Python实现二叉排序树与平衡二叉树的示例代码
目录
- 前言
- 1. 二叉排序树
- 1.1 构建一棵二叉排序树
- 1.2 二叉排序树的数据结构
- 1.3 实现二叉排序树类中的方法:
- 2. 平衡二叉排序树
- 2.1 二叉平衡排序树的数据结构
- 3. 总结
前言
什么是树表查询?
借助具有特殊性质的树数据结构进行关键字查找。
本文所涉及到的特殊结构性质的树包括:
- 二叉排序树。
- 平衡二叉树。
使用上述树结构存储数据时,因其本身对结点之间的关系以及顺序有特殊要求,也得益于这种限制,在查询某一个结点时会带来性能上的优势和操作上的方便。
树表查询属于动态查找算法。
所谓动态查找,不仅仅能很方便查询到目标结点。而且可以根据需要添加、删除结点,而不影响树的整体结构,也不会影响数据的查询。
本文并不会深入讲解树数据结构的基本的概念,仅是站在使用的角度说清楚动态查询。阅读此文之前,请预备一些树的基础知识。
1. 二叉排序树
二叉树是树结构中具有艳明特点的子类。
二叉树要求树的每一个结点(除叶结点)的子结点最多只能有 2 个。在二叉树的基础上,继续对其进行有序限制则变成二叉排序树。
二叉排序树特点:
基于二叉树结构,从根结点开始,从上向下,每一个父结点的值大于左子结点(如果存在左子结点)的值,而小于右子结点(如果存在右子结点)的值。则把符合这种特征要求的树称为二叉排序树。
1.1 构建一棵二叉排序树
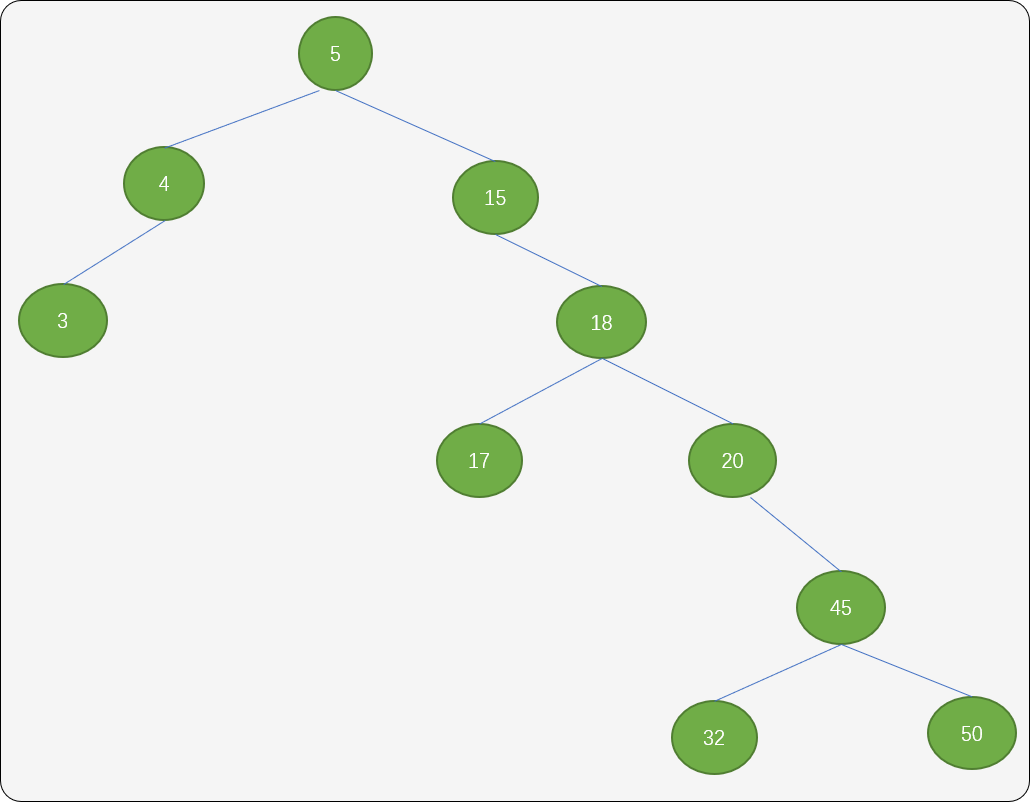
如有数列 nums=[5,12,4,45,32,8,10,50,32,3]。通过下面流程,把每一个数字映射到二叉排序树的结点上。
1.如果树为空,把第一个数字作为根结点。如下图,数字 5 作为根结点。

