django框架使用views.py的函数对表进行增删改查内容操作详解【models.py中表的创建、views.py中函数的使用,基于对象的跨表查询】
本文实例讲述了django框架使用views.py函数对表进行增删改查内容操作。分享给大家供大家参考,具体如下:
models之对于表的创建有以下几种:
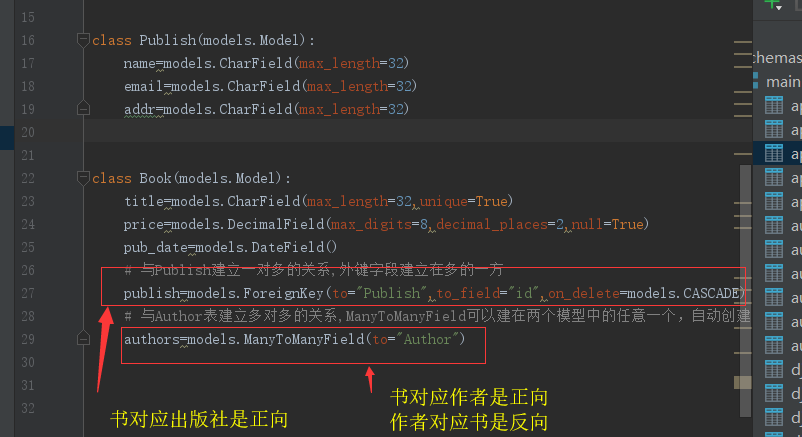
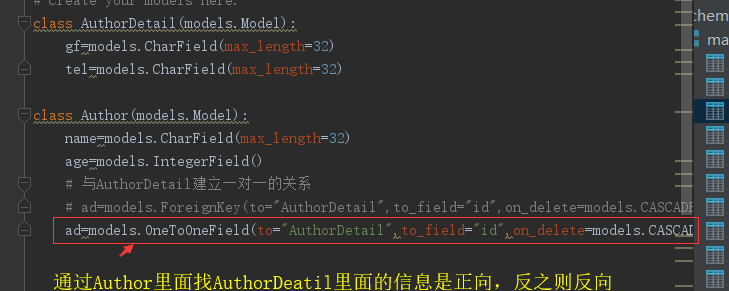
一对一:ForeignKey("Author",unique=True), OneToOneField("Author")
一对多:ForeignKey(to="Publish",to_field="id",on_delete.CASCADE)
多对多:ManyToManyField(to="Author")
首先我们来创建几张表
from django.db import models # Create your models here. class AuthorDetail(models.Model): gf=models.CharField(max_length=32) tel=models.CharField(max_length=32) class Author(models.Model): name=models.CharField(max_length=32) age=models.IntegerField() # 与AuthorDetail建立一对一的关系 # ad=models.ForeignKey(to="AuthorDetail",to_field="id",on_delete=models.CASCADE,unique=True) ad=models.OneToOneField(to="AuthorDetail",to_field="id",on_delete=models.CASCADE,) class Publish(models.Model): name=models.CharField(max_length=32) email=models.CharField(max_length=32) addr=models.CharField(max_length=32) class Book(models.Model): title=models.CharField(max_length=32,unique=True) price=models.DecimalField(max_digits=8,decimal_places=2,null=True) pub_date=models.DateField() # 与Publish建立一对多的关系,外键字段建立在多的一方 publish=models.ForeignKey(to="Publish",to_field="id",on_delete=models.CASCADE) # 与Author表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建关系表book_authors authors=models.ManyToManyField(to="Author")
说明:
OneToOneField 表示创建一对一关系。
to 表示需要和哪张表创建关系
to_field 表示关联字段
on_delete=models.CASCADE表示级联删除。假设a表删除了一条记录,b表也还会删除对应的记录。ad表示关联字段,但是ORM创建表的时候,会自动添加_id后缀。那么关联字段为ad_id
注意:创建一对一关系,会将关联字添加唯一属性。比如:ad_id
ForeignKey 表示建立外键
on_delete=models.CASCADE表示级联删除。使用ForeignKey必须要加on_delete。否则报错。这是2.x规定的ManyToManyField 表示建立多对多的关系。它只需要一个to参数,表示和哪张表创建多对多关系!
