JPA-JpaRepository方法命名语法说明
目录
- 前言
- JPA的语法分为如下5种:
- 1、count相关,返回值为int 或 long
- 2、exists相关,返回值只能是 boolean
- 3、find相关,返回值是数组List<aaa>
- 4、findFirst相关,返回值是aaa
- 5、delete相关,返回值是int,删除行数
前言
梳理了一遍JPA的方法命名语法,记录一下,以便后续备查。
注:本文不介绍JPL语法,版本为spring-data-jpa-2.3.0.RELEASE。
假设实体类名为 aaa,且定义如下:
import lombok.Data;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
@Data
public class aaa {
@Id
private long id;
private long restId;
private int dishHour;
private int num;
}
对应的仓储层接口定义:
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import javax.transaction.Transactional;
import java.util.List;
@Repository
public interface aaaRepository extends JpaRepository<aaa, Long> {
int countByDishHourAndRestId(int hour, long restId);
boolean existsByDishHourAndRestId(int hour, long restId);
List<aaa> findByDishHourAndRestId(int hour, long restId);
aaa findTopByDishHourAndRestId(int hour, long restId);
@Transactional
int deleteByDishHourAndRestId(int hour, long restId);
}
JPA的语法分为如下5种:
1、count相关,返回值为int 或 long
int countByDishHourAndRestId(int hour, long restId); int countaaaByDishHourAndRestId(int hour, long restId); int countaaasByDishHourAndRestId(int hour, long restId); int countAllByDishHourAndRestId(int hour, long restId);
上面这4个方法是一样的,对应的SQL如下:
select count(id) from aaa where dishHour=? and restId=?
下面这种定义,没有意义,知晓一下就好:
int countDistinctByDishHourAndRestId(int hour, long restId);
对应SQL如下,如果表中有主键,功能跟countBy是一致的,浪费性能:
select distinct count(distinct id) from aaa where dishHour=? and restId=?
2、exists相关,返回值只能是 boolean
boolean existsByDishHourAndRestId(int hour, long restId); boolean existsaaaByDishHourAndRestId(int hour, long restId); boolean existsaaasByDishHourAndRestId(int hour, long restId); boolean existsAllByDishHourAndRestId(int hour, long restId);
上面这4个方法是一样的,对应的SQL如下:
select id from aaa where dishHour=? and restId=? limit 1
下面这种定义,没有意义,知晓一下就好:
boolean existsDistinctByDishHourAndRestId(int hour, long restId);
对应SQL如下,功能跟existsBy是一致的,多余:
select distinct id from aaa where dishHour=? and restId=? limit 1
3、find相关,返回值是数组List<aaa>
List<aaa> findByDishHourAndRestId(int hour, long restId); List<aaa> findaaaByDishHourAndRestId(int hour, long restId); List<aaa> findaaasByDishHourAndRestId(int hour, long restId); List<aaa> findAllByDishHourAndRestId(int hour, long restId); List<aaa> getByDishHourAndRestId(int hour, long restId); List<aaa> getaaaByDishHourAndRestId(int hour, long restId); List<aaa> getaaasByDishHourAndRestId(int hour, long restId); List<aaa> getAllByDishHourAndRestId(int hour, long restId); List<aaa> queryByDishHourAndRestId(int hour, long restId); List<aaa> queryaaaByDishHourAndRestId(int hour, long restId); List<aaa> queryaaasByDishHourAndRestId(int hour, long restId); List<aaa> queryAllByDishHourAndRestId(int hour, long restId); List<aaa> readByDishHourAndRestId(int hour, long restId); List<aaa> readaaaByDishHourAndRestId(int hour, long restId); List<aaa> readaaasByDishHourAndRestId(int hour, long restId); List<aaa> readAllByDishHourAndRestId(int hour, long restId); List<aaa> streamByDishHourAndRestId(int hour, long restId); List<aaa> streamaaaByDishHourAndRestId(int hour, long restId); List<aaa> streamaaasByDishHourAndRestId(int hour, long restId); List<aaa> streamAllByDishHourAndRestId(int hour, long restId);
上面这20个方法是一样的,对应的SQL如下:
select id,dishHour,num,restId from aaa where dishHour=? and restId=?
下面这种定义,没有意义,知晓一下就好:
List<aaa> findDistinctByDishHourAndRestId(int hour, long restId);
对应SQL如下,如果表中有主键,功能跟findBy是一致的,多余:
select distinct id,dishHour,num,restId from aaa where dishHour=? and restId=?