2.如果已经存在根结点,则把数字和根结点比较,小于根结点则作为根结点的左子结点,大于根结点的作为根结点的右子结点。如数字 4 插入到左边,数字 12 插入到右边。

3.数列中后面的数字依据相同法则,分别插入到不同子的位置。

原始数列中的数字是无序的,根据二叉排序树的插入算法,最终可得到一棵有排序性质的树结构。对此棵树进行中序遍历就可得到从小到大的一个递增有序数列。
综观二叉排序树,进行关键字查找时,也应该是接近于二分查找算法的时间度。
这里有一个要注意的地方。
原始数列中的数字顺序不一样时,生成的二叉排序树的结构也会有差异性。对于查找算法的性能会产生影响。
1.2 二叉排序树的数据结构
现在使用OOP设计方案描述二叉排序树的数据结构。
首先,设计一个结点类,用来描述结点本身的信息。
'''
二叉排序树的结点类
'''
class TreeNode():
def __init__(self, value):
# 结点上的值
self.value = value
# 左结点
self.l_child = None
# 右结点
self.r_child = None
结点类中有 3 个属性:
value:结点上附加的数据信息。l_child:左子结点,初始值为None。r_child:右子结点,初始值为None。
二叉排序树类: 用来实现树的增、删、改、查。
'''
二叉排序树类
'''
class BinarySortTree:
# 初始化树
def __init__(self, value=None):
pass
'''
在整棵树上查询是否存在给定的关键字
'''
def find(self, key):
pass
'''
使用递归进行查询
'''
def find_dg(self, root, key):
pass
'''
插入新结点
'''
def insert(self, value):
pass
'''
中序遍历
'''
def inorder_traversal(self):
pass
'''
删除结点
'''
def delete(self, key):
pass
'''
检查是不是空树
'''
def is_empty(self):
return self.root == None
二叉排序树中可以有更多方法,本文只关注与查找主题有关的方法。
1.3 实现二叉排序树类中的方法:
__init__ 初始化方法:
# 初始化树
def __init__(self, value=None):
self.root = None
if value is not None:
root_node = TreeNode(value)
self.root = root_node
在初始化树对象时,如果指定了数据信息,则创建有唯一结点的树,否则创建一个空树。
关键字查询方法:查询给定的关键字在二叉排序树结构中是否存在。
查询流程:
- 把给定的关键字和根结点相比较。如果相等,则返回查找成功,结束查询.
- 如果根结点的值大于关键字,则继续进入根结点的左子树中开始查找。
- 如果根结点的值小于关键字,则进入根结点的右子树中开始查找。
- 如果没有查询到关键字,则返回最后访问过的结点和查询不成功信息。
关键字查询的本质是二分思想,以当前结点为分界线,然后向左或向右进行分枝查找。
非递归实现查询方法:
'''
在整棵树上查询是否存在给定的关键字
key: 给定的关键字
'''
def find(self, key):
# 从根结点开始查找。
move_node = self.root
# 用来保存最后访问过的结点
last_node = None
while move_node is not None:
# 保存当前结点
last_node = move_node
# 把关键字和当前结点相比较
if self.root.value == key:
# 出口一:成功查找
return move_node
elif move_node.value > key:
# 在左结点查找
move_node = move_node.l_child
else:
# 在右结点中查找
move_node = move_node.r_child
# 出口二:如果没有查询到,则返回最后访问过的结点及None(None 表示没查询到)
return last_node, None
注意:当没有查询到时,返回的值有 2 个,最后访问的结点和没有查询到的信息。
为什么要返回最后一次访问过的结点?
反过来想想,本来应该在这个地方找到,但是没有,如果改成插入操作,就应该插入到此位置。
基于递归实现的查找:
'''
使用递归进行查询
'''
def find_dg(self, root, key):
# 结点不存在
if root is None:
return None
# 相等
if root.value == key:
return root
if root.value > key:
return self.find_dg(root.l_child, key)
else:
return self.find_dg(root.r_child, key)
再看看如何把数字插入到二叉排序树中,利用二叉排序树进行查找的前提条件就是要把数字映射到二叉排序树的结点上。
插入结点的流程:
- 当需要插入某一个结点时,先搜索是否已经存在于树结构中。
- 如果没有,则获取到查询时访问过的最一个结点,并和此结点比较大小。
- 如果比此结点大,则插入最后访问过结点的右子树位置。
- 如果比此结点小,则插入最后访问过结点的左子树位置。
insert 方法的实现:
'''
插入新结点
'''
def insert(self, value):
# 查询是否存在此结点
res = self.find(value)
if type(res) != TreeNode:
# 没找到,获取查询时最后访问过的结点
last_node = res[0]
# 创建新结点
new_node = TreeNode(value)
# 最后访问的结点是根结点
if last_node is None:
self.root = new_node
if value > last_node.value:
last_node.r_child = new_node
else:
last_node.l_child = new_node
怎么检查插入的结点是符合二叉树特征?
再看一下前面根据插入原则手工绘制的插入演示图:

