MySQL 去重实例操作详解
目录
- 前言
- 1.创建测试数据
- 2.distinct 使用
- 2.1 单列去重
- 2.2 多列去重
- 2.3 聚合函数+去重
- 3.group by 使用
- 3.1 单列去重
- 3.2 多列去重
- 3.3 聚合函数 + group by
- 4.distinct 和 group by 的区别
- 区别1:查询结果集不同
- 区别2:使用业务场景不同
- 区别3:性能不同
- 总结
前言
在 MySQL 中,最常见的去重方法有两个:使用 distinct 或使用 group by,那它们有什么区别呢?接下来我们一起来看。
1.创建测试数据
最终展现效果如下:

2.distinct 使用
distinct 基本语法如下:
SELECT DISTINCT column_name,column_name FROM table_name;
2.1 单列去重
我们先用 distinct 实现单列去重,根据 aid(文章 ID)去重,具体实现如下:

2.2 多列去重
除了单列去重之外,distinct 还支持多列(两列及以上)去重,我们根据 aid(文章 ID)和 uid(用户 ID)联合去重,具体实现如下:

2.3 聚合函数+去重
使用 distinct + 聚合函数去重,计算 aid 去重之后的总条数,具体实现如下:

3.group by 使用
group by 基础语法如下:
SELECT column_name,column_name FROM table_name WHERE column_name operator value GROUP BY column_name
3.1 单列去重
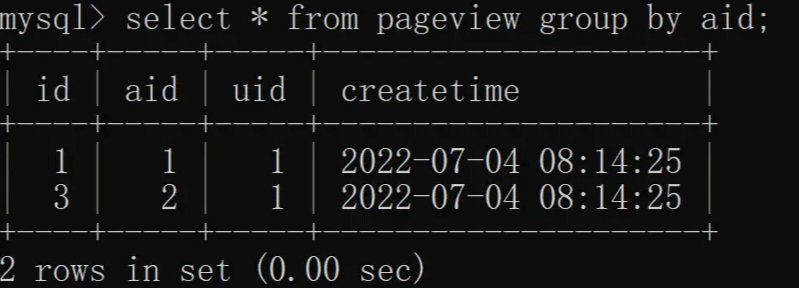
根据 aid(文章 ID)去重,具体实现如下:

与 distinct 相比 group by 可以显示更多的列,而 distinct 只能展示去重的列。
3.2 多列去重
根据 aid(文章 ID)和 uid(用户 ID)联合去重,具体实现如下:
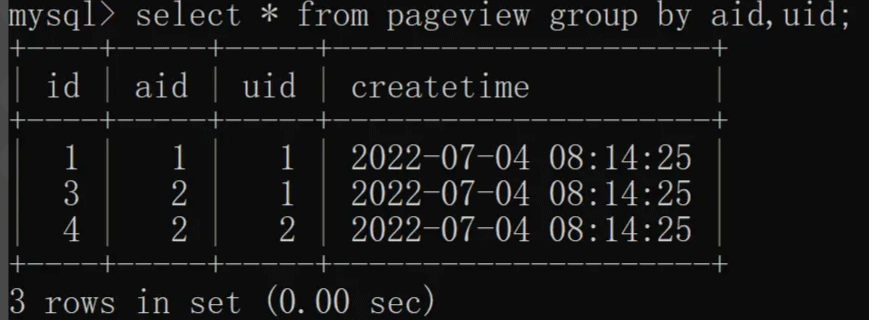
3.3 聚合函数 + group by
统计每个 aid 的总数量,SQL 实现如下:
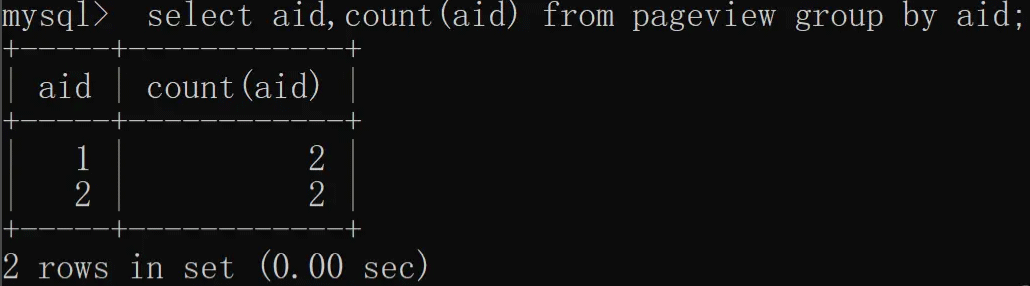
从上述结果可以看出,使用 group by 和 distinct 加 count 的查询语义是完全不同的,distinct + count 统计的是去重之后的总数量,而 group by + count 统计的是分组之后的每组数据的总数。
4.distinct 和 group by 的区别
官方文档在描述 distinct 时提到:在大多数情况下 distinct 是特殊的 group by,如下图所示:

