Python爬取微信读书实现读书免费自由
目录
- 前情提要
- 爬取小说
- 白嫖小说
大家好,我是小五
前情提要
不知道用微信读书的朋友多不多,这里顺便安利一下哈。

我目前看电子书的话基本都是在用微信读书,毕竟白嫖的无限卡真香。
在微信读书上,不仅很多正版的Python书籍电子书可以直接看,还可以在阅读的同时看别人写的标注。
但是无限卡对于小说不太友好,只能阅读开头的章节,后面的章节就需要变相付费了。
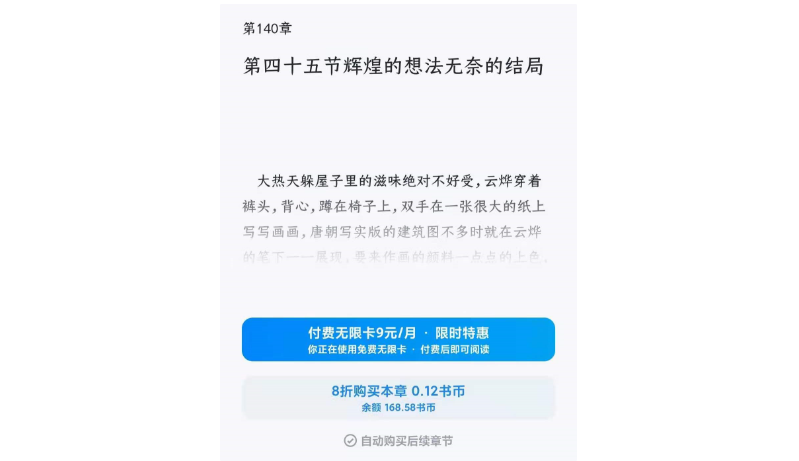
虽然知道番茄小说,七猫小说这种都能免费看,但是实在不愿意为了一部小说再多下一个软件。
幸亏微信读书出了一个功能——可以自己上传书籍,支持支持txt、pdf、epub格式。
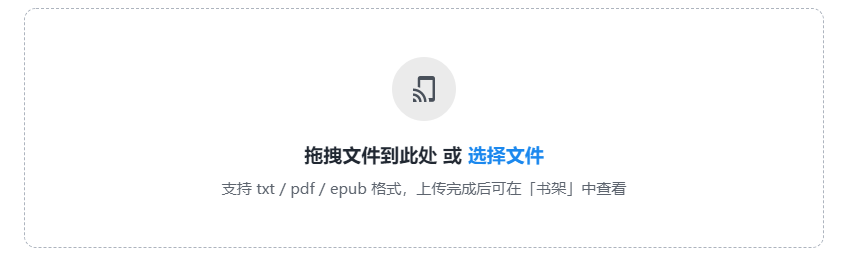
这就给了我一个想法,只需要将小说下载到本地,再导入到微信读书不就成了。
下载小说方法贼简单,用Python也行,搜搜专门打包好的下载器也成。不过我记得两年前刚学Python时自己练习写过笔趣阁的爬虫,这就翻出来用用。
爬取小说
原来代码是找到了,但是很尴尬,我爬取的那个网站404了。
不过目前笔趣阁遍地都是,也分不清到底谁是“正版”的?

