Python实现对照片中的人脸进行颜值预测
一、所需工具
**Python版本:**3.5.4(64bit)
二、相关模块
- opencv_python模块
- sklearn模块
- numpy模块
- dlib模块
- 一些Python自带的模块。
三、环境搭建
(1)安装相应版本的Python并添加到环境变量中;
(2)pip安装相关模块中提到的模块。
例如:

若pip安装报错,请自行到:
http://www.lfd.uci.edu/~gohlke/pythonlibs/
下载pip安装报错模块的whl文件,并使用:
pip install whl文件路径+whl文件名安装。
例如:
(已在相关文件中提供了编译好的用于dlib库安装的whl文件——>因为这个库最不好装)

参考文献链接
【1】xxxPh.D.的博客
http://www.learnopencv.com/computer-vision-for-predicting-facial-attractiveness/
【2】华南理工大学某实验室
http://www.hcii-lab.net/data/SCUT-FBP/EN/introduce.html
四、主要思路
(1)模型训练
用了PCA算法对特征进行了压缩降维;
然后用随机森林训练模型。
数据源于网络,据说数据“发源地”就是华南理工大学某实验室,因此我在参考文献上才加上了这个实验室的链接。
(2)提取人脸关键点
主要使用了dlib库。
使用官方提供的模型构建特征提取器。
(3)特征生成
完全参考了xxxPh.D.的博客。
(4)颜值预测
利用之前的数据和模型进行颜值预测。
使用方式
有特殊疾病者请慎重尝试预测自己的颜值,本人不对颜值预测的结果和带来的所有负面影响负责!!!
言归正传。
环境搭建完成后,解压相关文件中的Face_Value.rar文件,cmd窗口切换到解压后的*.py文件所在目录。
例如:
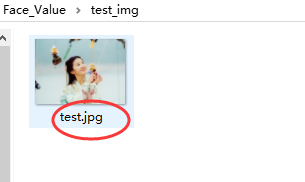
打开test_img文件夹,将需要预测颜值的照片放入并重命名为test.jpg。
例如:
若嫌麻烦或者有其他需求,请自行修改:
getLandmarks.py文件中第13行。
最后依次运行:
train_model.py(想直接用我模型的请忽略此步)
# 模型训练脚本
import numpy as np
from sklearn import decomposition
from sklearn.ensemble import RandomForestRegressor
from sklearn.externals import joblib
# 特征和对应的分数路径
features_path = './data/features_ALL.txt'
ratings_path = './data/ratings.txt'
# 载入数据
# 共500组数据
# 其中前480组数据作为训练集,后20组数据作为测试集
features = np.loadtxt(features_path, delimiter=',')
features_train = features[0: -20]
features_test = features[-20: ]
ratings = np.loadtxt(ratings_path, delimiter=',')
ratings_train = ratings[0: -20]
ratings_test = ratings[-20: ]
# 训练模型
# 这里用PCA算法对特征进行了压缩和降维。
# 降维之后特征变成了20维,也就是说特征一共有500行,每行是一个人的特征向量,每个特征向量有20个元素。
# 用随机森林训练模型
pca = decomposition.PCA(n_components=20)
pca.fit(features_train)
features_train = pca.transform(features_train)
features_test = pca.transform(features_test)
regr = RandomForestRegressor(n_estimators=50, max_depth=None, min_samples_split=10, random_state=0)
regr = regr.fit(features_train, ratings_train)
joblib.dump(regr, './model/face_rating.pkl', compress=1)
# 训练完之后提示训练结束
print('Generate Model Successfully!')
