MySQL Shell import_table数据导入的实现
目录
- 1. import_table介绍
- 2. Load Data 与 import table功能示例
- 2.1 用Load Data方式导入数据
- 2.2 用import_table方式导入数据
- 3. import_table特定功能
- 3.1 多文件导入(模糊匹配)
- 3.2 并发导入
- 3.3 导入速率控制
- 3.4 自定义chunk大小
- 4. Load Data vs import_table性能对比
- 5. 技术总结
1. import_table介绍
上期技术分享我们介绍了MySQL Load Data的4种常用的方法将文本数据导入到MySQL,这一期我们继续介绍另一款更加高效的数据导入工具,MySQL Shell 工具集中的import_table,该工具的全称是Parallel Table Import Utility,顾名思义,支持并发数据导入,该工具在MySQL Shell 8.0.23版本后,功能更加完善, 以下列举该工具的核心功能
- 基本覆盖了MySQL Data Load的所有功能,可以作为替代品使用
- 默认支持并发导入(支持自定义chunk大小)
- 支持通配符匹配多个文件同时导入到一张表(非常适用于相同结构数据汇总到一张表)
- 支持限速(对带宽使用有要求的场景,非常合适)
- 支持对压缩文件处理
- 支持导入到5.7及以上MySQL
2. Load Data 与 import table功能示例
该部分针对import table和Load Data相同的功能做命令示例演示,我们依旧以导入employees表的示例数据为例,演示MySQL Load Data的综合场景
- 数据自定义顺序导入
- 数据函数处理
- 自定义数据取值
## 示例数据如下
[root@10-186-61-162 tmp]# cat employees_01.csv
"10001","1953-09-02","Georgi","Facello","M","1986-06-26"
"10003","1959-12-03","Parto","Bamford","M","1986-08-28"
"10002","1964-06-02","Bezalel","Simmel","F","1985-11-21"
"10004","1954-05-01","Chirstian","Koblick","M","1986-12-01"
"10005","1955-01-21","Kyoichi","Maliniak","M","1989-09-12"
"10006","1953-04-20","Anneke","Preusig","F","1989-06-02"
"10007","1957-05-23","Tzvetan","Zielinski","F","1989-02-10"
"10008","1958-02-19","Saniya","Kalloufi","M","1994-09-15"
"10009","1952-04-19","Sumant","Peac","F","1985-02-18"
"10010","1963-06-01","Duangkaew","Piveteau","F","1989-08-24"
## 示例表结构
10.186.61.162:3306 employees SQL > desc emp;
+-------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+---------------+------+-----+---------+-------+
| emp_no | int | NO | PRI | NULL | |
| birth_date | date | NO | | NULL | |
| first_name | varchar(14) | NO | | NULL | |
| last_name | varchar(16) | NO | | NULL | |
| full_name | varchar(64) | YES | | NULL | | -- 表新增字段,导出数据文件中不存在
| gender | enum('M','F') | NO | | NULL | |
| hire_date | date | NO | | NULL | |
| modify_date | datetime | YES | | NULL | | -- 表新增字段,导出数据文件中不存在
| delete_flag | varchar(1) | YES | | NULL | | -- 表新增字段,导出数据文件中不存在
+-------------+---------------+------+-----+---------+-------+
2.1 用Load Data方式导入数据
具体参数含义不做说明,需要了解语法规则及含义可查看系列上一篇文章<MySQL Load Data的多种用法>
load data infile '/data/mysql/3306/tmp/employees_01.csv'
into table employees.emp
character set utf8mb4
fields terminated by ','
enclosed by '"'
lines terminated by '\n'
(@C1,@C2,@C3,@C4,@C5,@C6)
set emp_no=@C1,
birth_date=@C2,
first_name=upper(@C3),
last_name=lower(@C4),
full_name=concat(first_name,' ',last_name),
gender=@C5,
hire_date=@C6 ,
modify_date=now(),
delete_flag=if(hire_date<'1988-01-01','Y','N');

2.2 用import_table方式导入数据
