Python 中 -m 的典型用法、原理解析与发展演变
在命令行中使用 Python 时,它可以接收大约 20 个选项(option),语法格式如下:
python [-bBdEhiIOqsSuvVWx?] [-c command | -m module-name | script | - ] [args]
本文想要聊聊比较特殊的“-m”选项: 关于它的典型用法、原理解析与发展演变的过程。
首先,让我们用“--help”来看看它的解释:

-m mod run library module as a script (terminates option list)
"mod"是“module”的缩写,即“-m”选项后面的内容是 module(模块),其作用是把模块当成脚本来运行。
“terminates option list”意味着“-m”之后的其它选项不起作用,在这点上它跟“-c”是一样的,都是“终极选项”。官方把它们定义为“接口选项”(Interface options),需要区别于其它的普通选项或通用选项。
-m 选项的五个典型用法
Python 中有很多使用 -m 选项的场景,相信大家可能会用到或者看见过,我在这里想分享 5 个。
在 Python3 中,只需一行命令就能实现一个简单的 HTTP 服务:
python -m http.server 8000 # 注:在 Python2 中是这样 python -m SimpleHTTPServer 8000

执行后,在本机打开“ http://localhost:8000 ”,或者在局域网内的其它机器上打开“ http://本机ip:8000 ”,就能访问到执行目录下的内容,例如下图就是我本机的内容:

与此类似,我们只需要一行命令“python -m pydoc -p xxx”,就能生成 HTML 格式的官方帮助文档,可以在浏览器中访问。

上面的命令执行了 pydoc 模块,会在 9000 端口启动一个 http 服务,在浏览器中打开,我的结果如下:

它的第三个常见用法是执行 pdb 的调试命令“python -m pdb xxx.py”,以调试模式来执行“xxx.py”脚本:

第四个同样挺有用的场景是用 timeit 在命令行中测试一小段代码的运行时间。以下的 3 段代码,用不同的方式拼接 “0-1-2-……-99” 数字串。可以直观地看出它们的效率差异:

最后,还有一种常常被人忽略的场景:“python -m pip install xxx”。我们可能会习惯性地使用“pip install xxx”,或者做了版本区分时用“pip3 install xxx”,总之不在前面用“python -m”做指定。但这种写法可能会出问题。
很巧合的是,在本月初(2019.11.01),Python 的核心开发者、第一届指导委员会 五人成员之一的 Brett Cannon专门写了一篇博客《 Why you should use "python -m pip" 》,提出应该使用“python -m pip”的方式,并做了详细的解释。
他的主要观点是:在存在多个 Python 版本的环境中,这种写法可以精确地控制三方库的安装位置。例如用“python3.8 -m pip”,可以明确指定给 3.8 版本安装,而不会混淆成其它的版本。
(延伸阅读:关于 Brett 的文章,这有一篇简短的归纳《 原来我一直安装 Python 库的姿势都不对呀! 》)
-m 选项的两种原理解析
看了前面的几种典型用法,你是否开始好奇: “-m”是怎么运作的?它是怎么实现的?
对于“python -m name”,一句话解释: Python 会检索 sys.path ,查找名字为“name”的模块或者包(含命名空间包),并将其内容当成“__main__”模块来执行。
1、对于普通模块
以“.py”为后缀的文件就是一个模块,在“-m”之后使用时,只需要使用模块名,不需要写出后缀,但前提是该模块名是有效的,且不能是用 C 语言写成的模块。
在“-m”之后,如果是一个无效的模块名,则会报错“No module named xxx”。
如果是一个带后缀的模块,则首先会导入该模块,然后可能报错:Error while finding module specification for 'xxx.py' (AttributeError: module 'xxx' has no attribute '__path__'。
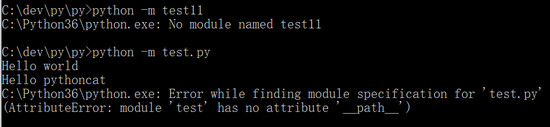
对于一个普通模块,有时候这两种写法表面看起来是等效的:

