解析Redis Cluster原理
目录
- 一、前言
- 二、为什么需要Redis Cluster
- 三、Redis Cluster是什么
- 四、节点负载均衡
- 五、什么是一致性哈希
- 六、虚拟节点机制
- 七、Redis Cluster采用的什么算法
- 八、Redis Cluster如何做到高可用
- 8.1、集群如何进行扩容
- 8.2、高可用及故障转移
- 九、简单了解gossip协议
- 十、gossip协议消息类型
- 十一、使用gossip的优劣
- 十二、总结
一、前言
Sentinel集群会对Redis的主从架构中的Redis实例进行监控,一旦发现了master节点宕机了,就会选举出一个Sentinel节点来执行故障转移,从原来的slave节点中选举出一个,将其提升为master节点,然后让其他的节点去复制新选举出来的master节点。
你可能会觉得这样没有问题啊,甚至能够满足我们生产环境的使用需求了,那我们为什么还需要Redis Cluster呢?
二、为什么需要Redis Cluster
的确,在数据上,有replication副本做保证;可用性上,master宕机会自动的执行failover。
那问题在哪儿呢?
首先Redis Sentinel说白了也是基于主从复制,在主从复制中slave的数据是完全来自于master。
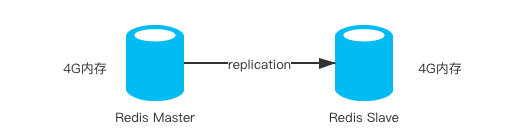
假设master节点的内存只有4G,那slave节点所能存储的数据上限也只能是4G。主从复制架构中是读写分离的,我们可以通过增加slave节点来扩展主从的读并发能力,但是写能力和存储能力是无法进行扩展的,就只能是master节点能够承载的上限。
所以,当你只需要存储4G的数据时候的,基于主从复制和基于Sentinel的高可用架构是完全够用的。
但是如果当你面临的是海量的数据的时候呢?16G、64G、256G甚至1T呢?现在互联网的业务里面,如果你的体量足够大,我觉得是肯定会面临缓存海量缓存数据的场景的。
这就是为什么我们需要引入Redis Cluster。
三、Redis Cluster是什么
知道了为什么需要Redis Cluster之后,我们就可以来对其一探究竟了。
那什么是Redis Cluster呢?
很简单,你就可以理解为n个主从架构组合在一起对外服务。Redis Cluster要求至少需要3个master才能组成一个集群,同时每个master至少需要有一个slave节点。
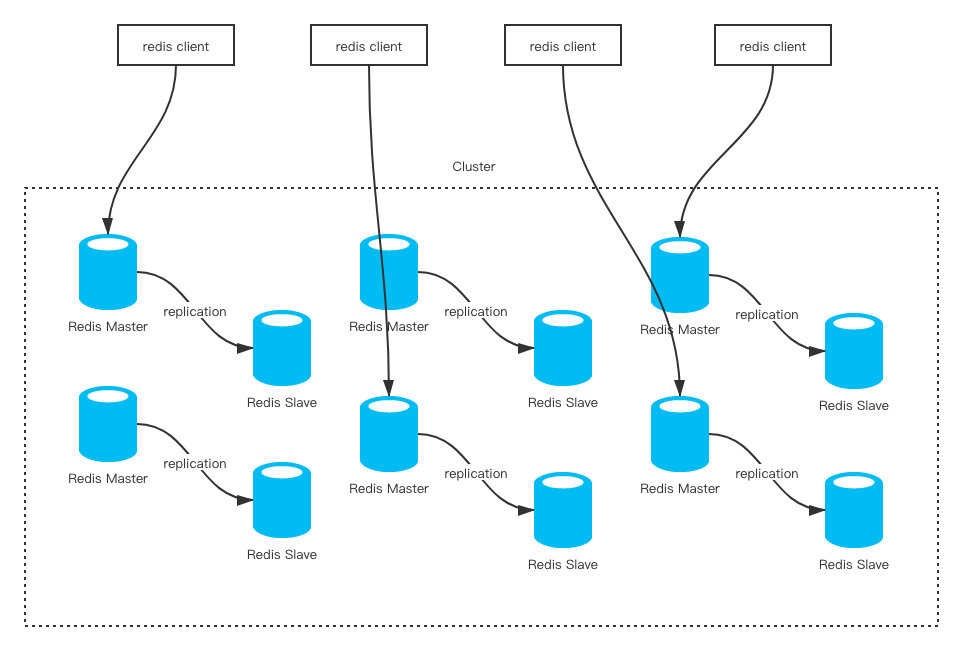
这样一来,如果一个主从能够存储32G的数据,如果这个集群包含了两个主从,则整个集群就能够存储64G的数据。
