Python二进制数据结构Struct的具体使用
目录
- 二进制数据结构Struct
- 函数与Struct类
- 打包
- 解包
- 字节序指示符
- 缓冲区
二进制数据结构Struct
在C/C++语言中,struct被称为结构体。而在Python中,struct是一个专门的库,用于处理字节串与原生Python数据结构类型之间的转换。
本篇,将详细介绍二进制数据结构struct的使用方式。
函数与Struct类
struct库包含了一组处理结构值得模块级函数,以及一个Struct类。格式指示符将由字符串格式转换为一种编译表示,这与处理正则表达式得方式类似。
这个转换会耗费一些资源,所以创建一个Struct实例并再这个实例上调用方法时,只完成一次转换,往往会更高效。
打包
Struct支持使用格式指示符将数据打包为字符串,另外支持从字符串解包数据,格式指示符由表示数据类型的字符串和可选的数量及字节序指示符构成。
下面,我们来打包一个元组,将其转换为16进制字节序列,示例如下:
import struct
import binascii
values = (2, 'lyj'.encode('UTF-8'), 3.8)
s = struct.Struct('I 3s f')
packed_data = s.pack(*values)
print("原值:", values)
print("格式指示符:", s.format)
print("大小:", s.size, 'bytes')
print("打包值:", binascii.hexlify(packed_data))
运行之后,效果如下:

这里的格式指示符为“I 3s f”。前面介绍array数组时,我们已经列出过一个表格。其中I标识一个整型或长整型,3s表示3个字节字符串(lyj),f表示浮点数。
解包
struct库使用unpack()可以从打包的表示数据中抽取数据,这里直接复制上面的打包值,进行测试。示例如下:
import struct
import binascii
packed_data = binascii.unhexlify(b'020000006c796a0033337340')
s = struct.Struct('I 3s f')
unpacked_data = s.unpack(packed_data)
print("解包值:", unpacked_data)
运行之后,效果如下:

虽然使用unpack()解包基本会得到相同值,但浮点数的值有微小的差别。
字节序指示符
默认情况下,值会使用原生C库的字节序(endianness)来编码。Struct的字节序指示符如下表所示:
| 代码 | 含义 |
|---|---|
| @ | 原生顺序 |
| = | 原生标准 |
| < | 小端 |
| > | 大端 |
| ! | 网络顺序 |
示例如下:
import struct
import binascii
values = (2, 'lyj'.encode('UTF-8'), 3.8)
endianness = [
('@', '原生顺序'),
('=', '原生标准'),
('<', '小端'),
('>', '大端'),
('!', '网络顺序'),
]
for code, name in endianness:
s = struct.Struct(code + ' I 3s f')
packed_data = s.pack(*values)
print("格式化字符串:", s.format, ' for ', name)
print("大小:", s.size, 'bytes')
print("打包:", binascii.hexlify(packed_data))
print("解包:", s.unpack(packed_data))
运行之后,效果如下:
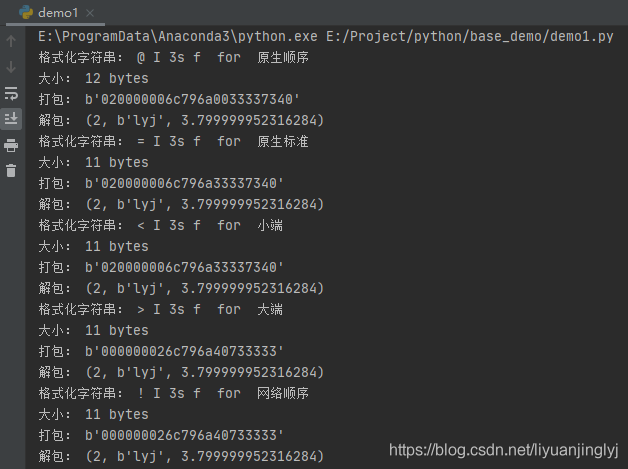
如果想改变字节序来编码,如上面代码所示,只需要改变格式串中提供一个显式的字节序指令,就可以很容易地覆盖这个默认选择。
缓冲区
通常在强调性能的情况下或者向扩展模块传入或传出数据时才会处理二进制打包数据。
为了避免为每个打包结构分配一个新缓冲区所带来的开销,通常情况下,我们使用pack_into()和unpack_from()方法支持直接写入预分配的缓冲区。
示例如下:
import struct
import binascii
import ctypes
import array
values = (2, 'lyj'.encode('UTF-8'), 3.8)
s = struct.Struct('I 3s f')
print("原始值:", values)
b = ctypes.create_string_buffer(s.size)
print("打包之前(缓冲区的值):", binascii.hexlify(b.raw))
s.pack_into(b, 0, *values)
print("打包之后(缓冲区的值):", binascii.hexlify(b.raw))
print("解包:", s.unpack_from(b, 0))
a = array.array('b', b'\0' * s.size)
print("打包之前(缓冲区的值):", binascii.hexlify(a))
s.pack_into(a, 0, *values)
