Python实现本地csv文件合并
目录
- 一、单文件之间合并
- 二、单个文件夹底下多个文件合并
- 三、多个文件夹底下多个文件合并
- 四、多文件夹[函数递归]
- 总结
本篇的文件合并主要是针对.csv的文件合并。
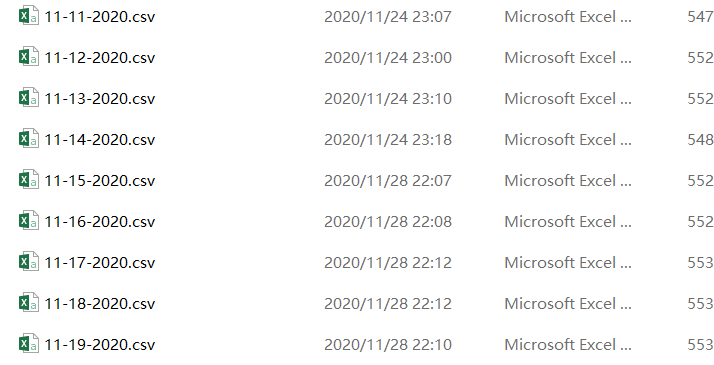
一、单文件之间合并
首先,要查询目录底下的文件要导入OS。并且我们要将.csv文件以pandas的dataframe底下,因此要导入PANDAS,另外由于我们要遍历目录,因此导入 GLOB:
import os import pandas as pd import glob
注:
import os的作用:在python环境下对文件,文件夹执行操作的一个模块。
os.name返回当前系统 os.getcwd()返回当前的路径 os.remove(路径)删除路径下的文件
import glob的作用: glob是python自带的一个操作文件的相关模块,由于模块功能比较少,所以很容易掌握。用它可以查找符合特定规则的文件路径名。使用该模块查找文件,只需要用到: “*”, “?”, “[]”这三个匹配符;
”*”匹配0个或多个字符; ”?”匹配单个字符; ”[]”匹配指定范围内的字符,如:[0-9]匹配数字。
f1=open('../input/covid19temp/2020/12-30-2020.csv').read()
f2=open('../input/covid19temp/2020/12-31-2020.csv').read()
with open('f1112.csv','a+') as f:
f.write('\n'+f1)
f.write('\n'+f2)
合并完成之后就会多出一个f1112.csv文件:
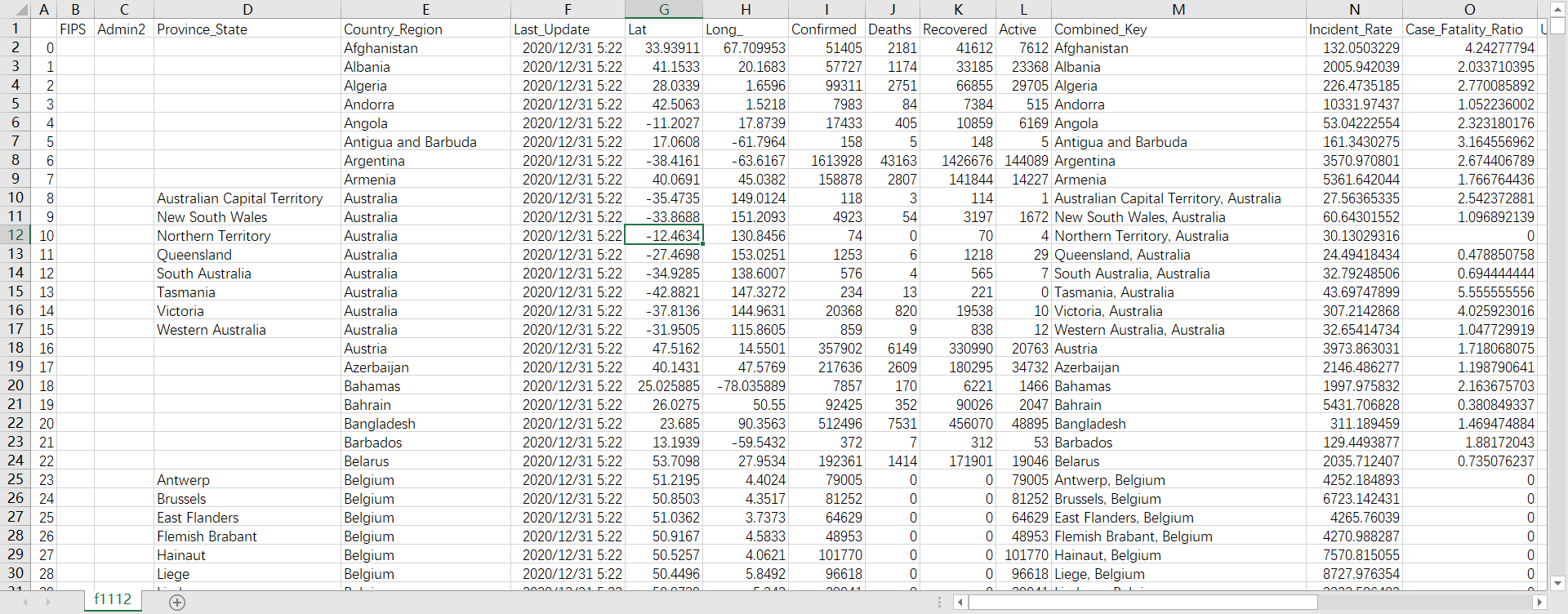
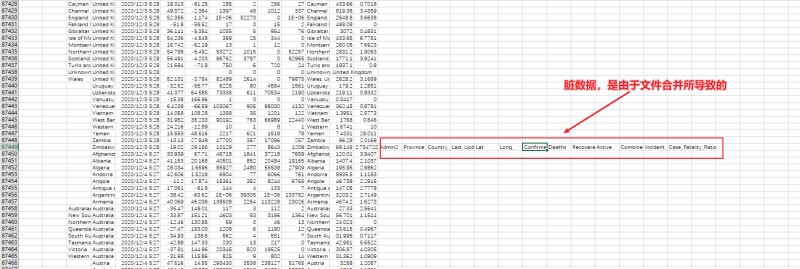
然而打开f1112.csv后发现合并后的文件有一些脏数据没有整理:
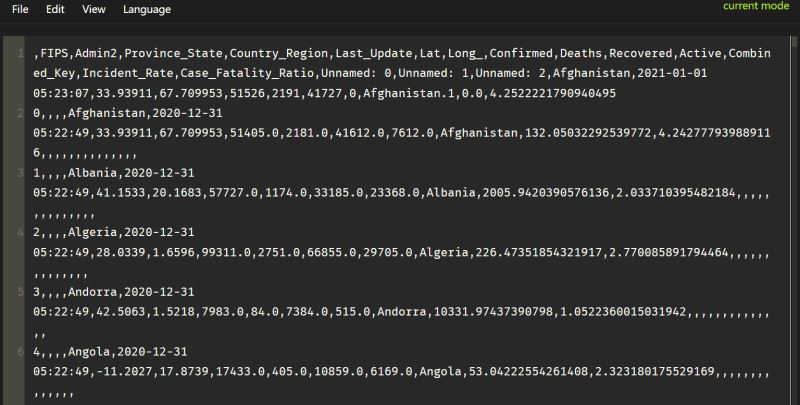
这时候我们试试skiprows:
在读取文件的时候设置skiprows参数的值,设置为1,会跳过一行,这里是要将第二个文件的索引属性给去掉,因为已经和第一个文件合并了,而第一个文件有索引属性了。
f1=pd.read_csv('../input/covid19temp/2020/12-30-2020.csv')
f2=pd.read_csv('../input/covid19temp/2020/12-31-2020.csv',skiprows=1)
f1112=f1.append(f2)
f1112.to_csv('f1112.csv') # 导出该文件
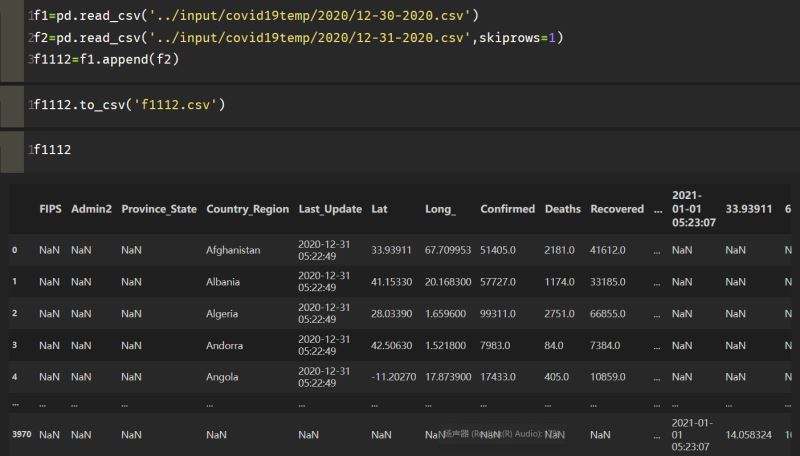