两种写法都会把定位到的模块脚本当成主程序入口来执行,即在执行时,该脚本的 __name__ 都是”__main__“,跟 import 导入方式是不同的。
但它的前提是:在执行目录中存在着“test.py”,且只有唯一的“test”模块。对于本例,如果换一个目录执行的话,“python test.py”当然会报找不到文件的错误,然而,“python -m test”却不会报错,因为解释器在遍历 sys.path 时可以找到同名的“test”模块,并且执行:
由此差异,我们其实可以总结出“-m”的用法: 已知一个模块的名字,但不知道它的文件路径,那么使用“-m”就意味着交给解释器自行查找,若找到,则当成脚本执行。
以前文的“python -m http.server 8000”为例,我们也可以找到“server”模块的绝对路径,然后执行,尽管这样会变得很麻烦。

那么,“-m”方式与直接运行脚本相比,在实现上有什么不同呢?
直接运行脚本时,相当于给出了脚本的完整路径(不管是绝对路径还是相对路径),解释器根据 文件系统的查找机制, 定位到该脚本,然后执行 使用“-m”方式时,解释器需要在不 import 的情况下,在 所有模块命名空间 中查找,定位到脚本的路径,然后执行。为了实现这个过程,解释器会借助两个模块: pkgutil 和 runpy ,前者用来获取所有的模块列表,后者根据模块名来定位并执行脚本 2、对于包内模块
如果“-m”之后要执行的是一个包,那么解释器经过前面提到的查找过程,先定位到该包,然后会去执行它的“__main__”子模块,也就是说,在包目录下需要实现一个“__main__.py”文件。
换句话说,假设有个包的名称是“pname”,那么, “python -m pname”,其实就等效于“python -m pname.__main__”。
仍以前文创建 HTTP 服务为例,“http”是 Python 内置的一个包,它没有“__main__.py”文件,所以使用“-m”方式执行时,就会报错:No module named http.__main__; 'http' is a package and cannot be directly executed。

作为对比,我们可以看看前文提到的 pip,它也是一个包,为什么“python -m pip”的方式可以使用呢?当然是因为它有“__main__.py”文件:

“python -m pip”实际上执行的就是这个“__main__.py”文件,它主要作为一个调用入口,调用了核心的"pip._internal.main"。
http 包因为没有一个统一的入口模块,所以采用了“python -m 包.模块”的方式,而 pip 包因为有统一的入口模块,所以加了一个“__main__.py”文件,最后只需要写“python -m 包”,简明直观。
-m 选项的十年演变过程
最早引入 -m 选项的是 Python 2.4 版本(2004年),当时功能还挺受限,只能作用于普通的内置模块(如 pdb 和 profile)。
随后,知名开发者 Nick Coghlan 提出的《PEP 338 -- Executing modules as scripts》把它的功能提升了一个台阶。这个 PEP 在 2004 年提出,最终实现在 2006 年的 2.5 版本。
(插个题外话:Nick Coghlan 是核心开发者中的核心之一,也是第一届指导委员会的五人成员之一。记得当初看材料,他是在 2005 年被选为核心开发者的,这时间与 PEP-338 的时间紧密贴合)

