Python实现智慧校园自动评教全新版
前言
因为前面的文章中已经涉及到了登录智慧校园的验证码处理问题,所以本文将略过此过程。如登录时遇到验证码的情况,请参考此文。其实第一次使用有验证码的话,可以在浏览器先登录一次,然后再使用python代码模拟登录,验证码就没了。因为CQCET智慧校园验证码弹出是有限定条件的!
一、准备工作
导包
import json import requests import uuid from fake_useragent import UserAgent # 随机生成UserAgent
生成uuid和UA
# 随机生成uuid
uuid = uuid.uuid4()
# 随机UA
headers = {'User-Agent': UserAgent().random}
二、登录智慧校园
此过程不再做过多的赘述,直接上代码吧!
# 登录智慧校园
def login():
login_url = 'http://sso.cqcet.edu.cn/uaa/login_process'
data = {'type': 1, 'deviceId': uuid, 'username': '19030****', 'password': 'xl*****5', 'img_code': ''}
session = requests.session()
session.post(url=login_url, headers=headers, data=data)
return session
注: username:账号 password:密码
三、进行评教操作
1、进入评教页面观察
从教学评价(学生)教学评价点击学生虽然能够看到教学评价页面但是并非真的教学评价对应的网址,故而需要在network中查看真正的教学评价页面对应的网址。按F12检查网页,然后进行如下图步骤的操作,就可以发现真正的教学评价网址了。
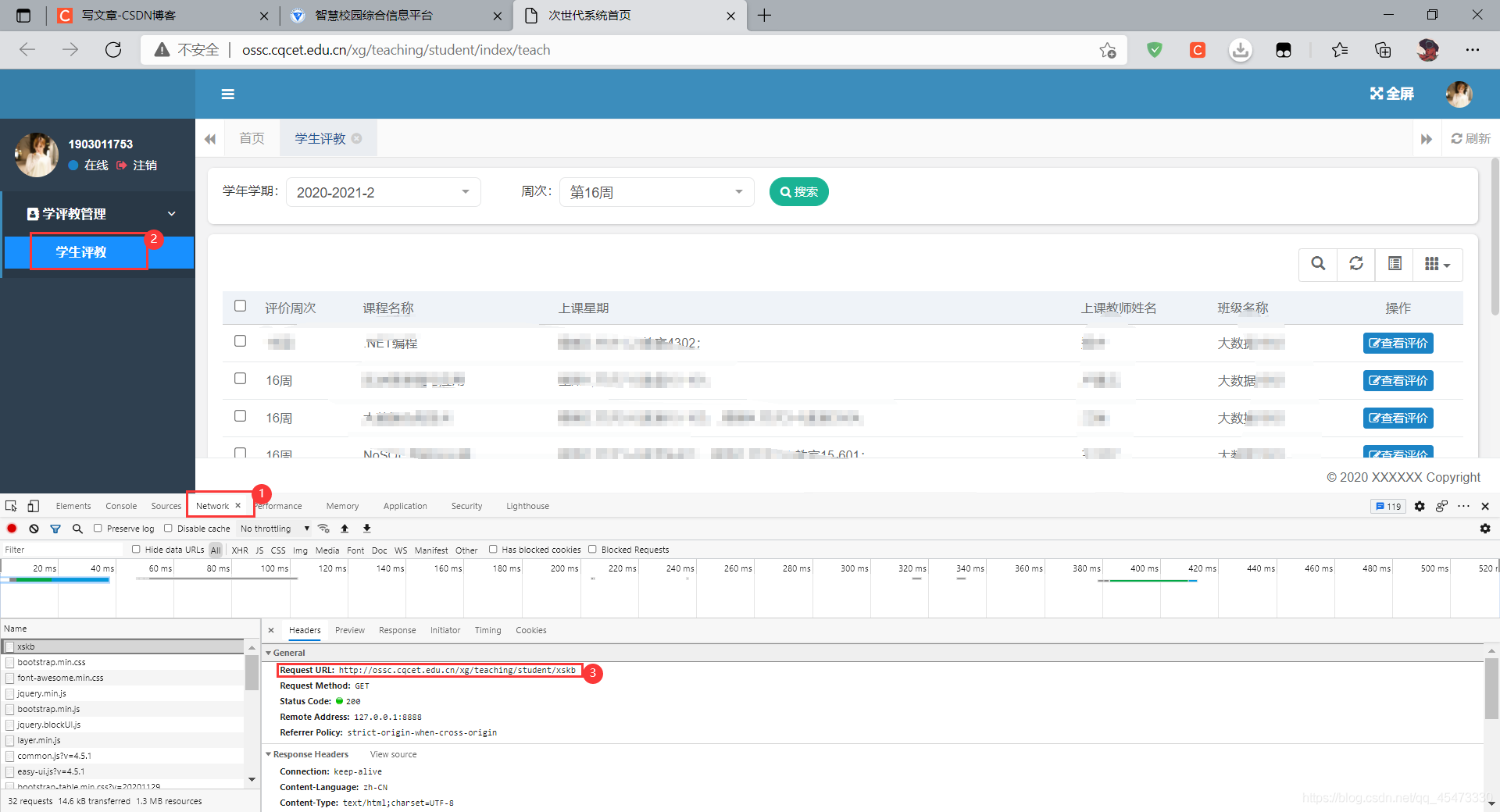
2、抓取评教时发起url请求操作
同样在此教学评价页面按F12调出开发者工具转至Network那一栏,然后对一节课进行评教。然后你会发现进行评教的url请求操作,如下图所示!
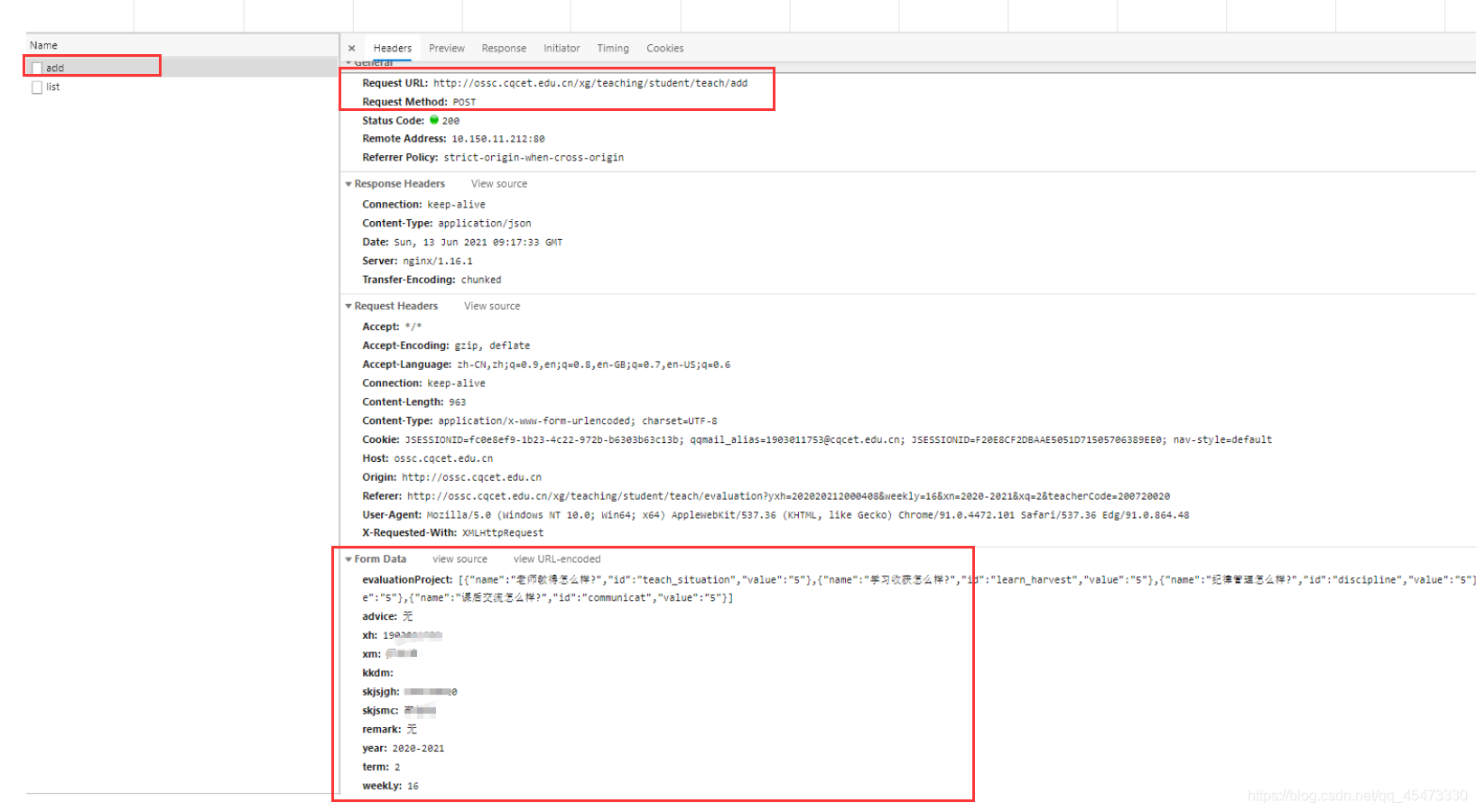
因此我们只需要用python模拟出同样的请求操作就可以完成评教了!但是这个是个需要携带data的post请求,那么问题来了,数据该从那儿去获取呢?
# 以下为部分所需携带的data advice: 无 xh: 1903011753 xm: xue kkdm: skjsjgh: 200720020 skjsmc: 上课老师姓名 remark: 无 year: 2020-2021 term: 2 weekLy: 周次 taskId: 202020*********08
缺什么就去找什么,很容易发现在add的下面有一个list。可以其对应的url发起post请求获取上述所需信息。
代码实现:
# 评教页面
def evaluation(session):
session.get(url='http://ossc.cqcet.edu.cn/xg/teaching/student/xskb')
data = {'pageSize': '10', 'pageNum': '1', 'isAsc': 'asc', 'xnxq': '2020-2021-2', 'weekly': '16'
''}
eval_jsons = json.loads(session.post(url='http://ossc.cqcet.edu.cn/xg/teaching/student/xskb/list', data=data).text)
add_data = {
'evaluationProject': '[{"name": "老师教得怎么样?", "id": "teach_situation", "value": "5"},\
{"name": "学习收获怎么样?", "id": "learn_harvest", "value": "5"},\
{"name": "纪律管理怎么样?", "id": "discipline", "value": "5"},\
{"name": "课堂互动怎么样?", "id": "interaction", "value": "5"},\
{"name": "课后交流怎么样?", "id": "communicat", "value": "5"}]',
'advice': '无',
'remark': '无',
'kkdm': ''
}
for eval_json in eval_jsons['rows']:
isFlag = eval_json['complete']
if isFlag:
print(eval_json['skjsmc'] + '老师的《' + eval_json['kcmc'] + '》已评价!')
