python selenium实现登录豆瓣示例详解
使用python爬虫selenium访问豆瓣https://www.douban.com/,实现模拟登录过程。
网页界面如图所示

首先导包后,定位图中 密码登录 的element,并点击。
经分析,该标签的class_name为’account-tab-account’。

from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://www.douban.com/')
# 点击 密码登录 按钮 。但是找不到该element,不存在网页中
driver.find_element_by_class_name('account-tab-account').click()
但是该段代码结果出现了报错,定位不到目标元素。
经核实,发现该element并不存在与网页源码中。
经分析,登录界面存在于一个叫iframe的标签中。iframe这个标签是嵌套在这个网页中的,单独拿出来也能用。所以并不存在于网页源码中。

访问该src链接可以看到如下界面:

iframe中的元素不属于原网页的元素,但是iframe在网页源码中,要获取其元素,先定位iframe:

# 找到登陆的iframe
login_iframe = driver.find_element_by_xpath('//div[@class="login"]/iframe')
# 切换到iframe
driver.switch_to.frame(login_iframe)
# 点击密码登陆
driver.find_element_by_class_name('account-tab-account').click()
找到之后,还要切换进去,使用 switch_to 方法。
经测试,点击成功。
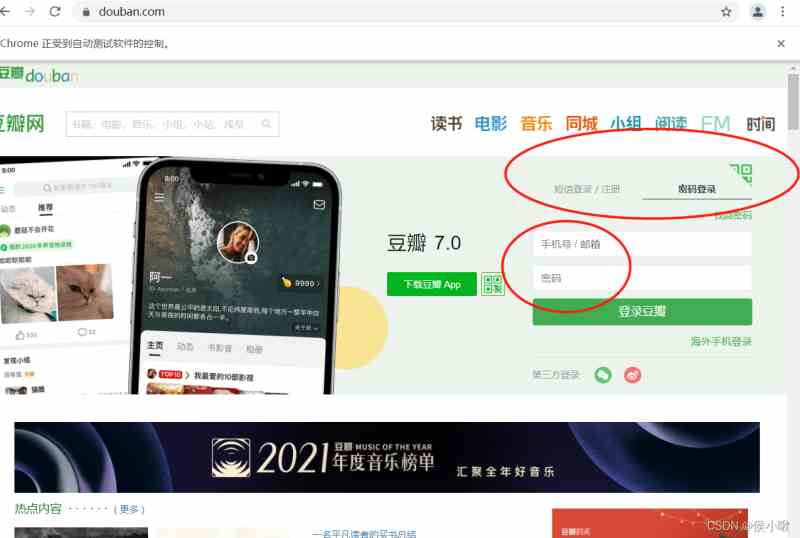
接下来,就是输入账号和密码过程了
# 填写账号
driver.find_element_by_id('username').send_keys('123456789@163.com')
time.sleep(2)
# 填写密码
driver.find_element_by_id('password').send_keys('xxxx')
登录
# 点击登陆按钮
driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[5]/a').click()
也可以通过JS点击
execute_script() 方法
login_button = driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[5]/a')
driver.execute_script("arguments[0].click()", login_button)
此外,在输入账号密码前,有时也会遇到输入框中有诸如“请输入账号”、“请输入密码”这样的文字(默认值),需要清除掉后才能输入,否则输入内容会重叠。(此例中不会,此例中输入新内容后自动覆盖原有的“手机号/邮箱”、“密码”字样)清楚输入框中的文字,使用 clear 方法。
# 以清除用户名一栏的内容为例
driver.find_element_by_id('username').clear()
最后,模拟登陆的目的,一般是为了获取cookie。使用到以下命令。
get_cookies()
print(driver.get_cookies())

到此这篇关于python selenium登录豆瓣示例详解的文章就介绍到这了,更多相关python selenium登录豆瓣内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python selenium登录豆瓣网过程解析
登录流程: 实例化一个driver,然后driver.get()发送请求 最重要的:切换iframe子框架,因为豆瓣的网页中的登录那部分是一个ifrme,必须切换才能寻找到对应元素 利用selenium切换到账号密码登录 利用selenium输入账户和密码 利用selenium点击登录按钮 然后利用字典推导式保存了一下cookie 代码实现: import time from selenium import webdriver # 实例化driver driver = webdriver.Chr
-

