C语言植物大战数据结构快速排序图文示例
目录
- 快速排序
- 一、经典1962年Hoare法
- 1.单趟排序
- 2.递归左半区间和右半区间
- 3.代码实现
- 二、填坑法(了解)
- 1.单趟思路
- 2.代码实现
- 三、双指针法(最佳方法)
- 1.单趟排序
- 2.具体思路
- 3.代码递归图
- 4.代码实现
- 四、三数取中优化(最终方案)
- 1.三数取中
- 2.代码实现(最终代码)
- 五、时间复杂度(重点)
- 1.最好情况下
- 2.最坏情况下
- 3.空间复杂度
- 六、非递归写法
- 1.栈模拟递归快排
- 2.队列实现快排
- 浅浅总结下
“田家少闲月,五月人倍忙”“夜来南风起,小麦覆陇黄”
C语言朱武大战数据结构专栏
C语言植物大战数据结构希尔排序算法
C语言植物大战数据结构堆排序图文示例
C语言植物大战数据结构二叉树递归
快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法。所以快速排序有种方法是以他的名字命名的。相比70年前的祖师爷级的 大佬 来说,今天我们学习快速排序的成本已经非常低了。今天的我们的是站在巨人的肩膀上学习快速排序。
快速排序有三种方法实现,我们 都 需要掌握。
一、经典1962年Hoare法
让我们来看看1962年祖师爷发明的快排吧。
什么是快速排序?给你以下代码,请你完善快速排序,你将怎么完善?
快速排序:顾名思义,它比较快,整体而言适合各种场景下的排序。缺陷相较于其他排序小。且大部分 程序语言 排序的库函数 的 源代码都是由快速排序实现的
void QuickSort(int* a, int left, int right)
{
//请你完善以下代码
}
int main()
{
int arr[] = {6,1,2,7,9,3,4,5,10,8};
int sz = sizeof(arr) / sizeof(arr[0]);
QuickSort(arr, 0, sz-1);
return 0;
}
具体实现:
Hoare法和二叉树的**前序遍历(根 左子树 右子树)**简直一模一样。
整体思路:
1.先进行一趟排序。
2.进行左半区间(左子树)递归。
3.进行右半区间(右子树)递归。
1.单趟排序
所有的排序的思想:就是先考虑单趟的排序,再合成n躺排序。这是毋庸置疑的,因为这样的思想很自然。
对于单趟排序,也有一个思路。可以说算是规定吧,这是祖师爷Hoare的规定。
为了好理解思路,以下思路是整体上的思路,写出来的程序还是有bug的。具体细节需要后期修改。

一定要按照规定走哦,不要问那么多为什么。按照规定走你就知道为什么要这么做了。总体思路规定:
1.设置一个基准值key,key一般为左边第一个数的下标。定义左指针left和有指针right分别指向第一个和最后一个。
2.先让右边的right指针往左走,一直找比key所指向小的数,找到后就停下。
3.紧接着让left指针往右走,一直找比key所指向大的数,找到后就停下。
4.如果第2步的right和第3步left都找到了,则交换swap两者的值。然后继续循环2和3步,直到left >= right为止。
5.此时left = right, 交换left和right相遇的位置的值 与 key位置上的值。



此时,Hoare 的单趟排序完成。产生的效果是key作为分割线,把大小分割开了,比key所指向值小的在key左边,比key所指向值大的在key右边。
2.递归左半区间和右半区间
对于单趟来说。
单趟排完之后,key已经放在正确的位置了。
如果左边有序,右边有序,那么我们整体就有序了。
那左边和右边如何有序呢?
解释:分治解决子问题。相当于二叉树。
一趟排序完成后,再对左半区间进行单趟排序,一直递归到什么时候结束呢?