print('打包之后(缓冲区的值):', binascii.hexlify(a))
print("解包:", s.unpack_from(a, 0))
运行之后,效果如下:

这里通过两种方式,创建缓冲区。其中size属性用于指出缓冲区需要的大小。
到此这篇关于Pytho 二进制数据结构Struct的具体使用的文章就介绍到这了,更多相关Pytho 二进制数据结构Struct内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
简单介绍Python中的struct模块
准确地讲,Python没有专门处理字节的数据类型.但由于str既是字符串,又可以表示字节,所以,字节数组=str.而在C语言中,我们可以很方便地用struct.union来处理字节,以及字节和int,float的转换. 在Python中,比方说要把一个32位无符号整数变成字节,也就是4个长度的str,你得配合位运算符这么写: >>> n = 10240099 >>> b1 = chr((n & 0xff000000) >> 24) >>&
-
Python标准库笔记struct模块的使用
最近在学习python网络编程这一块,在写简单的socket通信代码时,遇到了struct这个模块的使用,当时不太清楚这到底有和作用,后来查阅了相关资料大概了解了,在这里做一下简单的总结. 了解c语言的人,一定会知道struct结构体在c语言中的作用,它定义了一种结构,里面包含不同类型的数据(int,char,bool等等),方便对某一结构对象进行处理.而在网络通信当中,大多传递的数据是以二进制流(binary data)存在的.当传递字符串时,不必担心太多的问题,而当传递诸如int.char之
-

Python struct模块解析
python提供了一个struct模块来提供转换.下面就介绍这个模块中的几个方法. struct.pack(): struct.pack用于将Python的值根据格式符,转换为字符串(因为Python中没有字节(Byte)类型,可以把这里的字符串理解为字节流,或字节数组).其函数原型为:struct.pack(fmt, v1, v2, ...),参数fmt是格式字符串,关于格式字符串的相关信息下面有所介绍.v1, v2, ...表示要转换的python值.下面的例子将两个整数转换为字符串(字节流
-
Python使用struct处理二进制的实例详解
Python使用struct处理二进制的实例详解 有的时候需要用python处理二进制数据,比如,存取文件,socket操作时.这时候,可以使用python的struct模块来完成.可以用 struct来处理c语言中的结构体. struct模块中最重要的三个函数是pack(), unpack(), calcsize() pack(fmt, v1, v2, ...) 按照给定的格式(fmt),把数据封装成字符串(实际上是类似于c结构体的字节流) unpack(fmt, string)
-
Python内建模块struct实例详解
本文研究的主要是Python内建模块struct的相关内容,具体如下. Python中变量的类型只有列表.元祖.字典.集合等高级抽象类型,并没有像c中定义了位.字节.整型等底层初级类型.因为Python本来就是高级解释性语言,运行的时候都是经过翻译后再在底层运行.如何打通Python和其他语言之间的类型定义障碍,Python的内建模块struct完全解决了所有问题. 知识介绍: 在struct模块中最最常用的三个: (1)struct.pack:用于将Python的值根据格式符,转换为字符串(因
-
Python struct.unpack
1. 设置fomat格式,如下: 复制代码 代码如下: # 取前5个字符,跳过4个字符华,再取3个字符 format = '5s 4x 3s' 2. 使用struck.unpack获取子字符串 复制代码 代码如下: import struct print struct.unpack(format, 'Test astring') #('Test', 'ing') 来个简单的例子吧,有一个字符串'He is not very happy',处理一下,把中间的not去掉,然后再输出. 复制代码 代码
-
Python二进制数据结构Struct的具体使用
目录 二进制数据结构Struct 函数与Struct类 打包 解包 字节序指示符 缓冲区 二进制数据结构Struct 在C/C++语言中,struct被称为结构体.而在Python中,struct是一个专门的库,用于处理字节串与原生Python数据结构类型之间的转换. 本篇,将详细介绍二进制数据结构struct的使用方式. 函数与Struct类 struct库包含了一组处理结构值得模块级函数,以及一个Struct类.格式指示符将由字符串格式转换为一种编译表示,这与处理正则表达式得方式类似. 这个
-
Python描述数据结构学习之哈夫曼树篇
前言 本篇章主要介绍哈夫曼树及哈夫曼编码,包括哈夫曼树的一些基本概念.构造.代码实现以及哈夫曼编码,并用Python实现. 1. 基本概念 哈夫曼树(Huffman(Huffman(Huffman Tree)Tree)Tree),又称为最优二叉树,指的是带权路径长度最小的二叉树.树的带权路径常记作: 其中,nnn为树中叶子结点的数目,wkw_kwk为第kkk个叶子结点的权值,lkl_klk为第kkk个叶子结点与根结点的路径长度. 带权路径长度是带权结点和根结点之间的路径长度与该结点的权值的乘