getLandmarks.py
# 人脸关键点提取脚本
import cv2
import dlib
import numpy
# 模型路径
PREDICTOR_PATH = './model/shape_predictor_68_face_landmarks.dat'
# 使用dlib自带的frontal_face_detector作为人脸提取器
detector = dlib.get_frontal_face_detector()
# 使用官方提供的模型构建特征提取器
predictor = dlib.shape_predictor(PREDICTOR_PATH)
face_img = cv2.imread("test_img/test.jpg")
# 使用detector进行人脸检测,rects为返回的结果
rects = detector(face_img, 1)
# 如果检测到人脸
if len(rects) >= 1:
print("{} faces detected".format(len(rects)))
else:
print('No faces detected')
exit()
with open('./results/landmarks.txt', 'w') as f:
f.truncate()
for faces in range(len(rects)):
# 使用predictor进行人脸关键点识别
landmarks = numpy.matrix([[p.x, p.y] for p in predictor(face_img, rects[faces]).parts()])
face_img = face_img.copy()
# 使用enumerate函数遍历序列中的元素以及它们的下标
for idx, point in enumerate(landmarks):
pos = (point[0, 0], point[0, 1])
f.write(str(point[0, 0]))
f.write(',')
f.write(str(point[0, 1]))
f.write(',')
f.write('\n')
f.close()
# 成功后提示
print('Get landmarks successfully')
getFeatures.py
# 特征生成脚本
# 具体原理请参见参考论文
import math
import numpy
import itertools
def facialRatio(points):
x1 = points[0]
y1 = points[1]
x2 = points[2]
y2 = points[3]
x3 = points[4]
y3 = points[5]
x4 = points[6]
y4 = points[7]
dist1 = math.sqrt((x1-x2)**2 + (y1-y2)**2)
dist2 = math.sqrt((x3-x4)**2 + (y3-y4)**2)
ratio = dist1/dist2
return ratio
def generateFeatures(pointIndices1, pointIndices2, pointIndices3, pointIndices4, allLandmarkCoordinates):
size = allLandmarkCoordinates.shape
if len(size) > 1:
allFeatures = numpy.zeros((size[0], len(pointIndices1)))
for x in range(0, size[0]):
landmarkCoordinates = allLandmarkCoordinates[x, :]
ratios = []
for i in range(0, len(pointIndices1)):
x1 = landmarkCoordinates[2*(pointIndices1[i]-1)]
y1 = landmarkCoordinates[2*pointIndices1[i] - 1]
x2 = landmarkCoordinates[2*(pointIndices2[i]-1)]
y2 = landmarkCoordinates[2*pointIndices2[i] - 1]
x3 = landmarkCoordinates[2*(pointIndices3[i]-1)]
y3 = landmarkCoordinates[2*pointIndices3[i] - 1]
x4 = landmarkCoordinates[2*(pointIndices4[i]-1)]
y4 = landmarkCoordinates[2*pointIndices4[i] - 1]
points = [x1, y1, x2, y2, x3, y3, x4, y4]
ratios.append(facialRatio(points))
allFeatures[x, :] = numpy.asarray(ratios)
else:
allFeatures = numpy.zeros((1, len(pointIndices1)))
landmarkCoordinates = allLandmarkCoordinates
ratios = []
for i in range(0, len(pointIndices1)):
x1 = landmarkCoordinates[2*(pointIndices1[i]-1)]
y1 = landmarkCoordinates[2*pointIndices1[i] - 1]
x2 = landmarkCoordinates[2*(pointIndices2[i]-1)]
y2 = landmarkCoordinates[2*pointIndices2[i] - 1]
x3 = landmarkCoordinates[2*(pointIndices3[i]-1)]
y3 = landmarkCoordinates[2*pointIndices3[i] - 1]
x4 = landmarkCoordinates[2*(pointIndices4[i]-1)]
y4 = landmarkCoordinates[2*pointIndices4[i] - 1]
points = [x1, y1, x2, y2, x3, y3, x4, y4]
ratios.append(facialRatio(points))
allFeatures[0, :] = numpy.asarray(ratios)
return allFeatures
def generateAllFeatures(allLandmarkCoordinates):
a = [18, 22, 23, 27, 37, 40, 43, 46, 28, 32, 34, 36, 5, 9, 13, 49, 55, 52, 58]
combinations = itertools.combinations(a, 4)
i = 0
pointIndices1 = []
pointIndices2 = []
pointIndices3 = []
pointIndices4 = []
for combination in combinations:
pointIndices1.append(combination[0])
pointIndices2.append(combination[1])
pointIndices3.append(combination[2])
pointIndices4.append(combination[3])
i = i+1
pointIndices1.append(combination[0])
pointIndices2.append(combination[2])
pointIndices3.append(combination[1])
pointIndices4.append(combination[3])
i = i+1
pointIndices1.append(combination[0])
pointIndices2.append(combination[3])
pointIndices3.append(combination[1])
pointIndices4.append(combination[2])
i = i+1
return generateFeatures(pointIndices1, pointIndices2, pointIndices3, pointIndices4, allLandmarkCoordinates)
landmarks = numpy.loadtxt("./results/landmarks.txt", delimiter=',', usecols=range(136))
featuresALL = generateAllFeatures(landmarks)
numpy.savetxt("./results/my_features.txt", featuresALL, delimiter=',', fmt = '%.04f')
print("Generate Feature Successfully!")
