Pytorch深度学习gather一些使用问题解决方案
目录
- 问题场景描述
- 问题的思考
- gather的说明
- 问题的解决
问题场景描述
我在复现Faster-RCNN模型的过程中遇到这样一个问题:
有一个张量,它的形状是 (128, 21, 4)
roi_loc.shape = (128, 21, 4)
与之对应的还有一个label数据
gt_label.shape = (128)

我现在的需求是将label当作第一个张量在dim=1上的索引,将其中的数据拿出来。
具体来说就是,现在有128个样本数据,每个样本中有21个长度为4的向量。label也是128个,每个值代表取出21个向量中的哪一个。
问题的思考
我尝试了很多办法,包括布尔索引,index_select方法等,最后发现都不适用(也有可能我没用好)。最后利用gather API解决了这个问题。
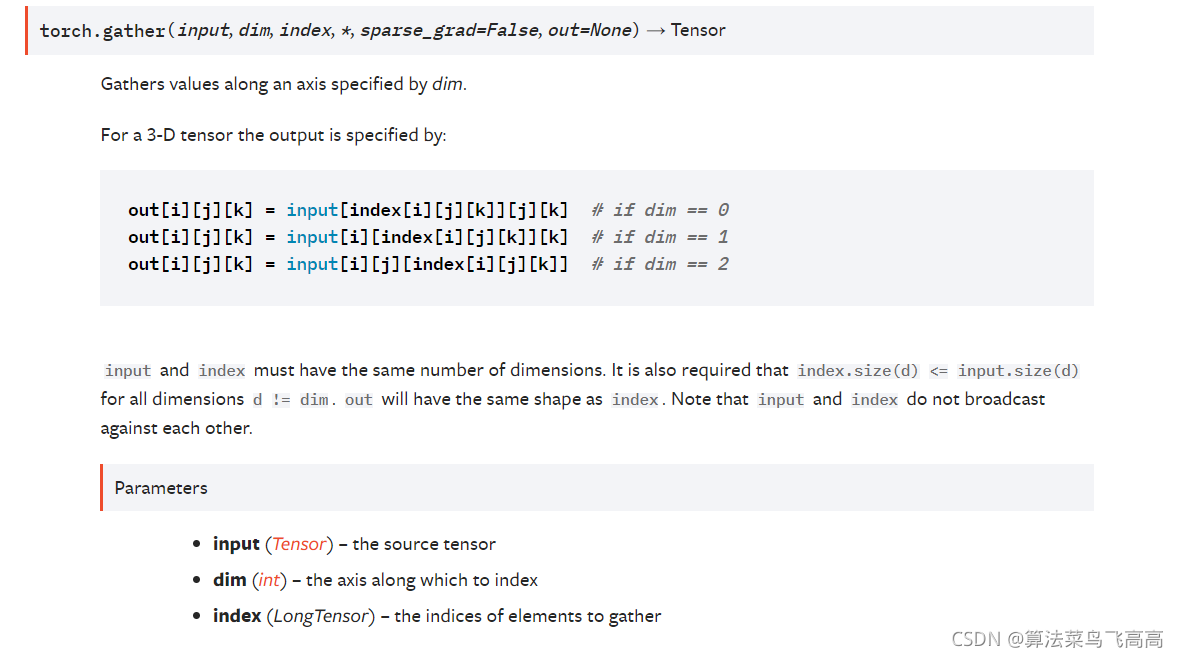
这个API的说明我看了很多遍都没看懂,我相信绝大部分读者也是因为看不懂这个说明才来这儿的。
下面我给出自己的一些理解:
gather的说明
gather所需要的第一个参数是待索引的数据,在我们的问题中 roi_loc就是这个input。第二个参数dim,是你的索引数据要作用在哪个轴上,正如前面所言,我们想索引第二个轴(dim=1).