-
python二进制转换模块的具体用法
在pyton中,通过struct模块来对二进制进行转换,主要包括两大类函数,即用于打包的pack和用于解包的unpack. 其中,struct.pack的输入格式为struct.pack(format, v1, v2, ...),其中format为格式字符串,v1,v2..为将要转成bytes的字符. 例如 >>> import struct >>> struct.pack('i', 15) b'\x0f\x00\x00\x00' >>> struct
-
Python常见数据结构详解
本文详细罗列归纳了Python常见数据结构,并附以实例加以说明,相信对读者有一定的参考借鉴价值. 总体而言Python中常见的数据结构可以统称为容器(container).而序列(如列表和元组).映射(如字典)以及集合(set)是三类主要的容器. 一.序列(列表.元组和字符串) 序列中的每个元素都有自己的编号.Python中有6种内建的序列.其中列表和元组是最常见的类型.其他包括字符串.Unicode字符串.buffer对象和xrange对象.下面重点介绍下列表.元组和字符串. 1.列表 列表是
-
Python cookbook(数据结构与算法)对切片命名清除索引的方法
本文实例讲述了Python对切片命名清除索引的方法.分享给大家供大家参考,具体如下: 问题:如何清理掉到处都是硬编码的切片索引 解决方案:对切片命名 假设有一些代码用来从字符串的固定位置中取出具体的数据(比如从一个平面文件或类似的格式:平面文件flat file是一种包含没有相对关系结构的记录文件): ########0123456789012345678901234567890123456789012345678901234567890123456789 record='...........
-
Python cookbook(数据结构与算法)从序列中移除重复项且保持元素间顺序不变的方法
本文实例讲述了Python从序列中移除重复项且保持元素间顺序不变的方法.分享给大家供大家参考,具体如下: 问题:从序列中移除重复的元素,但仍然保持剩下的元素顺序不变 解决方案: 1.如果序列中的值时可哈希(hashable)的,可以通过使用集合和生成器解决. # example.py # # Remove duplicate entries from a sequence while keeping order def dedupe(items): seen = set() for item i
-
Python cookbook(数据结构与算法)实现对不原生支持比较操作的对象排序算法示例
本文实例讲述了Python实现对不原生支持比较操作的对象排序算法.分享给大家供大家参考,具体如下: 问题:想在同一个类的实例之间做排序,但是它们并不原生支持比较操作. 解决方案:使用内建的sorted()函数可接受一个用来传递可调用对象的参数key,sorted利用该可调用对象返回的待排序对象中的某些值来比较对象. from operator import attrgetter class User: def __init__(self, user_id): self.user_id = use
-
Python cookbook(数据结构与算法)通过公共键对字典列表排序算法示例
本文实例讲述了Python通过公共键对字典列表排序算法.分享给大家供大家参考,具体如下: 问题:想根据一个或多个字典中的值来对列表排序 解决方案:利用operator模块中的itemgetter()函数对这类结构进行排序是非常简单的. # Sort a list of a dicts on a common key rows = [ {'fname': 'Brian', 'lname': 'Jones', 'uid': 1003}, {'fname': 'David', 'lname': 'Be
-
Python cookbook(数据结构与算法)找出序列中出现次数最多的元素算法示例
本文实例讲述了Python找出序列中出现次数最多的元素.分享给大家供大家参考,具体如下: 问题:找出一个元素序列中出现次数最多的元素是什么 解决方案:collections模块中的Counter类正是为此类问题所设计的.它的一个非常方便的most_common()方法直接告诉你答案. # Determine the most common words in a list words = [ 'look', 'into', 'my', 'eyes', 'look', 'into', 'my', '
-
Python cookbook(数据结构与算法)同时对数据做转换和换算处理操作示例
本文实例讲述了Python同时对数据做转换和换算处理操作.分享给大家供大家参考,具体如下: 问题:我们需要调用一个换算函数(例如sum().min().max()),但是首先需对数据做转换或者筛选处理 解决方案:非常优雅的方法---在函数参数中使用生成器表达式 例如: # 计算平方和 nums=[1,2,3,4,5] s1=sum((x*x for x in nums)) s2=sum(x*x for x in nums) #更优雅的用法 s3=sum([x*x for x in nums])