上图有 4 个子结点,写几行代码测试一下,看从根结点到叶子结点的顺序是否正确。
测试插入方法:
if __name__ == "__main__":
nums = [5, 12, 4, 45, 32, 8, 10, 50, 32, 3]
tree = BinarySortTree(5)
for i in range(1, len(nums)):
tree.insert(nums[i])
print("测试根5 -> 左4 ->左3:")
tmp_node = tree.root
while tmp_node != None:
print(tmp_node.value, end=" ->")
tmp_node = tmp_node.l_child
print("\n测试根5 -> 右12 ->右45->右50:")
tmp_node = tree.root
while tmp_node != None:
print(tmp_node.value, end=" ->")
tmp_node = tmp_node.r_child
'''
输出结果:
测试根5 -> 左4 ->左3:
5 ->4 ->3 ->
测试根5 -> 右12 ->右45->右50:
5 ->12 ->45 ->50 ->
'''
查看结果,可以初步判断插入的数据是符合二叉排序树特征的。当然,更科学的方式是写一个遍历方法。树的遍历方式有 3 种:
- 前序:根,左,右。
- 中序:左,根,右。
- 后序。左,右,根。
对二叉排序树进行中序遍历,理论上输出的数字应该是有序的。这里写一个中序遍历,查看输出的结点是不是有序的,从而验证查询和插入方法的正确性。
使用递归实现中序遍历:
'''
中序遍历
'''
def inorder_traversal(self, root):
if root is None:
return
self.inorder_traversal(root.l_child)
print(root.value,end="->")
self.inorder_traversal(root.r_child)
测试插入的顺序:
if __name__ == "__main__":
nums = [5, 12, 4, 45, 32, 8, 10, 50, 32, 3]
tree = BinarySortTree(5)
# res = tree.find(51)
for i in range(1, len(nums)):
tree.insert(nums[i])
tree.inorder_traversal(tree.root)
'''
输出结果
3->4->5->8->10->12->32->45->50->
'''
二叉排序树很有特色的数据结构,利用其存储特性,可以很方便地进行查找、排序。并且随时可添加、删除结点,而不会影响排序和查找操作。基于树表的查询操作称为动态查找。
二叉排序树中如何删除结点
从二叉树中删除结点,需要保证整棵二叉排序树的有序性依然存在。删除操作比插入操作要复杂,下面分别讨论。
- 如果要删除的结点是叶子结点。
只需要把要删除结点的父结点的左结点或右结点的引用值设置为空就可以了。
- 删除的结点只有一个右子结点。如下图删除结点
8。

因为结点8没有左子树,在删除之后,只需要把它的右子结点替换删除结点就可以了。

删除的结点即存在左子结点,如下图删除值为 25 的结点。

一种方案是:找到结点 25 的左子树中的最大值,即结点 20(该结点的特点是可能会存在左子结点,但一定不会有右子结点)。用此结点替换结点25 便可。
为什么要这么做?
道理很简单,既然是左子树中的最大值,替换删除结点后,整个二叉排序树的特性可以继续保持。

如果结点 20 存在左子结点,则把它的左子结点作为结点18的右子结点。
另一种方案:同样找到结点25中左子树中的最大值结点 20,然后把结点 25 的右子树作为结点 20 的右子树。