我们知道,主从架构中,可以通过增加slave节点的方式来扩展读请求的并发量,那Redis Cluster中是如何做的呢?虽然每个master下都挂载了一个slave节点,但是在Redis Cluster中的读、写请求其实都是在master上完成的。
slave节点只是充当了一个数据备份的角色,当master发生了宕机,就会将对应的slave节点提拔为master,来重新对外提供服务。
四、节点负载均衡
知道了什么是Redis Cluster,我们就可以继续下面的讨论了。
不知道你思考过一个问题没,这么多的master节点。我存储的时候,到底该选择哪个节点呢?一般这种负载均衡算法,会选择哈希算法。哈希算法是怎么做的呢?
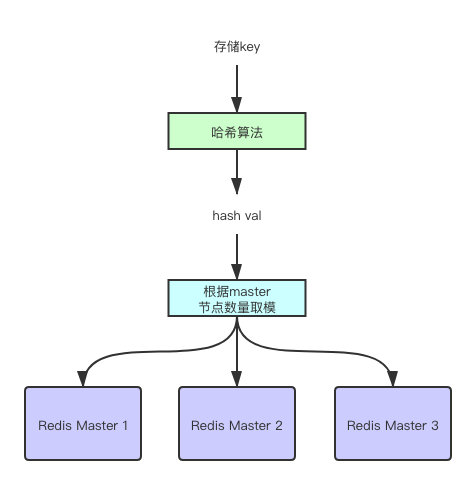
首先就是对key计算出一个hash值,然后用哈希值对master数量进行取模。由此就可以将key负载均衡到每一个Redis节点上去。这就是简单的哈希算法的实现。
那Redis Cluster是采取的上面的哈希算法吗?答案是没有。
Redis Cluster其实采取的是类似于一致性哈希的算法来实现节点选择的。那为什么不用哈希算法来进行实例选择呢?以及为什么说是类似的呢?我们继续讨论。
因为如果此时某一台master发生了宕机,那么此时会导致Redis中所有的缓存失效。为什么是所有的?假设之前有3个master,那么之前的算法应该是 hash % 3,但是如果其中一台master宕机了,则算法就会变成 hash % 2,会影响到之前存储的所有的key。而这对缓存后面保护的DB来说,是致命的打击。
五、什么是一致性哈希
知道了通过传统哈希算法来实现对节点的负载均衡的弊端,我们就需要进一步了解什么是一致性哈希。
我们上面提过哈希算法是对master实例数量来取模,而一致性哈希则是对2^32取模,也就是值的范围在[0, 2^32 -1]。一致性哈希将其范围抽象成了一个圆环,使用CRC16算法计算出来的哈希值会落到圆环上的某个地方。
然后我们的Redis实例也分布在圆环上,我们在圆环上按照顺时针的顺序找到第一个Redis实例,这样就完成了对key的节点分配。我们举个例子。

假设我们有A、B、C三个Redis实例按照如图所示的位置分布在圆环上,此时计算出来的hash值,取模之后位置落在了位置D,那么我们按照顺时针的顺序,就能够找到我们这个key应该分配的Redis实例B。同理如果我们计算出来位置在E,那么对应选择的Redis的实例就是A。
即使这个时候Redis实例B挂了,也不会影响到实例A和C的缓存。
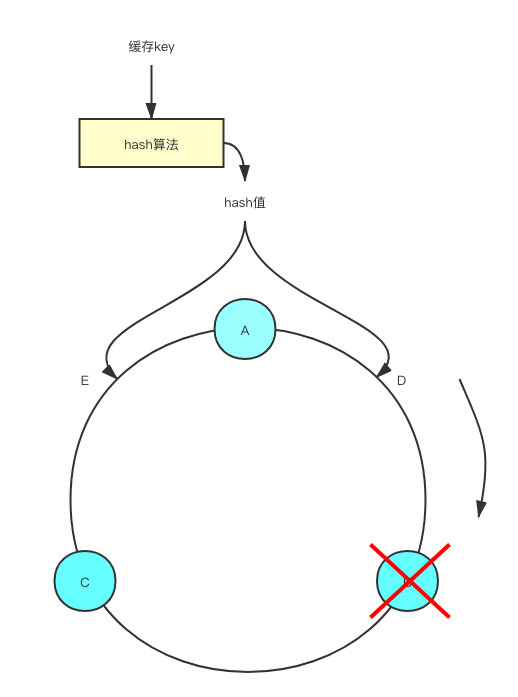
