python使用pandas读xlsx文件的实现
目录
- 使用pandas读xlsx文件
- 数据:d1.xlsx
- 运行结果展示
使用pandas读xlsx文件
- 读取前n行数据
- 读取指定数据(指定行指定列)
- 获取文件行号和列标题
- 将数据转换为字典形式
import pandas as pd
#1.读取前n行所有数据
df1=pd.read_excel('d1.xlsx')#读取xlsx中的第一个sheet
data1=df1.head(10)#读取前10行所有数据
data2=df1.values#list【】 相当于一个矩阵,以行为单位
#data2=df.values() 报错:TypeError: 'numpy.ndarray' object is not callable
print("获取到所有的值:\n{0}".format(data1))#格式化输出
print("获取到所有的值:\n{0}".format(data2))
#2.读取特定行特定列
data3=df1.iloc[0].values#读取第一行所有数据
data4=df1.iloc[1,1]#读取指定行列位置数据:读取(1,1)位置的数据
data5=df1.iloc[[1,2]].values#读取指定多行:读取第一行和第二行所有数据
data6=df1.iloc[:,[0]].values#读取指定列的所有行数据:读取第一列所有数据
print("数据:\n{0}".format(data3))
print("数据:\n{0}".format(data4))
print("数据:\n{0}".format(data5))
print("数据:\n{0}".format(data6))
#3.获取xlsx文件行号、列号
print("输出行号列表{}".format(df1.index.values))#获取所有行的编号:0、1、2、3、4
print("输出列标题{}".format(df1.columns.values))#也就是每列的第一个元素
#4.将xlsx数据转换为字典
data=[]
for i in df1.index.values:#获取行号的索引,并对其遍历
#根据i来获取每一行指定的数据,并用to_dict转成字典
row_data=df1.loc[i,['id','name','class','data','score',]].to_dict()
data.append(row_data)
print("最终获取到的数据是:{0}".format(data))
#iloc和loc的区别:iloc根据行号来索引,loc根据index来索引。
#所以1,2,3应该用iloc,4应该有loc
数据:d1.xlsx
| id | name | class | data | score |
| 201901 | A | 1 | Jan-20 | 1.3 |
| 201902 | B | 2 | Mar-20 | 3.4 |
| 201903 | C | 3 | May-20 | 3.4 |
| 201904 | D | 1 | Jan-20 | 3.4 |
| 201905 | E | 1 | Feb-20 | 5.6 |
| 201906 | F | 1 | Mar-20 | 4.6 |
| 201907 | G | 1 | Feb-19 | 7.8 |
| 201908 | H | 2 | Apr-30 | 5.6 |
| 201909 | I | 3 | Jan-42 | 5.6 |
| 201910 | G | 4 | Mar-30 | 4.5 |
| 201911 | K | 5 | Apr-20 | 3.4 |
| 201912 | L | 6 | Apr-20 | 2.3 |
| 201913 | M | 4 | Mar-20 | 2.4 |
运行结果展示
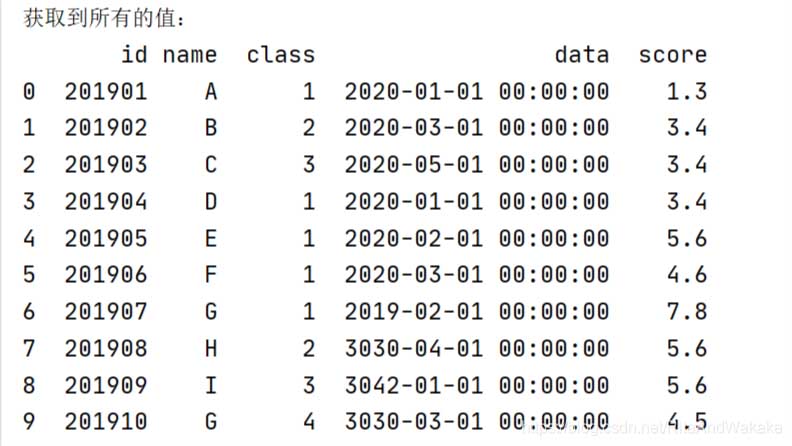


以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

pandas读取中文xlsx文件出现的问题
目录 panda读取中文xlsx文件 解决pandas读取xlsx时报错 panda读取中文xlsx文件 1.数据为中文内容,xlsx文件保存. 2.直接读取文件出错(Python报错:pandas.errors.ParserError: Error tokenizing data. C error: Expected 3……),将xlsx文件后缀保存为csv,仍出现格式问题(xlsx不能为多表,左下角可以切换多个窗口的那种),后**将xlsx文件另存为csv**解决此问题. 3.读取csv文件
-
Python使用pandas和xlsxwriter读写xlsx文件的方法示例
python使用pandas和xlsxwriter读写xlsx文件 已有xlsx文件如下: 1. 读取前n行所有数据 # coding: utf-8 import pandas as pd # 1. 读取前n行所有数据 df = pd.read_excel('school.xlsx')#读取xlsx中第一个sheet data1 = df.head(7) # 读取前7行的所有数据,dataFrame结构 data2 = df.values #list形式,读取表格所有数据 print("获取到所
-
关于Python 解决Python3.9 pandas.read_excel(‘xxx.xlsx‘)报错的问题