Predict.py
# 颜值预测脚本
from sklearn.externals import joblib
import numpy as np
from sklearn import decomposition
pre_model = joblib.load('./model/face_rating.pkl')
features = np.loadtxt('./data/features_ALL.txt', delimiter=',')
my_features = np.loadtxt('./results/my_features.txt', delimiter=',')
pca = decomposition.PCA(n_components=20)
pca.fit(features)
predictions = []
if len(my_features.shape) > 1:
for i in range(len(my_features)):
feature = my_features[i, :]
feature_transfer = pca.transform(feature.reshape(1, -1))
predictions.append(pre_model.predict(feature_transfer))
print('照片中的人颜值得分依次为(满分为5分):')
k = 1
for pre in predictions:
print('第%d个人:' % k, end='')
print(str(pre)+'分')
k += 1
else:
feature = my_features
feature_transfer = pca.transform(feature.reshape(1, -1))
predictions.append(pre_model.predict(feature_transfer))
print('照片中的人颜值得分为(满分为5分):')
k = 1
for pre in predictions:
print(str(pre)+'分')
k += 1
到此这篇关于Python实现对照片中的人脸进行颜值预测的文章就介绍到这了,更多相关Python对人脸进行颜值预测内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

10分钟学会使用python实现人脸识别(附源码)
前言 今天,我们用Python实现简单的人脸识别技术! Python里,简单的人脸识别有很多种方法可以实现,依赖于python胶水语言的特性,我们通过调用包可以快速准确的达成这一目的.这里介绍的是准确性比较高的一种. 一.首先 梳理一下实现人脸识别需要进行的步骤: 流程大致如此,在此之前,要先让人脸被准确的找出来,也就是能准确区分人脸的分类器,在这里我们可以用已经训练好的分类器,网上种类较全,分类准确度也比较高,我们也可以节约在这方面花的时间. 既然用的是python,那自然少不了包的使用了,在
-
Python3 利用face_recognition实现人脸识别的方法
前言 之前实践了下face++在线人脸识别版本,这回做一下离线版本.github 上面有关于face_recognition的相关资料,本人只是做个搬运工,对其中的一些内容进行搬运,对其中一些例子进行实现. 官方描述: face_recognition是一个强大.简单.易上手的人脸识别开源项目,并且配备了完整的开发文档和应用案例,特别是兼容树莓派系统.本项目是世界上最简洁的人脸识别库,你可以使用Python和命令行工具提取.识别.操作人脸.本项目的人脸识别是基于业内领先的C++开源库 dlib中
-
用Python实现简单的人脸识别功能步骤详解
前言 让我的电脑认识我,我的电脑只有认识我,才配称之为我的电脑! 今天,我们用Python实现简单的人脸识别技术! Python里,简单的人脸识别有很多种方法可以实现,依赖于python胶水语言的特性,我们通过调用包可以快速准确的达成这一目的.这里介绍的是准确性比较高的一种. 一.首先 梳理一下实现人脸识别需要进行的步骤: 流程大致如此,在此之前,要先让人脸被准确的找出来,也就是能准确区分人脸的分类器,在这里我们可以用已经训练好的分类器,网上种类较全,分类准确度也比较高,我们也可以节约在这方面花
-
python实现的人脸识别打卡系统
项目地址: https://github.com/king-xw/Face_Recogntion 简介 本仓库是使用python编写的一个简单的人脸识别考勤打卡系统 主要功能有录入人脸信息.人脸识别打卡.设置上下班时间.导出打卡日志等 下面是各模块截图 首页 录入人脸信息 人脸识别打卡 输出日志 使用 直接运行**==workAttendanceSystem==**.py即可 主要代码 import datetime import time import win32api import win3
-
python3.8动态人脸识别的实现示例
一.准备依赖库 pip install dlib pip python-opencv 二.代码实现 #coding: utf-8 """ 从视屏中识别人脸,并实时标出面部特征点 """ import dlib #人脸识别的库dlib import cv2 #图像处理的库OpenCv # 使用特征提取器get_frontal_face_detector detector = dlib.get_frontal_face_detector() # 读
-
如何通过python实现人脸识别验证
这篇文章主要介绍了如何通过python实现人脸识别验证,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 直接上代码,此案例是根据https://github.com/caibojian/face_login修改的,识别率不怎么好,有时挡了半个脸还是成功的 # -*- coding: utf-8 -*- # __author__="maple" """ ┏┓ ┏┓ ┏┛┻━━━┛┻┓ ┃ ☃ ┃ ┃ ┳┛ ┗
-
Python实现对照片中的人脸进行颜值预测