4、findFirst相关,返回值是aaa
aaa findFirstByDishHourAndRestId(int hour, long restId); aaa findTopByDishHourAndRestId(int a, long b); aaa getFirstByDishHourAndRestId(int hour, long restId); aaa getTopByDishHourAndRestId(int a, long b); aaa queryFirstByDishHourAndRestId(int hour, long restId); aaa queryTopByDishHourAndRestId(int a, long b); aaa readFirstByDishHourAndRestId(int hour, long restId); aaa readTopByDishHourAndRestId(int a, long b); aaa streamFirstByDishHourAndRestId(int hour, long restId); aaa streamTopByDishHourAndRestId(int a, long b);
上面这10个方法是一样的,对应的SQL如下:
select id,dishHour,num,restId from aaa where dishHour=? and restId=? limit 1
注:返回值也可以改成List<aaa>,但是SQL不变,返回的数组也只有一条数据
下面这种定义,没有意义,知晓一下就好:
List<aaa> findDistinctFirstByDishHourAndRestId(int hour, long restId);
对应SQL如下,如果表中有主键,功能跟countBy是一致的,多余:
select distinct id,dishHour,num,restId from aaa where dishHour=? and restId=? limit 1
5、delete相关,返回值是int,删除行数
@Transactional int deleteaaaByDishHourAndRestId(int a, long b); @Transactional int deleteaaasByDishHourAndRestId(int a, long b); @Transactional int deleteAllByDishHourAndRestId(int a, long b); @Transactional int deleteByDishHourAndRestId(int a, long b); @Transactional int removeaaaByDishHourAndRestId(int a, long b); @Transactional int removeaaasByDishHourAndRestId(int a, long b); @Transactional int removeAllByDishHourAndRestId(int a, long b); @Transactional int removeByDishHourAndRestId(int a, long b);
上面这8个方法是一样的,对应有2条SQL,如下:
select id,dishHour,num,restId from aaa where dishHour=? and restId=? delete from aaa where id=?
注:先SELECT查找主键,再进行删除,所以必须在方法前加注解Transactional,提供事务,否则会抛异常。
下面这种定义,没有意义,知晓一下就好:
int deleteDistinctByDishHourAndRestId(int hour, long restId);
对应SQL如下,如果表中有主键,功能跟deleteBy是一致的,多余:
select distinct id,dishHour,num,restId from aaa where dishHour=? and restId=?
注1:方法By后面的语法,可以参考下图,或官方文档:
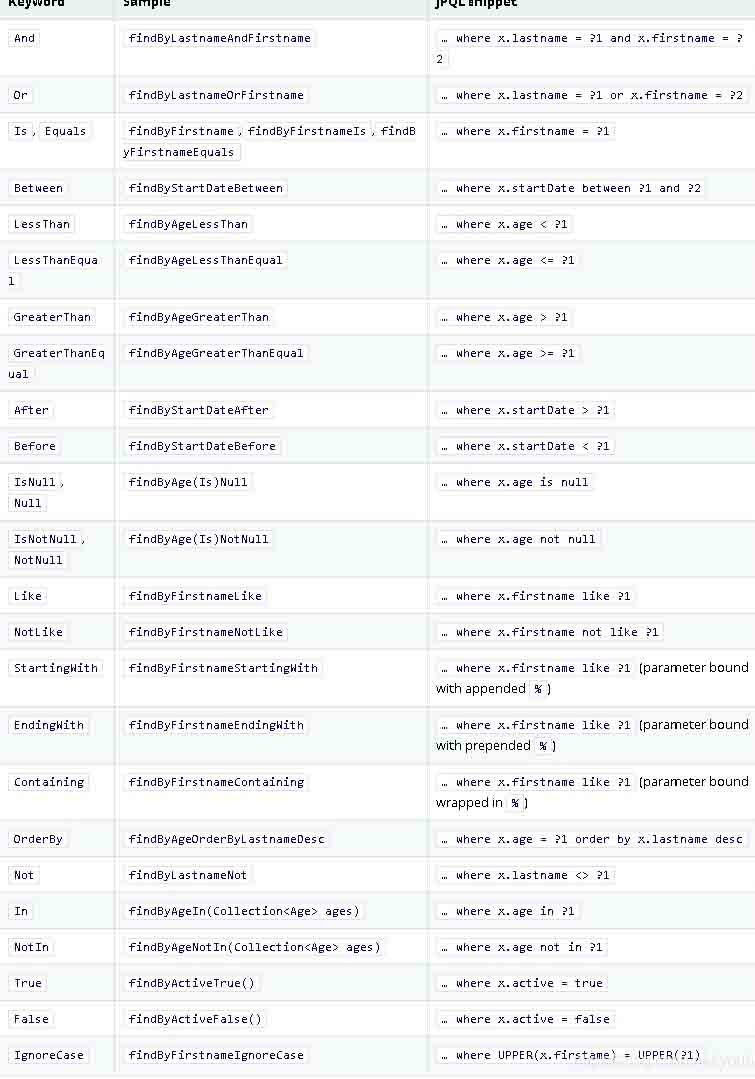
注2:JPA Query注解问题:
SQL里可以用 #{#entityName} 占位符,替代手写表名,如:
@Query(value = "select * from #{#entityName} where 1=2", nativeQuery = true)
aaa selectXXX();
INSERT、UPDATE、DELETE这3种DML操作,返回值只能是void、int、long,且必须增加2个注解,例如:
// 返回值不是void、int、long,报错:
// Modifying queries can only use void or int/Integer as return type!