问题描述 使用pandas库的read_excel()方法读取外部excel文件报错, 截图如下 好像是缺少了什么方法的样子 问题分析 分析个啥, 水平有限, 直接面向stackoverflow编程 https://stackoverflow.com/questions/64264563/attributeerror-elementtree-object-has-no-attribute-getiterator-when-trying 我找到了下面的这几种说法 根据国外大神的指点, 我得出了这些
-
python使用pandas读xlsx文件的实现
目录 使用pandas读xlsx文件 数据:d1.xlsx 运行结果展示 使用pandas读xlsx文件 读取前n行数据 读取指定数据(指定行指定列) 获取文件行号和列标题 将数据转换为字典形式 import pandas as pd #1.读取前n行所有数据 df1=pd.read_excel('d1.xlsx')#读取xlsx中的第一个sheet data1=df1.head(10)#读取前10行所有数据 data2=df1.values#list[] 相当于一个矩阵,以行为单位 #data
-
在python中pandas读文件,有中文字符的方法
后面要加encoding='gbk' import pandas as pd datt=pd.read_csv('D:\python_prj_1\data_1.txt',encoding='gbk') print(datt) 以上这篇在python中pandas读文件,有中文字符的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf
-
python使用pandas读写excel文件的方法实例
目录 引言 读取excel文件 写入文件: 总结 引言 现在本地创建一个excel表,以及两个sheet,具体数据如下: sheet1: sheet2: 读取excel文件 pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None) io:excel文件路径. sheet_name:返回指定的sheet. header:表头,默认值为0.也可以指定多行.当header取值为None
-
python 利用pandas将arff文件转csv文件的方法
直接贴代码啦: #coding=utf-8 import pandas as pd def arff_to_csv(fpath): #读取arff数据 if fpath.find('.arff') <0: print('the file is nott .arff file') return f = open(fpath) lines = f.readlines() content = [] for l in lines: content.append(l) datas = [] for c i
-
解决Python中pandas读取*.csv文件出现编码问题
1.问题 在使用Python中pandas读取csv文件时,由于文件编码格式出现以下问题: Traceback (most recent call last): File "pandas\_libs\parsers.pyx", line 1134, in pandas._libs.parsers.TextReader._convert_tokens File "pandas\_libs\parsers.pyx", line 1240, in pandas._libs
-
Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程: 使用
-
python利用pandas将excel文件转换为txt文件的方法
python将数据换为txt的方法有很多,可以用xlrd库实现.本人比较懒,不想按太多用的少的插件,利用已有库pandas将excel文件转换为txt文件. 直接上代码: ''' function:将excel文件转换为text author:Nstock date:2018/3/1 ''' import pandas as pd import re import codecs #将excel转化为txt文件 def exceltotxt(excel_dir, txt_dir): with co
-
Python使用pandas处理CSV文件的实例讲解
Python中有许多方便的库可以用来进行数据处理,尤其是Numpy和Pandas,再搭配matplot画图专用模块,功能十分强大. CSV(Comma-Separated Values)格式的文件是指以纯文本形式存储的表格数据,这意味着不能简单的使用Excel表格工具进行处理,而且Excel表格处理的数据量十分有限,而使用Pandas来处理数据量巨大的CSV文件就容易的多了. 我用到的是自己用其他硬件工具抓取得数据,硬件环境是在Linux平台上搭建的,当时数据是在运行脚本后直接输出在termin
-
python 使用pandas读取csv文件的方法
目录 pandas读取csv文件的操作 1. 读取csv文件 在这里记录一下,python使用pandas读取文件的方法用到pandas库的read_csv函数 # -*- coding: utf-8 -*- """ Created on Mon Jan 24 16:48:32 2022 @author: zxy """ # 导入包 import numpy as np import pandas as pd import matplotlib.