else:
add_data['xh'] = eval_json['xh']
add_data['xm'] = eval_json['xm']
add_data['skjsjgh'] = eval_json['skjsjgh']
add_data['skjsmc'] = eval_json['skjsmc']
add_data['year'] = eval_json['xn']
add_data['term'] = eval_json['xq']
add_data['weekLy'] = eval_json['weekly']
add_data['taskId'] = eval_json['yxh']
eval_add_url = 'http://ossc.cqcet.edu.cn/xg/teaching/student/teach/add'
# print(session.get(url=eval_url).text)
print(session.post(url=eval_add_url, data=add_data).text)
3、遇到的问题
到这就已经结束了,但是在post请求请教url时我一直失败,返回{"msg":"运行时异常:error parse new","code":500},让我困惑不已,百思不得其解。最后我用fiddler抓包,对比了一下浏览器post请求与python代码发起的post请求的区别,如下图所示:
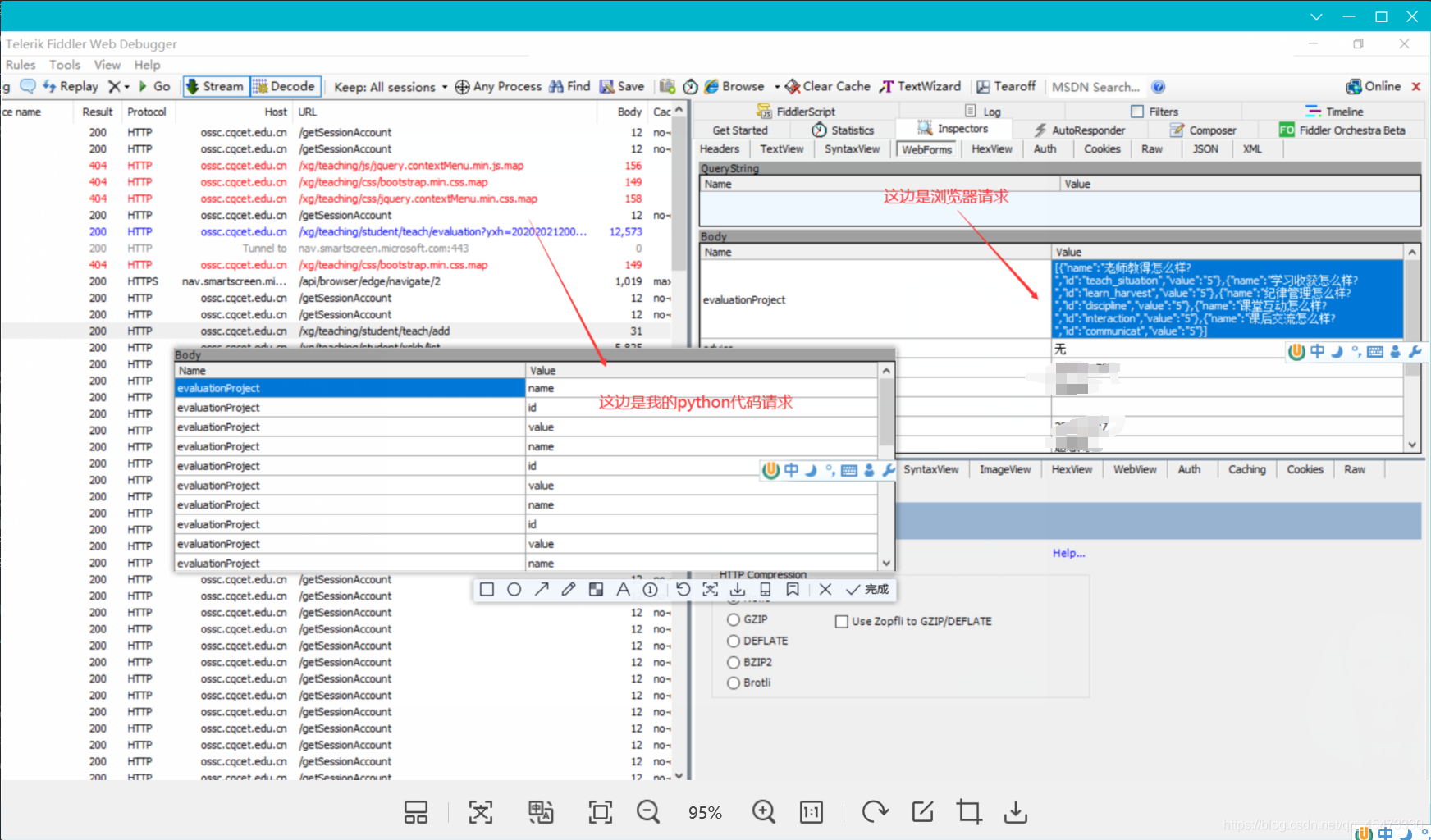
你会发现浏览器post请求时'evaluationProject'对应的value值为一个列表。而python的post请求时,'evaluationProject'对应多个value值,本来value应是一个列表的,活生生的本拆散了!因为当时post请求携带的数据是这么写的,如下所示:
'evaluationProject': [{"name": "老师教得怎么样?", "id": "teach_situation", "value": "5"},
{"name": "学习收获怎么样?", "id": "learn_harvest", "value": "5"},
{"name": "纪律管理怎么样?", "id": "discipline", "value": "5"},
{"name": "课堂互动怎么样?", "id": "interaction", "value": "5"},
{"name": "课后交流怎么样?", "id": "communicat", "value": "5"}],