python selenium实现登录豆瓣示例详解
使用python爬虫selenium访问豆瓣https://www.douban.com/,实现模拟登录过程. 网页界面如图所示 首先导包后,定位图中 密码登录 的element,并点击. 经分析,该标签的class_name为’account-tab-account’. from selenium import webdriver import time driver = webdriver.Chrome() driver.get('https://www.douban.com/') # 点击
-
Python实现连接dr校园网示例详解
目录 背景 分析 实现 背景 在校园里认证上网很麻烦需要web输入账号密码有时还会忘记web地址此时就需要一个人或者程序帮我们实现,这时我想到用python制作这个程序(初学者python代码不规范) 分析 需要分析web登录网址的浏览器头发现是get方法这就简单了,再次分析get请求发现有user_account字段,user_password字段还有ip字段mac字段这时我们的思路就来了使用curl命令直接把这个代码放到终端里运行发现是可以的 curl "http://学校认证服务器ip:8
-
Python selenium 三种等待方式详解(必会)
很多人在群里问,这个下拉框定位不到.那个弹出框定位不到-各种定位不到,其实大多数情况下就是两种问题:1 有frame,2 没有加等待.殊不知,你的代码运行速度是什么量级的,而浏览器加载渲染速度又是什么量级的,就好比闪电侠和凹凸曼约好去打怪兽,然后闪电侠打完回来之后问凹凸曼你为啥还在穿鞋没出门?凹凸曼分分中内心一万只羊驼飞过,欺负哥速度慢,哥不跟你玩了,抛个异常撂挑子了. 那么怎么才能照顾到凹凸曼缓慢的加载速度呢?只有一个办法,那就是等喽.说到等,又有三种等法,且听博主一一道来: 1. 强制等待
-
对python多线程SSH登录并发脚本详解
测试系统中有一项记录ssh登录日志,需要对此进行并发压力测试. 于是用多线程进行python并发记录 因为需要安装的一些依赖和模块比较麻烦,脚本完成后再用pyinstaller打成exe包分发给其他测试人员一起使用. 1.脚本编写 # -*- coding: utf-8 -*- import paramiko import threading import time lt = [] def ssh(a,xh,sp): count = 0 for i in range(0,xh): try: ss
-
python实现PCA降维的示例详解
概述 本文主要介绍一种降维方法,PCA(Principal Component Analysis,主成分分析).降维致力于解决三类问题. 1. 降维可以缓解维度灾难问题: 2. 降维可以在压缩数据的同时让信息损失最小化: 3. 理解几百个维度的数据结构很困难,两三个维度的数据通过可视化更容易理解. PCA简介 在理解特征提取与处理时,涉及高维特征向量的问题往往容易陷入维度灾难.随着数据集维度的增加,算法学习需要的样本数量呈指数级增加.有些应用中,遇到这样的大数据是非常不利的,而且从大数据集中学习
-
Python线性点运算数字图像处理示例详解
目录 点运算 定义 分类 线性点运算 分段线性点运算 非线性点运算 对数变换 幂次变换 点运算 定义 分类 线性点运算 例子: 分段线性点运算 非线性点运算 对数变换 幂次变换 1. 点运算是否会改变图像内像素点之间的空间位置关系? 点运算是一种像素的逐点运算,它与相邻的像素之间没有运算关系,点运算不会改变图像内像素点之间的空间位置关系. 2. 对图像灰度的拉伸,非线性拉伸与分段线性拉伸的区别? 非线性拉伸不是通过在不同灰度值区间选择不同的线性方程来实现对不同灰度值区间的扩展与压缩,而是在整个灰
-
Python面向对象编程repr方法示例详解
目录 为什么要讲 __repr__ 重写 __repr__ 方法 str() 和 repr() 的区别 为什么要讲 __repr__ 在 Python 中,直接 print 一个实例对象,默认是输出这个对象由哪个类创建的对象,以及在内存中的地址(十六进制表示) 假设在开发调试过程中,希望使用 print 实例对象时,输出自定义内容,就可以用 __repr__ 方法了 或者通过 repr() 调用对象也会返回 __repr__ 方法返回的值 是不是似曾相识....没错..和 __str__ 一样的
-
python函数传参意义示例详解
目录 C++这样的语言用多了之后,在Python函数传递参数的时候,经常会遇到一个问题,我要传递一个引用怎么办? 比如我们想要传一个x到函数中做个运算改变x的值: def change(y): y += 1 x = 1 print ("before change:", x) change(x) print ("after change: ", x) 得到的结果是 before change: 1 after change: 1 完全没用~~~这是怎么回事? 我来说
-
python模块shutil函数应用示例详解教程
目录 本文大纲 知识串讲 1)模块导入 2)复制文件 3)复制文件夹 4)移动文件或文件夹 5)删除文件夹(慎用) 6)创建和解压压缩包 本文大纲 os模块是Python标准库中一个重要的模块,里面提供了对目录和文件的一般常用操作.而Python另外一个标准库--shutil库,它作为os模块的补充,提供了复制.移动.删除.压缩.解压等操作,这些 os 模块中一般是没有提供的.但是需要注意的是:shutil 模块对压缩包的处理是调用 ZipFile 和 TarFile这两个模块来进行的. 知识串
-
Python绘制3D立体花朵示例详解
目录 动态展示 导读 源码和详解 荷花 玫瑰花 桃花 月季 动态展示 这是一个动态图哦 导读 兄弟们可以收藏一下哦!情人节可以送出去,肥学找了几朵python写的花给封装好送给大家.不是多炫酷但是有足够的用心哦.别忘了点赞呀我也就不细说了,来吧展示! 源码和详解 荷花 def lotus(): fig = plt.figure(figsize=(10,7),facecolor='black',clear=True) ax = fig.gca(projection='3d') [x, t] = n