还有个比较好的消息,很多家连网页模板都是一模一样,你的爬虫改改地址就能接着用了,这是妙啊。
于是乎,我又随便找了一家“笔趣阁”。

今天我们就以我吃西红柿近期完结的沧元图为例,可以看到在这个笔趣阁网站里,小说沧元图的网址url是
https://*********/html/2292/
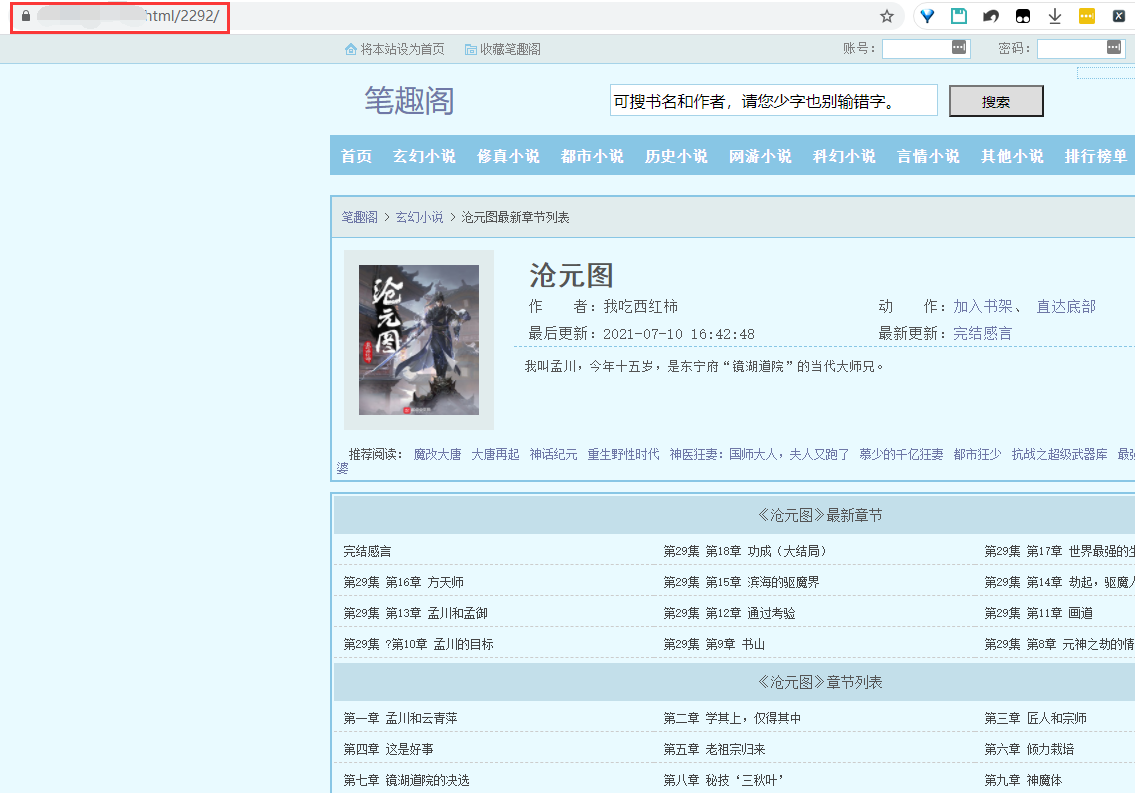
同时,《沧元图》所有的章节也都罗列在本页面。
我觉得先爬取所有的章节名和对应的url网址,分别保存到列表中。然后再使用requests爬取,并依次写入txt文档中。

网页结构并不复杂,也没有反爬措施。大概20行代码即可下载
for i, j in zip(urls, names):
res_text = requests.get(url, headers=header).text
zj_html = etree.HTML(res_text)
texts = zj_html.xpath('//*[@id="content"]/text()')
texts2 = zj_html.xpath('//*[@id="content"]/*/text()')
text = '\n'.join(texts).strip()+'\n'.join(texts2).strip()
with open('novels_n.txt', 'a', encoding='utf8') as f:
f.write(f'{j} \n {text} \n')
print(f'{novels_n}/{j},正在下载...')