这个 PEP 的几个核心点是:
- 结合了 PEP-302 的新探针机制(new import hooks),提升了解释器查找包内模块的能力
- 结合了其它的导入机制(例如
zipimport和冻结模块(frozen modules)),拓展了解释器查找模块的范围与精度 - 开发了新的
runpy.run_module(modulename)来实现本功能,而不用修改 CPython 解释器,如此可方便移植到其它解释器
至此,-m 选项使得 Python 可以在所有的命名空间内定位到命令行中给定的模块。
2009 年,在 Python 3.1 版本中,只需给定包的名称,就能定位和运行它的“__main__”子模块。2014 年,-m 扩展到支持命名空间包。
至此,经过十年的发展演变,-m 选项变得功能齐全,羽翼丰满。
最后,我们来个 ending 吧:-m 选项可能看似不起眼,但它绝对是最特别的选项之一,它使得在命令行中,使用内置模块、标准包与三方库时变得更轻松便利。有机会就多用一下吧,体会它带来的愉悦体验。
参考材料
https://docs.python.org/3.7/using/cmdline.html#cmdoption-m
https://snarky.ca/why-you-should-use-python-m-pip
https://www.python.org/dev/peps/pep-0338/
总结
以上所述是小编给大家介绍的Python 中 -m 的典型用法、原理解析与发展演变,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
K-means聚类算法介绍与利用python实现的代码示例
聚类 今天说K-means聚类算法,但是必须要先理解聚类和分类的区别,很多业务人员在日常分析时候不是很严谨,混为一谈,其实二者有本质的区别. 分类其实是从特定的数据中挖掘模式,作出判断的过程.比如Gmail邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,我人工对于每一封邮件点选"垃圾"或"不是垃圾",过一段时间,Gmail就体现出一定的智能,能够自动过滤掉一些垃圾邮件了.这是因为在点选的过程中,其实是给每一条邮件打了一个"标签&qu
-
Python3利用SMTP协议发送E-mail电子邮件的方法
前言 本文主要给大家介绍了关于Python3用SMTP协议发送电子邮件的相关内容,在介绍如何使用python程序向指定邮箱发送邮件之前,我们需要先介绍一下有关电子邮件的相关知识. Email的历史比Web还要久远,直到现在,Email也是互联网上应用非常广泛的服务. 几乎所有的编程语言都支持发送和接收电子邮件,但是,先等等,在我们开始编写代码之前,有必要搞清楚电子邮件是如何在互联网上运作的. 假设我们自己的电子邮件地址是me@163.com,对方的电子邮件地址是friend@sina.com,现
-
Python实现k-means算法
本文实例为大家分享了Python实现k-means算法的具体代码,供大家参考,具体内容如下 这也是周志华<机器学习>的习题9.4. 数据集是西瓜数据集4.0,如下 编号,密度,含糖率 1,0.697,0.46 2,0.774,0.376 3,0.634,0.264 4,0.608,0.318 5,0.556,0.215 6,0.403,0.237 7,0.481,0.149 8,0.437,0.211 9,0.666,0.091 10,0.243,0.267 11,0.245,0.057 12
-
Python机器学习之K-Means聚类实现详解
本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.其基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果.各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开. 算法大致流程为:(1)随机选取k个点作为种子点(这k个点不一定属于数据集)
-
Python的Flask框架中使用Flask-Migrate扩展迁移数据库的教程
我们在升级系统的时候,经常碰到需要更新服务器端数据结构等操作,之前的方式是通过手工编写alter sql脚本处理,经常会发现遗漏,导致程序发布到服务器上后无法正常使用. 现在我们可以使用Flask-Migrate插件来解决之,Flask-Migrate插件是基于Alembic,Alembic是由大名鼎鼎的SQLAlchemy作者开发数据迁移工具. 具体操作如下: 1. 安装Flask-Migrate插件 $ pip install Flask-Migrate 2. 修改Flask App部分的代
-
详解K-means算法在Python中的实现
K-means算法简介 K-means是机器学习中一个比较常用的算法,属于无监督学习算法,其常被用于数据的聚类,只需为它指定簇的数量即可自动将数据聚合到多类中,相同簇中的数据相似度较高,不同簇中数据相似度较低. K-MEANS算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法.k-means 算法接受输入量 k :然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高:而不同聚类中的对象相似度较小. 核心思想 通过迭代寻找
-
Python 中 -m 的典型用法、原理解析与发展演变
在命令行中使用 Python 时,它可以接收大约 20 个选项(option),语法格式如下: python [-bBdEhiIOqsSuvVWx?] [-c command | -m module-name | script | - ] [args] 本文想要聊聊比较特殊的"-m"选项: 关于它的典型用法.原理解析与发展演变的过程. 首先,让我们用"--help"来看看它的解释: -m mod run library module as a script (ter