例如此时节点B挂了,那之前计算出来在位置D的key,此时会按照顺时针的顺序,找到节点C。相当于自动的把原来节点B的流量给转移到了节点C上去。而其他原本就在节点A和节点C的数据则完全不受影响。
这就是一致性哈希,能够在我们后续需要新增节点或者删除节点的时候,不影响其他节点的正常运行。
六、虚拟节点机制
但是一致性哈希也存在自身的小问题,例如当我们的Redis节点分布如下时,就有问题了。

此时数据落在节点A上的概率明显是大于其他两个节点的,其次落在节点C上的概率最小。这样一来会导致整个集群的数据存储不平衡,AB节点压力较大,而C节点资源利用不充分。为了解决这个问题,一致性哈希算法引入了虚拟节点机制。
 virtual-dom
virtual-dom
在圆环中,增加了对应节点的虚拟节点,然后完成了虚拟节点到真实节点的映射。假设现在计算得出了位置D,那么按照顺时针的顺序,我们找到的第一个节点就是C #1,最终数据实际还是会落在节点C上。
通过增加虚拟节点的方式,使ABC三个节点在圆环上的位置更加均匀,平均了落在每一个节点上的概率。这样一来就解决了上文提到的数据存储存在不均匀的问题了,这就是一致性哈希的虚拟节点机制。
七、Redis Cluster采用的什么算法
上面提到过,Redis Cluster采用的是类一致性哈希算法,之所以是类一致性哈希算法是因为它们实现的方式还略微有差别。
例如一致性哈希是对2^32取模,而Redis Cluster则是对2^14(也就是16384)取模。Redis Cluster将自己分成了16384个Slot(槽位)。通过CRC16算法计算出来的哈希值会跟16384取模,取模之后得到的值就是对应的槽位,然后每个Redis节点都会负责处理一部分的槽位,就像下表这样。
| 节点 | 处理槽位 |
|---|---|
| A | 0 - 5000 |
| B | 5001 - 10000 |
| C | 10001 - 16383 |
每个Redis实例会自己维护一份slot - Redis节点的映射关系,假设你在节点A上设置了某个key,但是这个key通过CRC16计算出来的槽位是由节点B维护的,那么就会提示你需要去节点B上进行操作。
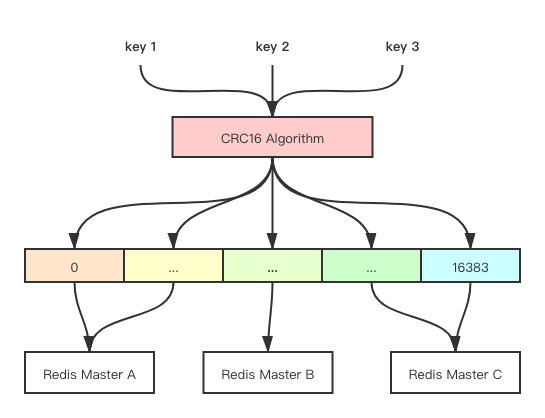 slot-to-node
slot-to-node
八、Redis Cluster如何做到高可用
不知道你思考过一个问题没,如果Redis Cluster中的某个master节点挂了,它是如何保证集群自身的高可用的?如果这个时候我们集群需要扩容节点,它该负责哪些槽位呢?我们一个一个问题的来看一下。
8.1、集群如何进行扩容
我们开篇聊过,Redis Cluster可以很方便的进行横向扩容,那当新的节点加入进来的时候,它是如何获取对应的slot的呢?