再把结点 25 的左子树移到 25 位置。
这种方案会让树增加树的深度。所以,建议使用第一种方案。
删除方法的实现:
'''
删除结点
key 为要要删除的结点
'''
def delete(self, key):
# 从根结点开始查找,move_node 为搜索指针
move_node = self.root
# 要删除的结点的父结点,因为根结点没有父结点,初始值为 None
parent_node = None
# 结点存在且没有匹配上要找的关键字
while move_node is not None and move_node.value != key:
# 保证当前结点
parent_node = move_node
if move_node.value > key:
# 在左子树中继续查找
move_node = move_node.l_child
else:
# 在右子树中继续查找
move_node = move_node.r_child
# 如果不存在
if move_node is None:
return -1
# 检查要删除的结点是否存在左子结点
if move_node.l_child is None:
if parent_node is None:
# 如果要删除的结点是根结点
self.root = move_node.r_child
elif parent_node.l_child == move_node:
# 删除结点的右结点作为父结点的左结点
parent_node.l_child = move_node.r_child
elif parent_node.r_child == move_node:
parent_node.r_child = move_node.r_child
return 1
else:
# 如果删除的结点存在左子结点,则在左子树中查找最大值
s = move_node.l_child
q = move_node
while s.r_child is not None:
q = s
s = s.r_child
if q == move_node:
move_node.l_child = s.l_child
else:
q.r_child = s.l_child
move_node.value = s.value
q.r_child = None
return 1
测试删除后的二叉树是否依然维持其有序性。
if __name__ == "__main__":
nums = [5, 12, 4, 45, 32, 8, 10, 50, 32, 3]
tree = BinarySortTree(5)
# res = tree.find(51)
for i in range(1, len(nums)):
tree.insert(nums[i])
tree.delete(12)
tree.inorder_traversal(tree.root)
'''
输出结果
3->4->5->8->10->32->45->50->
'''
无论删除哪一个结点,其二叉排序树的中序遍历结果都是有序的,很好地印证了删除算法的正确性。
2. 平衡二叉排序树
二叉排序树中进行查找时,其时间复杂度理论上接近二分算法的时间复杂度,其查找时间与树的深度有关。但是,这里有一个问题,前面讨论过,如果数列中的数字顺序不一样时,所构建出来的二叉排序树的深度会有差异性,对最后评估时间性能也会有影响。
如有数列 [36,45,67,28,20,40]构建的二叉排序树如下图:

基于上面的树结构,查询任何一个结点的次数不会超过 3 次。
稍调整一下数列中数字的顺序 [20,28,36,40,45,67],由此构建出来的树结构会出现一边倒的现象,也增加了树的深度。

此棵树的深度为6,最多查询次数是 6 次。在二叉排序树中,减少查找次数的最好办法,就是尽可能维护树左右子树之间的对称性,也就让其有平衡性。
所谓平衡二叉排序树,顾名思义,基于二叉排序树的基础之上,维护任一结点的左子树和右子树之间的深度之差不超过 1。把二叉树上任一结点的左子树深度减去右子树深度的值称为该结点的平衡因子。
平衡因子只可能是:
0:左、右子树深度一样。1:左子树深度大于右子树。-1:左子树深度小于右子树。
如下图,就是平衡二叉排序树,根结点的 2 个子树深度相差为 0, 结点 28 的左、右子树深度为 1,结点 45 的左右子树深度相差为 0。

平衡二叉排序树相比较于二叉排序树,其 API 多了保持平衡的算法。
2.1 二叉平衡排序树的数据结构
结点类:
'''
结点类
'''
class TreeNode:
def __init__(self,value):
self.value=value
self.l_child=None
self.r_child=None
self.balance=0
结点类中有 4 个属性:
value:结点上附加的值。l_child:左子结点。r_child:右子结点。balance:平衡因子,默认平衡因子为0。
二叉平衡排序树类:
'''
树类
'''
class Tree:
def __init__(self, value):
self.root = None
'''
LL型调整
'''
def ll_rotate(self, node):
pass
'''
RR 型调整
'''
def rr_rotate(self, node):
pass
'''
LR型调整
'''
def lr_rotate(self, node):
pass
'''
RL型调整
'''
def rl_rotate(self, node):
pass
'''
插入新结点
'''
def insert(self, value):
pass
'''
中序遍历
'''
def inorder_traversal(self, root):
pass
def is_empty(self):
pass
在插入或删除结点时,如果导致树结构发生了不平衡性,则需要调整让其达到平衡。这里的方案可以有 4种。
LL型调整(顺时针):左边不平衡时,向右边旋转。

