Python中Pyspider爬虫框架的基本使用详解
1.pyspider介绍
一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。
- 用Python编写脚本
- 功能强大的WebUI,包含脚本编辑器,任务监视器,项目管理器和结果查看器
- MySQL,MongoDB,Redis,SQLite,Elasticsearch; PostgreSQL与SQLAlchemy作为数据库后端
- RabbitMQ,Beanstalk,Redis和Kombu作为消息队列
- 任务优先级,重试,定期,按年龄重新抓取等...
- 分布式架构,抓取JavaScript页面,Python 2和3等...
2.pyspider文档
1>中文文档:http://www.pyspider.cn/
2>英文文档:http://docs.pyspider.org/
3.pyspider安装
打开cmd命令行工具,执行命令
pip install pyspider
出现下图则安装成功

4.pyspider启动服务,进入WebUI界面
安装pyspider后,打开cmd命令工具,执行命令来启动服务器
pyspider
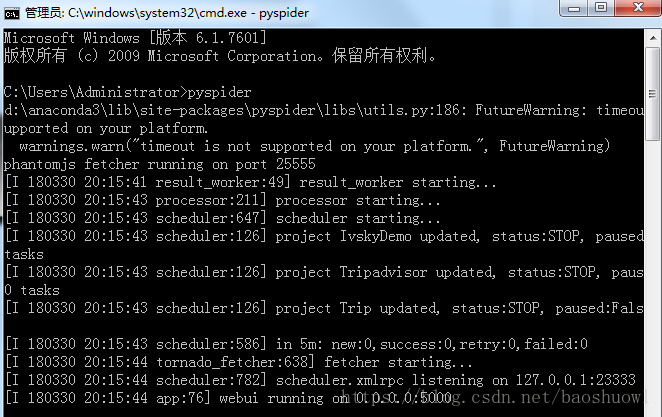
出现下图则启动服务成功,默认地址端口为127.0.0.1:5000
输入地址127.0.0.1:5000,打开WebUI界面
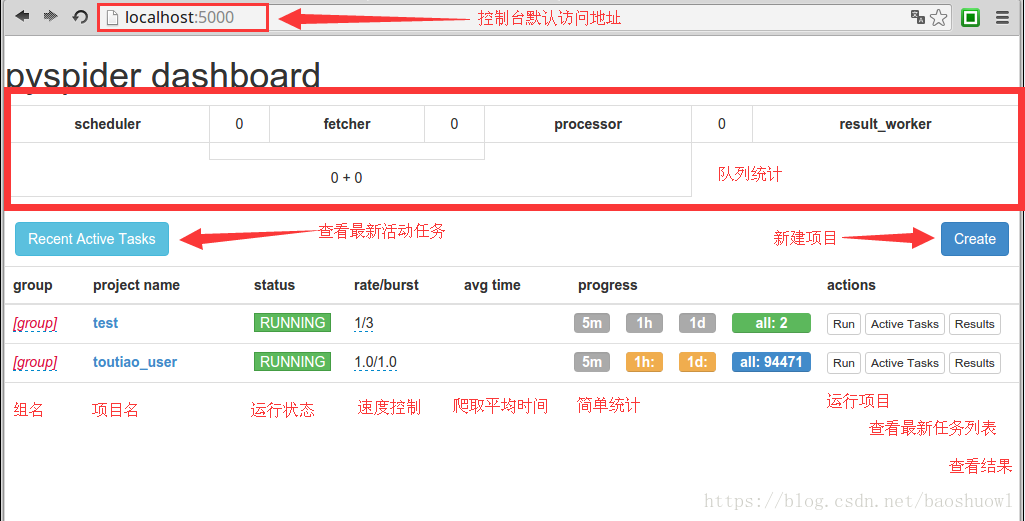
队列统计是为了方便查看爬虫状态,优化爬虫爬取速度新增的状态统计.每个组件之间的数字就是对应不同队列的排队数量.通常来是0或是个位数.如果达到了几十甚至一百说明下游组件出现了瓶颈或错误,需要分析处理.
新建项目:pyspider与scrapy最大的区别就在这,pyspider新建项目调试项目完全在web下进行,而scrapy是在命令行下开发并运行测试.
组名:项目新建后一般来说是不能修改项目名的,如果需要特殊标记可修改组名.直接在组名上点鼠标左键进行修改.注意:组名改为delete后如果状态为stop状态,24小时后项目会被系统删除.
