片加载,禁止推送通知 prefs = { "profile.default_content_setting_val
-
使用Selenium实现微博爬虫(预登录、展开全文、翻页)
前言 在CSDN发的第一篇文章,时隔两年,终于实现了爬微博的自由!本文可以解决微博预登录.识别"展开全文"并爬取完整数据.翻页设置等问题.由于刚接触爬虫,有部分术语可能用的不正确,请大家多指正! 一.区分动态爬虫和静态爬虫 1.静态网页 静态网页是纯粹的HTML,没有后台数据库,不含程序,不可交互,体量较少,加载速度快.静态网页的爬取只需四个步骤:发送请求.获取相应内容.解析内容及保存数据. 2.动态网页 动态网页上的数据会随时间及用户交互发生变化,因此数据不会直接呈现在网页源代码中,
-
Python selenium实现微博自动登录的示例代码
(一)编程环境 操作系统:Win 10 编程语言:Python 3.6 (二)安装selenium 这里使用selenium实现. 如果没有安装过python的selenium库,则安装命令如下 pip install selenium (三)下载ChromeDriver 因为selenium要用到浏览器的驱动,这里我用的是Google Chrome浏览器,所以要先下载ChromeDriver.exe并放到C:\Program Files (x86)\Google\Chrome\Applicat
-
用Python编写简单的微博爬虫
先说点题外话,我一开始想使用Sina Weibo API来获取微博内容,但后来发现新浪微博的API限制实在太多,大家感受一下: 只能获取当前授权的用户(就是自己),而且只能返回最新的5条,WTF! 所以果断放弃掉这条路,改为『生爬』,因为PC端的微博是Ajax的动态加载,爬取起来有些困难,我果断知难而退,改为对移动端的微博进行爬取,因为移动端的微博可以通过分页爬取的方式来一次性爬取所有微博内容,这样工作就简化了不少. 最后实现的功能: 1.输入要爬取的微博用户的user_id,获得该用户的所有微
-
Selenium实现微博自动化运营之关注、点赞、评论功能
Selenium 是什么? Selenium是一个用于Web应用程序测试的工具,可以模拟真正的用户操作,支持多种浏览器,如Firefox,Safari,Google Chrome,Opera等. Selenium 模拟的就是一个真实的用户的操作行为,我们完全不用担心 cookie 追踪和隐藏字段的干扰. 除了Selenium 外,还有Puppeteer 工具可以模拟用户操作,Python + Selenium + 第三方浏览器可以让我们处理多种复杂场景,包括网页动态加载.JS 响应.Post 表
-
Python3+selenium实现cookie免密登录的示例代码
进过两天的研究终于实现了cookie的免密登录,其实就是session.特别开心,因为在Python爬虫群里问那些大佬,可是他们的回答令我寒心,自己琢磨!!! 靠谁比如靠自己,为此我总结下经验,以免入门的小白再次踩这样的吭.其实网上很多博客写的都比较不详细甚 首先问题自己思考,不懂得去群里问问,然后最重要的要理解事物的本质,只有理解后才能运用它:最后在百度一下把所有相关的博客都点开,一条一条的看一遍总结下规律,比较喽的就舍弃,这样基本上都能得到启发作用.比如selenium的本质就是操作浏览器的
-
selenium 与 chrome 进行qq登录并发邮件操作实例详解
selenium 与 chrome 进行qq登录并发邮件操作实例详解 出现的问题: qq邮箱各种iframe需要切换,延时是必须的,通过各种方法找元素,qq邮件正文的iframe name是变化的,其他几种方法都不行,最后居然用这样搞定.o[0].click() , o[0].send_keys("abc"),还得再研究研究!!! 备注:已经在机器上登录过QQ客户端,XXXX是发送QQ号,YYYYY是接受QQ号 from selenium import webdriver import
-
python利用selenium进行浏览器爬虫
前言 相信大家刚开始在做爬虫的时候,是不是requests和sound这两个库来使用,这样确实有助于我们学习爬虫的知识点,下面来介绍一个算事较复杂的爬虫案例selenium进形打开浏览器爬取网站的信息 导入第三方库 自执行函数 解析信息 保存文件信息 打开浏览器 获取链接信息 执行函数 运行结果 总结 以上所述是小编给大家介绍的python利用selenium进行浏览器爬虫,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持! 如果你觉得本
-
Python+Selenium+phantomjs实现网页模拟登录和截图功能(windows环境)
本文全部操作均在windows环境下 安装 Python Python是一种跨平台的计算机程序设计语言,它可以运行在Windows.Mac和各种Linux/Unix系统上.是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的.大型项目的开发 去Python的官网 www.python.org 下载安装 安装时勾选pip (python包管理工具),同时安装pip python安装好之后,打开命令行工具cmd,输入
-
python+selenium+chromedriver实现爬虫示例代码
下载好所需程序 1.Selenium简介 Selenium是一个用于Web应用程序测试的工具,直接运行在浏览器中,就像真正的用户在操作一样. 2.Selenium安装 方法一:在Windows命令行(cmd)输入pip install selenium即可自动安装,安装完成后,输入pip show selenium可查看当前的版本 方法二:直接下载selenium包: selenium下载网址 Pychome安装selenium如果出现无法安装,参考以下博客 解决Pycharm无法使用已经安装S