在本地目录中打开该文件:

二、单个文件夹底下多个文件合并
csv_list=glob.glob('../input/covid19temp/2020/*.csv')
# 如果不加上*的话拿到的就是目录的名称,如果加上*,拿到的就是完整的目录数据
print(csv_list)

for i in csv_list:
fr=open(i,'r').read()
with open('2020csvdata.csv','a') as f:
f.write(fr)
f.close()
print('数据文件合并完成!')
csv_list=glob.glob('../input/covid19temp/2020/*')
for i in csv_list:
fr=open(i,'rb').read()
with open('2020csvdata2.csv','ab') as f:
f.write(fr)
f.close()
print('数据文件合并完成!')
csv_list=glob.glob('../input/covid19temp/2020/*')
csvdatadf=pd.DataFrame()
for i in csv_list:
csvdata=pd.read_csv(i)
csvdatadf=csvdatadf.append(csvdata)
print('数据文件合并完成!')
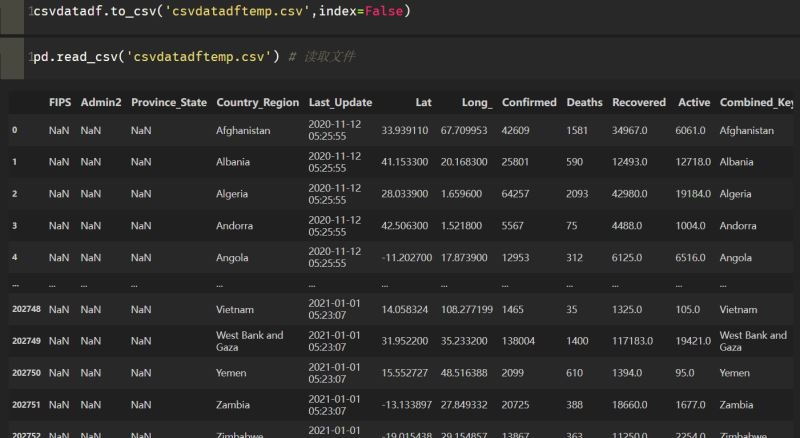
合并之后使用pd.read_csv读取文件数据,一共有20W+的疫情数据记录:
三、多个文件夹底下多个文件合并
import os
import pandas as pd
import glob
import openpyxl
import numpy as np
path='../input/covid19temp' # 写的路径
csv_lists=[] # 该列表的作用
# 是否更新目录判断:
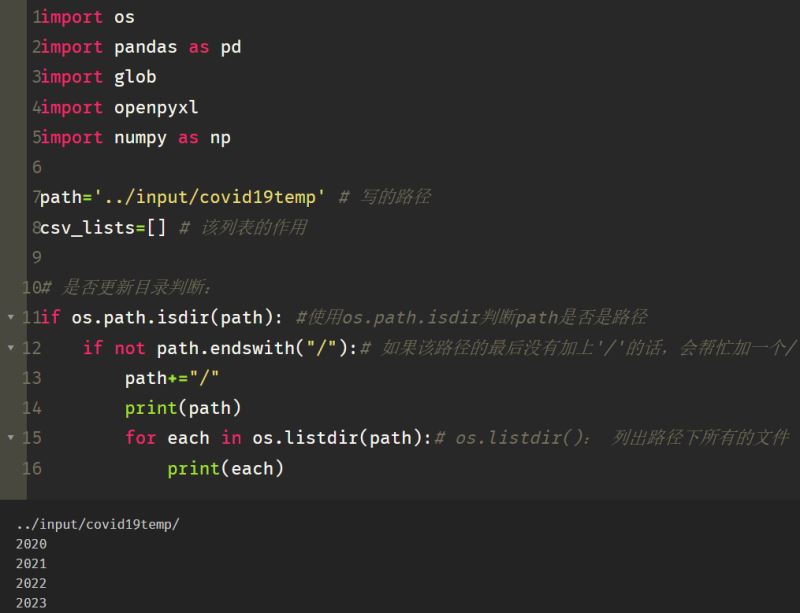
if os.path.isdir(path): #使用os.path.isdir判断path是否是路径
if not path.endswith("/"):# 如果该路径的最后没有加上'/'的话,会帮忙加一个/
path+="/"
print(path)
如上图所示,路径后面多了一个 ‘/’,否则路径会找不到
文件操作:
os.listdir(): 列出路径下所有的文件
os.path.join(): 连接文件的作用
os.path.isdir(): 判断是否是文件夹
import os
import pandas as pd
import glob
import openpyxl
import numpy as np