直接让evaluationProject与一个列表形成键值对,找到原因之后我就想把这个列表放在字符串中,但是还是报错。因为我忘了,一个字符串换行需要用续行符连接,最后改成下面那样才算成功!
'evaluationProject': '[{"name": "老师教得怎么样?", "id": "teach_situation", "value": "5"},\
{"name": "学习收获怎么样?", "id": "learn_harvest", "value": "5"},\
{"name": "纪律管理怎么样?", "id": "discipline", "value": "5"},\
{"name": "课堂互动怎么样?", "id": "interaction", "value": "5"},\
{"name": "课后交流怎么样?", "id": "communicat", "value": "5"}]',
四、总结
此次实现自动评教并不难,主要在于一些细节问题困扰了我好久,果然是细节决定成败。我也长记性了,python中字符串为多行时,一定要用\这个续行符!
到此这篇关于Python实现智慧校园自动评教全新版的文章就介绍到这了,更多相关Python智慧校园自动评教内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python自动化运维之Telnetlib的具体使用
目录 前言: 1.导入telnetlib库可以直接使用. 2.配置服务器.用户名.密码,cmd命令等 3.功能函数 前言: 远程连接中兴设备(系统使用的中兴网卡)时使用的事Telnet连接,连接时设有二次验证,每次输入用户名密码和执行命令是个繁琐的过程,使用Python自带的telnetlib库可以编写脚本,实现批量登录服务器并执行命令查询数据量. 1.导入telnetlib库可以直接使用. from telnetlib import Telnet 2.配置服务器.用户名.密码,cmd命令等 #
-

python 利用PyAutoGUI快速构建自动化操作脚本
一.背景 大家好,我是安果! 我们经常遇到需要进行大量重复操作的时候,比如:网页上填表,对 web 版本 OA 进行操作,自动化测试或者给新系统首次添加数据等 这些操作的特点往往是:数据同构,大多是已经有了的结构化数据:操作比较呆板,都是同一个流程的点击.输入:数据量大,极大消耗操作人精力 那么能不能自动化呢? 二.自动化的方案 如果你在 web 上进行操作, Python 的 Selenium 可以满足要求.如果需要对 GUI 界面进行操作,你恐怕得试验下"按键精灵"能不能满足要求.
