Python 统计列表中重复元素的个数并返回其索引值的实现方法
需求:统计列表list1中元素3的个数,并返回每个元素的索引
list1 = [3, 3, 8, 9, 2, 10, 6, 2, 8, 3, 4, 5, 5, 4, 1, 5, 9, 7, 10, 2]
在实际工程中,可能会遇到以上需求,统计元素个数使用list.count()方法即可,不做多余说明
返回每个元素的索引需要做一些转换,简单整理了几个实现方法
1 list.index()方法
list.index()方法返回列表中首个元素的索引,当有重复元素时,可以通过更改index()方法__start参数来更改起始索引
找到一个元素后,将起始索引替换为该元素的下一个索引,继续进行查找,直到找到所有的元素索引
list1 = [3, 3, 8, 9, 2, 10, 6, 2, 8, 3, 4, 5, 5, 4, 1, 5, 9, 7, 10, 2]
count = list1.count(3)
index_list = []
index = -1
# 通过list.index()方法的__start参数,指定起始索引
for i in range(0, count):
index = list1.index(3, index + 1)
index_list.append(index)
print(index_list)
结果如下:
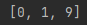
2 通过索引遍历原列表,对每一个元素进行判断
通过索引遍历原列表,对每一个元素进行判断,如果元素是目标元素,则返回对应索引值,示例如下:
list1 = [3, 3, 8, 9, 2, 10, 6, 2, 8, 3, 4, 5, 5, 4, 1, 5, 9, 7, 10, 2]
list1_len = len(list1)
index_list = []
for i in range(0, list1_len):
if list1[i] == 3:
index_list.append(i)
print(index_list)
结果同上
3 enumerate()函数和列表推导式
使用enumerate()函数返回可解析的index-value列表,然后使用列表推导式,同时使用if条件过滤得到目标值的索引,示例如下:
list1 = [3, 3, 8, 9, 2, 10, 6, 2, 8, 3, 4, 5, 5, 4, 1, 5, 9, 7, 10, 2] index_list = [a for a, b in enumerate(list1) if b == 3] print(index_list)
结果同上
各位大佬有好的实现方法可以在下方评论分享一下
到此这篇关于Python 统计列表中重复元素的个数并返回其索引值的文章就介绍到这了,更多相关Python 统计列表元素内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 输出列表元素实例(以空格/逗号为分隔符)
给定list,如何以空格/逗号等符号以分隔符输出呢? 一般的,简单的for循环可以打印出list的内容: l=[1,2,3,4] for i in l: print(i) 输出结果一行一个元素: 1 2 3 4 若想得到以空格或逗号为分隔符的输出结果,代码可改为: l=[1,2,3,4] for i in l: print(i,end=' ')#以空格为分隔符 输出结果为:1 2 3 4 (注意,此时4后面还有一个空格) l=[1,2,3,4] for i in l: print(i,end='
-
Python统计列表元素出现次数的方法示例
1. 引言 在使用Python的时候,通常会出现如下场景: array = [1, 2, 3, 3, 2, 1, 0, 2] 获取array中元素的出现次数 比如,上述列表中:0出现了1次,1出现了2次,2出现了3次,3出现了2次. 本文阐述了Python获取元素出现次数的几种方法.点击获取完整代码. 2. 方法 获取元素出现次数的方法较多,这里我提出如下5个方法,谨供参考.下面的代码,传入的参数均为 array = [1, 2, 3, 3, 2, 1, 0, 2] 2.1 Counter方法
-
python 实现交换两个列表元素的位置示例
在IDLE 中验证如下: >>> numbers = [5, 6, 7] >>> i = 0 >>> numbers[i], numbers[i+1] = numbers[i+1], numbers[i] >>> numbers [6, 5, 7] python是可以一次赋值两个变量的!谢谢! 以上这篇python 实现交换两个列表元素的位置示例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python删除列表元素的三种方法(remove,pop,del)
remove 删除单个元素,删除首个符合条件的元素,按值删除,返回值为空 List_remove = [1, 2, 2, 2, 3, 4] print(List_remove.remove(2)) print("after remove", List_remove) # None # after remove [1, 2, 2, 3, 4] -------------------------------------------------------------------------
-
python中列表元素连接方法join用法实例
本文实例讲述了python中列表元素连接方法join用法.分享给大家供大家参考.具体分析如下: 创建列表: >>> music = ["Abba","Rolling Stones","Black Sabbath","Metallica"] >>> print music 输出: ['Abba', 'Rolling Stones', 'Black Sabbath', 'Metallica']
-
Python中列表元素转为数字的方法分析
本文实例讲述了Python中列表元素转为数字的方法.分享给大家供大家参考,具体如下: 有一个数字字符的列表: numbers = ['1', '5', '10', '8'] 想要把每个元素转换为数字: numbers = [1, 5, 10, 8] 用一个循环来解决: new_numbers = []; for n in numbers: new_numbers.append(int(n)); numbers = new_numbers; 有没有更简单的语句可以做到呢? 1. numbers =
