深入探寻seajs的模块化与加载方式
由于一直在使用,所以了解了下seajs的源代码。这里是我对下面几个问题的理解:
1、seajs的require(XXX)的方法是怎样实现模块加载的?
2、为什么需要预加载?
3、为什么需要构建工具?
4、构建前后的代码究竟有些什么区别,为什么要这么做?
问题1: seajs的require(XXX)的方法是怎样实现模块加载的?
代码逻辑比较绕,对源代码的理解放在文章的末尾,这里先简单梳理下模块加载的逻辑:
1、从seajs.use方法入口,开始加载use到的模块。
2、use到的模块这时mod缓存当中一定是不存在的。seajs创建一个新的mod,赋予一些初始的状态。
3、执行mod.load方法
4、一堆逻辑之后走到seajs.request方法,请求模块文件。模块加载完成之后,执行define方法。
5、define方法分析提取模块的依赖模块,保存起来。缓存factory但不执行。
6、模块的依赖模块再被加载,如果继续有依赖模块,则继续加载。直至所有被依赖的模块都加载完毕。
7、所有的模块加载完毕之后,执行use方法的callback.
8、模块内部逻辑从callback开始执行。require方法在这个过程当中才被执行。
问题2:为什么需要预加载?
我们看到seajs.use方法实际上是在所有依赖模块都加载完了之后才执行callback。可以理解成在业务逻辑代码在执行之前,必须先预加载所有被依赖的模块代码。那么为什么是一个这样必须先做预加载的逻辑?
答案在于逻辑代码里面引用其他模块方法的这个require方法的执行方法:
var mod = require(id);
这个语法决定了mod的取得是个同步执行的过程,如果模块代码在此之前没有被预加载的话,就只能采用异步加载回调的方法来实现了,那么整个seajs的执行逻辑将完全会是另一个样子。因为异步你会搞不懂模块的执行顺序,逻辑会变的难以掌控。
问题3:为什么需要构建工具?
可以看到没有构建前各个依赖模块都是单独加载的。这会产生过多的模块请求,对于页面的加载性能是不利的。构建工具本质上就是为了解决模块合并加载的问题。
问题4:构建前后的代码究竟有些什么区别,为什么要这么做?
构建工具究竟做了些什么。我们说它本质上是为了解决代码合并加载的问题,那么它所做的只是简单的将各个模块文件合并成一个文件?
当然不是。测试一下,你如果只是简单把几个模块文件合并到一个文件以后,会发现这个文件根本没有办法正常执行。
原因在于define方法的实现。
seajs是推崇定义模块的时候只在define方法传入factory参数的。回顾define方法内部,当没有传入id(姑且等同于模块的url)时,会通过getCurrentScript()方法去取得当前正在执行的这个模块文件的url路径,然后把这个路径作为键值与模块本身一起缓存到cachedMods。这里很关键的一点是,整个seajs内部的这个模块缓存机制其实是依赖每个模块的url来做缓存的键值。require(id)方法,归根结底也是通过url键值到。require(id)方法,归根结底也是通过url键值到cachedMods里面去找相应的模块。这个键值不能重复不能出错,不然模块的对应关系就混乱了。如果把a、b、c几个模块文件简单合并到一个目标文件x之后,getCurrentScript()只能获取到x的路径,三个模块的键值就没法做出区别了,执行肯定出错。
所以如果要把几个模块文件合并在一起,就必须为每个模块明确uri。也就是define方法必须都传入id参数。当id传入的时候,seajs会将这个id转换为url用作缓存的键值。
如果只传id和factory,也就是 define(id, factory),那么deps = undefined,define方法就会去执行parseDependencies(factory.toString())方法提取factory里面的依赖模块,后续会走到解析模块路径,线上单独加载各个模块的逻辑里面去,这个时候就失去了合并加载的意义了。
所以合并加载,define方法必须正确的传入id,deps,factory三个参数才能正确执行。
seajs 所谓CMD的模块定义方法,是提倡大家写模块的阶段都只传factory一个参数的,其他两个参数在后期代码构建的阶段来生成。上面解释了为什么这两参数在构建后是必须的。
至于为什么提倡定义模块的时候只传factory,我看主要是因为手工传入的id和deps参数,极易出错,不便维护。工具可以提高效率并保证参数的正确。
附: 对seajs 主要代码逻辑的理解。
说明:源代码版本是Sea.js 2.3.0
1、先看看define方法做了些什么
Module.define = function (id, deps, factory)
define方法的时候,支持三个参数。其中id,deps是选填的。factory必须。代码里面通过以下逻辑来控制:
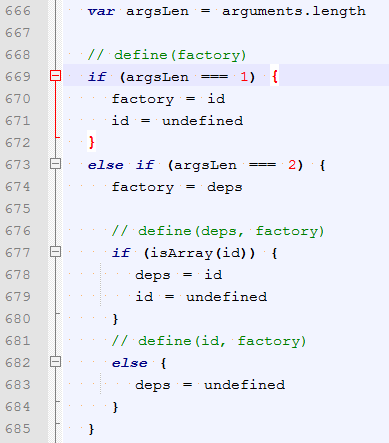
但其实deps是必须的,因为seajs必须知道每个模块依赖了哪些模块,不然无法执行加载。
所以,当factory是函数,并且deps没有被主动传入的时候,就需要使用parseDependencies方法来分析出factory当中的依赖模块了。