如上图,现在根结点 36 的平衡因子为 1。如果现插入值为 18 结点,显然要作为结点 20 的左子结点,才符合二叉排序树的有序性。但是破坏了根结点的平衡性。根结点的左子树深度变成 3,右子树深度为1,平衡被打破,结点 36 的平衡因子变成了2。

这里可以使用顺时针旋转方式,让其继续保持平衡,旋转流程:
- 让结点
28成为新根结点,结点36成为结点28的左子结点。 - 结点
29成为结点36的新左子结点。

旋转后,树结构即满足了有序性,也满足了平衡性。
LL 旋转算法具体实现:
'''
LL型调整
顺时针对调整
'''
def ll_rotate(self, p_root):
# 原父结点的左子结点成为新父结点
new_p_root = p_root.l_child
# 新父结点的右子结点成为原父结点的左子结点
p_root.l_child = new_p_root.r_child
# 原父结点成为新父结点的右子结点
new_p_root.r_child = p_root
# 重置平衡因子
p_root.balance = 0
new_p_root.balance = 0
return new_p_root
RR 型调整(逆时针旋转):RR旋转和 LL旋转的算法差不多,只是当右边不平衡时,向左边旋转。
如下图所示,结点 50 插入后,树的平衡性被打破。

这里使用左旋转(逆时针)方案。结点 36 成为结点 45 的左子结点,结点45 原来的左子结点成为结点36的右子结点。
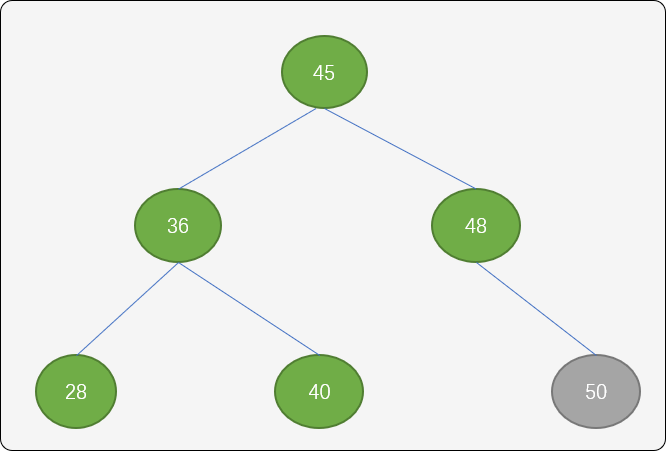
向逆时针旋转后,结点45的平衡因子为 0,结点36的平衡因子为0,结点 48 的平衡因子为 -1。树的有序性和平衡性得到保持。
RR 旋转算法具体实现:
'''
RR 型调整
'''
def rr_rotate(self, node):
# 右子结点
new_p_node = p_node.r_child
p_node.r_child = new_p_node.l_child
new_p_node.l_child = p_node
# 重置平衡因子
p_node.balance = 0
new_p_node.balance = 0
return new_p_node
LR型调整(先逆后顺):如下图当插入结点 28 后,结点 36 的平衡因子变成 2,则可以使用 LR 旋转算法。

以结点 29 作为新的根结点,结点27以结点29为旋转中心,逆时针旋转。

结点36以结点29为旋转中心向顺时针旋转。

最后得到的树还是一棵二叉平衡排序树。
LR 旋转算法实现:
'''
LR型调整
'''
def lr_rotate(self, p_node):
# 左子结点
b = p_node.l_child
new_p_node = b.r_child
p_node.l_child = new_p_node.r_child
b.r_child = new_p_node.l_child
new_p_node.l_child = b
new_p_node.r_child = p_node
if new_p_node.balance == 1:
p_node.balance = -1
b.balance = 0
elif new_p_node.balance == -1:
p_node.balance = 0
b.balance = 1
else:
p_node.balance = 0
b.balance = 0
new_p_node.balance = 0
return new_p_node
RL型调整: 如下图插入结点39 后,整棵树的平衡打破,这时可以使用 RL 旋转算法进行调整。