path='../input/covid19temp' # 写的路径
csv_lists=[] # 该列表的作用
# 是否更新目录判断:
if os.path.isdir(path): #使用os.path.isdir判断path是否是路径
if not path.endswith("/"):# 如果该路径的最后没有加上'/'的话,会帮忙加一个/
path+="/"
print(path)
for each in os.listdir(path):# os.listdir(): 列出路径下所有的文件
print(each)
import os
import pandas as pd
import glob
import openpyxl
import numpy as np
path='../input/covid19temp' # 写的路径
csv_lists=[] # 该列表的作用
# 是否更新目录判断:
if os.path.isdir(path): #使用os.path.isdir判断path是否是路径
if not path.endswith("/"):# 如果该路径的最后没有加上'/'的话,会帮忙加一个/
path+="/"
print(path)
for each in os.listdir(path):# os.listdir(): 列出路径下所有的文件
print(each)
sub_path=path+each
path_list=[]
if os.path.isdir(sub_path):
path_list.append(sub_path)
csv_lists.append(path_list) # 生成主目录下路径列表(非文件)
# 根据路径进行路径下文件列表的生成
csvlists=[]
for i in range(len(csv_lists)):
# print(i)
csvlists.append(glob.glob(csv_lists[i][0]+'/*.csv'))
csvlists
# 获取每年的文件路径
csvfilelist=[]
for j in range(len(csvlists)):
for k in csvlists[j]:
csvfilelist.append(k)
csvfilelist
csvdatadf=pd.DataFrame()
for m in csvfilelist:
filesize=os.path.getsize(m)
if filesize>0:
csvdata=pd.read_csv(m)
csvdatadf=csvdatadf.append(csvdata)
else:
continue
print('数据合并完成')
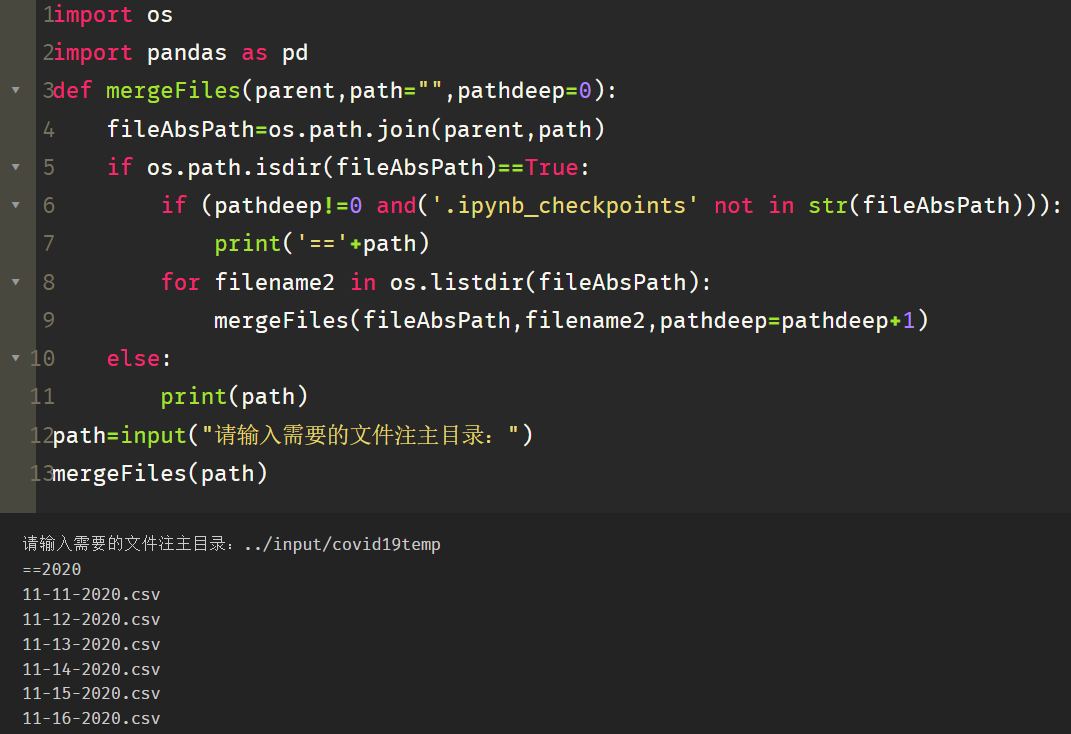
四、多文件夹[函数递归]
import os