答案是通过reshard(重新分片)来实现。reshard可以将已经分配给某个节点的任意数量的slot迁移给另一个节点,在Redis内部是由redis-trib负责执行的。你可以理解为Redis其实已经封装好了所有的命令,而redis-trib则负责向获取slot的节点和被转移slot的节点发送命令来最终实现reshard。
假设我们需要向集群中加入一个D节点,而此时集群内已经有A、B、C三个节点了。
此时redis-trib会向A、B、C三个节点发送迁移出槽位的请求,同时向D节点发送准备导入槽位的请求,做好准备之后A、B、C这三个源节点就开始执行迁移,将对应的slot所对应的键值对迁移至目标节点D。最后redis-trib会向集群中所有主节点发送槽位的变更信息。
8.2、高可用及故障转移
Redis Cluster中保证集群高可用的思路和实现和Redis Sentinel如出一辙
简单来说,针对A节点,某一个节点认为A宕机了,那么此时是主观宕机。而如果集群内超过半数的节点认为A挂了, 那么此时A就会被标记为客观宕机。
一旦节点A被标记为了客观宕机,集群就会开始执行故障转移。其余正常运行的master节点会进行投票选举,从A节点的slave节点中选举出一个,将其切换成新的master对外提供服务。当某个slave获得了超过半数的master节点投票,就成功当选。
 cluster-failover
cluster-failover
当选成功之后,新的master会执行slaveof no one来让自己停止复制A节点,使自己成为master。然后将A节点所负责处理的slot,全部转移给自己,然后就会向集群发PONG消息来广播自己的最新状态。
按照一致性哈希的思想,如果某个节点挂了,那么就会沿着那个圆环,按照顺时针的顺序找到遇到的第一个Redis实例。
而对于Redis Cluster,某个key它其实并不关心它最终要去到哪个节点,他只关心他最终落到哪个slot上,无论你节点怎么去迁移,最终还是只需要找到对应的slot,然后再找到slot关联的节点,最终就能够找到最终的Redis实例了。
那这个PONG消息又是什么东西呢?别急,下面就会聊到。
九、简单了解gossip协议
这就是Redis Cluster各个节点之间交换数据、通信所采用的一种协议,叫做gossip。
gossip: 流言、八卦、小道消息
gossip是在1989年的论文上提出的,我看了一堆资料都说的是1987年发表的,但是文章里的时间明确是1989年1月份发表。
 image-20201215100703648
image-20201215100703648
感兴趣的可以去看看Epidemic Algorithms for Replicated . Database Maintenance,在当时提出gossip主要是为了解决在分布式数据库中,各个副本节点的数据同步问题。但随着技术的发展,gossip后续也被广泛运用于信息扩散、故障探测等等。
Redis Cluster就是利用了gossip来实现自身的信息扩散的。那使用gossip具体是如何通信的呢?