这里是在book模型下定义了多对多关系,它会自动创建一张额外的关系表。表的名字就是当前模型的名字(book)+关系的属性名(等式左边的属性名authors)。
也就是会创建表book_authors,它只有3个字段,分别是:本身表的id,boo表主键id,authors表主键id。
下面在视图 views.py里面使用
from django.shortcuts import render,HttpResponse
from app01.models import AuthorDetail,Author,Publish,Book
# Create your views here.
def add(request):
# 注意:因为author的ad属性是关联authordetail表,必须添加authordetail表,才能添加author表。
# hong_gf=AuthorDetail.objects.create(gf='小唐',tel=1314)
# hong=Author.objects.create(name='hong',age='25',ad=hong_gf)
# print(hong)
# # publish_id就是Book类的publish属性。它的字段为publish_id
# book = Book.objects.create(title='西游记', price=100, pub_date="1743-4-12", publish_id=2)
# print(book.title) # 打印title
# return HttpResponse('添加成功')
# xigua = Publish.objects.filter(name="西瓜出版社").first() #model对象
# book = Book.objects.create(title='三国演义',price=300,pub_date="1643-4-12",publish=xigua)
# return HttpResponse('添加成功')
下面是对应两个其他表的字段
# book = Book.objects.create(title='python',price=122,pub_date="2012-12-12",publish_id=1)
# xiao = Author.objects.filter(name="xiao").first() #取Author表name为xiao的id
# zhang = Author.objects.filter(name="zhang").first()
# print(zhang)
# book.authors.add(xiao,zhang) # 添加2条数据,接收一个参数,就会产生一条记录
#
# return HttpResponse('添加成功')
下面是对应author表的所有作者
# book = Book.objects.create(title='linux', price=155, pub_date="2013-12-12", publish_id=2)
# author_list=Author.objects.all()
# book.authors.add(*author_list)
# return HttpResponse('添加成功')
#解除绑定关系
# book = Book.objects.filter(id=3).first() # 先找到这本书
# xiao = Author.objects.filter(name="xiao").first() # 再找到作者
# book.authors.remove(xiao) # 解除绑定的关系
# return HttpResponse('解除绑定成功')
#清空所有关系对象
# book = Book.objects.filter(id=4).first()
# book.authors.clear() # 清理所有关系对象
# return HttpResponse('清理成功')
#绑定唯一的作者或者几个作者,放入一个列表中
book=Book.objects.filter(id=3).first()
wang=Author.objects.filter(name='wang').first()
book.authors.set([wang]) #先清空再设置
return HttpResponse('绑定唯一作者成功')
总结:
重点掌握create,add,remove,clear,set这五个方法!
添加表记录:
一对一和一对多,使用create方法。它有2种使用方法:
1. create(字段名1=值1...)。适用于表单添加操作!注意,这里面的字段名是ORM创建表之后的的字段名
比如: book类的publish属性,它是关联字段,ORM创建之后,字段名为publish_id
2.create(模型类属性1=值1...)。比如book类的publish属性,它是关联字段。
直接create(publish=obj1),注意,它接收一个model对象,对象包含了主键id
多对多使用add方法。add用2种使用方法:
1.add(obj1,obj2...) 它接收一个model对象,对象包含了主键id
2.add(主键id1,主键id2...) 它接收一个主键id。适用于表单添加操作!
还有一个python的打散语法,前面加一个*就可以了。比如*[1,2],它会依次调用前置方法,每次只取一个值。表单操作,会用到!
删除记录:
适用于一对一,一对多,多对一。
remove(obj1, obj2, ...) 去除多个关系对象。它需要指定一个或者多个对象
clear() 清理所有关系对象。不管现有的关系有多少,一律清空!
set([obj1,obj2...]) 先清空再设置。不管现有的关系有多少,一律清空再设置。适用于网页后台修改操作
查询 ---》基于对象的跨表查询(子查询)
一对多查询
book_authors表的内容

一般写法:
def add(request): book = Book.objects.filter(title="西游记").first() #过滤出记录 publish_id = book.publish_id #找出书籍对应的出版社id publish = Publish.objects.filter(id=publish_id).first() #根据id号在 Publish表中找出出版社名称 print(publish.name)
简单写法
def add(request): book = Book.objects.filter(title="西游记").first() #找出Book表中title为 西游记的 记录 print(book.publish.name) #书籍.出版社.名称
正向和反向查询
正向和反向,就看关键字段在哪里?
如果是通过关联字段查询,就是正向。否则是反向!