最难理解的是index,index就是我们想要用来索引的张量,对应的是label。可是label不能直接拿来用,得先做一定的变换,这也就是gather的难点。
我们先从简单的情况来看
input和gather必须在维度上相同,假设数据还是3 * 3,index也是1 * 3的(注意这里是二维的)
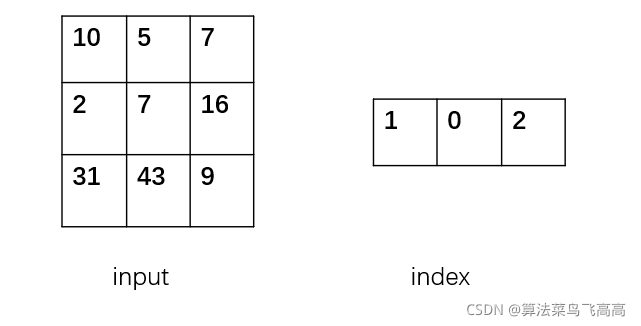
此时row至多取值0,col至多取值为2
如果我要对dim=0索引
那么data[0][0] = data[index[0][0]] [0] = data[1][0] = 2
data[0][1] = data[index[0][1]] [1] = data[0][1] = 5
data[0][2] = data[index[0][2]][2] = data[2][2] = 9
上面的过程可以描述为,第一列的元素我想选第二行的,第二列的元素我想选第一行的,第三列的元素我想选第三行的。
可以发现因为index是1 * 3的,所以最后的输出也是31* 3,即输出张量的shape取决于index的shape

以上过程我相信读者好好体悟应该可以理解。
问题的解决
回到我们的问题
roi_loc.shape = (128, 21, 4),gt_label.shape = (128)
我们想索引dim=1,最后的结果应该是(128, 4)
由上面的说明可以知道,input和index的dimension首先得相同
idx = gt_roi_labels.unsqueeze(-1).unsqueeze(-1) idx.shape = (128, 1, 1)
又因为我们想要输出的结果得是(128, 4),所以得让idx在最后一个轴上重复4次
idx = idx.repeat_interleave(-1, 4) idx.shape = (128, 1, 4)
现在就可以利用gather在dim=1上索引了
result = roi_loc.gather(1, idx) result.shape = (128, 1, 4)
最后将长度为1的轴压缩(本身这个轴的出现是为了满足input和index维度一样的要求)
result = result.squeeze(1) result.shape(128, 4)
以上就是Pytorch深度学习gather一些使用问题解决方案的详细内容,更多关于Pytorch学习gather使用问题的资料请关注我们其它相关文章!
相关推荐
-

pyTorch深度学习多层感知机的实现
目录 激活函数 多层感知机的PyTorch实现 激活函数 前两节实现的传送门 pyTorch深度学习softmax实现解析 pyTorch深入学习梯度和Linear Regression实现析 前两节实现的linear model 和 softmax model 是单层神经网络,只包含一个输入层和一个输出层,因为输入层不对数据进行transformation,所以只算一层输出层. 多层感知机(mutilayer preceptron)加入了隐藏层,将神经网络的层级加深,因为线性层的串联结果还是线
-
Python深度学习pyTorch权重衰减与L2范数正则化解析
下面进行一个高维线性实验 假设我们的真实方程是: 假设feature数200,训练样本和测试样本各20个 模拟数据集 num_train,num_test = 10,10 num_features = 200 true_w = torch.ones((num_features,1),dtype=torch.float32) * 0.01 true_b = torch.tensor(0.5) samples = torch.normal(0,1,(num_train+num_test,num_fe
-
pyTorch深入学习梯度和Linear Regression实现
目录 梯度 线性回归(linear regression) 模拟数据集 加载数据集 定义loss_function 梯度 PyTorch的数据结构是tensor,它有个属性叫做requires_grad,设置为True以后,就开始track在其上的所有操作,前向计算完成后,可以通过backward来进行梯度回传. 评估模型的时候我们并不需要梯度回传,使用with torch.no_grad() 将不需要梯度的代码段包裹起来.每个Tensor都有一个.grad_fn属性,该属性即创建该Tensor
-
pytorch教程网络和损失函数的可视化代码示例
目录 1.效果 2.环境 3.用到的代码 1.效果 2.环境 1.pytorch 2.visdom 3.python3.5 3.用到的代码 # coding:utf8 import torch from torch import nn, optim # nn 神经网络模块 optim优化函数模块 from torch.utils.data import DataLoader from torch.autograd import Variable from torchvision import t
-
Python强化练习之PyTorch opp算法实现月球登陆器
目录 概述 强化学习算法种类 PPO 算法 Actor-Critic 算法 Gym LunarLander-v2 启动登陆器 PPO 算法实现月球登录器 PPO main 输出结果 概述 从今天开始我们会开启一个新的篇章, 带领大家来一起学习 (卷进) 强化学习 (Reinforcement Learning). 强化学习基于环境, 分析数据采取行动, 从而最大化未来收益. 强化学习算法种类 On-policy vs Off-policy: On-policy: 训练数据由当前 agent 不断
-