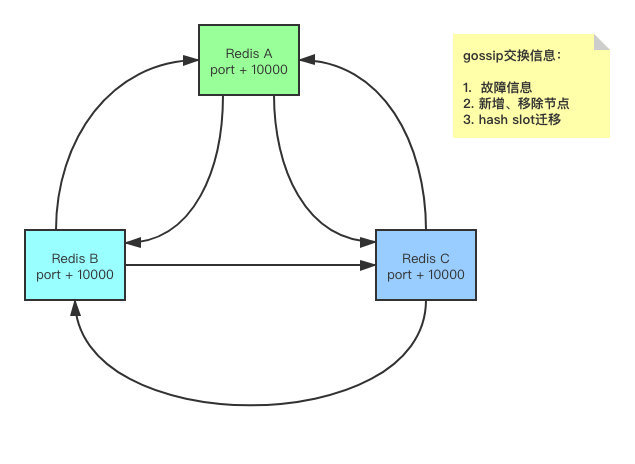 gossip
gossip
很简单,就像图里这样。每个Redis节点每秒钟都会向其他的节点发送PING,然后被PING的节点会回一个PONG。
十、gossip协议消息类型
Redis Cluster中,节点之间的消息类型有5种,分别是MEET、PING、PONG、FAIL和PUBLISH。这些消息分别传递了什么内容呢?我简单总结了一下。
| 消息类型 | 消息内容 |
|---|---|
| MEET | 给某个节点发送MEET消息,请求接收消息的节点加入到集群中 |
| PING | 每隔一秒钟,选择5个最久没有通信的节点,发送PING消息,检测对应的节点是否在线;同时还有一种策略是,如果某个节点的通信延迟大于了cluster-node-time的值的一半,就会立即给该节点发送PING消息,避免数据交换延迟过久 |
| PONG | 当节点接收到MEET或者PING消息之后,会回一个PONG消息给发送方,代表自己收到了MEET或者PING消息。同时,节点也可以主动的通过PONG消息向集群中广播自己的信息,让其他节点获取到自己最新的属性,就像完成了故障转移之后新的master向集群发送PONG消息一样 |
| FAIL | 用于广播自己的对某个节点的宕机判断,假设当前节点对A节点判断为宕机,就会立即向Redis Cluster广播自己对于A节点的判断,所有收到消息的节点就会对A节点做标记 |
| PUBLISH | 用于向指定的Channel发送消息,某个节点收到PUBLISH消息之后会直接在集群内广播,这样一来,客户端无论连接到任何节点都能够订阅这个Channel |
十一、使用gossip的优劣
既然Redis Cluster选择了gossip,那肯定存在一些gossip的优点,我们接下来简单梳理一下。
| 优点 | 描述 |
|---|---|
| 扩展性 | 网络可以允许节点的任意增加和减少,新增加的节点的状态最终会与其他节点一致。 |
| 容错性 | 由于每个节点都持有一份完整元数据,所以任何节点宕机都不会影响gossip的运行 |
| 健壮性 | 与容错性类似,由于所有节点都持有数据,地位平台,是一个去中心化的设计,任何节点都不会影响到服务的运行 |
| 最终一致性 | 当有新的信息需要传递时,消息可以快速的发送到所有的节点,让所有的节点都拥有最新的数据 |
gossip可以在O(logN) 轮就可以将信息传播到所有的节点,为什么是O(logN)呢?因为每次ping,当前节点会带上自己的信息外加整个Cluster的1/10数量的节点信息,一起发送出去。你可以简单的把这个模型抽象为:
你转发了一个特别有意思的文章到朋友圈,然后你的朋友们都觉得还不错,于是就一传十、十传百这样的散播出去了,这就是朋友圈的裂变传播。
当然,gossip仍然存在一些缺点。例如消息可能最终会经过很多轮才能到达目标节点,而这可能会带来较大的延迟。同时由于节点会随机选出5个最久没有通信的节点,这可能会造成某一个节点同时收到n个重复的消息。
十二、总结
总的来说,Redis Cluster相当于是把Redis的主从架构和Sentinel集成到了一起,从Redis Cluster的高可用机制、判断故障转移以及执行故障转移的过程,都和主从、Sentinel相关,这也是为什么我在之前的文章里说,主从是Redis高可用架构的基石。
以上就是解析Redis Cluster原理的详细内容,更多关于Redis Cluster的资料请关注我们其它相关文章!