-

Python 统计列表中重复元素的个数并返回其索引值的实现方法
需求:统计列表list1中元素3的个数,并返回每个元素的索引 list1 = [3, 3, 8, 9, 2, 10, 6, 2, 8, 3, 4, 5, 5, 4, 1, 5, 9, 7, 10, 2] 在实际工程中,可能会遇到以上需求,统计元素个数使用list.count()方法即可,不做多余说明 返回每个元素的索引需要做一些转换,简单整理了几个实现方法 1 list.index()方法 list.index()方法返回列表中首个元素的索引,当有重复元素时,可以通过更改index()方法__s
-
Python3查找列表中重复元素的个数的3种方法详解
方法一: mylist = [1,2,2,2,2,3,3,3,4,4,4,4] myset = set(mylist) for item in myset: print("the %d has found %d" %(item,mylist.count(item))) the 1 has found 1 the 2 has found 4 the 3 has found 3 the 4 has found 4 方法二: from collections import Counter C
-
python 统计列表中不同元素的数量方法
刚刚上网搜了一下如何用python统计列表中不同元素的数量,发现很少,找了半天.我自己来写一种方法. 代码如下 list=[1,1,2,2,3] print(list) set1=set(list) print(set1) print(len(set1)) #len(set1)即为列表中不同元素的数量 得到结果: [1, 1, 2, 2, 3] {1, 2, 3} 3 原理就是set集合中不允许重复元素出现. 以上这篇python 统计列表中不同元素的数量方法就是小编分享给大家的全部内容了,希望
-
Python去除列表中重复元素的方法
本文实例讲述了Python去除列表中重复元素的方法.分享给大家供大家参考.具体如下: 比较容易记忆的是用内置的set l1 = ['b','c','d','b','c','a','a'] l2 = list(set(l1)) print l2 还有一种据说速度更快的,没测试过两者的速度差别 l1 = ['b','c','d','b','c','a','a'] l2 = {}.fromkeys(l1).keys() print l2 这两种都有个缺点,祛除重复元素后排序变了: ['a', 'c',
-
Python统计列表中的重复项出现的次数的方法
本文实例展示了Python统计列表中的重复项出现的次数的方法,是一个很实用的功能,适合Python初学者学习借鉴.具体方法如下: 对一个列表,比如[1,2,2,2,2,3,3,3,4,4,4,4],现在我们需要统计这个列表里的重复项,并且重复了几次也要统计出来. 方法1: mylist = [1,2,2,2,2,3,3,3,4,4,4,4] myset = set(mylist) #myset是另外一个列表,里面的内容是mylist里面的无重复 项 for item in myset: prin
-
Python实现去除列表中重复元素的方法总结【7种方法】
这里首先给出来我很早之前写的一篇博客,Python实现去除列表中重复元素的方法小结[4种方法],感兴趣的话可以去看看,今天是在实践过程中又积累了一些方法,这里一并总结放在这里. 由于内容很简单,就不再过多说明了,这里直接上代码,具体如下: # !/usr/bin/env python # -*- coding:utf-8 -*- ''' __Author__:沂水寒城 功能: python列表去除方法总结(7种方法) ''' import sys reload(sys) import copy
-
Python实现去除列表中重复元素的方法小结【4种方法】
本文实例讲述了Python实现去除列表中重复元素的方法.分享给大家供大家参考,具体如下: 这里一共使用了四种方法来去除列表中的重复元素,下面是具体实现: #!usr/bin/env python #encoding:utf-8 ''' __Author__:沂水寒城 功能:去除列表中的重复元素 ''' def func1(one_list): ''''' 使用集合,个人最常用 ''' return list(set(one_list)) def func2(one_list): ''''' 使用
-
python代码实现将列表中重复元素之间的内容全部滤除
1. 引言 因为在学习遗传算法路径规划的内容,其中遗传算法中涉及到了种群的初始化,而在路径规划的种群初始化中,种群初始化就是先找到一条条从起点到终点的路径,也因此需要将路径中重复节点之间的路径删除掉(避免走回头路),这样子初始种群会比较优越,也能加快算法收敛速度.然后我在搜资料的时候发现,许多的代码都是滤除列表中相同元素的,并没有滤除相同元素中间段的代码,因此就自己写了. 2. 代码部分 我在python程序中把每一条路径用列表表示的,因此每一个列表就是一条路径比如 a = [0,1,3,4,5
-
Python实现列表删除重复元素的三种常用方法分析
本文实例讲述了Python实现列表删除重复元素的三种常用方法.分享给大家供大家参考,具体如下: 给定一个列表,要求删除列表中重复元素. listA = ['python','语','言','是','一','门','动','态','语','言'] 方法1,对列表调用排序,从末尾依次比较相邻两个元素,遇重复元素则删除,否则指针左移一位重复上述过程: def deleteDuplicatedElementFromList(list): list.sort(); print("sorted list:%
-
Python 修改列表中的元素方法
如下所示: #打印列表文件 def show_magicians(magics) : for magic in magics : print(magic) #修改列表文件 def make_great(magics) : length=len(magics) for a in range(1,length+1) : magics[a-1]='the Great'+magics[a-1] #输入信息 def input_name(magics) : n=input('请输入魔术师的个数 : ')