把结点40设置为新的根结点,结点45以结点 40 为中心点顺时针旋转,结点36逆时针旋转。
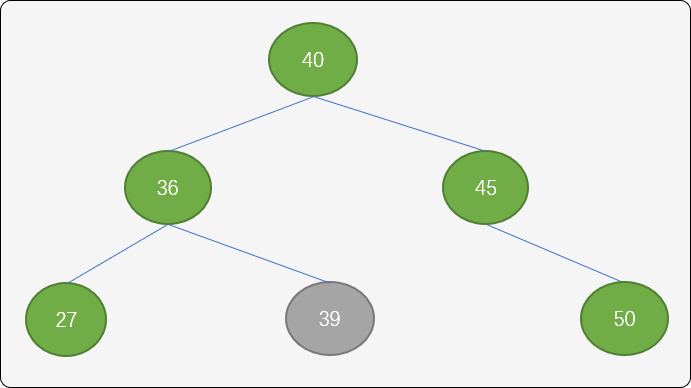
RL 算法具体实现:
'''
RL型调整
'''
def rl_rotate(self, p_node):
b = p_node.r_child
new_p_node = b.l_child
p_node.r_child = new_p_node.l_child
b.l_child = new_p_node.r_child
new_p_node.l_child = p_node
new_p_node.r_child = b
if new_p_node.balance == 1:
p_node.balance = 0
b.balance = -1
elif new_p_node.balance == -1:
p_node.balance = 1
b.balance = 0
else:
p_node.balance = 0
b.balance = 0
new_p_node.balance = 0
return new_p_node
编写完上述算法后,就可以编写插入算法。在插入新结点时,检查是否破坏二叉平衡排序树的的平衡性,否则调用平衡算法。
当插入一个结点后,为了保持平衡,需要找到最小不平衡子树。
什么是最小不平衡子树?
指离插入结点最近,且平衡因子绝对值大于 1 的结点为根结点构成的子树。
'''
插入新结点
'''
def insert(self, val):
# 新的结点
new_node = TreeNode(val)
if self.root is None:
# 空树
self.root = new_node
return
# 记录离 s 最近的平衡因子不为 0 的结点。
min_b = self.root
# f 指向 a 的父结点
f_node = None
move_node = self.root
f_move_node = None
while move_node is not None:
if move_node.value == new_node.value:
# 结点已经存在
return
if move_node.balance != 0:
# 寻找最小不平衡子树
min_b = move_node
f_node = f_move_node
f_move_node = move_node
if new_node.value < move_node.value:
move_node = move_node.l_child
else:
move_node = move_node.r_child
if new_node.value < f_move_node.value:
f_move_node.l_child = new_node
else:
f_move_node.r_child = new_node
move_node = min_b
# 修改相关结点的平衡因子
while move_node != new_node:
if new_node.value < move_node.value:
move_node.balance += 1
move_node = move_node.l_child
else:
move_node.balance -= 1
move_node = move_node.r_child
if min_b.balance > -2 and min_b.balance < 2:
# 插入结点后没有破坏平衡性
return
if min_b.balance == 2:
b = min_b.l_child
if b.balance == 1:
move_node = self.ll_rotate(min_b)
else:
move_node = self.lr_rotate(min_b)
else:
b = min_b.r_child
if b.balance == 1:
move_node = self.rl_rotate(min_b)
else:
move_node = self.rr_rotate(min_b)
if f_node is None:
self.root = move_node
elif f_node.l_child == min_b:
f_node.l_child = move_node
else:
f_node.r_child = move_node
中序遍历: 此方法为了验证树结构还是排序的。
'''
中序遍历
'''
def inorder_traversal(self, root):
if root is None:
return
self.inorder_traversal(root.l_child)
print(root.value, end="->")
self.inorder_traversal(root.r_child)
二叉平衡排序树本质还是二树排序树。如果使用中序遍历输出的数字是有序的。测试代码。
if __name__ == "__main__":
nums = [3, 12, 8, 10, 9, 1, 7]
tree = Tree(3)
for i in range(1, len(nums)):
tree.inster(nums[i])
# 中序遍历
tree.inorder_traversal(tree.root)
'''
输出结果
1->3->7->8->9->10->12->
'''
3. 总结
利用二叉排序树的特性,可以实现动态查找。在添加、删除结点之后,理论上查找到某一个结点的时间复杂度与树的结点在树中的深度是相同的。
但是,在构建二叉排序树时,因原始数列中数字顺序的不同,则会影响二叉排序树的深度。
这里引用二叉平衡排序树,用来保持树的整体结构是平衡,方能保证查询的时间复杂度为 Ologn(n 为结点的数量)。
到此这篇关于Python实现二叉排序树与平衡二叉树的示例代码的文章就介绍到这了,更多相关Python二叉树内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