相关推荐
-
Redis cluster集群的介绍
1.前言 Redis集群模式主要有2种: 主从集群.分布式集群. 前者主要是为了高可用或是读写分离,后者为了更好的存储数据,负载均衡. redis集群提供了以下两个好处 1.将数据自动切分(split)到多个节点 2.当集群中的某一个节点故障时,redis还可以继续处理客户端的请求. 一个 redis 集群包含 16384 个哈希槽(hash slot),数据库中的每个数据都属于这16384个哈希槽中的一个.集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽.集群中
-
Redis Cluster添加、删除的完整操作步骤
前言 最近学习了Redis,发现Redis还是挺好玩的,今天测试了集群的添加.删除节点.重分配slot等.更深入的理解redis的游戏规则.步骤繁多,但是详细,话不多说了,来一起看看详细的介绍吧. 环境解释: 我是在一台Centos 6.9上测试的,各个redis节点以端口号区分.文中针对各个redis,我只是以端口号代表. ~~~~Master Node~~~~~ 172.16.32.116:7000 172.16.32.116:7001 172.16.32.116:7002 ~~~~Slav
-
docker redis5.0 cluster集群搭建的实现
系统环境:ubuntu16.04LTS 本文是使用 6 个 docker 容器搭建单机集群测试,实际环境如果是多台,可对应修改容器数量.端口号和集群 ip 地址,每台机器都按下面步骤同样操作即可. 拉取redis官方镜像 docker pull redis:5.0 创建配置文件和数据目录 创建目录 mkdir ~/redis_cluster cd ~/redis_cluster 新建一个模板文件sudo vim redis_cluster.tmpl,填入如下内容: # redis端口 port
-
Windows环境下Redis Cluster环境搭建(图文)
搭建 Redis集群,三个主节点,三个从节点,多主节点为了分布集群,从节点是为了高可用性. 1. 下载redis 地址:https://github.com/MicrosoftArchive/redis/releases 此次案例中使用的版本为3.0.503 Source code可以一起下载,下文会用到. 2. 安装redis 解压Redis-x64-3.0.503.zip,并复制,如下图 3. 修改每台redis.windows.conf,修改里面的端口号,以及集群的配置 port 6380
-
Redis Cluster集群数据分片机制原理
Redis Cluster数据分片机制 Redis 集群简介 Redis Cluster 是 Redis 的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 分布式方面的需求. Redis Cluster 一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为主节点,三个为从节点.三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点. 如上图所示,该集群中包含 6 个 Redis 节点,3主3从,分别为M1,M2,M3,S
-
spring集成redis cluster详解
客户端采用最新的jedis 2.7 1.maven依赖: <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.7.3</version> </dependency> 2.增加spring 配置 <bean name="genericObjectPoolConfig"
-

使用Ruby脚本部署Redis Cluster集群步骤讲解
安装Ruby和Gem 下载ruby wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.8.tar.gz 解压 tar xvf ruby-2.3.8.tar.gz 生成Makefile并且后面会被安装到/usr/local/ruby目录下 ./configure -prefix /usr/local/ruby 编译 make 安装 make install cd /usr/local/ruby cp bin/ruby /usr/local
-
详解SpringBoot Redis自适应配置(Cluster Standalone Sentinel)
核心代码段 提供一个JedisConnectionFactory 根据配置来判断 单点 集群 还是哨兵 @Bean @ConditionalOnMissingBean public JedisConnectionFactory jedisConnectionFactory() { JedisConnectionFactory factory = null; String[] split = node.split(","); Set<HostAndPort> nodes =
-
php成功操作redis cluster集群的实例教程
前言 java操作redis cluster集群可使用jredis php要操作redis cluster集群有两种方式: 1.使用phpredis扩展,这是个c扩展,性能更高,但是phpredis2.x扩展不行,需升级phpredis到3.0,但这个方案参考资料很少 2.使用predis,纯php开发,使用了命名空间,需要php5.3+,灵活性高 我用的是predis,下载地址:点击这里 步骤如下: 下载好后重命名为predis, server1:192.168.1.198 server2:1
-
如何用docker部署redis cluster的方法
前言 由于本人是个docker控,不喜欢安装各种环境,而且安装redis-trib也有点繁琐,索性用docker来做redis cluster. 本文用的是伪集群,真正的集群放到不同的机器即可.端口是7001-7006. 工作目录: /data/redis 创建文件夹 首先创建一堆对应端口的文件夹,下面是脚本 create.sh for i in `seq 7001 7006` do mkdir -p ${i}/data done 添加执行权限并执行 chmod 777 create.sh ./