解释:递归到左半区间只有一个值的时候,或者为空的时候递归结束。
这个过程适合用 画递归图 来查看。
由于数据是10个数,递归图庞大。所以此处省略。下面双指针法有具体递归图。
3.代码实现
具体代码实现和你想的总是那么不同。因为特殊情况确实是存在,且还是那么离谱。
我认为这个题难在了边界问题,边界问题要时刻注意!。
特殊情况1:当排以下数据时,我只是把6改了,这样会导致right和left直接不走了。
{6,1,2,7,9,3,4,5,10,6}
特殊情况2:当排以下数据时,会发生left找不到最大的值导致越界。
{5,4,3,2,1}
改动如下。
//快速排序Hoare
int PartSort(int* a, int left,int right)
{
int key = left;
while (left < right)
{
while (left < right && a[right] >= a[key])
{
--right;
}
while (left < right && a[left] <= a[key])
{
++left;
}
swap(&a[left], &a[right]);
}
swap(&a[left], &a[key]);
return left;
}
void QuickSort(int* a, int left, int right)
{
//当有个区间为空的时候right-left会小于0。
if (right <= left)
return;
int div = PartSort(a, left, right);
QuickSort(a, left, div-1);
QuickSort(a, div+1, right);
}
int main()
{
int arr[] = {6,1,2,7,9,3,4,5,10,8};
int sz = sizeof(arr) / sizeof(arr[0]);
QuickSort(arr, 0, sz-1);
return 0;
}
二、填坑法(了解)
和Hoare法思想类似,大差不差,没什么区别。相比Hoare法较好理解。因为挖坑填坑思想很生动形象,所以较好理解。
1.单趟思路
单趟思路:
1.先保存key的值。让左边的key做坑(pit),让右边找比key小的,然后填到坑中。
2.然后让那个小的做坑,再让左边找比key大的,找到后填到坑中。依次循环,直到right和left相遇。
3.相遇后,把key的值填到相遇的位置。
这时,单趟循环结束。

2.代码实现
和Hoare法相似,只是少了交换的步骤。注意:要事先把key的值保存下来。
int PartSort(int* a, int left, int right)
{
int keyval = a[left];
int pit = left;
while (left < right)
{
while (left < right && a[right] >= keyval)
{
right--;
}
a[pit] = a[right];
pit = right;
while (left < right && a[left] <= keyval)
{
left++;
}
a[pit] = a[left];
pit = left;
}
a[pit] = keyval;
return left;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int div = PartSort(a, left, right);
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}
int main()
{
int arr[] = { 6,1,2,7,9,3,4,5,10,8 };
int sz = sizeof(arr) / sizeof(arr[0]);
QuickSort(arr, 0, sz-1);
return 0;
}
三、双指针法(最佳方法)
1.单趟排序
和以上两种方法的不同之处只有单趟排序,也就是PartSort函数的部分.
优点:有了双指针的优化,不需要考虑 边界问题!写代码不易出错。
代码好写,不好理解。代码极为简单,只需五行。
双指针法也称快慢指针法,两个指针一前一后
2.具体思路
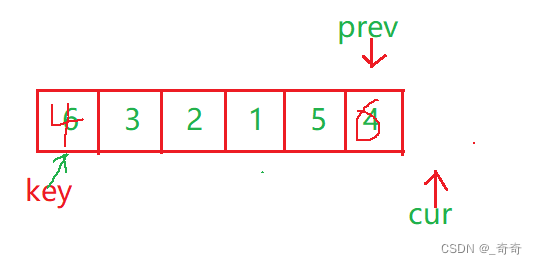
对于排6,3,2,1,5,4的升序来说。
思路:让cur找比key指向的值小的,找到后,++prev,交换prev和cur位置的值。若cur比key指向的值大,则不交换。
prev和cur的关系:
1.cur还没遇到比key大的值时,prev紧跟着cur,一前一后。
2.cur遇到比key大的,prev和cur之间的一段都是最大的值

第一趟排序后的结果。这时候div为基准值。将左右子树分隔开。
全部排完序后的二叉树图。
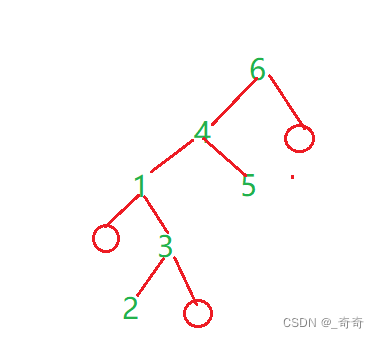
3.代码递归图
红色线代表递归,绿色线代表返回。

4.代码实现
#include <stdio.h>
void Swap(int* x, int* y)
{
int t = 0;
t = *x;
*x = *y;
*y = t;
}
int PartSort(int* a, int left, int right)
{
