jupyter 导入csv文件方式
先将准备的文件上传到自己的jupyter工作空间
import numpy as np
import pandas as pd
housing = pd.read_csv('housing.csv')
补充知识:在jupyter中读取CSV文件时出现‘utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte解决方法
导入
import pandas as pd
使用pd.read_csv()读csv文件时,出现如下错误:
UnicodeDecodeError: ‘utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte
出现原因:CSV文件不是UTF-8进行编码,而是用gbk进行编码的。jupyter-notebook使用的Python解释器的系统编码默认使用UTF-8.
解决方式有两种:
第一种:
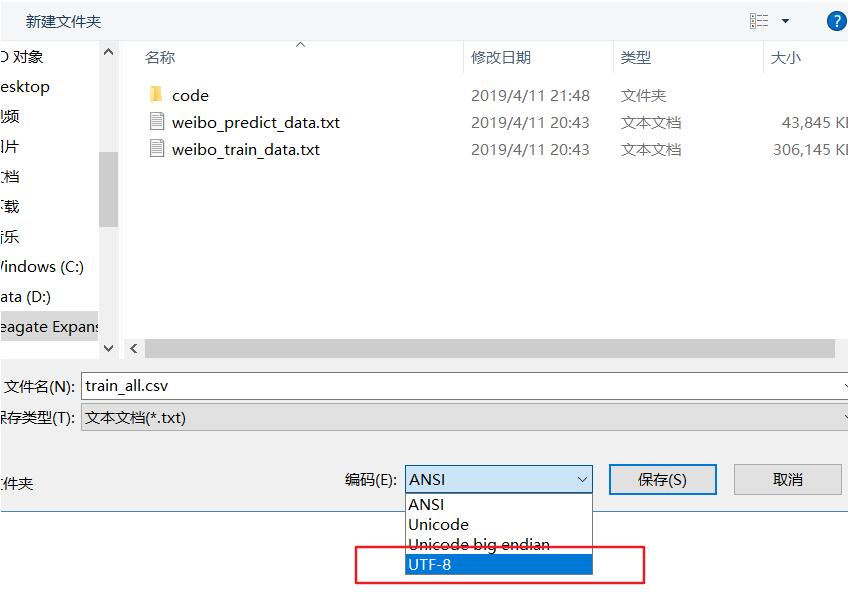
1.找到使用的csv文件--->鼠标右键--->打开方式---->选择记事本
2.打开文件选择“文件”----->"另存为“,我们可以看到默认编码是:ANSI,选择UTF-8重新保存一份,再使用pd.read_csv()打开就不会保存了

第二种:
使用pd.read()读取CSV文件时,进行编码
pd.read(filename,encoding='gbk')
比如:

以上这篇jupyter 导入csv文件方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
快速解决jupyter notebook启动需要密码的问题
jupyter notebook安装完成之后需要密码,还有某些情况下也会出现需要输入密码的情况 解决方法如下: 1.在运行界面输入 jupyter notebook list 2.之后运行界面会输出token值,将其复制到密码栏中 补充知识:Python 遇到NameError: name '_name_' is not defined这样的错误 今天练习写Python主函数的时候,遇到了NameError: name 'name' is not defined 这样的错误.>因为name是一个
-
jupyter修改文件名方式(TensorFlow)
1.选择文件 2.修改文件名称 补充知识:没用root权限启动jupyter notebook后,文件创建被denied 错误:Creating Notebook Failed 解决方法: sudo chown [普通用户名]:root ~/.local/share/jupyter *[普通用户名]:你的用户名字,转变jupyter 的权限为root 这样就可以在现有环境下,正常使用jupyter notebook了 以上这篇jupyter修改文件名方式(TensorFlow)就是小编分享给大家
-
解决Jupyter notebook中.py与.ipynb文件的import问题
在jupyter notebook中,因为其解析文件的方式是基于json的,所以其默认保存的文件格式不是.py而是.ipynb.而.ipynb文件并不能简单的import进.py或者.ipynb文件中,这就为开发带来了极大不便.因为在jupyter notebook中,一定要是在默认的.ipynb下才能有一系列的特性支持,比如自动补全,控制台等待,而.py文件只能通过文本编辑器修改,非常非常不便. 因为.ipynb可以import .py的module,所以其中一个解决方法是将已经写好的.ipy
-
jupyter notebook tensorflow打印device信息实例
juypter notebook中直接使用log_device_placement=True打印不出来device信息 # Creates a graph. with tf.device('/device:CPU:0'): a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name
-
jupyter notebook 的工作空间设置操作
Jupyter notebook 安装后,启动后,默认的工作空间是当前用户目录.为了方便对文档进行管理,往往需要自行设置工作空间.下面介绍一种便捷的工作空间设置方法. 对 Jupyter notebook 快捷方式进行修改.右击 jupyter notebook 快捷方式 -> 属性 -> 把"目标"中的 %USERPROFILE% 替换成你想要的目录,eg:D:\python-workspace. 接下来双击 Jupyter notebook 运行,就可以见证效果. 补充
-
Jupyter Notebook的连接密码 token查询方式
换用非默认浏览器时需要输入密码或token 查询方法: 在XX:\AnacondaXX\Scripts下 运行 jupyter-notebook.exe list 可得token 密码:(设成了用不了..???) 在jupyter notebook正常开的文件里打 in[1]from notebook.auth import passwd in[2]passwd() 补充知识:Anaconda3中自带Jupyter notebook如何查找token 最近在使用Anaconda3学习tensor
