用Python获取亚马逊商品信息
目录
- 引言
- 一、获取亚马逊列表页的信息
- 二、获取详情页信息
- 三、代理设置
- 四、全部代码
- 总结
引言
亚马逊网站相较于国内的购物网站,可以直接使用python的最基本的requests进行请求。访问不是过于频繁,在未触发保护机制的情况下,可以获取我们想要的数据。本次通过以下三部分简单介绍下基本爬取流程:
使用requests的get请求,获取亚马逊列表和详情页的页面内容使用css/xpath对获取的内容进行解析,取得关键数据动态IP的作用及其使用方法
一、获取亚马逊列表页的信息
以游戏区为例:
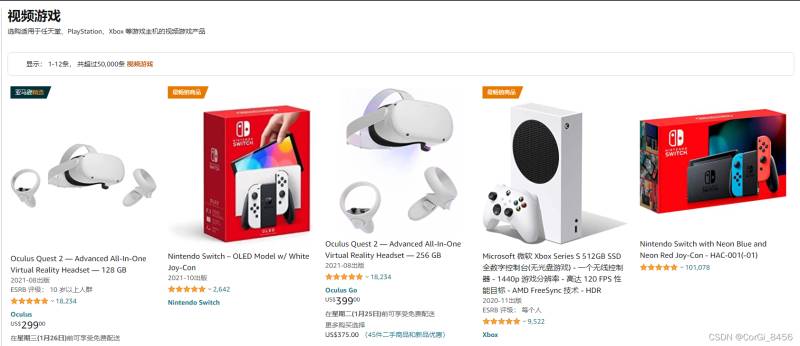
获取列表内能获取到的商品信息,如商品名,详情链接,进一步获取其他内容。
用requests.get()获取网页内容,设置好header,利用xpath选择器选取相关标签的内容:
import requests
from parsel import Selector
from urllib.parse import urljoin
spiderurl = 'https://www.amazon.com/s?i=videogames-intl-ship'
headers = {
"authority": "www.amazon.com",
"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G Language/zh_TW",
}
resp = requests.get(spiderurl, headers=headers)
content = resp.content.decode('utf-8')
select = Selector(text=content)
nodes = select.xpath("//a[@title='product-detail']")
for node in nodes:
itemUrl = node.xpath("./@href").extract_first()
itemName = node.xpath("./div/h2/span/text()").extract_first()
if itemUrl and itemName:
itemUrl = urljoin(spiderurl,itemUrl)#用urljoin方法凑完整链接
print(itemUrl,itemName)
此时已经获取的当前列表页目前能获得的信息:

二、获取详情页信息
进入详情页:
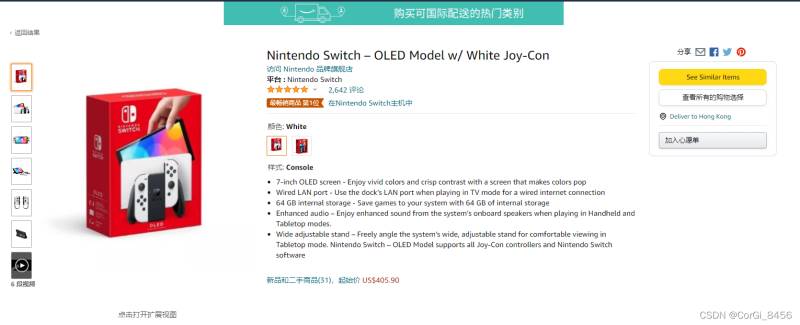
进入详情页之后,能获得更多的内容
用requests.get()获取网页内容,css选取相关标签的内容:
res = requests.get(itemUrl, headers=headers)
content = res.content.decode('utf-8')
Select = Selector(text=content)
itemPic = Select.css('#main-image::attr(src)').extract_first()
itemPrice = Select.css('.a-offscreen::text').extract_first()
itemInfo = Select.css('#feature-bullets').extract_first()
data = {}
data['itemUrl'] = itemUrl
data['itemName'] = itemName
data['itemPic'] = itemPic
data['itemPrice'] = itemPrice
data['itemInfo'] = itemInfo
print(data)
此时已经生成详情页数据的信息:

目前涉及到的就是最基本的requests请求亚马逊并用css/xpath获取相应的信息。
三、代理设置
目前,国内访问亚马逊会很不稳定,我这边大概率会出现连接不上的情况。如果真的需要去爬取亚马逊的信息,最好使用一些稳定的代理,我这边自己使用的是ipidea的代理,可以白嫖50M流量。如果有代理的话访问的成功率会高,速度也会快一点。
代理使用有两种方式,一是通过api获取IP地址,还有用账密的方式使用,方法如下:
3.1.1 api获取代理


3.1.2 api获取ip代码
def getProxies():
# 获取且仅获取一个ip
api_url = '生成的api链接'
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = {
'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
}
print(proxies)
return proxies
else:
print('获取失败')
except:
print('获取失败')
3.2.1 账密获取代理
因为是账密验证,所以需要 去到账户中心填写信息创建子账户:


创建好子账户之后,根据账号和密码获取链接:
3.2.2 账密获取代理代码
# 获取账密ip
def getAccountIp():
# 测试完成后返回代理proxy
mainUrl = 'https://api.myip.la/en?json'
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G Language/zh_TW",
