使用Scrapy框架爬取网页并保存到Mysql的实现
大家好,这一期阿彬给大家分享Scrapy爬虫框架与本地Mysql的使用。今天阿彬爬取的网页是虎扑体育网。
(1)打开虎扑体育网,分析一下网页的数据,使用xpath定位元素。
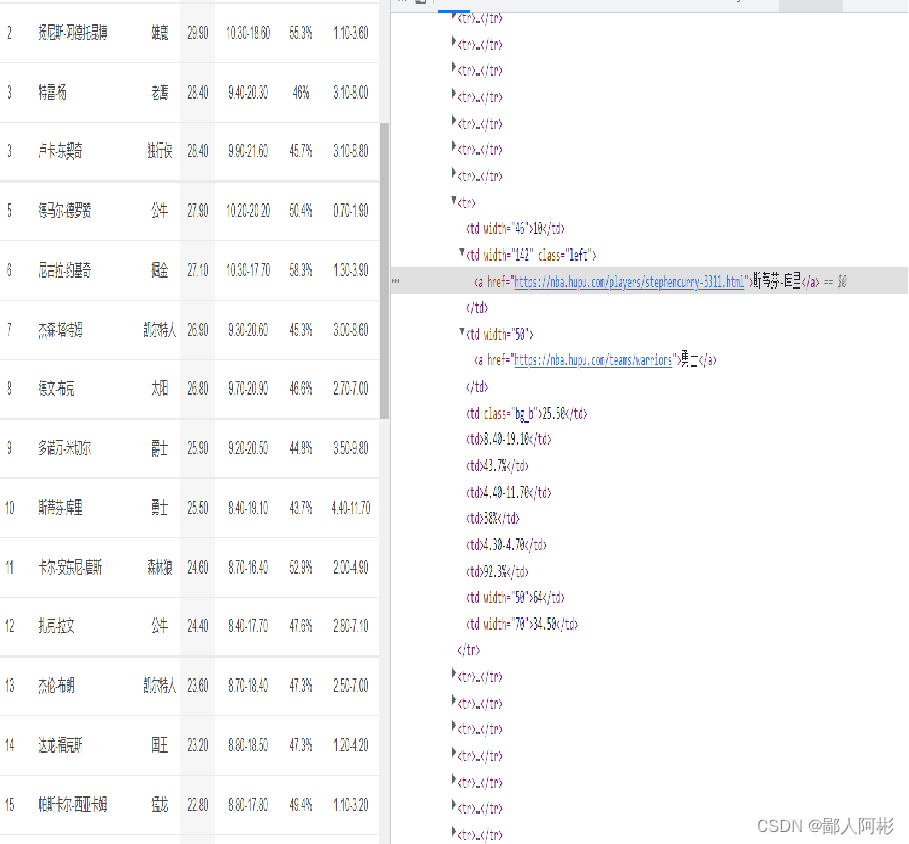
(2)在第一部分析网页之后就开始创建一个scrapy爬虫工程,在终端执行以下命令:
“scrapy startproject huty(注:‘hpty’是爬虫项目名称)”,得到了下图所示的工程包:
(3)进入到“hpty/hpty/spiders”目录下创建一个爬虫文件叫‘“sww”,在终端执行以下命令: “scrapy genspider sww” (4)在前两步做好之后,对整个爬虫工程相关的爬虫文件进行编辑。 1、setting文件的编辑:
把君子协议原本是True改为False。

再把这行原本被注释掉的代码把它打开。

2、对item文件进行编辑,这个文件是用来定义数据类型,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class HptyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
球员 = scrapy.Field()
球队 = scrapy.Field()
排名 = scrapy.Field()
场均得分 = scrapy.Field()
命中率 = scrapy.Field()
三分命中率 = scrapy.Field()
罚球命中率 = scrapy.Field()
3、对最重要的爬虫文件进行编辑(即“hpty”文件),代码如下:
import scrapy
from ..items import HptyItem
class SwwSpider(scrapy.Spider):
name = 'sww'
allowed_domains = ['https://nba.hupu.com/stats/players']
start_urls = ['https://nba.hupu.com/stats/players']
def parse(self, response):
whh = response.xpath('//tbody/tr[not(@class)]')
for i in whh:
排名 = i.xpath(
'./td[1]/text()').extract()# 排名
球员 = i.xpath(
'./td[2]/a/text()').extract() # 球员
球队 = i.xpath(
'./td[3]/a/text()').extract() # 球队
场均得分 = i.xpath(
'./td[4]/text()').extract() # 得分
命中率 = i.xpath(
'./td[6]/text()').extract() # 命中率
三分命中率 = i.xpath(
'./td[8]/text()').extract() # 三分命中率
罚球命中率 = i.xpath(
'./td[10]/text()').extract() # 罚球命中率
data = HptyItem(球员=球员, 球队=球队, 排名=排名, 场均得分=场均得分, 命中率=命中率, 三分命中率=三分命中率, 罚球命中率=罚球命中率)
yield data
4、对pipelines文件进行编辑,代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from cursor import cursor
from itemadapter import ItemAdapter
import pymysql
class HptyPipeline:
def process_item(self, item, spider):
db = pymysql.connect(host="Localhost", user="root", passwd="root", db="sww", charset="utf8")
cursor = db.cursor()
球员 = item["球员"][0]
球队 = item["球队"][0]
排名 = item["排名"][0]
场均得分 = item["场均得分"][0]