-
jupyter notebook 添加kernel permission denied的操作
为什么要手动添加核? 因为使用公司的服务器,最好不要直接使用anaconda自带的python,更不要使用系统下自带的python,如果每个人都使用同一个python,可能会给别人的工作带来"致命的伤害". 怎么添加? 正常情况: python -m ipykernel install --name your_env_name (your_env_name 代表你的python环境的名字) 如果出现 error13 permiss denied:/usr/local/share/jup
-
基于jupyter代码无法在pycharm中运行的解决方法
存在问题: jupyter代码无法在pycharm中运行 原因:工作文件和安装文件不统一引起的 解决方案: pycharm中新建工程项目时,要将图中所示红色部分勾选,从而保证可以引用到相应文件 补充知识:jupyter 在浏览器中 代码不执行 在机器学习的时候,当开始就遇到问题,pycharm启动jupyter notebook之后,浏览器前两行代码执行的好好的,后面就不执行了,上面的键全点了一遍(英语不行,见谅- -,死马当活马医).还是不行,后来,返现右上角python3旁边有个圈,当我重新
-
jupyter 导入csv文件方式
先将准备的文件上传到自己的jupyter工作空间 import numpy as np import pandas as pd housing = pd.read_csv('housing.csv') 补充知识:在jupyter中读取CSV文件时出现'utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte解决方法 导入 import pandas as pd 使用pd.read_csv()读csv文
-
H2 数据库导入CSV文件实现原理简析
1.启动H2数据库不打开浏览器窗口(默认是打开的) 2.数据库创建SQL增加了支持BigDecimal类型,h2数据库默认是不支持bigdecimal类型的: Sql代码 复制代码 代码如下: create table test(id int(11),charge BigDecimal(12)) Sql代码 复制代码 代码如下: create table test(id int(11),charge BigDecimal(12)) 3.通过传参数方式导入数据库脚本 复制代码 代码如下: new
-
php导入csv文件碰到乱码问题的解决方法
今天主要是想写一个php导入csv文件的方法,其实网上一搜一大把.都是可以实现怎么去导入的.但是我导入的时候遇到了两个问题,一个是在windows上写代码的时候测试发生了乱码问题,然后解决了.第二个是提交到linux系统上的时候又发生了乱码.我开始还不清楚是乱码的原因,一开始我还以为是代码svn提交发生的错误,到最后我在我的一个群里提问了一下,一朋友是做phpcms的,他说他遇到从Windows提交到Linux的时候刚开始也总是发生错误,后来排查原因就是乱码导致成的.下面切入正题看怎么解决两个问
-
python导入csv文件出现SyntaxError问题分析
背景 np.loadtxt()用于从文本加载数据. 文本文件中的每一行必须含有相同的数据. *** loadtxt(fname,dtype=<class'float'>,comments='#',delimiter=None,converters=None,skiprows=0,usecols=None,unpack=False,ndmin=0) fname要读取的文件.文件名.或生成器. dtype数据类型,默认float. comments注释. delimiter分隔符,默认是空格. s
-
Python使用pandas导入csv文件内容的示例代码
目录 使用pandas导入csv文件内容 1. 默认导入 2. 指定分隔符 3. 指定读取行数 4. 指定编码格式 5. 列标题与数据对齐 使用pandas导入csv文件内容 1. 默认导入 在Python中导入.csv文件用的方法是read_csv(). 使用read_csv()进行导入时,指定文件名即可 import pandas as pd df = pd.read_csv(r'G:\test.csv') print(df) 2. 指定分隔符 read_csv()默认文件中的数据都是以逗号
-
C#实现导入CSV文件到Excel工作簿的方法
本文实例讲述了C#实现导入CSV文件到Excel工作簿的方法.分享给大家供大家参考.具体如下: 你必须在项目中添加对 Microsoft.Office.Core 的引用:from the .NET tab of the Visual Studio Add Reference dialog box, and the Microsoft Excel 12.0 Object Library (you can use 14.0 if you want, too, but nothing lower).