}
entry = 'http://{}-zone-custom{}:proxy.ipidea.io:2334'.format("帐号", "密码")
proxy = {
'http': entry,
'https': entry,
}
try:
res = requests.get(mainUrl, headers=headers, proxies=proxy, timeout=10)
if res.status_code == 200:
return proxy
except Exception as e:
print("访问失败", e)
pass
使用代理之后,亚马逊商品信息的获取改善了不少,之前代码会报各种连接失败的错误,在requests请求之前调用代理获取的方法,方法return回代理ip并加入requests请求参数,就可以实现代理请求了。
四、全部代码
# coding=utf-8
import requests
from parsel import Selector
from urllib.parse import urljoin
def getProxies():
# 获取且仅获取一个ip
api_url = '生成的api链接'
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = {
'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
}
print(proxies)
return proxies
else:
print('获取失败')
except:
print('获取失败')
spiderurl = 'https://www.amazon.com/s?i=videogames-intl-ship'
headers = {
"authority": "www.amazon.com",
"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G Language/zh_TW",
}
proxies = getProxies()
resp = requests.get(spiderurl, headers=headers, proxies=proxies)
content = resp.content.decode('utf-8')
select = Selector(text=content)
nodes = select.xpath("//a[@title='product-detail']")
for node in nodes:
itemUrl = node.xpath("./@href").extract_first()
itemName = node.xpath("./div/h2/span/text()").extract_first()
if itemUrl and itemName:
itemUrl = urljoin(spiderurl,itemUrl)
proxies = getProxies()
res = requests.get(itemUrl, headers=headers, proxies=proxies)
content = res.content.decode('utf-8')
Select = Selector(text=content)
itemPic = Select.css('#main-image::attr(src)').extract_first()
itemPrice = Select.css('.a-offscreen::text').extract_first()
itemInfo = Select.css('#feature-bullets').extract_first()
data = {}
data['itemUrl'] = itemUrl
data['itemName'] = itemName
data['itemPic'] = itemPic
data['itemPrice'] = itemPrice
data['itemInfo'] = itemInfo
print(data)
通过上面的步骤,可以实现最基础的亚马逊的信息获取。
目前只获得最基本的数据,若想获得更多也可以自行修改xpath/css选择器去拿到你想要的内容。而且稳定的动态IP能是你进行请求的时候少一点等待的时间,无论是编写中的测试还是小批量的爬取,都能提升工作的效率。以上就是全部的内容。
总结
到此这篇关于用Python获取亚马逊商品信息的文章就介绍到这了,更多相关Python亚马逊商品信息内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬取当当、京东、亚马逊图书信息代码实例
注:1.本程序采用MSSQLserver数据库存储,请运行程序前手动修改程序开头处的数据库链接信息 2.需要bs4.requests.pymssql库支持 3.支持多线程 from bs4 import BeautifulSoup import re,requests,pymysql,threading,os,traceback try: conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root',
-
python爬取亚马逊书籍信息代码分享