命中率 = item["命中率"]
三分命中率 = item["三分命中率"][0]
罚球命中率 = item["罚球命中率"][0]
# 三分命中率 = item["三分命中率"][0].strip('%')
# 罚球命中率 = item["罚球命中率"][0].strip('%')
cursor.execute(
'INSERT INTO nba(球员,球队,排名,场均得分,命中率,三分命中率,罚球命中率) VALUES (%s,%s,%s,%s,%s,%s,%s)',
(球员, 球队, 排名, 场均得分, 命中率, 三分命中率, 罚球命中率)
)
# 对事务操作进行提交
db.commit()
# 关闭游标
cursor.close()
db.close()
return item
(5)在scrapy框架设计好了之后,先到mysql创建一个名为“sww”的数据库,在该数据库下创建名为“nba”的数据表,代码如下: 1、创建数据库
create database sww;
2、创建数据表
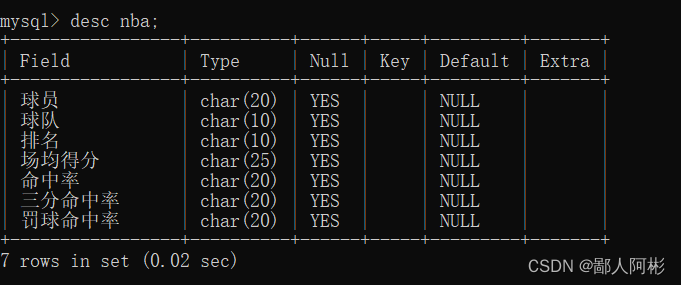
create table nba (球员 char(20),球队 char(10),排名 char(10),场均得分 char(25),命中率 char(20),三分命中率 char(20),罚球命中率 char(20));
3、通过创建数据库和数据表可以看到该表的结构:
(6)在mysql创建数据表之后,再次回到终端,输入如下命令:“scrapy crawl sww”,得到的结果
到此这篇关于使用Scrapy框架爬取网页并保存到Mysql的实现的文章就介绍到这了,更多相关Scrapy爬取网页并保存内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
如何在scrapy中集成selenium爬取网页的方法
1.背景 我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium.requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化). 在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦. 尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面后台发生了怎样的请求,也不需要分析整
-
Python下使用Scrapy爬取网页内容的实例
上周用了一周的时间学习了Python和Scrapy,实现了从0到1完整的网页爬虫实现.研究的时候很痛苦,但是很享受,做技术的嘛. 首先,安装Python,坑太多了,一个个爬.由于我是windows环境,没钱买mac, 在安装的时候遇到各种各样的问题,确实各种各样的依赖. 安装教程不再赘述.如果在安装的过程中遇到 ERROR:需要windows c/c++问题,一般是由于缺少windows开发编译环境,晚上大多数教程是安装一个VisualStudio,太不靠谱了,事实上只要安装一个WindowsS
-

使用Scrapy框架爬取网页并保存到Mysql的实现
大家好,这一期阿彬给大家分享Scrapy爬虫框架与本地Mysql的使用.今天阿彬爬取的网页是虎扑体育网. (1)打开虎扑体育网,分析一下网页的数据,使用xpath定位元素. (2)在第一部分析网页之后就开始创建一个scrapy爬虫工程,在终端执行以下命令:“scrapy startproject huty(注:‘hpty’是爬虫项目名称)”,得到了下图所示的工程包: (3)进入到“hpty/hpty/spiders”目录下创建一个爬虫文件叫‘“sww”,在终端执行以下命令: “scrapy
-
利用scrapy将爬到的数据保存到mysql(防止重复)
前言 本文主要给大家介绍了关于scrapy爬到的数据保存到mysql(防止重复)的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 1.环境建立 1.使用xmapp安装php, mysql ,phpmyadmin 2.安装python3,pip 3.安装pymysql 3.(windows 略)我这边是mac,安装brew,用brew 安装scrapy 2.整个流程 1. 创建数据库和数据库表,准备保存 2.写入爬虫目标URL,进行网络请求 3.对爬返回数据进行处理,得