int key = left;
int prev = left;
int cur = left + 1;
//推荐写法一,较好理解
while (cur <= right)
{
if (a[cur] < a[key])
{
++prev;
Swap(&a[cur], &a[prev]);
}
++cur;
}
//写法二。比较妙,不好理解
//while (cur <= right)
//{
// if (a[cur] < a[key] && a[++prev] != a[cur])
// {
// Swap(&a[cur], &a[prev]);
// }
// ++cur;
//}
Swap(&a[prev], &a[key]);
return prev;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int div = PartSort(a, left, right);
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}
int main()
{
int arr[] = {6,3,2,1,5,4};
int sz = sizeof(arr) / sizeof(arr[0]);
QuickSort(arr, 0, sz-1);
return 0;
}
到这里快速排序还没有完,因为它存在缺陷。还需继续优化。请往下看
四、三数取中优化(最终方案)
以上三种方法的时间复杂度
最好情况:是O(N*Log2N)。
最坏情况:也就是在数据有序的情况下,就退化为了冒泡排序 O(N2)
当给你一组上万个数据测试时,会发生超时现象。
例如LeetCode912. 排序数组
快排竟然超时了,这时候用三数取中来解决此问题。
1.三数取中
三数取中的含义:取三个数中间不是最大也不是最小的那个。哪三个数?第一个,最后一个,和中间那个。例如排以下数据时。
9 8 7 6 5 4 3 2 1 0
思路:
默认key选最左边的数。
1.三个数取第一个 9 和第二个 1 和中间的 5
2.选出不是最大也不是最小的那个,也就是5。
3.将5和key交换位置。也就是和最左边的数交换。
这样做可以打破单边树形状,可以使之变为二分。因为这时候5做了key,key的左边是比5小的,
key的右边是比key大的。
二分后的时间复杂度还是N*LogN
注意:三数取中仍然无法完全解决
在某种特殊情况序列下时间复杂度变为O(n2)的情况
2.代码实现(最终代码)
int GetMidIndex(int* a, int left, int right)
{
//防溢出写法
//int mid = left + (right - left) / 2;
int mid = (left + right) / 2;
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] < a[right])
{
return right;
}
else
{
return left;
}
}
else
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[right] > a[left])
{
return left;
}
else
{
return right;
}
}
}
int PartSort(int* a, int left, int right)
{
int midi = GetMidIndex(a, left, right);
Swap(&a[midi], &a[left]);
int key = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
if (a[cur] < a[key])
{
++prev;
Swap(&a[cur], &a[prev]);
}
++cur;
}
Swap(&a[prev], &a[key]);
return prev;
}
void QuickSort(int* a, int left, int right)
{
if (right <= left)
return;
int div = PartSort(a, left, right);
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}
int main()
{
int arr[] = { 6,1,2,7,9,3,4,5,10,8 };
int sz = sizeof(arr) / sizeof(arr[0]);
QuickSort(arr, 0, sz-1);
return 0;
}
五、时间复杂度(重点)
结论大家都会,是N*LogN。怎么算出来的呢?
1.最好情况下
在最好的情况下:每次选key刚好能平分这组数据,一直都是二分,构成了满二叉树。
1.对于单趟排序的一层递归,不管是哪种方法,left和right每次都遍历了一遍数组,时间复杂度为N。
2.因为满二叉树的高度为Log2N,所以递归深度(深度不等于次数)也为Log2N,所以递归Log2N层就是(N *Log2N).
3.综上所述,快排最好情况下时间复杂度为O(N * LogN).
2.最坏情况下
最坏情况下,每次选key都是最大或者最小的那个元素,这使得每次划分所得的子表中一个为空表,另一个表的长度为原表的长度-1.