import pandas as pd
def mergeFiles(parent,path="",pathdeep=0):
fileAbsPath=os.path.join(parent,path)
if os.path.isdir(fileAbsPath)==True:
if (pathdeep!=0 and('.ipynb_checkpoints' not in str(fileAbsPath))):
print('=='+path)
for filename2 in os.listdir(fileAbsPath):
mergeFiles(fileAbsPath,filename2,pathdeep=pathdeep+1)
else:
print(path)
path=input("请输入需要的文件注主目录:")
mergeFiles(path)
总结
到此这篇关于Python实现本地csv文件合并的文章就介绍到这了,更多相关Python csv文件合并内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

教你如何把Python CSV 合并到多个sheet工作表
目标 将多个CSV文件,合并到一个Excel文件中的,多个sheet工作表. 前言 网上大多方法都是将csv直接合并在一起,也不分别创建sheet表. 还有一些解答说CSV不支持合并到多个sheet表. 网上有用宏命令的,我试了,但是只能导入一个sheet表.也有用python的,大多都没什么用. 尽管困难重重,最后终于还是利用pandas库实现了目标. 开始 下面的代码用到了,两个带数据的csv文件.(2019-04-01.csv和2019-04-02.csv) import pandas a
-
python:pandas合并csv文件的方法(图书数据集成)
数据集成:将不同表的数据通过主键进行连接起来,方便对数据进行整体的分析. 两张表:ReaderInformation.csv,ReaderRentRecode.csv ReaderInformation.csv: ReaderRentRecode.csv: pandas读取csv文件,并进行csv文件合并处理: # -*- coding:utf-8 -*- import csv as csv import numpy as np # ------------- # csv读取表格数据 # ---
-
Python实现本地csv文件合并
目录 一.单文件之间合并 二.单个文件夹底下多个文件合并 三.多个文件夹底下多个文件合并 四.多文件夹[函数递归] 总结 本篇的文件合并主要是针对.csv的文件合并. 一.单文件之间合并 首先,要查询目录底下的文件要导入OS.并且我们要将.csv文件以pandas的dataframe底下,因此要导入PANDAS,另外由于我们要遍历目录,因此导入 GLOB: import os import pandas as pd import glob 注: import os的作用:在python环境下对文