util.import_table(
[
"/data/mysql/3306/tmp/employees_01.csv",
],
{
"schema": "employees",
"table": "emp",
"dialect": "csv-unix",
"skipRows": 0,
"showProgress": True,
"characterSet": "utf8mb4",
"columns": [1,2,3,4,5,6], ## 文件中多少个列就用多少个序号标识就行
"decodeColumns": {
"emp_no": "@1", ## 对应文件中的第1列
"birth_date": "@2", ## 对应文件中的第2个列
"first_name": "upper(@3)", ## 对应文件中的第3个列,并做转为大写的处理
"last_name": "lower(@4)", ## 对应文件中的第4个列,并做转为大写的处理
"full_name": "concat(@3,' ',@4)", ## 将文件中的第3,4列合并成一列生成表中字段值
"gender": "@5", ## 对应文件中的第5个列
"hire_date": "@6", ## 对应文件中的第6个列
"modify_date": "now()", ## 用函数生成表中字段值
"delete_flag": "if(@6<'1988-01-01','Y','N')" ## 基于文件中第6列做逻辑判断,生成表中对应字段值
}
})


3. import_table特定功能
3.1 多文件导入(模糊匹配)
## 在导入前我生成好了3分单独的employees文件,导出的结构一致
[root@10-186-61-162 tmp]# ls -lh
总用量 1.9G
-rw-r----- 1 mysql mysql 579 3月 24 19:07 employees_01.csv
-rw-r----- 1 mysql mysql 584 3月 24 18:48 employees_02.csv
-rw-r----- 1 mysql mysql 576 3月 24 18:48 employees_03.csv
-rw-r----- 1 mysql mysql 1.9G 3月 26 17:15 sbtest1.csv
## 导入命令,其中对对文件用employees_*做模糊匹配
util.import_table(
[
"/data/mysql/3306/tmp/employees_*",
],
{
"schema": "employees",
"table": "emp",
"dialect": "csv-unix",
"skipRows": 0,
"showProgress": True,
"characterSet": "utf8mb4",
"columns": [1,2,3,4,5,6], ## 文件中多少个列就用多少个序号标识就行
"decodeColumns": {
"emp_no": "@1", ## 对应文件中的第1列
"birth_date": "@2", ## 对应文件中的第2个列
"first_name": "upper(@3)", ## 对应文件中的第3个列,并做转为大写的处理
"last_name": "lower(@4)", ## 对应文件中的第4个列,并做转为大写的处理
"full_name": "concat(@3,' ',@4)", ## 将文件中的第3,4列合并成一列生成表中字段值
"gender": "@5", ## 对应文件中的第5个列
"hire_date": "@6", ## 对应文件中的第6个列
"modify_date": "now()", ## 用函数生成表中字段值
"delete_flag": "if(@6<'1988-01-01','Y','N')" ## 基于文件中第6列做逻辑判断,生成表中对应字段值
}
})
## 导入命令,其中对要导入的文件均明确指定其路径
util.import_table(
[
"/data/mysql/3306/tmp/employees_01.csv",
"/data/mysql/3306/tmp/employees_02.csv",
"/data/mysql/3306/tmp/employees_03.csv"
],
{
"schema": "employees",
"table": "emp",
"dialect": "csv-unix",
"skipRows": 0,
"showProgress": True,
"characterSet": "utf8mb4",
"columns": [1,2,3,4,5,6], ## 文件中多少个列就用多少个序号标识就行
"decodeColumns": {
"emp_no": "@1", ## 对应文件中的第1列
"birth_date": "@2", ## 对应文件中的第2个列
"first_name": "upper(@3)", ## 对应文件中的第3个列,并做转为大写的处理
"last_name": "lower(@4)", ## 对应文件中的第4个列,并做转为大写的处理
"full_name": "concat(@3,' ',@4)", ## 将文件中的第3,4列合并成一列生成表中字段值
"gender": "@5", ## 对应文件中的第5个列
"hire_date": "@6", ## 对应文件中的第6个列
"modify_date": "now()", ## 用函数生成表中字段值
"delete_flag": "if(@6<'1988-01-01','Y','N')" ## 基于文件中第6列做逻辑判断,生成表中对应字段值
}
})


3.2 并发导入
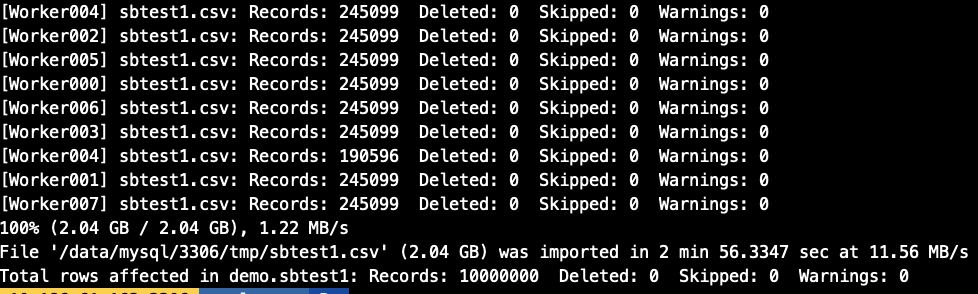
在实验并发导入前我们创建一张1000W的sbtest1表(大约2G数据),做并发模拟,import_table用threads参数作为并发配置, 默认为8个并发.
