浅谈pytorch中的nn.Sequential(*net[3: 5])是啥意思
看到代码里面有这个

1 class ResNeXt101(nn.Module):
2 def __init__(self):
3 super(ResNeXt101, self).__init__()
4 net = resnext101()
# print(os.getcwd(), net)
5 net = list(net.children()) # net.children()得到resneXt 的表层网络
# for i, value in enumerate(net):
# print(i, value)
6 self.layer0 = nn.Sequential(net[:3]) # 将前三层打包0, 1, 2两层
print(self.layer0)
7 self.layer1 = nn.Sequential(*net[3: 5]) # 将3, 4两层打包
8 self.layer2 = net[5]
9 self.layer3 = net[6]
可以看到代码中的第六行(序号自己去掉,我打上去的) self.layer0 = nn.Sequential(net[:3])和
第七行self.layer1 = nn.Sequential(*net[3: 5])
有一个nn.Sequential(net[:3])
和nn.Sequential(*net[3: 5])
今天不讲nn.Sequential()用法,意义,作用因为我也不咋明白。惊天就说*net[3: 5]这个东西为啥要带“ * ”
当代码中不带*的时候,运行会出现以下问题
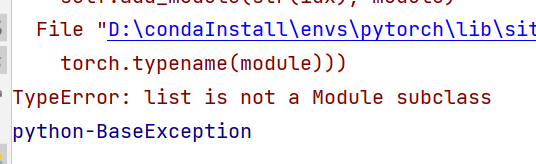
意思就是列表不是子类,就是说参数不对
net = list(net.children())
这一行代码是将模型的每一层取出来构建一个列表,自己试着打印就可以。大概的输出就是[conv(),BatchNorm2d(), ReLU,MaxPool2d]等等

总共是是个元素,和一般的列表不太一样。
当我们取net[:3]的时候,传进去的参数是一个列表,但是我们用*net[:3]的时候传进去的是单个元素
list1 = ["conv", ("relu", "maxing"), ("relu", "maxing", 3), 3]
list2 = [list1[:1]]
list3 = [*list1[:1]]
print("list2:{}, *list1[:2]:{}".format(list1[:1], *list1[:1]))