如何在Python中创建二叉树
前言 本文的内容是数据结构中二叉树部分最基础的,之所以写一下主要是为了方便刷题的时候,能够在自己电脑上很快的使用这种小的demo进行复杂的练习. 二叉树节点定义 二叉树的节点定义如下: class TreeNode():#二叉树节点 def __init__(self,val,lchild=None,rchild=None): self.val=val #二叉树的节点值 self.lchild=lchild #左孩子 self.rchild=rchild #右孩子 递归构建二叉树 本文使用的前序
-
python实现二叉排序树
目录 方法一(粗暴) 方法二(递归) 方法一(粗暴) #二叉排序树 class BTree(): def __init__(self,data): self.left = None self.right = None if type(data) == list: self.data = data[0] for d in data[1:]: self.insert
-
二叉树的概念案例详解
二叉树简介 关于树的介绍,请参考:https://blog.csdn.net/weixin_43790276/article/details/104033482 一.二叉树简介 二叉树是每个节点最多有两个子树的树结构,是一种特殊的树,如下图,就是一棵二叉树. 二叉树是由n(n>=0)个节点组成的数据集合.当 n=0 时,二叉树中没有节点,称为空二叉树.当 n=1 时,二叉树只有根节点一个节点.当 n>1 时,二叉树的每个节点都最多只能有两个子树,递归地构建成一棵完整的二叉树. 二叉树的两个子树
-
用Python实现二叉树、二叉树非递归遍历及绘制的例子
前言 关于二叉树的实现与遍历,网上已经有很多文章了,包括C, C++以及JAVA等.鉴于python做为脚本语言的简洁性,这里写一篇小文章用python实现二叉树,帮助一些对数据结构不太熟悉的人快速了解下二叉树.本文主要通过python以非递归形式实现二叉树构造.前序遍历,中序遍历,后序遍历,层次遍历以及求二叉树的深度及叶子结点数.其他非递归形式的遍历,想必大多人应该都很清楚,就不再声明.如果你用C或者C++或者其他高级语言写过二叉树或者阅读过相关方面代码,应该知道二叉树的非递归遍历避不开通过栈
-
python 平衡二叉树实现代码示例
平衡二叉树: 在上一节二叉树的基础上我们实现,如何将生成平衡的二叉树 所谓平衡二叉树: 我自己定义就是:任何一个节点的左高度和右高度的差的绝对值都小于2 如图所示,此时a的左高度等于3,有高度等于1,差值为2,属于不平衡中的左偏 此时的处理办法就是: 将不平衡的元素的左枝的最右节点变为当前节点, 此时分两种情况: 一.左枝有最右节点 将最右节点的左枝赋予其父节点的右枝 二.左枝没有最右节点, 直接将左枝节点做父级节点,父级节点做其右枝 如图所示,图更清楚些. 可能会有疑问,为什么这样变换? 假定
-
Python实现二叉排序树与平衡二叉树的示例代码
目录 前言 1. 二叉排序树 1.1 构建一棵二叉排序树 1.2 二叉排序树的数据结构 1.3 实现二叉排序树类中的方法: 2. 平衡二叉排序树 2.1 二叉平衡排序树的数据结构 3. 总结 前言 什么是树表查询? 借助具有特殊性质的树数据结构进行关键字查找. 本文所涉及到的特殊结构性质的树包括: 二叉排序树. 平衡二叉树. 使用上述树结构存储数据时,因其本身对结点之间的关系以及顺序有特殊要求,也得益于这种限制,在查询某一个结点时会带来性能上的优势和操作上的方便. 树表查询属于动态查找算法. 所
-
Go/Python/Erlang编程语言对比分析及示例代码
本文主要是介绍Go,从语言对比分析的角度切入.之所以选择与Python.Erlang对比,是因为做为高级语言,它们语言特性上有较大的相似性,不过最主要的原因是这几个我比较熟悉. Go的很多语言特性借鉴与它的三个祖先:C,Pascal和CSP.Go的语法.数据类型.控制流等继承于C,Go的包.面对对象等思想来源于Pascal分支,而Go最大的语言特色,基于管道通信的协程并发模型,则借鉴于CSP分支. Go/Python/Erlang语言特性对比 如<编程语言与范式>一文所说,不管语言如何层出不穷
-
python tkinter实现界面切换的示例代码
跳转实现思路 主程序相当于桌子: import tkinter as tk root = tk.Tk() 而不同的Frame相当于不同的桌布: face1 = tk.Frame(root) face2 = tk.Frame(root) ... 每个界面采用类的方式定义各自的控件和函数,每个界面都建立在一个各自定义的Frame上,那么在实现跳转界面的效果时, 只需要调用tkinter.destroy()方法销毁旧界面,同时生成新界面的对象,即可实现切换. 而对于切换的过程中改变背景颜色和大小,可以