-
Python拆分大型CSV文件代码实例
这篇文章主要介绍了Python拆分大型CSV文件代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 #!/usr/bin/env python3 # -*- coding:utf-8 -*- # @FileName :Test.py # @Software PyCharm import os import pandas as pd # filename为文件路径,file_num为拆分后的文件行数 # 根据是否有表头执行不同程序,默认有表头
-
python实现对csv文件的列的内容读取
以下代码测试在python2.7 mac上运行成功 import csv with open('/Users/wangzhao/Downloads/test.csv', 'U') as csvfile: reader = csv.DictReader(csvfile) column = [row['Employee Name'] for row in reader] print column import csv with open('/Users/wangzhao/Downloads/test
-
Python中的CSV文件使用"with"语句的方式详解
是否可以直接使用with语句与CSV文件?能够做这样的事情似乎很自然: import csv with csv.reader(open("myfile.csv")) as reader: # do things with reader 但是csv.reader不提供__enter__和__exit__方法,所以这不行.但是我可以分两步做: import csv with open("myfile.csv") as f: reader = csv.reader(f)
-
Python如何读写CSV文件
CSV文件是一种纯文本文件,它使用特定的结构来排列表格数据. CSV文件内容看起来应该是下面这样的: column 1 name,column 2 name, column 3 name first row data 1,first row data 2,first row data 3 second row data 1,second row data 2,second row data 3 ... 每段数据是如何用逗号分隔的.通常,第一行标识每个数据块--换句话说,数据列的名称.之后的每一行
-
Python批量将csv文件转化成xml文件的实例