-
python趣味挑战之爬取天气与微博热搜并自动发给微信好友
一.系统环境 1.python 3.8.2 2.webdriver(用于驱动edge) 3.微信电脑版 4.windows10 二.爬取中国天气网 因为中国天气网的网页是动态生成的,所以不能直接爬取到数据,需要先使用webdriver打开网页并渲染完成,然后保存网页源代码,使用beautifulsoup分析数据.爬取的数据包括实时温度.最高温度与最低温度.污染状况.风向和湿度.紫外线状况.穿衣指南八项数据. def getZZWeatherAndSendMsg(): HTML1='http://
-
Python 如何实现文件自动去重
Python 文件自动去重 平日里一来无聊,二来手巧,果然下载了好多无(luan)比(qi)珍(ba)贵(zao)的资料,搞得我小小的硬盘(已经扩到6T了)捉襟见肘, 有次无意间,发现有两个居然长得一毛一样,在房子这么小的情况下,我怎能忍两个一毛一样的东西不要脸皮的躺在我的硬盘里,果断搞掉一个,整理一下,本来想文件名一样的就保留一份,但问题出现了,居然有名字一样,内容却完全不一样的文件,想我背朝黄土面朝天吹着空调吃着西瓜下载下来的东西,删除是不可能的,这辈子都是不可能删除的.可是我也又不能把这数
-
Python脚本实现自动登录校园网
Python自动化脚本登录校园网 所需工具:python编译环境(博主使用的pycharm作演示,其实在cmd也可以操作!) selenium自动化脚本 .bat批处理文件 第一步,通过pycharm创建一个项目 点击左上角file,然后new project 2.创建项目 3.然后右键项目名创建py文件 4.在pycharm中调用cmd,(在左下角的terminal就是了),再通过cd命令进入到Scripts文件下,Scripts是自己的python编译器文件夹下的目录 5.下载seleniu
-
还在手动盖楼抽奖?教你用Python实现自动评论盖楼抽奖(一)
获取评论贴的请求头与表单数据 下一篇在这里 这里,我们随便选取一个网站,获取该贴评论后的请求头,表单数据以及评论贴链接.(因为涉及敏感信息,自己看图片是哪个网址) 比如这个网站,经常有不定时的盖楼活动推出,我们随便评论一条,通过chrome F12功能,获取其请求头与表单数据. 可以看到其右侧的表单数据(评论参数)有: message:盖楼的内容,一般来说这个内容可以提供一个文档随机选择评论,可以规避自动盖楼导致评论一模一样. posttime:标识数据,一般具有唯一性,确定是否是人为操作.(各
-
Python爬虫之自动爬取某车之家各车销售数据
一.目标网页分析 目标网站是某车之家关于品牌汽车车型的口碑模块相关数据,比如我们演示的案例奥迪Q5L的口碑页面如下: https://k.autohome.com.cn/4851/#pvareaid=3311678 为了演示方式,大家可以直接打开上面这个网址,然后拖到全部口碑位置,找到我们本次采集需要的字段如下图所示: 采集字段 我们进行翻页发现,浏览器网址发生了变化,大家可以对下如下几页的网址找出规律: https://k.autohome.com.cn/4851/index_2.html#d
-
Python实现智慧校园自动评教全新版
前言 因为前面的文章中已经涉及到了登录智慧校园的验证码处理问题,所以本文将略过此过程.如登录时遇到验证码的情况,请参考此文.其实第一次使用有验证码的话,可以在浏览器先登录一次,然后再使用python代码模拟登录,验证码就没了.因为CQCET智慧校园验证码弹出是有限定条件的! 一.准备工作 导包 import json import requests import uuid from fake_useragent import UserAgent # 随机生成UserAgent 生成uuid和UA
-
Python趣味爬虫之用Python实现智慧校园一键评教
一.安装selenium库 问题1:什么是selenium模块? 基于浏览器自动化的一个模块. 问题2:selenium模块有什么作用呢? 便捷地获取网站中动态加载的数据 便捷地实现模拟登录 问题3:环境安装 pip install selenium 二.下载一个浏览器的驱动程序(谷歌浏览器) 1.下载路径 http://chromedriver.storage.googleapis.com/index.html 2.驱动程序和浏览器的映射关系(谷歌浏览器) 方法1:[不推荐] 在浏览器地址栏输
-
用Python获取智慧校园每日课表并自动发送至邮箱
一.准备工作 1.1 观察登陆界面 我很很容易发现,当我们输入了账号与密码之后,就会出现这么一个链接,Response返回的是false: http://sso.cqcet.edu.cn/verificationCode?userCode={username} 此处的username指的是你的智慧校园账号:false表示登入时不需要输入验证码:当Response返回的是true时,需要输入验证码. 1.2 观察登陆请求过程 我们可以发现,Request URL为http://sso.cqcet.