-
php中数据的批量导入(csv文件)
有时写程序时后台要求把大量数据导入数据库中,比如计算机考试成绩的查询.电话簿的数据等一般都是存放在excel中的,这时我们可把数据导出成csv文件,然后通过以下程序即可在后台批量导入数据到数据库中. 下面只是主要程序部分: <?php /***************************************************作者:冲星/arcow**************************njj@nuc.edu.cn*****************************
-
Navicat for MySql可视化导入CSV文件
本文为大家分享了Navicat for MySql可视化导入CSV文件的具体代码,供大家参考,具体内容如下 版本号:Navicate 12 1.创建一个数据库,右键单击表,导入向导import Wizard. 2.选择导入的数据文件格式,next-> 3.选择要导入的.csv文件,注意编码格式与文件编码格式一样否则会出现乱码,然后进行下一步 4.选择需要的分隔符,我用的Linux,所以record delimiter这个记录分隔符为LF,来表示下一行 5.根据你的csv文件内容来调整,field
-
java实现批量导入.csv文件到mysql数据库
这篇博文是在参加CCF时导入.csv文件时自己总结的,虽然NavicatForMysql可以导入.csv文件,可是当我导入的时候不知道是文件太大还是什么原因,总是会出现失败.然后就用java写了一个批量导入数据的类去导入该.csv文件,这里也没有考虑代码的结构,只是为了快速的完成这个工作,做一个总结. package com.cqu.price_prediction.farm; import java.io.File; import java.io.FileNotFoundException;
-
mysql实现查询结果导出csv文件及导入csv文件到数据库操作
本文实例讲述了mysql实现查询结果导出csv文件及导入csv文件到数据库操作.分享给大家供大家参考,具体如下: mysql 查询结果导出csv文件: select logtime, operatingsystem, imei from GameCenterLogs where operatingsystem >= 1 and operatingsystem <=3 group by operatingsystem,imei into outfile '/tmp_logs/tmp.csv' f
随机推荐
- angular框架实现全选与单选chekbox的自定义
- php验证手机号码(支持归属地查询及编码为UTF8)
- javascript 写类方式之六
- Node 自动化部署的方法
- chown与chmod的区别
- iOS中类似微信红点显示功能
- iOS10 适配-Xcode8问题总结及解决方案
- iOS App初次启动时的用户引导页制作实例分享
- 在一个网站下再以虚拟目录的方式挂多个网站的方法
- 浏览器复制插件zeroclipboard使用指南
- javascript 的变量、作用域和内存问题
- 整理的比较全的event对像在ie与firefox浏览器中的区别
- PHP单元测试利器 PHPUNIT深入用法(三)第1/2页
- 深入理解PHP之源码目录结构与功能说明
- PHP中把数据库查询结果输出为json格式简单实例
- myeclipse8.5优化技巧详解
- C语言实现在数组A上有序合并数组B的方法
- 实例详解Linxu中df命令
- winxp apache用php建本地虚拟主机的方法
- jQuery 剧场版 你必须知道的javascript