这样,长度为n的数据表的快速排序需要经过n趟划分,使得整个排序算法退化为冒泡排序,时间复杂度为N2
如图是给9 8 7 6 5 4 3 2 1排升序的例子。
每次选最左边的为key。

3.空间复杂度
在空间上来看,尽管快排只需要一个元素的辅助空间。
但是快排需要一个栈空间来实现递归
最好情况下:每一次都被均匀的分割为深度相近的两个子表,所需要栈的最大深度为Log2N。空间复杂度为O(Log2N)
最坏情况下:但最坏的情况下,栈的最大深度为n.这样快速排序的空间复杂度为O(N).这时就会导致栈溢出(Stack Overflow)。因为栈的空间很小。
这时候就需要非递归的算法,来解决栈溢出问题。
六、非递归写法
1.栈模拟递归快排
如图对以下数据排序
{ 6,1,2,7,9,3,4,5,10,8 }

void QuickSort(int* a, int begin, int end)
{
ST st;
StackInit(&st);
//先入0和9这段区间
StackPush(&st, begin);
StackPush(&st, end);
while (!StackEmpty(&st))
{
//接着出栈,9和0,注意后进先出
int end = StackTop(&st);
StackPop(&st);
int begin = StackTop(&st);
StackPop(&st);
//然后再进行对0和9这段区间单趟排序。
int keyi = PartSort(a, begin, end);
//[begin , keyi - 1] [keyi+1,end]
//最后判断区间是否为最小规模子问题,来判断是否需要继续入栈。
if (begin < keyi - 1)
{
StackPush(&st, begin);
StackPush(&st, keyi - 1);
}
if (keyi + 1 < end)
{
StackPush(&st, keyi + 1);
StackPush(&st, end);
}
}
//记得销毁栈。
StackDestory(&st);
}
由此可以看出,虽然栈实现快排不是递归,但是和递归的思想一样。简直和递归一模一样。
2.队列实现快排
废话不多说。看图

//快速排序的非递归形式1:通过队列来实现
void QuickSort(int* a, int begin, int end)
{
Queue q;
QueueInit(&q);
QueuePush(&q, begin);
QueuePush(&q, end);
while (!QueueEmpty(&q))
{
int left = QueueFront(&q);
QueuePop(&q);
int right = QueueFront(&q);
QueuePop(&q);
int keyi = PartSort(a, left, end);//[left,keyi-1][keyi+1,right]
if (left < keyi - 1)
{
QueuePush(&q, left);
QueuePush(&q, keyi - 1);
}
if (keyi + 1 < right)
{
QueuePush(&q, keyi + 1);
QueuePush(&q, right);
}
}
QueueDestory(&q);
}
浅浅总结下
快排的平均时间复杂度为O(N*LogN)
如果每次划分只有一半区间,另一半区间为空,则时间复杂度为n2
快排对初始顺序影响较大,假如数据有序时,其性能最差。对初始顺序比较敏感
以上就是C语言植物大战数据结构快速排序图文示例的详细内容,更多关于C语言数据结构快速排序的资料请关注我们其它相关文章!