-
教你用python编写脚本实现自动签到
目录 1. 背景原因 2. 签到原理 3. 需要的环境selenium 4. 安装模拟的插件 5. 下载完成 6.正题 7. 完工! 8. 更新 1. 背景原因 最近才上班,要求每天打卡!我老是忘记,于是乎搞个脚本进行自动签到. 2. 签到原理 模拟用户进行自行输入,然后登录,然后签到,在研究过程中使用到了python的selenium包,本人在win10环境中进行测试使用,可以实现基本的自动打卡. 3. 需要的环境selenium pip install selenium 4. 安装模拟的插件
-
Python完全识别验证码自动登录实例详解
1.直接贴代码 #!C:/Python27 #coding=utf-8 from selenium import webdriver from selenium.webdriver.common.keys import Keys from pytesser import * from PIL import Image,ImageEnhance,ImageFilter from selenium.common.exceptions import NoSuchElementException,Tim
-
python 利用toapi库自动生成api
在学习做接口测试自动化的时候,我们往往会自己动手写一些简单的API,比如写一个简单的TODO API之类. 不过自己写API的时候经常需要造一些假数据,以及处理分页逻辑,开始的时候还觉得比较有意思,但久而久之就显得比较乏味了. 这时候你可能会想,有没有什么工具可以自动将一个线上的网站转化成简单的API呢? 这样的工具确实是存在的,而且不少,其中python语言中比较受欢迎的实现是https://github.com/gaojiuli/toapi项目,项目名称是toapi. 我们来简单体验一下这个
-
python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)
[python爬虫基础入门]系列是对python爬虫的一个入门练习实践,旨在用最浅显易懂的语言,总结最明了,最适合自己的方法,本人一直坚信,总结才会使人提高 1. BeautifulSoup库简介 BeautifulSoup库在python中被美其名为"靓汤",它和和 lxml 一样也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,若在没用安装此库的情况下
-
Python脚本实现一键自动整理办公文件
目录 导语: 1.准备 2.原理 3.自定义整理 导语: 举例:Python做一个根据后缀名整理文件的工具,先来看看效果: 自动整理前: 自动整理后: 这样看起来就好很多了. 1.准备 开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,可以访问这篇文章:python Windows最新版本安装教程 我们只需要修改源代码主程序中调用 auto_organize函数的参数即可完成对对应文件夹的整理,比如我想整理 C:\Users\83493\Downloads 文件夹: if
-
Python实现的一个自动售饮料程序代码分享
写这个程序的时候,我已学习Python将近有一百个小时,在CSDN上看到有人求助使用Python如何写一个自动售饮料的程序,我一想,试试写一个实用的售货程序.当然,只是实现基本功能,欢迎高手指点,新手学习参考. 运行环境:Python 2.7 # encoding=UTF-8 loop=True money=0 while loop: x = raw_input('提示:请投入金币,结束投币请按"q"键') if x=='q': if money==0:
-
python实现QQ空间自动点赞功能
本文实例为大家分享了python实现QQ空间自动点赞的具体代码,供大家参考,具体内容如下 项目github地址 使用python实现qq空间自动点赞功能. 需自行安装库并配置环境. 我想实现的是每6个小时就自动更新一次cookie.这也是和网上其他版本相比具有的优点.不用手动输入cookie.更加自动.(不负责任的说,这个功能没有测试过.) 程序运行方法:将代码存为.py文件,运行即可. 输入QQ密码的时候采用了linux登录的方式--没有回显. from selenium import web