## 导出测试需要的sbtest1数据
[root@10-186-61-162 tmp]# ls -lh
总用量 1.9G
-rw-r----- 1 mysql mysql 579 3月 24 19:07 employees_01.csv
-rw-r----- 1 mysql mysql 584 3月 24 18:48 employees_02.csv
-rw-r----- 1 mysql mysql 576 3月 24 18:48 employees_03.csv
-rw-r----- 1 mysql mysql 1.9G 3月 26 17:15 sbtest1.csv
## 开启threads为8个并发
util.import_table(
[
"/data/mysql/3306/tmp/sbtest1.csv",
],
{
"schema": "demo",
"table": "sbtest1",
"dialect": "csv-unix",
"skipRows": 0,
"showProgress": True,
"characterSet": "utf8mb4",
"threads": "8"
})

3.3 导入速率控制
可以通过maxRate和threads来控制每个并发线程的导入数据,如,当前配置线程为4个,每个线程的速率为2M/s,则最高不会超过8M/s
util.import_table(
[
"/data/mysql/3306/tmp/sbtest1.csv",
],
{
"schema": "demo",
"table": "sbtest1",
"dialect": "csv-unix",
"skipRows": 0,
"showProgress": True,
"characterSet": "utf8mb4",
"threads": "4",
"maxRate": "2M"
})

3.4 自定义chunk大小
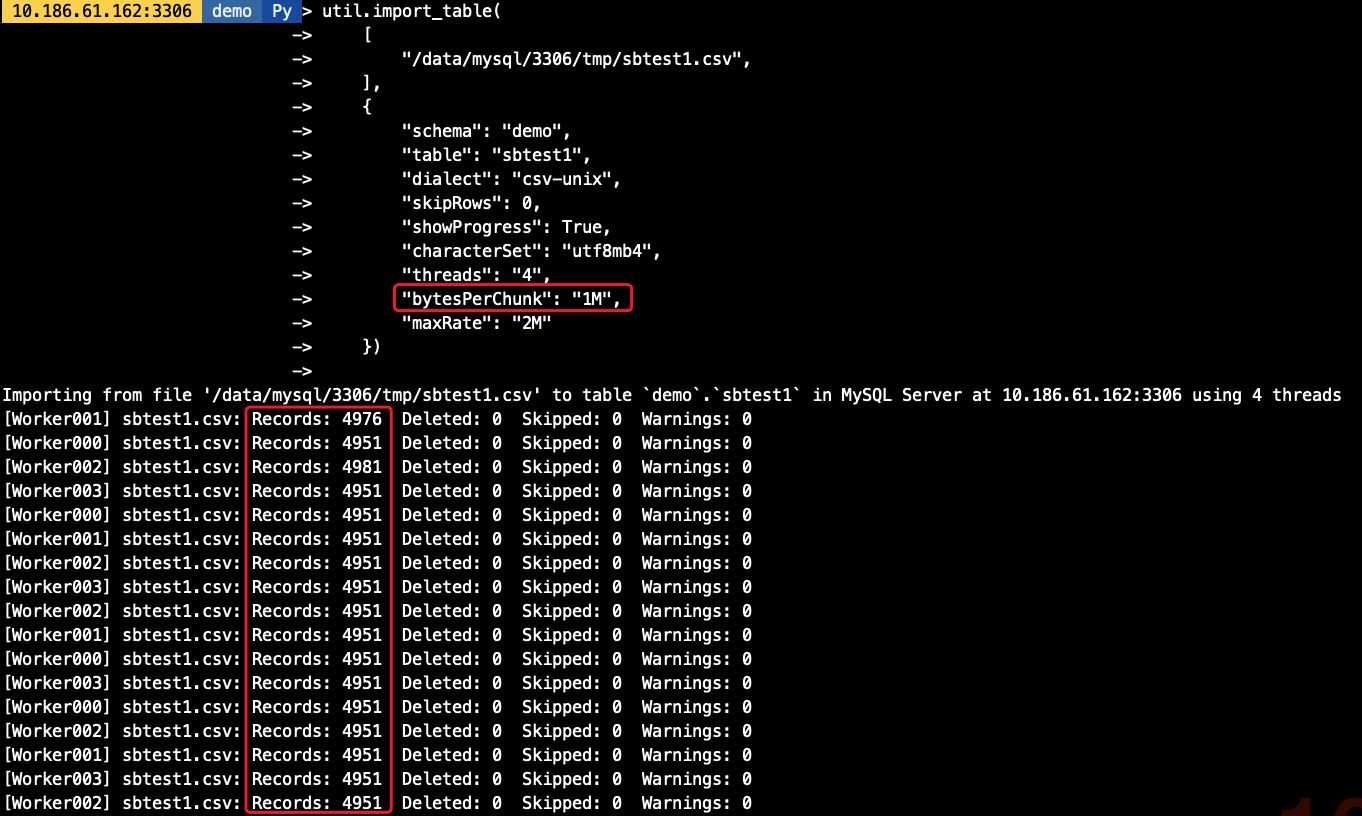
默认的chunk大小为50M,我们可以调整chunk的大小,减少事务大小,如我们将chunk大小调整为1M,则每个线程每次导入的数据量也相应减少
util.import_table(
[
"/data/mysql/3306/tmp/sbtest1.csv",
],
{
"schema": "demo",
"table": "sbtest1",
"dialect": "csv-unix",
"skipRows": 0,
"showProgress": True,
"characterSet": "utf8mb4",
"threads": "4",
"bytesPerChunk": "1M",
"maxRate": "2M"
})
4. Load Data vs import_table性能对比
- 使用相同库表
- 不对数据做特殊处理,原样导入
- 不修改参数默认值,只指定必备参数
-- Load Data语句
load data infile '/data/mysql/3306/tmp/sbtest1.csv'
into table demo.sbtest1
character set utf8mb4
fields terminated by ','
enclosed by '"'
lines terminated by '\n'
-- import_table语句
util.import_table(
[
"/data/mysql/3306/tmp/sbtest1.csv",
],
{
"schema": "demo",
"table": "sbtest1",
"dialect": "csv-unix",
"skipRows": 0,
"showProgress": True,
"characterSet": "utf8mb4"
})
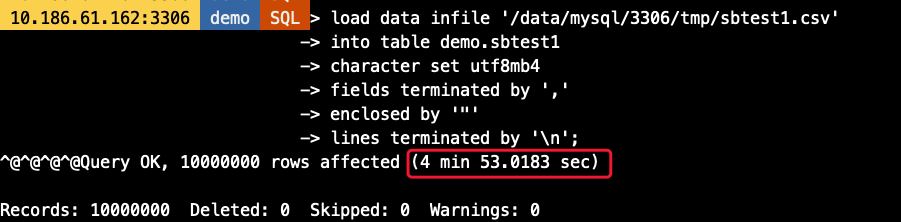

可以看到,Load Data耗时约5分钟,而import_table则只要不到一半的时间即可完成数据导入,效率高一倍以上(虚拟机环境磁盘IO能力有限情况下)
5. 技术总结
- import_table包含了Load Data几乎所有的功能