// 不加 Transactional 报错:
// javax.persistence.TransactionRequiredException: Executing an update/delete query
@Transactional
// 不加Modifing 报错:
// Can not issue data manipulation statements with executeQuery().
@Modifying
@Query(value = "update #{#entityName} set num=num+1 where id=6", nativeQuery = true)
int doupdate();
注3:JPA原生方法列表:
List<T> findAll(); List<T> findAll(Sort var1); List<T> findAllById(Iterable<ID> var1); <S extends T> List<S> saveAll(Iterable<S> var1); void flush(); <S extends T> S saveAndFlush(S var1); void deleteInBatch(Iterable<T> var1); void deleteAllInBatch(); T getOne(ID var1); <S extends T> List<S> findAll(Example<S> var1); <S extends T> List<S> findAll(Example<S> var1, Sort var2);
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
spring data jpa使用详解(推荐)
使用Spring data JPA开发已经有一段时间了,这期间学习了一些东西,也遇到了一些问题,在这里和大家分享一下. 前言: Spring data简介: Spring Data是一个用于简化数据库访问,并支持云服务的开源框架.其主要目标是使得对数据的访问变得方便快捷,并支持map-reduce框架和云计算数据服务. Spring Data 包含多个子项目: Commons - 提供共享的基础框架,适合各个子项目使用,支持跨数据库持久化 JPA - 简化创建 JPA 数据访问层和跨存储的持久层
-
SpringData Repository接口用法解析
本节主要介绍Repository接口规范,及其子接口 Repository是一个空接口,即标准接口若我们定义的接口继承了Repository,则该接口会被IOC容器识别为一个Repositoty Bean纳入到IOC容器中.进而可以在该接口中定义满足一定规范的方法.实际上也可以通过注解的方式定义Repository接口 package com.ntjr.springdata; import org.springframework.data.repository.RepositoryDefinit
-
Springboot使用Spring Data JPA实现数据库操作
SpringBoot整合JPA 使用数据库是开发基本应用的基础,借助于开发框架,我们已经不用编写原始的访问数据库的代码,也不用调用JDBC(Java Data Base Connectivity)或者连接池等诸如此类的被称作底层的代码,我们将从更高的层次上访问数据库,这在Springboot中更是如此,本章我们将详细介绍在Springboot中使用 Spring Data JPA 来实现对数据库的操作. JPA & Spring Data JPA JPA是Java Persistence API
-
Spring Boot中使用Spring-data-jpa的配置方法详解
为了解决这些大量枯燥的数据操作语句,我们第一个想到的是使用ORM框架,比如:hibernate.通过整合Hibernate之后,我们以操作Java实体的方式最终将数据改变映射到数据库表中. 为了解决抽象各个Java实体基本的"增删改查"操作,我们通常会以泛型的方式封装一个模板Dao来进行抽象简化,但是这样依然不是很方便,我们需要针对每个实体编写一个继承自泛型模板Dao的接口,再编写该接口的实现.虽然一些基础的数据访问已经可以得到很好的复用,但是在代码结构上针对每个实体都会有一堆Dao的
-

JPA-JpaRepository方法命名语法说明
目录 前言 JPA的语法分为如下5种: 1.count相关,返回值为int 或 long 2.exists相关,返回值只能是 boolean 3.find相关,返回值是数组List<aaa> 4.findFirst相关,返回值是aaa 5.delete相关,返回值是int,删除行数 前言 梳理了一遍JPA的方法命名语法,记录一下,以便后续备查. 注:本文不介绍JPL语法,版本为spring-data-jpa-2.3.0.RELEASE. 假设实体类名为 aaa,且定义如下: import lo
-
JPA like 模糊查询 语法格式解析
目录 JPA like 模糊查询 语法格式 模糊查询:Spring Data JPA 如何进行模糊查询(LIKE) ? 一. 方法一 二. 方法二 JPA like 模糊查询 语法格式 public List<InstitutionInfo> getAllInstitution(final Application app){ String zdGljg = null; Sysuser user = (Sysuser) app.getUser(); String userGljg = user.