简单来说:正向,按照字段。
反向,按照表名小写_set() 例如:publish.book_set() --->适用于一对多,多对多
记录只有一条 通过 字段.名称 -----》一对一
例子:找出西瓜出版社出版的所有书籍名称(一对多查询)
正向查询
def add(request):
publish = Publish.objects.filter(name="西瓜出版社").first() # 先找出版社
ret = Book.objects.filter(publish_id=publish.id).values("title") # 再找书籍
print(ret)
return HttpResponse('ok')
反向查询
def add(request):
publish = Publish.objects.filter(name="西瓜出版社").first() # 先找出版社
ret = publish.book_set.all().values("title") # 再找书籍,过滤title
print(ret)
return HttpResponse('ok')
例子:(多对多)
正向查询 查询python这本书籍的所有作者的姓名和年龄
def add(request):
book = Book.objects.filter(title="python").first() # 先找书籍
ret = book.authors.all().values("name","age") # 再找作者,过滤name和age
print(ret)
return HttpResponse('ok')
反向查询:查询作者xiao出版过的所有书籍名称
def add(request):
xiao = Author.objects.filter(name="xiao").first() # 先找作者
ret = xiao.book_set.all().values("title") # 再找书籍,过滤title
print(ret)
return HttpResponse('ok')
例子:一对一
正向查询:查询xiao的女朋友的名字--》gf
def add(request):
xiao = Author.objects.filter(name="xiao").first() # 先找作者
ret = xiao.ad.gf # 再找女朋友
print(ret)
return HttpResponse('ok')
反向查询:查询手机号为112的作者名字
def add(request): phone = AuthorDetail.objects.filter(tel="112").first() # 先找号码 ret = phone.author.name # 再找作者的名字 print(ret)
希望本文所述对大家基于Django框架的Python程序设计有所帮助。
相关推荐
-
django的聚合函数和aggregate、annotate方法使用详解
支持聚合函数的方法: 提到聚合函数,首先我们要知道的就是这些聚合函数是不能在django中单独使用的,要想在django中使用这些聚合函数,就必须把这些聚合函数放到支持他们的方法内去执行.支持聚合函数的方法有两种,分别是aggregate和annotate,这两种方法执行的原生SQL以及结果都有很大的区别,下面我们以实例操作的方式一一介绍: # 示例模型: class Author(models.Model): """作者模型""" name =
-

Django之无名分组和有名分组的实现
在Django 2.0版本之前,在urls,py文件中,用url设定视图函数 urlpatterns = [ url(r'login/',views.login), ] 其中第一个参数是正则匹配,如下代码,输入http://127.0.0.1:8000/login,出现的是login页面,但是输入login2,出现的还是login页面,这是因为Django会将匹配成功的返回,不会继续往下匹配 urlpatterns = [ url(r'login',views.login), url(r'log
-
django框架基于queryset和双下划线的跨表查询操作详解
本文实例讲述了django框架基于queryset和双下划线的跨表查询操作.分享给大家供大家参考,具体如下: 前面篇随笔写的是基于对象的跨表查询:对象.objects.filter(...) 对象.关联对象_set.all(...) -->反向 基于对象的跨表查询例如: book_obj= Book.objects.filter(id=4).first() #注意多了个first print(book_obj) #go 这里得到的是一个models对象 print(book_obj.publ
-
Django ORM 聚合查询和分组查询实现详解
models.py: from django.db import models # 出版社 class Publisher(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=64, null=False, unique=True) def __str__(self): return "<Publisher object: {}>".format(
-
Django 表单模型选择框如何使用分组
起步 Django 表单中有两种字段类型可以使用选择框: ChoiceField 和 ModelChoiceField . 对于 ChoiceField 的基本使用是: class ExpenseForm(forms.Form): CHOICES = ( (11, 'Credit Card'), (12, 'Student Loans'), (13, 'Taxes'), (21, 'Books'), (22, 'Games'), (31, 'Groceries'), (32, 'Restaura
-
django框架F&Q 聚合与分组操作示例
本文实例讲述了django框架F&Q 聚合与分组操作.分享给大家供大家参考,具体如下: F 使用查询条件的值,专门取对象中某列值的操作,可以对同一个表中的两个列进行比较 from django.db.models import F ret=models.Book.objects.filter(count__lt=F('sale')).values() #查找 列 count < sale的数据 for i in ret: print(i) models.Book.objects.filter
-
django 中的聚合函数,分组函数,F 查询,Q查询
先以mysql的语句,聚合用在分组里, 对mysql中groupby 是分组 每什么的时候就要分组,如 每个小组,就按小组分, group by 字段 having 聚合函数 #举例 :求班里的平均成绩, select Avg(score) from stu 在django中 聚合 是aggreate(*args,**kwargs),通过QuerySet 进行计算.做求值运算的时候使用 分组 是annotate(*args,**kwargs),括号里是条件,遇到 每什么的时候就要分组, 先从mo
-
Django中自定义查询对象的具体使用
自定义查询对象 - objects ①声明一个类EntryManager,继承自models.Manager,并添加自定义函数 ②使用创建的自定义类EntryManager 覆盖Models中的objects # models.py class AuthorManager(models.Manager): # 新建一个类,继承自models.Manager def name_count(self, keywords): # 添加自定义的查询函数 '''统计姓名中含有某些关键字的数量''' ret
-
Django Aggregation聚合使用方法解析
在当今根据需求而不断调整而成的应用程序中,通常不仅需要能依常规的字段,如字母顺序或创建日期,来对项目进行排序,还需要按其他某种动态数据对项目进行排序.Djngo聚合就能满足这些要求. 以下面的Model为例 from django.db import models class Author(models.Model): name = models.CharField(max_length=100) age = models.IntegerField() class Publisher(model
-
对Django中的权限和分组管理实例讲解
权限 Django中内置了权限的功能.他的权限都是针对表或者说是模型级别的.比如对某个模型上的数据是否可以进行增删改查操作.他不能针对数据级别的,比如对某个表中的某条数据能否进行增删改查操作(如果要实现数据级别的,考虑使用django-guardian).创建完一个模型后,针对这个模型默认就有四种权限,分别是增/删/改/查.可以在执行完migrate命令后,查看数据库中的auth_permission表中的所有权限. 字段: content_type_id:是一个外键,参考表是django_co