- import_table导入的效率比Load Data更高
- import_table支持对导入速度,并发以及每次导入的数据大小做精细控制
- import_table的导入进度报告更加详细,便于排错及时间评估,包括
- 导入速度
- 导入总耗时
- 每批次导入的数据量,是否存在Warning等等
- 导入最终的汇总报告
到此这篇关于MySQL import_table数据导入的实现的文章就介绍到这了,更多相关MySQL import_table数据导入内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
在linux中导入sql文件的方法分享(使用命令行转移mysql数据库)
因导出sql文件 在你原来的网站服务商处利用phpmyadmin导出数据库为sql文件,这个步骤大家都会,不赘述. 上传sql文件 前面说过了,我们没有在云主机上安装ftp,怎么上传呢? 打开ftp客户端软件,例如filezilla,使用服务器IP和root及密码,连接时一定要使用SFTP方式连接,这样才能连接到linux.注意,这种方法是不安全的,但我们这里没有ftp,如果要上传本地文件到服务器,没有更好更快的方法. 我们把database.sql上传到/tmp目录. 连接到linux,登录m
-
Mysql命令行导入sql数据
我的个人实践是:phpmyadmin 导出 utf-8 的 insert 模式的 abc.sql ftp abc.sql 到服务器 ssh 到服务器 mysql -u abc -p use KKK(数据库名,如果没有就 create database KKK) set names 'utf8' source abc.sql 注意:我看到 set character set utf8; 的说法,那样不行,中文乱码. 1.首先在命令行控制台中打开mysql 或许命令的如下: mysql -u roo
-

MySQL 文本文件的导入导出数据的方法
MySQL写入数据通常用insert语句,如 复制代码 代码如下: insert into person values(张三,20),(李四,21),(王五,70)-; 但有时为了更快速地插入大批量数据或交换数据,需要从文本中导入数据或导出数据到文本. 一. 建立测试表,准备数据 首先建立一个用于测试的表示学生信息的表,字段有id.姓名.年龄.城市.薪水.Id和姓名不 能为空. 复制代码 代码如下: create table person( id int not null auto_increm
-
mysql 导入导出数据库、数据表的方法
Linux下均在控制台下操作.导入数据库:前提:数据库和数据表要存在(已经被创建) (1)将数据表 test_user.sql 导入到test 数据库的test_user 表中[root@test ~]# mysql -uroot -p test < /www/web/test/test_user.sql (2) 将数据库 test.sql 导入到 test 数据库test 中[root@test ~]# mysql -uroot -p test < /www/web/test/test.sq
-
MYSQL 数据库导入导出命令
MySQL命令行导出数据库 1,进入MySQL目录下的bin文件夹:cd MySQL中到bin文件夹的目录 如我输入的命令行:cd C:\Program Files\MySQL\MySQL Server 4.1\bin (或者直接将windows的环境变量path中添加该目录) 2,导出数据库:mysqldump -u 用户名 -p 数据库名 > 导出的文件名 如我输入的命令行:mysqldump -u root -p news > news.sql (输入后会让你输入进入MySQL的密码
-
MYSQL大数据导入
感谢XP提供的代码! 在这里记录一下,因为以后学要用:作用资料查询之用! 第一步:mysql -h localhost -uroot 第二步:show databases; 第三步:use changchunmap; 第四步:show tables; 第五步:load data local infile "d:/c.txt" replace into table changchunmap fields terminated by ' '; 没有了: load data