-
Python利用Scrapy框架爬取豆瓣电影示例
本文实例讲述了Python利用Scrapy框架爬取豆瓣电影.分享给大家供大家参考,具体如下: 1.概念 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包 pip install scrapy scrapy的组成结构如下图所示 引擎Scrapy Engine,用于中转调度其他部分的信号和数据
-
Python爬虫实例——scrapy框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏可以看到搜索结果页的url为: 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=', 尝试将?后的参数删除, 发现访问结果相同. 打开Chrome网页调试工具(F12), 分析每条搜索结果
-
Python爬虫教程使用Scrapy框架爬取小说代码示例
目录 Scrapy框架简单介绍 创建Scrapy项目 创建Spider爬虫 Spider爬虫提取数据 items.py代码定义字段 fiction.py代码提取数据 pipelines.py代码保存数据 settings.py代码启动爬虫 结果展示 Scrapy框架简单介绍 Scrapy框架是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,是提取结构性数据而编写的应用框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,我们只需要少量的代码就能够快速抓取数据. 其框架如下图
-
Scrapy框架爬取西刺代理网免费高匿代理的实现代码
分析 需求: 爬取西刺代理网免费高匿代理,并保存到MySQL数据库中. 这里只爬取前10页中的数据. 思路: 分析网页结构,确定数据提取规则 创建Scrapy项目 编写item,定义数据字段 编写spider,实现数据抓取 编写Pipeline,保存数据到数据库中 配置settings.py文件 运行爬虫项目 代码实现 items.py import scrapy class XicidailiItem(scrapy.Item): # 国家 country=scrapy.Field() # IP
-
Scrapy框架爬取Boss直聘网Python职位信息的源码
分析 使用CrawlSpider结合LinkExtractor和Rule爬取网页信息 LinkExtractor用于定义链接提取规则,一般使用allow参数即可 LinkExtractor(allow=(), # 使用正则定义提取规则 deny=(), # 排除规则 allow_domains=(), # 限定域名范围 deny_domains=(), # 排除域名范围 restrict_xpaths=(), # 使用xpath定义提取队则 tags=('a', 'area'), attrs=(
-
Python爬虫 scrapy框架爬取某招聘网存入mongodb解析
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.py title = scrapy.Field() position = scrapy.Field() publish_date = scrapy.Field() pipelines.py from pymongo import MongoClient mongoclient = MongoClien
-
python爬取网页数据到保存到csv
目录 任务需求: 爬取网址: 网址页面: 代码实现结果: 代码实现: 完整代码: 总结 任务需求: 爬取一个网址,将网址的数据保存到csv中. 爬取网址: https://www.iqiyi.com/ranks1/1/0?vfrm=pcw_home&vfrmblk=&vfrmrst=712211_dianyingbang_rebo_title 网址页面: 代码实现结果: 代码实现: 导入包: import requests import parsel import csv 设置csv文件格