一.前言 逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本).纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据.CSV文件由任意数目的记录组成,记录间以某种换行符分隔:每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符.通常,所有记录都有完全相同的字段序列,通常都是纯文本文件. 可扩展标记语言,标准通用标记语言的子集,简称XML.是一种用
-
使用Python pandas读取CSV文件应该注意什么?
示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3,周娟,女,1998-03-25,合肥,护士,音乐,跑步 4,赵盈盈,Female,2001-6-32,,学生,画画 5,郑强强,男,1991-03-05,南京(nanjing),律师,历史-政治 如果一切正常的话,在Jupyter Notebook 中应该显示以下内容:
-
Python pandas读取CSV文件的注意事项(适合新手)
目录 前言 示例文件 文件编码 空值 日期错误 函数映射 方法1:直接使用labmda表达式 方法二:使用自定义函数 方法三:使用数值字典映射 总结 前言 本文是给使用pandas的新手而写,主要列出一些常见的问题,根据笔者所踩过的坑,进行归纳总结,希望对读者有所帮助. 示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3
-
Python 文本文件与csv文件的读取与写入
目录 一.文本文件读取与写入 1读取文件的read()方法 2读取文件的readline()方法 3读取文件的readlines()方法 4写入文件的write()方法 5写入文件的writelines()方法 二.csv文件读取与写入 一.文本文件读取与写入 1 读取文件的 read() 方法 file_object.read([size]) file_object 表示文件对象 size 表示读取数据的长度,单位是字节,如果size省略则读至文件尾 返回值是读取到的字符串 2 读取文件的 r
-
Python取读csv文件做dbscan分析
目录 1.读取csv数据做dbscan分析 2.输出结果显示 3.计算效率 1.读取csv数据做dbscan分析 读取csv文件中相应的列,然后进行转化,处理为本算法需要的格式,然后进行dbscan运算,目前公开的代码也比较多,本文根据公开代码修改, 具体代码如下: from sklearn import datasets import numpy as np import random import matplotlib.pyplot as plt import time import cop