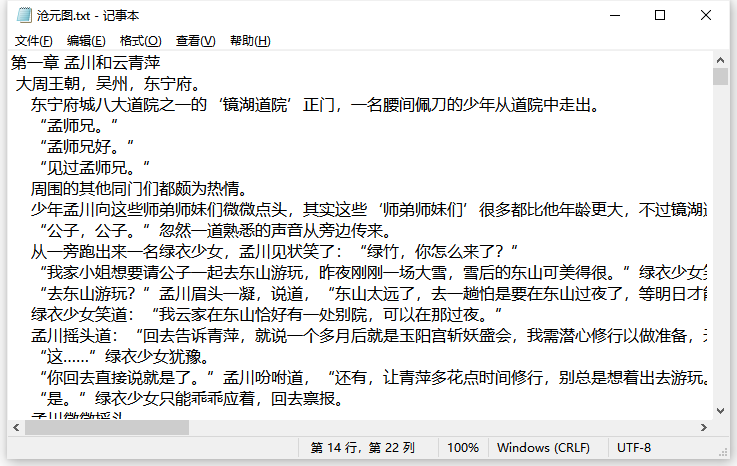
这样我们就爬取了小说《沧元图》,并将它保存成txt文档。
通过\n使得章节名都与正文分割开。
白嫖小说
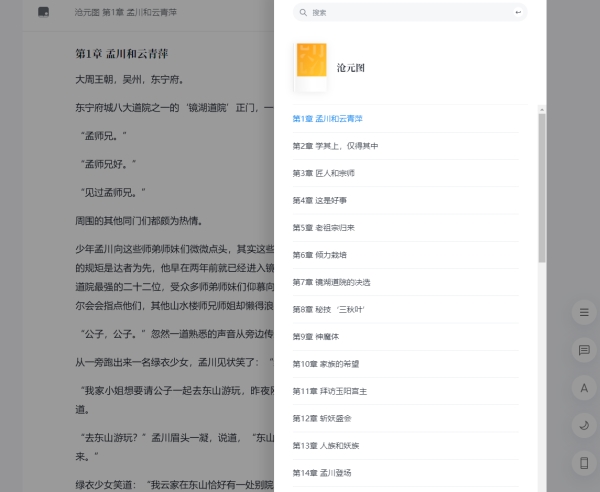
下面的步骤就更简单了,只需要在微信读书的网页版中,点击【传书到手机】,上传刚刚爬取生成的《沧元图》。

导入成功。

单击【立即阅读】,享受一下劳动成果。
整体段落和文字都没什么问题。

再看一下章节目录,也是按照正常的目录进行排版的。
非常完美!
小结
以上,就是我使用Python爬取小说,再导入微信读书,成功白嫖小说阅读的全部步骤了。
这个方法已经用了几个月,白嫖了好几本小说。
赶紧把小技巧分享给大家,快上车吧!
老铁们,如果想看更多Python改变生活的真实问题案例,来给本文右下角点个赞吧
如果你也有一直想去解决的重复性问题,欢迎在评论区告诉我,大家一起探讨一下。
以上就是Python爬取微信读书实现读书免费自由的详细内容,更多关于Python爬取微信读书的资料请关注我们其它相关文章!
相关推荐
-
Python基于requests库爬取网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML 下面这段代码便是爬取百度的信息并简单输出百度的界面信息 import requests from bs4 import BeautifulSoup r=requests.get('http://www.bai
-
33个Python爬虫项目实战(推荐)
今天为大家整理了32个Python爬虫项目. 整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快~O(∩_∩)O WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- 豆瓣读书爬虫.可以爬下豆瓣读书标签下的所有图书,按评分排名依次存储,存储到Excel中,可方便大家筛选搜罗,比如筛选评价人数>1
-
python爬虫爬取网页数据并解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等. 有时,我们比较喜欢的新闻网站可能有几个,每次都要分别
-
selenium+PhantomJS爬取豆瓣读书
本文实例为大家分享了selenium+PhantomJS爬取豆瓣读书的具体代码,供大家参考,具体内容如下 获取关于Python的全部书籍信息: 通过代码测试 request携带'User-Agent'及 'data'数据信息的方式均无法获取到相关信息,获取数据时,部分数据为空,导致获取过程中报错,无法获取全部数据,初步判定豆瓣读书的反爬机制较为严格:通过selenium 模拟浏览器请求的方法测试后发现,可利用 selenium 方法请求获取数据: #导入需要的模块 from selenium i
-