官方文档地址:但二者还是有一些细微的不同的,比如以下几个。
区别1:查询结果集不同
当使用 distinct 去重时,查询结果集中只有去重列信息,如下图所示:

当你试图添加非去重字段(查询)时,SQL 会报错如下图所示:

而使用 group by 排序可以查询一个或多个字段,如下图所示:
区别2:使用业务场景不同
统计去重之后的总数量需要使用 distinct,而统计分组明细,或在分组明细的基础上添加查询条件时,就得使用 group by 了。
使用 distinct 统计某列去重之后的总数量:

统计分组之后数量大于 2 的文章,就要使用 group by 了,如下图所示:

区别3:性能不同
如果去重的字段有索引,那么 group by 和 distinct 都可以使用索引,此情况它们的性能是相同的;而当去重的字段没有索引时,distinct 的性能就会高于 group by,因为在 MySQL 8.0 之前,group by 有一个隐藏的功能会进行默认的排序,这样就会触发 filesort 从而导致查询性能降低。
总结
大部分场景下 distinct 是特殊的 group by,但二者也有细微的区别,比如它们在查询结果集上、使用的具体业务场景上,以及性能上都是不同的。
到此这篇关于MySQL 去重实例操作详解的文章就介绍到这了,更多相关MySQL 去重内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL连表查询分组去重的实现示例
目录 业务逻辑 数据表结构 查询逻辑 SQL脚本 脚本说明 业务逻辑 通过多种渠道将小程序的活动页链接发布出去,比如通过多多种短信附带链接( channel 就记为 sms1,sms2,sms3 ),或者海报上面贴微信小程序的二维码( channel 记为 qrcode1,qrcode2,qrcode3 ),线下会员通过扫描二维码也能进入小程序指定的活动页,亦或者是通过其他会员分享的小程序链接也可以进入小程序( channel 记为 share).这些不同的进入方式在我这篇文章统称为不同的渠道,
-
将MySQL去重操作优化到极致的操作方法
•问题提出 源表t_source结构如下: item_id int, created_time datetime, modified_time datetime, item_name varchar(20), other varchar(20) 要求: 1.源表中有100万条数据,其中有50万created_time和item_name重复. 2.要把去重后的50万数据写入到目标表. 3.重复created_time和item_name的多条数据,可以保留任意一条,不做规则限制. •实验环境 L
-