运行状态:这一栏显示的是当前项目的运行状态.每个项目的运行状态都是单独设置的.直接在每个项目的运行状态上点鼠标左键进行修改.运行分为五个状态:TODO,STOP,CHECKING,DEBUG,RUNNING.各状态说明:TODO是新建项目后的默认状态,不会运行项目.STOP状态是停止状态,也不会运行.CHECHING是修改项目代码后自动变的状态.DEBUG是调试模式,遇到错误信息会停止继续运行,RUNNING是运行状态,遇到错误会自动尝试,如果还是错误会跳过错误的任务继续运行.
速度控制:很多朋友安装好用说爬的慢,多数情况是速度被限制了.这个功能就是速度设置项.rate是每秒爬取页面数,burst是并发数.如1/3是三个并发,每秒爬取一个页面.
简单统计:这个功能只是简单的做的运行状态统计,5m是五分钟内任务执行情况,1h是一小时内运行任务统计,1d是一天内运行统计,all是所有的任务统计.
运行:run按钮是项目初次运行需要点的按钮,这个功能会运行项目的on_start方法来生成入口任务.
任务列表:显示最新任务列表,方便查看状态,查看错误等
结果查看:查看项目爬取的结果.
5.创建pyspider项目
点击上图中的新建项目按钮
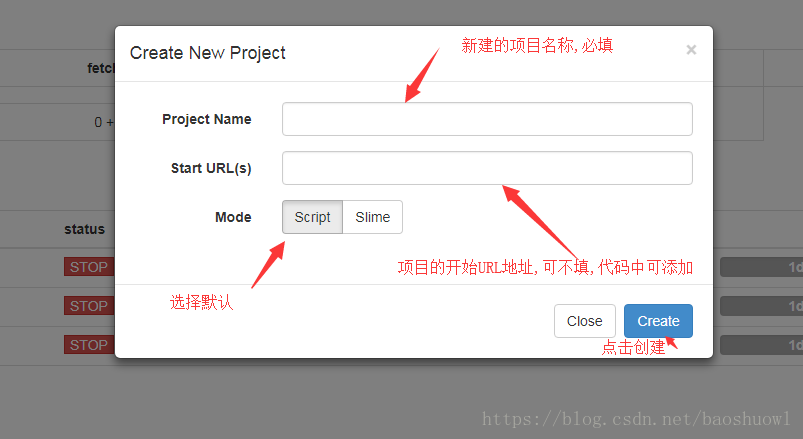
6.创建后的pyspider项目



到此这篇关于Python中Pyspider爬虫框架的基本使用详解的文章就介绍到这了,更多相关Pyspider爬虫框架使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python3爬虫中pyspider的安装步骤
pyspider是国人binux编写的强大的网络爬虫框架,它带有强大的WebUI.脚本编辑器.任务监控器.项目管理器以及结果处理器,同时支持多种数据库后端.多种消息队列,另外还支持JavaScript渲染页面的爬取,使用起来非常方便,本节介绍一下它的安装过程. 1. 相关链接 官方文档:http://docs.pyspider.org/ PyPI:https://pypi.python.org/pypi/pyspider GitHub:https://github.com/binux/pyspi
-
以Python的Pyspider为例剖析搜索引擎的网络爬虫实现方法
在这篇文章中,我们将分析一个网络爬虫. 网络爬虫是一个扫描网络内容并记录其有用信息的工具.它能打开一大堆网页,分析每个页面的内容以便寻找所有感兴趣的数据,并将这些数据存储在一个数据库中,然后对其他网页进行同样的操作. 如果爬虫正在分析的网页中有一些链接,那么爬虫将会根据这些链接分析更多的页面. 搜索引擎就是基于这样的原理实现的. 这篇文章中,我特别选了一个稳定的."年轻"的开源项目pyspider,它是由 binux 编码实现的. 注:据认为pyspider持续监控网络,它假定网页在一
-
Pyspider中给爬虫伪造随机请求头的实例
Pyspider 中采用了 tornado 库来做 http 请求,在请求过程中可以添加各种参数,例如请求链接超时时间,请求传输数据超时时间,请求头等等,但是根据pyspider的原始框架,给爬虫添加参数只能通过 crawl_config这个Python字典来完成(如下所示),框架代码将这个字典中的参数转换成 task 数据,进行http请求.这个参数的缺点是不方便给每一次请求做随机请求头. crawl_config = { "user_agent": "Mozilla/5.