Python爬取微信读书实现读书免费自由
目录 前情提要 爬取小说 白嫖小说 大家好,我是小五 前情提要 不知道用微信读书的朋友多不多,这里顺便安利一下哈. 我目前看电子书的话基本都是在用微信读书,毕竟白嫖的无限卡真香. 在微信读书上,不仅很多正版的Python书籍电子书可以直接看,还可以在阅读的同时看别人写的标注. 但是无限卡对于小说不太友好,只能阅读开头的章节,后面的章节就需要变相付费了. 虽然知道番茄小说,七猫小说这种都能免费看,但是实在不愿意为了一部小说再多下一个软件. 幸亏微信读书出了一个功能--可以自己上传书籍,支持支持tx
-
python爬取微信公众号文章
本文实例为大家分享了python爬取微信公众号文章的具体代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup from requests.exceptions import RequestException import time import random import MySQLdb import threading import socket import math soc
-
python 爬取微信文章
本人想搞个采集微信文章的网站,无奈实在从微信本生无法找到入口链接,网上翻看了大量的资料,发现大家的做法总体来说大同小异,都是以搜狗为入口.下文是笔者整理的一份python爬取微信文章的代码,有兴趣的欢迎阅读 #coding:utf-8 author = 'haoning' **#!/usr/bin/env python import time import datetime import requests** import json import sys reload(sys) sys.setd
-
python爬取微信公众号文章图片并转为PDF
遇到那种有很多图的微信公众号文章咋办?一个一个存很麻烦,应朋友的要求自己写了个爬虫.2.0版本完成了!完善了生成pdf的功能,可根据图片比例自动调节大小,防止超出页面范围,增加了序号方面查看 #-----------------settings--------------- #url='https://mp.weixin.qq.com/s/8JwB_SXQ-80uwQ9L97BMgw' print('jd3096 for king 2.0 VIP8钻石永久会员版') print('愿你远离流氓软
-
Python爬取微信小程序Charles实现过程图解
一.前言 最近需要获取微信小程序上的数据进行分析处理,第一时间想到的方式就是采用python爬虫爬取数据,尝试后发现诸多问题,比如无法获取目标网址.解析网址中存在指定参数的不确定性.加密问题等等,经过一番尝试,终于使用 Charles 抓取到指定微信小程序中的数据,本文进行记录并总结. 环境配置: 电脑:Windows10,连接有线网 手机:iPhone Xr,连接无线网 注:有线网与无线网最好位于同一网段下. 本文有线网网址:192.168.131.24,无线网网址:192.168.210.2
-
python 爬取百度文库并下载(免费文章限定)
import requests import re import json import os session = requests.session() def fetch_url(url): return session.get(url).content.decode('gbk') def get_doc_id(url): return re.findall('view/(.*).html', url)[0] def parse_type(content): return re.findall
-
python爬取微信公众号文章的方法
最近在学习Python3网络爬虫开发实践(崔庆才 著)刚好也学习到他使用代理爬取公众号文章这里,但是照着他的代码写,出现了一些问题.在这里我用到了这本书的前面讲的一些内容进行了完善.(作者写这个代码已经是半年前的事了,但腾讯的网站在这半年前进行了更新) 下面我直接上代码: TIMEOUT = 20 from requests import Request, Session, PreparedRequest import requests from selenium import webdrive
-
Python爬取微信小程序通用方法代码实例详解
背景介绍 最近遇到一个需求,大致就是要获取某个小程序上的数据.心想小程序本质上就是移动端加壳的浏览器,所以想到用Python去获取数据.在网上学习了一下如何实现后,记录一下我的实现过程以及所踩过的小坑.本文关键词:Python,小程序,Charles抓包 目标小程序: 公众号"同城商圈网"左下角"找商家"->汽车维修->小车维修->所有的商家信息,如下图所示: 环境 PC端:Windows 10 移动端:iPhone 软件:Charles Char
-
python爬取指定微信公众号文章
本文实例为大家分享了python爬取微信公众号文章的具体代码,供大家参考,具体内容如下 该方法是依赖于urllib2库来完成的,首先你需要安装好你的python环境,然后安装urllib2库 程序的起始方法(返回值是公众号文章列表): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") # 加载页面 url = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query=要爬取的公众号名
-
Python爬虫爬取微信朋友圈
接下来,我们将实现微信朋友圈的爬取. 如果直接用 Charles 或 mitmproxy 来监听微信朋友圈的接口数据,这是无法实现爬取的,因为数据都是被加密的.而 Appium 不同,Appium 作为一个自动化测试工具可以直接模拟 App 的操作并可以获取当前所见的内容.所以只要 App 显示了内容,我们就可以用 Appium 抓取下来. 1. 本节目标 本节我们以 Android 平台为例,实现抓取微信朋友圈的动态信息.动态信息包括好友昵称.正文.发布日期.其中发布日期还需要进行转换,如日期