结果不带✳的是列表,带✳的是元素,所以nn.Sequential(*net[3: 5])中的*net[3: 5]就是给nn.Sequential()这个容器中传入多个层。
到此这篇关于pytorch中的nn.Sequential(*net[3: 5])是啥意思的文章就介绍到这了,更多相关pytorch nn.Sequential(*net[3: 5])内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
对Pytorch中nn.ModuleList 和 nn.Sequential详解
简而言之就是,nn.Sequential类似于Keras中的贯序模型,它是Module的子类,在构建数个网络层之后会自动调用forward()方法,从而有网络模型生成.而nn.ModuleList仅仅类似于pytho中的list类型,只是将一系列层装入列表,并没有实现forward()方法,因此也不会有网络模型产生的副作用. 需要注意的是,nn.ModuleList接受的必须是subModule类型,例如: nn.ModuleList( [nn.ModuleList([Conv(inp_dim
-
![浅谈pytorch中的nn.Sequential(*net[3: 5])是啥意思](/assets/blank.gif)
浅谈pytorch中的nn.Sequential(*net[3: 5])是啥意思
看到代码里面有这个 1 class ResNeXt101(nn.Module): 2 def __init__(self): 3 super(ResNeXt101, self).__init__() 4 net = resnext101() # print(os.getcwd(), net) 5 net = list(net.children()) # net.children()得到resneXt 的表层网络 # for i, value in enumerate(net): # print(
-
浅谈Pytorch中的自动求导函数backward()所需参数的含义
正常来说backward( )函数是要传入参数的,一直没弄明白backward需要传入的参数具体含义,但是没关系,生命在与折腾,咱们来折腾一下,嘿嘿. 对标量自动求导 首先,如果out.backward()中的out是一个标量的话(相当于一个神经网络有一个样本,这个样本有两个属性,神经网络有一个输出)那么此时我的backward函数是不需要输入任何参数的. import torch from torch.autograd import Variable a = Variable(torch.Te
-
浅谈PyTorch中in-place operation的含义
in-place operation在pytorch中是指改变一个tensor的值的时候,不经过复制操作,而是直接在原来的内存上改变它的值.可以把它成为原地操作符. 在pytorch中经常加后缀"_"来代表原地in-place operation,比如说.add_() 或者.scatter().python里面的+=,*=也是in-place operation. 下面是正常的加操作,执行结束加操作之后x的值没有发生变化: import torch x=torch.rand(2) #t
-
浅谈pytorch中torch.max和F.softmax函数的维度解释
在利用torch.max函数和F.Ssoftmax函数时,对应该设置什么维度,总是有点懵,遂总结一下: 首先看看二维tensor的函数的例子: import torch import torch.nn.functional as F input = torch.randn(3,4) print(input) tensor([[-0.5526, -0.0194, 2.1469, -0.2567], [-0.3337, -0.9229, 0.0376, -0.0801], [ 1.4721, 0.1
-
浅谈Pytorch中的torch.gather函数的含义
pytorch中的gather函数 pytorch比tensorflow更加编程友好,所以准备用pytorch试着做最近要做的一些实验. 立个flag开始学习pytorch,新开一个分类整理学习pytorch中的一些踩到的泥坑. 今天刚开始接触,读了一下documentation,写一个一开始每太搞懂的函数gather b = torch.Tensor([[1,2,3],[4,5,6]]) print b index_1 = torch.LongTensor([[0,1],[2,0]]) ind
-
浅谈pytorch中的BN层的注意事项
最近修改一个代码的时候,当使用网络进行推理的时候,发现每次更改测试集的batch size大小竟然会导致推理结果不同,甚至产生错误结果,后来发现在网络中定义了BN层,BN层在训练过程中,会将一个Batch的中的数据转变成正太分布,在推理过程中使用训练过程中的参数对数据进行处理,然而网络并不知道你是在训练还是测试阶段,因此,需要手动的加上,需要在测试和训练阶段使用如下函数. model.train() or model.eval() BN类的定义见pytorch中文参考文档 补充知识:关于pyto
-
浅谈pytorch中的dropout的概率p
最近需要训练一个模型,在优化模型时用了dropout函数,为了减少过拟合. 训练的时候用dropout,测试的时候不用dropout.刚开始以为p是保留神经元的比率,训练设置0.5,测试设置1,loss根本没减小过,全设置成1也是一样的效果,后来就考虑到是不是p设置错了. 上网一搜,果然是的!!!p的含义理解错了!不是保留的,而是不保留的! 具体的代码为: x2 = F.dropout(x1, p) x1是上一层网络的输出,p是需要删除的神经元的比例. 当p=0时,保留全部神经元更新.当p=1时
-
浅谈Pytorch中autograd的若干(踩坑)总结
关于Variable和Tensor 旧版本的Pytorch中,Variable是对Tensor的一个封装:在Pytorch大于v0.4的版本后,Varible和Tensor合并了,意味着Tensor可以像旧版本的Variable那样运行,当然新版本中Variable封装仍旧可以用,但是对Varieble操作返回的将是一个Tensor. import torch as t from torch.autograd import Variable a = t.ones(3,requires_grad=
-
浅谈pytorch中stack和cat的及to_tensor的坑
初入计算机视觉遇到的一些坑 1.pytorch中转tensor x=np.random.randint(10,100,(10,10,10)) x=TF.to_tensor(x) print(x) 这个函数会对输入数据进行自动归一化,比如有时候我们需要将0-255的图片转为numpy类型的数据,则会自动转为0-1之间 2.stack和cat之间的差别 stack x=torch.randn((1,2,3)) y=torch.randn((1,2,3)) z=torch.stack((x,y))#默
-
浅谈pytorch中为什么要用 zero_grad() 将梯度清零
pytorch中为什么要用 zero_grad() 将梯度清零 调用backward()函数之前都要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加. 这样逻辑的好处是,当我们的硬件限制不能使用更大的bachsize时,使用多次计算较小的bachsize的梯度平均值来代替,更方便,坏处当然是每次都要清零梯度. optimizer.zero_grad() output = net(input) loss = loss_f(output, target) los