-

Linux/ubuntu 下安装pyspider的过程
首先执行 pip install pyspider 此时系统提示 <span style="font-size: 16px;">Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-Lau0Qp/pycurl/ You are using pip version 9.0.1, however version 9.0.3 is available. Y
-
在centos7中分布式部署pyspider
1.搭建环境: 系统版本:Linux centos-linux.shared 3.10.0-123.el7.x86_64 #1 SMP Mon Jun 30 12:09:22 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux python版本:Python 3.5.1 1.1.搭建python3环境: 本人在尝试过后选择集成环境Anaconda 1.1.1.编译 # 下载依赖 yum install -y ncurses-devel openssl openssl-
-
Python中Pyspider爬虫框架的基本使用详解
1.pyspider介绍 一个国人编写的强大的网络爬虫系统并带有强大的WebUI.采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器. 用Python编写脚本 功能强大的WebUI,包含脚本编辑器,任务监视器,项目管理器和结果查看器 MySQL,MongoDB,Redis,SQLite,Elasticsearch; PostgreSQL与SQLAlchemy作为数据库后端 RabbitMQ,Beanstalk,Redis
-
Python之Scrapy爬虫框架安装及使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. 本文档将
-
python中数据爬虫requests库使用方法详解
一.什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库.它urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 一句话--requests是python实现的简单易用的HTTP库 二.安装Requests库 进入命令行win+R执行 命令:pip install requests 项目导入:import requests 三.各种请求方式 直接上代码,不明白可以查看我的urllib的基
-
Python 中 Virtualenv 和 pip 的简单用法详解
本文介绍了Python 中 Virtualenv 和 pip 的简单用法详解,分享给大家,具体如下: 0X00 安装环境 我们在 Python 开发和学习过程中需要用到各种库,然后在各个不同的项目和作品里可能用的版本还不一样,正因为有这种问题的存在才催生了virtualenv的诞生.virtualenv 可以在电脑上创建一个虚拟环境,可以针对每一个项目创建一个虚拟环境,这样就不用担心各个不同的项目用不同版本的库的时候出现的冲突了. 下面的内容只适用于 Linux/OSX,未经 Windows 环
-
python中函数总结之装饰器闭包详解
1.前言 函数也是一个对象,从而可以增加属性,使用句点来表示属性. 如果内部函数的定义包含了在外部函数中定义的对象的引用(外部对象可以是在外部函数之外),那么内部函数被称之为闭包. 2.装饰器 装饰器就是包装原来的函数,从而在不需要修改原来代码的基础之上,可以做更多的事情. 装饰器语法如下: @deco2 @deco1 def func(arg1,arg2...): pass 这个表示了有两个装饰器的函数,那么表示的含义为:func = deco2(deco1(func)) 无参装饰器语法如下:
-
python中 chr unichr ord函数的实例详解
python中 chr unichr ord函数的实例详解 chr()函数用一个范围在range(256)内的(就是0-255)整数作参数,返回一个对应的字符.unichr()跟它一样,只不过返回的是Unicode字符,这个从Python 2.0才加入的unichr()的参数范围依赖于你的python是如何被编译的.如果是配置为USC2的Unicode,那么它的允许范围就是range(65536)或0x0000-0xFFFF:如果配置为UCS4,那么这个值应该是range(1114112)或0x
-
python中函数默认值使用注意点详解
当在函数中定义默认值时,值初始化只会进行一次,就是执行到def methodname时执行.看下面代码: from datetime import datetime def test(t=datetime.today()): print t if __name__ == "__main__": test() test() 两次方法调用输出的时间都为同一个值,而不是我们预想当前执行时间.对于上面这种情况,建议用下面的方式实现: from datetime import datetime
-
Python中set与frozenset方法和区别详解
set(可变集合)与frozenset(不可变集合)的区别: set无序排序且不重复,是可变的,有add(),remove()等方法.既然是可变的,所以它不存在哈希值.基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交集), difference(差集)和sysmmetric difference(对称差集)等数学运算. sets 支持 x in set, len(set),和 for x in set.作为一个无序的集合,sets不记录元素位
-
对numpy的array和python中自带的list之间相互转化详解
a=([3.234,34,3.777,6.33]) a为python的list类型 将a转化为numpy的array: np.array(a) array([ 3.234, 34. , 3.777, 6.33 ]) 将a转化为python的list a.tolist() 以上这篇对numpy的array和python中自带的list之间相互转化详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: Python创建二维数组实例(关于list的一个
-
对python中字典keys,values,items的使用详解
在python中对字典进行遍历时,可以直接使用如下模式: dict = {"name": "jack", "age": 15, "height": 1.75} for k in dict.keys(): print(k) 使用keys方法遍历得到的是key,可以依次输出,但是当单独使用dict.keys() 时,得到的结果时dict.keys类,属于迭代器,此时并不能使用列表的下标,需要转换一下,方法如下: 直接使用list(