相关推荐
-

C语言实现快速排序算法
一.快速排序算法(Quicksort) 1. 定义 快速排序由C. A. R. Hoare在1962年提出.快速排序是对冒泡排序的一种改进,采用了一种分治的策略. 2. 基本思想 通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 3. 步骤 a. 先从数列中取出一个数作为基准数. b. 分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全
-
C语言实现选择排序、冒泡排序和快速排序的代码示例
选择和冒泡 #include<stdio.h> void maopao(int a[],int len){ int i,j,temp; for(i = 0;i < len - 1 ; i ++){//从第一个到倒数第二个 for (j = 0 ; j < len - 1 - i ; j ++)//排在后的是已经排序的 { if (a[j] > a[j + 1])//大的数换到后面去 { temp = a[j]; a[j] = a[j + 1]; a [j + 1] = tem
-
C语言简单实现快速排序
快速排序是一种不稳定排序,它的时间复杂度为O(n·lgn),最坏情况为O(n2):空间复杂度为O(n·lgn). 这种排序方式是对于冒泡排序的一种改进,它采用分治模式,将一趟排序的数据分割成独立的两部分,其中一组数据的每个值都小于另一组.每一趟在进行分类的同时实现排序. 其中每一趟的模式通过设置key当基准元素,key的选择可以是数据的第一个,也可以是数据的最后一个.这里以每次选取数据的第一个为例: 具体代码实现: #include<stdio.h> #define N 6 int fun(i
-
C语言中快速排序和插入排序优化的实现
快速排序 快速排序思想 1962年,由C.A.R.Hoare创造出来.该算法核心思想就一句话:"排序数组时,将数组分成两个小部分,然后对它们递归排序".然而采取什么样的策略将数组分成两个部分是关键,想想看,如果随便将数组A分成A1和A2两个小部分,即便分别将A1和A2排好序,那么A1和A2重新组合成A时仍然是无序的.所以,我们可以在数组中找一个值,称为key值,我们在把数组A分解为A1和A2前先对A做一些处理,让小于key值的元素都移到其左边,所有大于key值的元素都移到其右边.这样递
-
C语言数据结构 快速排序实例详解
C语言数据结构 快速排序实例详解 一.快速排序简介 快速排序采用分治的思想,第一趟先将一串数字分为两部分,第一部分的数值都比第二部分要小,然后按照这种方法,依次对两边的数据进行排序. 二.代码实现 #include <stdio.h> /* 将两个数据交换 */ void swap(int* Ina , int* Inb) { int temp = *Ina; *Ina = *Inb; *Inb = temp; } /* 进行一趟的快速排序,把一个序列分为两个部分 */ int getPart
-
C语言快速排序函数用法(qsort)
本文实例为大家分享了C语言快排函数用法,供大家参考,具体内容如下 #include <stdio.h> #include <stdlib.h> #include <string.h> struct student { int id; char name[12]; char sex; }; int compare(const void* a,const void* b)//基本数据类型排序 { return *(char*)a-*(char*)b;//从小到大 //取值/
-
C语言植物大战数据结构快速排序图文示例
目录 快速排序 一.经典1962年Hoare法 1.单趟排序 2.递归左半区间和右半区间 3.代码实现 二.填坑法(了解) 1.单趟思路 2.代码实现 三.双指针法(最佳方法) 1.单趟排序 2.具体思路 3.代码递归图 4.代码实现 四.三数取中优化(最终方案) 1.三数取中 2.代码实现(最终代码) 五.时间复杂度(重点) 1.最好情况下 2.最坏情况下 3.空间复杂度 六.非递归写法 1.栈模拟递归快排 2.队列实现快排 浅浅总结下 “田家少闲月,五月人倍忙”“夜来南风起,小麦覆陇黄” C
-
C语言植物大战数据结构堆排序图文示例