-
python实现网站微信登录的示例代码
最近微信登录开放公测,为了方便微信用户使用,我们的产品也决定加上微信登录功能,然后就有了这篇笔记. 根据需求选择相应的登录方式 python实现网站微信登录的示例代码 微信现在提供两种登录接入方式 移动应用微信登录 网站应用微信登录 这里我们使用的是网站应用微信登录 按照 官方流程 1 注册并通过开放平台开发者资质认证 注册微信开放平台帐号后,在帐号中心中填写开发者资质认证申请,并等待认证通过. 2 创建网站应用 通过填写网站应用名称.简介和图标,以及各平台下载地址等资料,创建网站应用 3 接入
-
使用python画个小猪佩奇的示例代码
基本原理 选好画板大小,设置好画笔颜色.粗细,定位好位置,依次画鼻子.头.耳朵.眼睛.腮.嘴.身体.手脚.尾巴,完事儿. 都知道,Turtle 是 Python 内置的一个比较有趣味的模块,俗称"海龟绘图",它是基于 Tkinter 模块打造,提供一些简单的绘图工具. 在海龟作图中,我们可以编写指令让一个虚拟的(想象中的)海龟在屏幕上来回移动.这个海龟带着一只钢笔,我们可以让海龟无论移动到哪都使用这只钢笔来绘制线条.通过编写代码,以各种很酷的模式移动海龟,我们可以绘制出令人惊奇的图片.
-
python绘制BA无标度网络示例代码
如下所示: #Copyright (c)2017, 东北大学软件学院学生 # All rightsreserved #文件名称:a.py # 作 者:孔云 #问题描述: #问题分析:.代码如下: import networkx as ne #导入建网络模型包,命名ne import matplotlib.pyplot as mp #导入科学绘图包,命名mp #BA scale-free degree network graphy BA=ne.barabasi_albert_graph(50,1)
-
python 实现人和电脑猜拳的示例代码
完成人机猜拳互动游戏的开发,用户通过控制台输入实现出拳,电脑通过程序中的随机数实现出拳,每一局结束后都要输出结果.当用户输入n时停止游戏,并输出总结果. import random all = ['石头','剪刀','布'] computer = random.choice(['石头','剪刀','布']) #所有赢了的情况 win = [['石头','剪刀'],['布','石头'],['剪刀','布']] class Text(): def func_play(self): ind = inp
-
Python操作Excel工作簿的示例代码(\*.xlsx)
前言 Excel 作为流行的个人计算机数据处理软件,混迹于各个领域,在程序员这里也是常常被处理的对象,可以处理 Excel 格式文件的 Python 库还是挺多的,比如 xlrd.xlwt.xlutils.openpyxl.xlwings 等等,但是每个库处理 Excel 的方式不同,有些库在处理时还会有一些局限性. 接下来对比一下几个库的不同,然后主要记录一下 xlwings 这个库的使用,目前这是个人感觉使用起来比较方便的一个库了,其他的几个库在使用过程中总是有这样或那样的问题,不过在特定情
-
Python实现多线程下载脚本的示例代码
0x01 分析 一个简单的多线程下载资源的Python脚本,主要实现部分包含两个类: Download类:包含download()和get_complete_rate()两种方法. download()方法种首先用 urlopen() 方法打开远程资源并通过 Content-Length获取资源的大小,然后计算每个线程应该下载网络资源的大小及对应部分吗,最后依次创建并启动多个线程来下载网络资源的指定部分. get_complete_rate()则是用来返回已下载的部分占全部资源大小的比例,用来回
-
Python 实现敏感目录扫描的示例代码
01 实现背景 1.PHPdict.txt,一个文本文件,包含可能的敏感目录后缀 2.HackRequests模块,安全测试人员专用的类Requests模块 02 实现目标 利用HackRequests模块,配合敏感目录字典PHPdict.txt,实现一个简单的敏感目录扫描Python文件 03 注意事项 1.输入URL时要输全:如 https://www.baidu.com/. https://www.csdn.net/ 2.为防止网站可能存在的简单反爬机制,我们简单添加headers信息,尝