-
MySQL如何导入csv格式数据文件解决方案
给自己做备份的,高手们请忽略. 数据太大,用数据库客户端软件直接导入非常卡,还是直接执行SQL吧. 1.指定文件路径. 2.字段之间以逗号分隔,数据行之间以\r\n分隔(我这里文件是以\n分隔的). 3.字符串以半角双引号包围,字符串本身的双引号用两个双引号表示. Sql代码 复制代码 代码如下: load data infile 'D:\\top-1m.csv' into table `site` fields terminated by ',' optionally enclosed by
-
mysql导入导出数据中文乱码解决方法小结
linux系统中 linux默认的是utf8编码,而windows是gbk编码,所以会出现上面的乱码问题. 解决mysql导入导出数据乱码问题 首先要做的是要确定你导出数据的编码格式,使用mysqldump的时候需要加上--default-character-set=utf8, 例如下面的代码: 复制代码 代码如下: mysqldump -uroot -p --default-character-set=utf8 dbname tablename > bak.sql 那么导入数据的时候也要使用-
-
mysql 导入导出数据库以及函数、存储过程的介绍
mysql常用导出数据命令:1.mysql导出整个数据库 mysqldump -hhostname -uusername -ppassword databasename > backupfile.sql mysqldump -hlocalhost -uroot hqgr> hqgr.sql (如果root用户没用密码可以不写-p,当然导出的sql文件你可以制定一个路径,未指定则存放在mysql的bin目录下) 2.mysql导出数据库一个表 mysqldump -hhostnam
-
MySQL Shell import_table数据导入的实现
目录 1. import_table介绍 2. Load Data 与 import table功能示例 2.1 用Load Data方式导入数据 2.2 用import_table方式导入数据 3. import_table特定功能 3.1 多文件导入(模糊匹配) 3.2 并发导入 3.3 导入速率控制 3.4 自定义chunk大小 4. Load Data vs import_table性能对比 5. 技术总结 1. import_table介绍 上期技术分享我们介绍了MySQL Load
-
MySQL数据库Shell import_table数据导入
目录 MySQL Shell import_table数据导入 1. import_table介绍 2. Load Data 与 import table功能示例 2.1 用Load Data方式导入数据 2.2 用import_table方式导入数据 3. import_table特定功能 3.1 多文件导入(模糊匹配) 3.2 并发导入 3.3 导入速率控制 3.4 自定义chunk大小 4. Load Data vs import_table性能对比 MySQL Shell import_
-
Oracle和MySQL的数据导入为何差别这么大
经常会有一些朋友咨询我一些数据库的问题,我注意到一个很有意思的现象,凡是数据导入的问题,基本上都是Oracle类的,MySQL类的问题脑子里想了下竟然一次都没有. 我禁不住开始思考这个未曾注意的问题: 为什么Oracle导入数据会碰到很多的问题? 我们来梳理一下这个问题,分别从导出导入的方式来聊聊. 首先Oracle导出的文件格式就没打算让你拿来即用,导出文件叫做dump,换句话说可以理解这是一个二进制文件.当然实际上这个文件还是有很多的方式去抓取一些关键的信息,比如dump头部的信息可以通过s
-
将sqlite3中数据导入到mysql中的实战教程