-
教你快速学会JPA中所有findBy语法规则
目录 快速学会JPA中所有findBy语法规则 1.findBy findAllBy的区别 2.JPA中支持的关键词 JPA findBy 语法总结 1.JPA同时查询两个属性 2.表格汇总 3.Spring Data JPA框架在进行方法名解析时 4.JPA的NamedQueries 5.JPQL查询 快速学会JPA中所有findBy语法规则 1.findBy findAllBy的区别 它们之间没有区别,它们将执行完全相同的查询,当从方法名称派生查询时,Spring Data会忽略All部分.
-
JPA save()方法将字段更新为null的解决方案
这篇文章主要介绍了JPA save()方法将字段更新为null的解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 今天在开发上碰到一个问题,在做页面展示的时候传给前端十个字段,前端修改了其中3个的值,所以只传了3个值给后端,其余字段默认为null,更新后其他7个字段在全部变为了空值. 在前端没法全量回传所有属性的前提下,由后端来处理这类问题. 解决方法: 1.写一个工具方法(UpdateUtil) 用来筛选出所有的空值字段 2.更新时先通
-
解决JPA save()方法null值覆盖掉mysql预设的默认值问题
目录 JPA save()方法null值覆盖掉mysql预设的默认值 覆盖原因 解决办法 data jpa动态插入(null为sql默认值,utime自动更新 ) JPA save()方法null值覆盖掉mysql预设的默认值 覆盖原因 save()方法在没有参数传进去的时候默认是null值,而mysql表中该字段设置为可以为null值,这时虽然我们设置了默认值,可null值还是会把默认值覆盖掉. 解决办法 将该字段设置为不允许null值即可,这样null值就会被替换为默认值. data jpa
-
spring data jpa 创建方法名进行简单查询方式
目录 最常见的做法是 按照规范创建查询方法 支持的规范表达式 spring data jpa 可以通过在接口中按照规定语法创建一个方法进行查询,spring data jpa 基础接口中,如CrudRepository中findOne,save,delete等,那么我们自己怎么按照需要创建一个方法进行查询呢? 最常见的做法是 声明一个接口继承于CrudRepository 或者 PagingAndSortingRepository,JpaRepository,Repository public
-
javascript中with()方法的语法格式及使用
内容导读: 有了 With 语句,在存取对象属性和方法时就不用重复指定参考对象,在 With 语句块中,凡是 JavaScript 不识别的属性和方法都和该语句块指定的对象有关.With 语句的语法格式如下所示: With Object { Statements } 对象指明了当语句组中对象缺省时的参考对象,这里我们用较为熟悉的 Document 对象对 With 语句举例.例如 当使用与 Document 对象有关的 write( )或 writeln( )方法时,往往使用如下形式: docu
-
JavaScript数组reduce()方法的语法与实例解析
前言 reduce() 方法接收一个函数作为累加器(accumulator),数组中的每个值(从左到右)开始缩减,最终为一个值. reduce 为数组中的每一个元素依次执行回调函数,不包括数组中被删除或从未被赋值的元素,接受四个参数:初始值(或者上一次回调函数的返回值),当前元素值,当前索引,调用 reduce 的数组. Javascript数组方法中,相比map.filter.forEach等常用的迭代方法,reduce常常被我们所忽略,今天一起来探究一下reduce在我们实战开发当中,能有哪
-
SpringBoot整合JPA数据源方法及配置解析
一.创建项目并导入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>dr
-
MySQL 创建索引(Create Index)的方法和语法结构及例子
CREATE INDEX Syntax CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [index_type] ON tbl_name (index_col_name,...) [index_type] index_col_name: col_name [(length)] [ASC | DESC] index_type: USING {BTREE | HASH | RTREE} 复制代码 代码如下: -- 创建无索引的表格 create t