目录 TOP.堆排序前言 一.向下调整堆排序 1.向下调整建堆 建堆的技巧 建堆思路代码 2.向下调整排序 调整思路 排序整体代码 3.时间复杂度(难点) 向下建堆O(N) 向下调整(N*LogN) 二.向上调整堆排序 1.向上调整建堆 2.建堆代码 “大弦嘈嘈如急雨,小弦切切如私语”“嘈嘈切切错杂弹,大珠小珠落玉盘” TOP.堆排序前言 什么是堆排序?假如给你下面的代码让你完善堆排序,你会怎么写?你会怎么排? void HeapSort(int* a, int n) { } int main(
-
C语言植物大战数据结构二叉树递归
目录 前言 一.二叉树的遍历算法 1.构造二叉树 2.前序遍历(递归图是重点.) 3.中序遍历 4.后序遍历 二.二叉树遍历算法的应用 1.求节点个数 3.求第k层节点个数 4.查找值为x的节点 5.二叉树销毁 6.前序遍历构建二叉树 7.判断二叉树是否是完全二叉树 8.求二叉树的深度 三.二叉树LeetCode题目 1.单值二叉树 2. 检查两颗树是否相同 3. 对称二叉树 4.另一颗树的子树 6.反转二叉树 " 梧桐更兼细雨,到黄昏.点点滴滴." C语言朱武大战数据结构专栏 C语言
-
C语言植物大战数据结构希尔排序算法
目录 前言 一.插入排序 1.排序思路 2.单趟排序 详细图解 3.整体代码 4.时间复杂度 (1).最坏情况下 (2).最好情况下 (3).基本有序情况下(重点) 5.算法特点 二.希尔排序 1.希尔从哪个方面优化的插入排序? 2.排序思路 3.预排序 4.正式排序 5.整体代码 6.时间复杂度 (1).while循环的复杂度 (2).每组gap的时间复杂度 结论: “至若春和景明,波澜不惊,上下天光,一碧万顷,沙鸥翔集,锦鳞游泳,岸芷汀兰,郁郁青青.” C语言朱武大战数据结构专栏 C语言植物
-
C语言植物大战数据结构二叉树堆
目录 前言 堆的概念 创建结构体 初始化结构体 销毁结构体 向堆中插入数据 1.堆的物理结构和逻辑结构 2.完全二叉树下标规律 3.插入数据思路 依次打印堆的值 删除堆顶的值 判断堆是否为空 求堆中有几个元素 得到堆顶的值 堆排序 总体代码 Heap.h Heap.c Test.c “竹杖芒鞋轻胜马,谁怕?一蓑烟雨任平生” C语言朱武大战数据结构专栏 C语言植物大战数据结构快速排序图文示例 C语言植物大战数据结构希尔排序算法 C语言植物大战数据结构堆排序图文示例 C语言植物大战数据结构二叉树递归
-
C语言实现交换排序算法(冒泡,快速排序)的示例代码
目录 前言 一.冒泡排序 1.基本思想 2.优化 3.扩展 二.快速排序 1.基本思想 2.优化 3.代码 前言 查找和排序是数据结构与算法中不可或缺的一环,是前辈们在算法道路上留下的重要且方便的一些技巧,学习这些经典的查找和排序也能让我们更好和更快的解决问题.在这个专栏中我们会学习六大查找和十大排序的算法与思想,而本篇将详细讲解其中的交换排序——冒泡排序和快速排序: 注意:本文中所有排序按照升序排序,降序只需要把逻辑反过来即可! 一.冒泡排序 1.基本思想 对于很多同学来说冒泡排序是再熟悉不过
-
Go语言数据结构之插入排序示例详解
目录 插入排序 动画演示 Go 代码实现 总结 插入排序 插入排序,英文名(insertion sort)是一种简单且有效的比较排序算法. 思想: 在每次迭代过程中算法随机地从输入序列中移除一个元素,并将改元素插入待排序序列的正确位置.重复该过程,直到所有输入元素都被选择一次,排序结束. 插入排序有点像小时候我们抓扑克牌的方式,如果抓起一张牌,我们放在手里:抓起第二张的时候,会跟手里的第一张牌进行比较,比手里的第一张牌小放在左边,否则,放在右边. 因此,对所有的牌重复这样的操作,所以每一次都是插
-
C语言单链表的图文示例讲解
目录 一.单链表的结构 二.单链表的函数接口 1. 申请结点及打印单链表 2. 尾插尾删 3. 头插头删 4. 中间插入和删除 1. 在 pos 指向的结点之后插入结点 2. 在 pos 指向的结点之前插入结点 3. 删除 pos 指向的结点的后一个结点 4. 删除 pos 指向的结点 6. 查找 7. 销毁单链表 在上一篇所讲述的 动态顺序表 中存在一些缺陷 1.当空间不够时需要扩容,扩容是有一定的消耗的 如果每次空间扩大一点,可能会造成空间的浪费,而空间扩小了,又会造成频繁的扩容2.在顺序表
-
Sublime Text 3 实现C语言代码的编译和运行(示例讲解)
Sublime Text 3是一款优秀的代码编辑软件.界面简洁,轻巧快速,很受大家的欢迎. 最近开始用他来编辑数据结构的代码,这就需要在新建编译系统. 具体方法如下: 首先: 接下来是关键的一步,将以下代码粘贴到弹出的编辑页面中,文件名为name.sublime-build形式,name是新建的编译器名字. { "cmd": ["gcc","${file}","-fexec-charset=gbk","-o"