详解mysql数据去重的三种方式
目录 一.背景 二.数据去重三种方法使用 1.通过MySQL DISTINCT:去重(过滤重复数据) 2.group by 3.row_number窗口函数 三.总结 一.背景 最近在和系统模块做数据联调,其中有一个需求是将两个角色下的相关数据对比后将最新的数据返回出去,于是就想到了去重,再次做一个总结. 二.数据去重三种方法使用 1.通过MySQL DISTINCT:去重(过滤重复数据) 1.1.在使用 mysql SELECT 语句查询数据的时候返回的是所有匹配的行. SELECT
-
MySQL 数据查重、去重的实现语句
有一个表user,字段分别有id.nick_name.password.email.phone. 一.单字段(nick_name) 查出所有有重复记录的所有记录 select * from user where nick_name in (select nick_name from user group by nick_name having count(nick_name)>1); 查出有重复记录的各个记录组中id最大的记录 select * from user where id in (se
-
MySQL去重该使用distinct还是group by?
前言 关于group by 与distinct 性能对比:网上结论如下,不走索引少量数据distinct性能更好,大数据量group by 性能好,走索引group by性能好.走索引时分组种类少distinct快.关于网上的结论做一次验证. 准备阶段屏蔽查询缓存 查看MySQL中是否设置了查询缓存.为了不影响测试结果,需要关闭查询缓存. show variables like '%query_cache%'; 查看是否开启查询缓存决定于query_cache_type和query_cache_
-
MySQL中使用去重distinct方法的示例详解
一 distinct 含义:distinct用来查询不重复记录的条数,即distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段 用法注意: 1.distinct[查询字段],必须放在要查询字段的开头,即放在第一个参数: 2.只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用: 3.DISTINCT 表示对后面的所有参数的拼接取 不重复的记录,即查出的参数拼接每行记录
-
一条sql语句完成MySQL去重留一
前几天在做一个需求的时候,需要清理mysql中重复的记录,当时的想法是通过代码遍历写出来,然后觉得太复杂,心里想着应该可以通过一个sql语句来解决问题的.查了资料,请教了大佬之后得出了一个很便利的sql语句,这里分享下这段sql语句和思路. 需求分析 数据库中存在重复记录,删除保留其中一条(是否重复判断基准为多个字段) 解决方案 碰到这个需求的时候,心里大概是有思路的.最快想到的是可以通过一条sql语句来解决,无奈自己对于复杂sql语句的道行太浅,所以想找大佬帮忙. 找人帮忙 因为这个需求有点着
-
MySQL 去重实例操作详解
目录 前言 1.创建测试数据 2.distinct 使用 2.1 单列去重 2.2 多列去重 2.3 聚合函数+去重 3.group by 使用 3.1 单列去重 3.2 多列去重 3.3 聚合函数 + group by 4.distinct 和 group by 的区别 区别1:查询结果集不同 区别2:使用业务场景不同 区别3:性能不同 总结 前言 在 MySQL 中,最常见的去重方法有两个:使用 distinct 或使用 group by,那它们有什么区别呢?接下来我们一起来看. 1.创建测
-
java迭代器中删除元素的实例操作详解
我们知道通过Iterator,可以对集合中的元素进行遍历.那么在其中遇到我们不需要的元素时,可不可以在遍历的时候顺便给删除呢?答案是当然可以.在Iterator下有一个remove函数,专门用于删除的操作.下面我们就remove进行讲解,然后对删除元素方法进行说明,最后带来实例的展示. 1.Iterator中的remove void remove():删除迭代器刚越过的元素 从基础集合中移除这个迭代器返回的最后一个元素(可选操作).两个线程中都删除,保证线程的同步. 2.删除元素说明 (1)迭代
-
Mysql数据库 ALTER 操作详解