我有个需求就是抓取一些简单的书籍信息存储到mysql数据库,例如,封面图片,书名,类型,作者,简历,出版社,语种. 我比较之后,决定在亚马逊来实现我的需求. 我分析网站后发现,亚马逊有个高级搜索的功能,我就通过该搜索结果来获取书籍的详情URL. 由于亚马逊的高级搜索是用get方法的,所以通过分析,搜索结果的URL,可得到node参数是代表书籍类型的.field-binding_browse-bin是代表书籍装饰. 所以我固定了书籍装饰为平装,而书籍的类型,只能每次运行的时候,爬取一种类型的书籍难
-
Python实现爬取亚马逊数据并打印出Excel文件操作示例
本文实例讲述了Python实现爬取亚马逊数据并打印出Excel文件操作.分享给大家供大家参考,具体如下: python大神们别喷,代码写的很粗糙,主要是完成功能,能够借鉴就看下吧,我是学java的,毕竟不是学python的,自己自学看了一点点python,望谅解. #!/usr/bin/env python3 # encoding=UTF-8 import sys import re import urllib.request import json import time import zli
-
用Python获取亚马逊商品信息
目录 引言 一.获取亚马逊列表页的信息 二.获取详情页信息 三.代理设置 四.全部代码 总结 引言 亚马逊网站相较于国内的购物网站,可以直接使用python的最基本的requests进行请求.访问不是过于频繁,在未触发保护机制的情况下,可以获取我们想要的数据.本次通过以下三部分简单介绍下基本爬取流程: 使用requests的get请求,获取亚马逊列表和详情页的页面内容使用css/xpath对获取的内容进行解析,取得关键数据动态IP的作用及其使用方法 一.获取亚马逊列表页的信息 以游戏区为例: 获
-
基于Python获取亚马逊的评论信息的处理
目录 一.分析亚马逊的评论请求 二.获取亚马逊评论的内容 三.亚马逊评论信息的处理 四.代码整合 4.1代理设置 4.2while循环翻页 总结 上次亚马逊的商品信息都获取到了,自然要看一下评论的部分.用户的评论能直观的反映当前商品值不值得购买,亚马逊的评分信息也能获取到做一个评分的权重. 亚马逊的评论区由用户ID,评分及评论标题,地区时间,评论正文这几个部分组成,本次获取的内容就是这些. 测试链接:https://www.amazon.it/product-reviews/B08GHGTGQ2
-
用pushplus+python监控亚马逊到货动态推送微信
xbox series和ps5发售以来,国内黄牛价格一直居高不下.虽然海外amazon上ps5补货很少而且基本撑不过一分钟,但是xbox series系列明显要好抢很多. 日亚.德亚的xbox series x/s都可以直邮中国大陆,所以我们只需要借助脚本,监控相关网页的动态,在补货的第一时刻通过微信告知我们,然后迅速人工购买即可! 需求:pushplus(需要微信关注公众号).python3 一.pushplus相关介绍 pushplus提供了免费的微信消息推送api,具体内容可以参考他的官网
-
react版模拟亚马逊人机交互菜单的实现
目录 前言 需求介绍 实现方案 实现需求3 部分逻辑代码 实现效果 前言 前段时间接了一个需求,实现一个模仿亚马逊和京东的菜单交互效果,这种效果被称为模拟人机交互.在网上搜了一下,目前没有见到有 react和Vue的版本,然后就自己参考了一下现有的方式,实现了一个react版本. 需求介绍 本文都是在web端的需求 参考亚马逊和京东商城的首页左侧菜单效果,实现一个react版本的组件,以供业务使用. 我们先看下亚马逊和京东商城的效果: 亚马逊商城 京东商城 从上面的效果得出我们的菜单效果需求点:
-
Python 爬取淘宝商品信息栏目的实现
一.相关知识点 1.1.Selenium Selenium是一个强大的开源Web功能测试工具系列,可进行读入测试套件.执行测试和记录测试结果,模拟真实用户操作,包括浏览页面.点击链接.输入文字.提交表单.触发鼠标事件等操作,并且能够对页面结果进行种种验证.也就是说,只要在测试用例中把预期的用户行为与结果都描述出来,我们就得到了一个可以自动化运行的功能测试套件. 1.2.ActionChains Actionchains是selenium里面专门处理鼠标相关的操作如:鼠标移动,鼠标按钮操作,按键和
-
亚马逊经典面试题实例详解
亚马逊面试题: 如下所示的Map中,0代表海水,1代表岛屿,其中每一个岛屿与其八领域的区间的小岛能相连组成岛屿群.写代码,统计Map中岛屿个数. /* Q1. Map [ 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 ] */ 实现代码: #include<iostream> #include<queue> using namespace
-
python获取Linux下文件版本信息、公司名和产品名的方法
本文实例讲述了python获取Linux下文件版本信息.公司名和产品名的方法,分享给大家供大家参考.具体如下: 区别于前文所述.本例是在linux下得到文件版本信息,主要是通过pefile模块解析文件 中的字符串得到的.代码如下: def _get_company_and_product(self, file_path): """ Read all properties of the given file return them as a dictionary. @retur