一.所需工具 **Python版本:**3.5.4(64bit) 二.相关模块 opencv_python模块 sklearn模块 numpy模块 dlib模块 一些Python自带的模块. 三.环境搭建 (1)安装相应版本的Python并添加到环境变量中: (2)pip安装相关模块中提到的模块. 例如: 若pip安装报错,请自行到: http://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载pip安装报错模块的whl文件,并使用: pip install whl
-
python+opencv实现的简单人脸识别代码示例
# 源码如下: #!/usr/bin/env python #coding=utf-8 import os from PIL import Image, ImageDraw import cv def detect_object(image): '''检测图片,获取人脸在图片中的坐标''' grayscale = cv.CreateImage((image.width, image.height), 8, 1) cv.CvtColor(image, grayscale, cv.CV_BGR2GR
-
Python OpenCV调用摄像头检测人脸并截图
本文实例为大家分享了Python OpenCV调用摄像头检测人脸并截图的具体代码,供大家参考,具体内容如下 注意:需要在python中安装OpenCV库,同时需要下载OpenCV人脸识别模型haarcascade_frontalface_alt.xml,模型可在OpenCV-PCA-KNN-SVM_face_recognition中下载. 使用OpenCV调用摄像头检测人脸并连续截图100张 #-*- coding: utf-8 -*- # import 进openCV的库 import cv2
-
Python使用百度api做人脸对比的方法
安装SDK: pip install baidu-aip 如果在pycharm里也可以在setting----Project Interpreter---右边绿色加号,输入baidu,安装baidu-aip 入门代码: 先去百度AI开放平台注册一个账号,然后开通人脸识别,免费的 http://ai.baidu.com/tech/face 之后把得到的Api key secretkey 填进去. from aip import AipFace """ 你的 APPID AK S
-
浅析Python+OpenCV使用摄像头追踪人脸面部血液变化实现脉搏评估
使用摄像头追踪人脸由于血液流动引起的面部色素的微小变化实现实时脉搏评估. 效果如下(演示视频): 由于这是通过比较面部色素的变化评估脉搏所以光线.人体移动.不同角度.不同电脑摄像头等因素均会影响评估效果,实验原理是面部色素对比,识别效果存在一定误差,各位小伙伴且当娱乐,代码如下: import cv2 import numpy as np import dlib import time from scipy import signal # Constants WINDOW_TITLE = 'Pu
-
Python下应用opencv 实现人脸检测功能
使用OpenCV's Haar cascades作为人脸检测,因为他做好了库,我们只管使用. 代码简单,除去注释,总共有效代码只有10多行. 所谓库就是一个检测人脸的xml 文件,可以网上查找,下面是一个地址: https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml 如何构造这个库,学习完本文后可以参考: http://note.sonots.com/Sc
-
python openCV实现摄像头获取人脸图片
本文实例为大家分享了python openCV实现摄像头获取人脸图片的具体代码,供大家参考,具体内容如下 在机器学习中,训练模型需要大量图片,通过openCV中的库可以快捷的调用摄像头,截取图片,可以快速的获取大量人脸图片 需要注意将CascadeClassifier方法中的地址改为自己包cv2包下面的文件 import cv2 def load_img(path,name,mun = 100,add_with = 0): # 获取人脸识别模型 # # #以下路径需要更改为自己环境下xml文件
-
Python用dilb提取照片上人脸的示例
上代码: #coding=utf-8 import cv2 import dlib path = "imagePath/9.jpg" img = cv2.imread(path) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #人脸分类器 detector = dlib.get_frontal_face_detector() # 获取人脸检测器 predictor = dlib.shape_predictor( "shape_pre
-
python调用百度API实现人脸识别
1.代码 from aip import AipFace import cv2 import time import base64 from PIL import Image from io import BytesIO import pyttsx3 # """ 你的 APPID AK SK """ APP_ID = '1965####' API_KEY = 'YXL65ekIloykyjrT4kzc####' SECRET_KEY = 'lFi
-
python实现图片,视频人脸识别(dlib版)
图片人脸检测 #coding=utf-8 import cv2 import dlib path = "img/meinv.png" img = cv2.imread(path) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #人脸分类器 detector = dlib.get_frontal_face_detector() # 获取人脸检测器 predictor = dlib.shape_predictor( "C:\\Pytho