目录 背景: 案例一:将表employees的lastName字段修改到firstName字段后面,并减少字符长度. 案例二:将表employees的sex字段改名为employee_sex. 案例三:修改employee_sex字段,数据类型为CHAR(1),非空约束 案例四:删除字段employee_sex 案例五:增加字段名city,数据类型为VARCHAR(10). 案例六:将表employees名称修改为employees_info 背景: ALTER作为DDL语言之一,工作中经常遇到
-
mysql事务管理操作详解
本文实例讲述了mysql事务管理操作.分享给大家供大家参考,具体如下: 本文内容: 什么是事务管理 事务管理操作 回滚点 默认的事务管理 首发日期:2018-04-18 什么是事务管理: 可以把一系列要执行的操作称为事务,而事务管理就是管理这些操作要么完全执行,要么完全不执行(很经典的一个例子是:A要给B转钱,首先A的钱减少了,但是突然的数据库断电了,导致无法给B加钱,然后由于丢失数据,B不承认收到A的钱:在这里事务就是确保加钱和减钱两个都完全执行或完全不执行,如果加钱失败,那么不会发生减钱).
-
win7+apache+php+mysql环境配置操作详解
1.php版本简介php各版本之间的区别,php版本后面一般有VC6和VC9.Thread Safe和Non Thread Safe的区别,VC6就是legacy Visual Studio 6 compiler,就是使用这个编译器编译的,VC9就是the Visual Studio 2008 compiler,就是用微软的VS编辑器编译的,如果你选用的是Apache或者其他服务软件,那么选择VC6,选用的是IIS的话,那么请下载VC9 的.Thread Safe 是线程安全,而Non Thre
-
MySQL操作之JSON数据类型操作详解
上一篇文章我们介绍了mysql数据存储过程参数实例详解,今天我们看看MySQL操作之JSON数据类型的相关内容. 概述 mysql自5.7.8版本开始,就支持了json结构的数据存储和查询,这表明了mysql也在不断的学习和增加nosql数据库的有点.但mysql毕竟是关系型数据库,在处理json这种非结构化的数据时,还是比较别扭的. 创建一个JSON字段的表 首先先创建一个表,这个表包含一个json格式的字段: CREATE TABLE table_name ( id INT NOT NULL
-
mysql 循环批量插入的实例代码详解
背景 前几天在MySql上做分页时,看到有博文说使用 limit 0,10 方式分页会有丢数据问题,有人又说不会,于是想自己测试一下.测试时没有数据,便安装了一个MySql,建了张表,在建了个while循环批量插入10W条测试数据的时候,执行时间之长无法忍受,便查资料找批量插入优化方法,这里做个笔记. 数据结构 寻思着分页时标准列分主键列.索引列.普通列3种场景,所以,测试表需要包含这3种场景,建表语法如下: drop table if exists `test`.`t_model`; Crea
-
mysql语法之DQL操作详解
目录 简单查询 运算符查询 排序查询 聚合查询 分组查询 分页查询 一张表查询结果插入到另一张表 SQL语句分析 DQL小练习1 DQL小练习2 正则表达式 总结 DQL(Data Query Language),数据查询语言,主要是用来查询数据的,这也是SQL中最重要的部分! 简单查询 #DQL操作之基本查询 #创建数据库 CREATE DATABASE IF NOT EXISTS mydb2; #使用数据库 USE mydb2; #创建表 CREATE TABLE IF NOT EXISTS
-
MySql常用数据类型与操作详解
目录 常用数据类型 数据库基本操作 约束类型 常用数据类型 1.int:整形 2.double(m,d) decimal(m,d):浮点数类型 (m指定长度,d表示小数点位数) 3.varchar(size):字符串类型 4.timestamp:日期类型 数据库基本操作 不管执行什么语句,都要在语句的最后加上:(分号). 1.创建数据库 create database 数据库名: 2.显示当前数据库 show databases; 3.删除数据库 drop database 数据库名; 4.使用
-
MySQL筑基篇之增删改查操作详解
目录 一.增加表中数据 1.无自增列时 2.有自增列时 二.删除表中数据 1.使用delete 2.使用truncate 三.修改表中数据 四.*查询操作 1.简单查询 2.条件查询 3.排序 一.增加表中数据 1.无自增列时 1.指定字段添加数据 给表中的部分列添加数据:值的顺序必须跟指定列的顺序保持一致 语法:insert into 表名(列1,列2,...) values(值1,值2,...) 2.默认添加数据 向表中的所有列添加数据:值的顺序必须跟字段顺序保持一致 语法:insert i