Pytorch深度学习gather一些使用问题解决方案
目录 问题场景描述 问题的思考 gather的说明 问题的解决 问题场景描述 我在复现Faster-RCNN模型的过程中遇到这样一个问题: 有一个张量,它的形状是 (128, 21, 4) roi_loc.shape = (128, 21, 4) 与之对应的还有一个label数据 gt_label.shape = (128) 我现在的需求是将label当作第一个张量在dim=1上的索引,将其中的数据拿出来. 具体来说就是,现在有128个样本数据,每个样本中有21个长度为4的向量.label也是1
-
pyTorch深度学习softmax实现解析
目录 用PyTorch实现linear模型 模拟数据集 定义模型 加载数据集 optimizer 模型训练 softmax回归模型 Fashion-MNIST cross_entropy 模型的实现 利用PyTorch简易实现softmax 用PyTorch实现linear模型 模拟数据集 num_inputs = 2 #feature number num_examples = 1000 #训练样本个数 true_w = torch.tensor([[2],[-3.4]]) #真实的权重值 t
-
PyTorch深度学习模型的保存和加载流程详解
一.模型参数的保存和加载 torch.save(module.state_dict(), path):使用module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的文件存放路径(常用文件格式为.pt..pth或.pkl). torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其子类中 . torch.nn.Module.state_dict()函数
-
Pytorch深度学习之实现病虫害图像分类
目录 一.pytorch框架 1.1.概念 1.2.机器学习与深度学习的区别 1.3.在python中导入pytorch成功截图 二.数据集 三.代码复现 3.1.导入第三方库 3.2.CNN代码 3.3.测试代码 四.训练结果 4.1.LOSS损失函数 4.2. ACC 4.3.单张图片识别准确率 四.小结 一.pytorch框架 1.1.概念 PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序. 2017年1月,由Facebook人工智能研究院(FA
-
Pytorch深度学习经典卷积神经网络resnet模块训练
目录 前言 一.resnet 二.resnet网络结构 三.resnet18 1.导包 2.残差模块 2.通道数翻倍残差模块 3.rensnet18模块 4.数据测试 5.损失函数,优化器 6.加载数据集,数据增强 7.训练数据 8.保存模型 9.加载测试集数据,进行模型测试 四.resnet深层对比 前言 随着深度学习的不断发展,从开山之作Alexnet到VGG,网络结构不断优化,但是在VGG网络研究过程中,人们发现随着网络深度的不断提高,准确率却没有得到提高,如图所示: 人们觉得深度学习到此
-
PyTorch深度学习LSTM从input输入到Linear输出
目录 LSTM介绍 LSTM参数 Inputs Outputs batch_first 案例 LSTM介绍 关于LSTM的具体原理,可以参考: https://www.jb51.net/article/178582.htm https://www.jb51.net/article/178423.htm 系列文章: PyTorch搭建双向LSTM实现时间序列负荷预测 PyTorch搭建LSTM实现多变量多步长时序负荷预测 PyTorch搭建LSTM实现多变量时序负荷预测 PyTorch搭建LSTM
-
如何在conda虚拟环境中配置cuda+cudnn+pytorch深度学习环境
首先,我们要明确,我们是要在虚拟环境中安装cuda和cuDNN!!!只需要在虚拟环境中安装就可以了. 下面的操作默认你安装好了python 一.conda创建并激活虚拟环境 前提:确定你安装好了anaconda并配置好了环境变量,如果没有,网上有很多详细的配置教程,请自行学习 在cmd命令提示符中输入conda命令查看anaconda 如果显示和上图相同,那么可以继续向下看 1.进入anaconda的base环境 方法1 在cmd命令提示符中输入如下命令 activate 方法2 直接在搜索栏里
-
Python Pytorch深度学习之核心小结
目录 一.Numpy实现网络 二.Pytorch:Tensor 三.自动求导 1.PyTorch:Tensor和auto_grad 总结 Pytorch的核心是两个主要特征: 1.一个n维tensor,类似于numpy,但是tensor可以在GPU上运行 2.搭建和训练神经网络时的自动微分/求导机制 一.Numpy实现网络 在总结Tensor之前,先使用numpy实现网络.numpy提供了一个n维数组对象,以及许多用于操作这些数组的函数. import numpy as np # n是批量大小,
-
Python Pytorch深度学习之自动微分
目录 一.简介 二.TENSOR 三.梯度 四.Example--雅克比向量积 总结 一.简介 antograd包是Pytorch中所有神经网络的核心.autograd为Tensor上的所有操作提供自动微分,它是一个由运行定义的框架,这意味着以代码运行方式定义后向传播,并且每一次迭代都可能不同 二.TENSOR torch.Tensor是包的核心. 1.如果将属性.requires_grad设置为True,则会开始跟踪针对tensor的所有操作. 2.完成计算之后,可以调用backward()来