-
Python中使用gflags实例及原理解析
这篇文章主要介绍了Python中使用gflags实例及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 安装命令pip install python-gflags 使用示例: import gflags FLAGS = gflags.FLAGS gflags.DEFINE_string('name', 'ming', 'this is a value') gflags.DEFINE_integer('qps', 0, 'test qps'
-
Python中的xlrd模块使用原理解析
on里面的xlrd模块详解(一) - 疯了的小蜗 - 博客园[内容]:> 那我就一下面积个问题对xlrd模块进行学习一下: 什么是xlrd模块? 为什么使用xlrd模块? 1.什么是xlrd模块? ♦python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库. 今天就先来说一下xlrd模块: 一.安装xlrd模块 ♦ 到python官网下载http://pypi.python.org/pypi/xlrd模块安装,前提是已经安装了python
-
python中namedtuple函数的用法解析
源码解释: def namedtuple(typename, field_names, *, rename=False, defaults=None, module=None): """Returns a new subclass of tuple with named fields. >>> Point = namedtuple('Point', ['x', 'y']) >>> Point.__doc__ # docstring for
-
python @propert装饰器使用方法原理解析
这篇文章主要介绍了python @propert装饰器使用方法原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 首先,@propert的作用是把类中的方法『变成』了属性,方便通过实例访问.propert可以有两种用法:可以把一个方法变成只读属性:可以对一些属性进行过滤. 想象这样一个场景,在实例化一个类之后,需要对类的一个属性进行赋值,这时候是没有对属性属性被赋予的值进行判断的,如果属性被赋予了一个不合适的值,那么代码在后面执行的时候就会
-
python中的lambda表达式用法详解
本文实例讲述了python中的lambda表达式用法.分享给大家供大家参考,具体如下: 这里来为大家介绍一下lambda函数. lambda 函数是一种快速定义单行的最小函数,是从 Lisp 借用来的,可以用在任何需要函数的地方 .下面的例子比较了传统的函数定义def与lambda定义方式: >>> def f ( x ,y): ... return x * y ... >>> f ( 2,3 ) 6 >>> g = lambda x ,y: x *
-
python中list循环语句用法实例
本文实例讲述了python中list循环语句用法.分享给大家供大家参考.具体用法分析如下: Python 的强大特性之一就是其对 list 的解析,它提供一种紧凑的方法,可以通过对 list 中的每个元素应用一个函数,从而将一个 list 映射为另一个 list. 实例 复制代码 代码如下: a = ['cat', 'window', 'defenestrate'] for x in a: print x, len(x) for x in [1, 2, 3]: print x,
-
python中使用%与.format格式化文本方法解析
初学python,看来零零碎碎的格式化文本的方法,总结一下python中格式化文本的方法.使用不当的地欢迎指出谢谢. 1.首先看使用%格式化文本 常见的占位符: 常见的占位符有: %d 整数 %f 浮点数 %s 字符串 %x 十六进制整数 使用方法: >>> 'Hello, %s' % 'world' 'Hello, world' >>> 'Hi, %s, you have $%d.' % ('Michael', 1000000) 'Hi, Michael, you h
-
Python中使用__new__实现单例模式并解析
单例模式是一个经典设计模式,简要的说,一个类的单例模式就是它只能被实例化一次,实例变量在第一次实例化时就已经固定. 在Python中常见的单例模式有None,这就是一个很典型的设计,通常使用 if xxx is None或者if xxx is not None来比较运算. Python实现单例模式 代码如下: class MyClass: _instance = None _first_init = False def __new__(cls, *args, **kwargs): if not
-
python通过opencv实现图片裁剪原理解析
这篇文章主要介绍了python通过opencv实现图片裁剪原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 图像裁剪的基本概念 : 图像裁剪是指将图像中我们想要的研究区以外的区域去除,经常是按照行政区划或研究区域的边界对图像进行裁剪.例如,一张500×400的图像,我们只想要中间的250×200的区域,就可以使用图像裁剪将四周的区域去除. 在实际开发工作中,我们经常需要对图像进行分幅裁剪,按照ERDAS实际图像分幅裁剪的过程,可以将图像分