前言 sqlite3只小巧轻便,但是并不支持并发访问,当网站并发量较大时候,数据库请求队列边长,有可能导致队列末尾去数据库操作超时,从而操作失败.因此需要切换到支持并发访问的数据库.切换数据库需要将老的数据导出,再导入到新的数据库中,但是sqlite3和mysql的数据库并不完全兼容,需要做部分调整才能正常导入到mysql中.我最近工作中就遇到了这个问题. 最近一个项目中使用magenetico抓取磁力链接,由于它使用的是sqlite3, 文件会越来越大,而且不支持分布式:所以需要将其改造成My
-
PHP把MSSQL数据导入到MYSQL的方法
本文实例讲述了PHP把MSSQL数据导入到MYSQL的方法.分享给大家供大家参考.具体分析如下: 最近需要把一个以前的asp网站转换成php的,但php是与mysql而我的asp与mssql的,结果就需要把mssql数据导入到mysql数据库了,下面我自己写了一个实例还抄了一个实例都不错. 实例一,代码如下: 复制代码 代码如下: <?php //国内的PNR码连接 $hostname="127.0.0.1"; //MSSQL服务器的IP地址 或 服务器的名字 $dbuser
-
Excel数据导入Mysql数据库的实现代码
首先做一下说明,为什么我要用Navicat,第一个原因,因为它是个不错的Mysql GUI工具,更重要的是,它可以将一些外部数据源导入Mysql数据库中.因为我的数据源是excel数据,所以想借助Navicat将其导入Mysql. 第一次运行,首先创建连接,主机名填写:localhost,端口为3306,然后填写用户名密码,OK.顺利的话,大家就可以看到名为localhost的连接图标了.双击点开它,一般Mysql默认有两个数据库,分别为mysql与test. 不用管它们,右键localhost
-
解析csv数据导入mysql的方法
mysql自己有个csv引擎,可以通过这个引擎来实现将csv中的数据导入到mysql数据库中,并且速度比通过php或是python写的批处理程序快的多.具体的实现代码示例: 复制代码 代码如下: load data infile '/tmp/file.csv' into table _tablename (set character utf8) fields terminated by ','enclosed by '"'lines terminated by '\r\n'; 这段代码中涉及的一
-
如何把ACCESS的数据导入到Mysql中
如何把ACCESS的数据导入到Mysql中 www.Alltips.Com 2001-10-6 极限技术网 在建设网站的过程中,经常要处理一些数据的导入及导出.在Mysql数据库中,有两种方法来处理数据的导出(一般). 1. 使用select * from table_name into outfile "file_name"; 2. 使用mysqldump实用程序 下面我们来举例说明: 假设我们的数据库中有一个库为samp_db,一个表为samp_table.现在
-
MySQL中数据导入恢复的简单教程
有两个简单的方法MySQL中的数据加载到MySQL数据库从先前备份的文件. LOAD DATA导入数据: MySQL提供了LOAD DATA语句,作为一个大容量数据加载.下面是一个例子声明中,读取一个文件dump.txt,,从当前目录加载到当前数据库中的表mytbl: mysql> LOAD DATA LOCAL INFILE 'dump.txt' INTO TABLE mytbl; 如果本地的关键字是不存在的,MySQL的外观使用绝对路径名寻找到完全指定位置的文件在服务器主机上的数据文件,从文
-
php基于Fleaphp框架实现cvs数据导入MySQL的方法
本文实例讲述了php基于Fleaphp框架实现cvs数据导入MySQL的方法.分享给大家供大家参考,具体如下: <?php /* * To change this template, choose Tools | Templates * and open the template in the editor. */ class Controller_KaoqinUpload extends FLEA_Controller_Action { var $uploaddir = "./uploa