parseDependencies方法做的事情主要就是用一个正则表达式把函数体里面所有require(XXX)里面的XXX提取出来,这也就是这个函数依赖到的所有模块了。

方法本身不复杂,但是这个正则表达式不简单:
分析完deps之后,将模块定义存入缓存:

注意,我们会发现define方法纯粹只是分析模块、存储模块,并没有执行模块。
2、真正执行模块,是在require方法里面。我们接下来看require。


简而言之require方法就是根据id在define定义存储的模块缓存中找到相应的模块,并执行它,获得模块定义返回的方法:

整个这个大步骤中,有一个很关键的步骤,有必要细说:
Module.get(require.resolve(id))。
require一个模块的时候,首先要找到这个模块。 Module.get方法就起这个作用。

cachedMods里面没有的话,就创建一个新的Module并缓存到cachedMods里面:
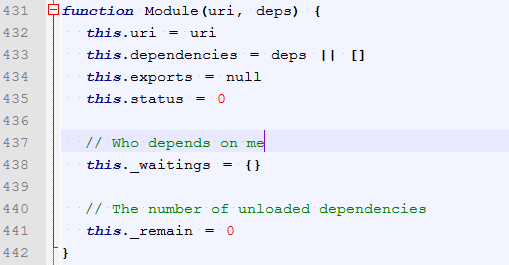
define和rquire方法这样看来不算复杂。seajs主要还是模块加载的逻辑有点复杂。
3、seajs真正执行的入口,是use方法:

通过use方法,从这里的ids开始触发模块的加载和执行。
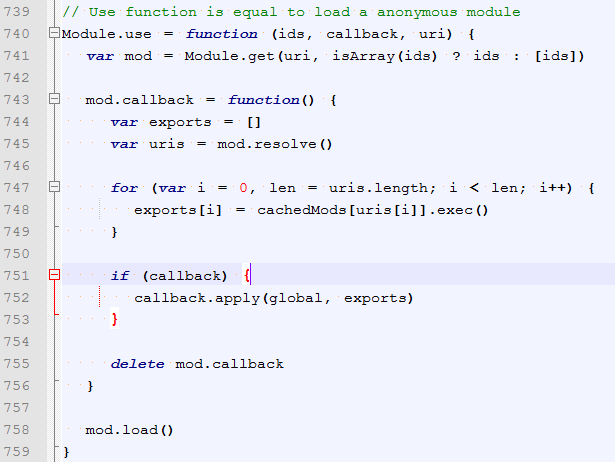
可以看到加载的关键点在mod.load方法。
load方法代码有点长,其中的主要逻辑是:判断mod的当前状态是否为已加载或者加载中。
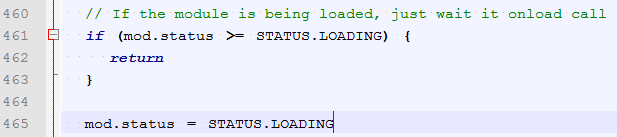
在Module的舒适化函数中,我们可以看到status默认值是0.
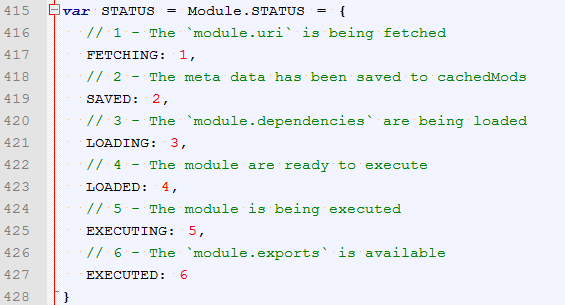
所以没有加载过的新模块,到这里都是: mod.status = STATUS.LOADING 状态设置为加载中,并执行后续加载逻辑。
接来下是获取模块的依赖urls
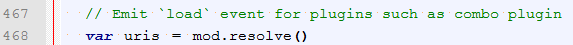
mod.resolve方法:

Module.resolve方法本质上就是把相对路径、配置的path、别名等转换成一个绝对路径。不贴代码了。
更新模块加载状态。
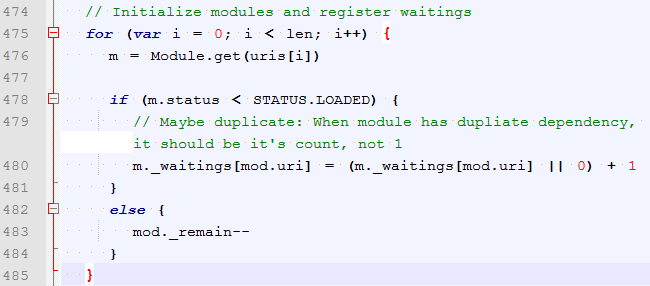
加载模块的逻辑:
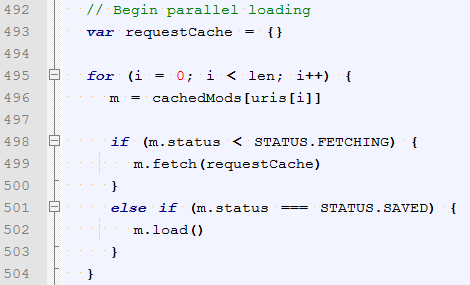
主要是m.fetch方法,里面其他逻辑这里略过。
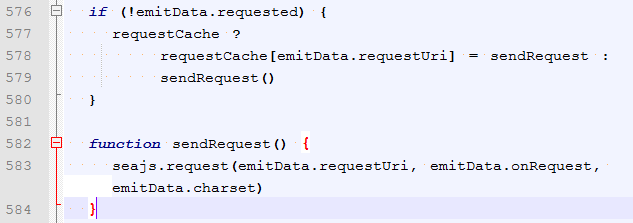
可以看到 seajs.request最终会去执行模块文件的加载:

当所有依赖模块加载完了之后,执行mod的onload方法

这里是 mod.onload()方法
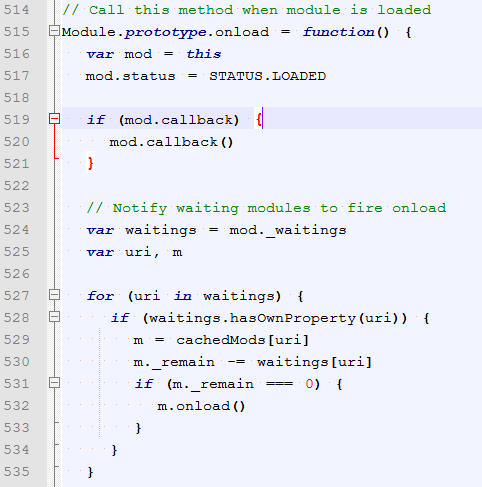
到此,seajs的核心逻辑就差不多都看到了。供参考,有理解不到位或者表达不准确的地方,欢迎一起探讨。
以上所述就是本文的全部内容了,希望大家能够喜欢。
相关推荐
-

SeaJS 与 RequireJS 的差异对比
"历史不是过去,历史正在上演.随着 W3C 等规范.以及浏览器的飞速发展,前端的模块化开发会逐步成为基础设施.一切终究都会成为历史,未来会更好."--引用玉伯原文最后一段话,我个人也非常赞同.既然谈到了"未来",我个人认为:前端 js 模块如果继续发展,其模块格式很可能会成为未来 WEB 一种标准规范,产生多种实现方式.就好比 JSON 格式一样,最终成为标准.被浏览器原生实现. 谁更有能成为未来的异步模块标准?SeaJS 遵循 CMD 规范,RequireJS 遵
-
seajs中模块的解析规则详解和模块使用总结
seajs github 模块标识已经说的相对清楚了.但并没有面面俱到,特别是当你需要手写 [模块ID]和[模块依赖]的时候,或者自己写自动化工具来做 transport 的时候(ps:spm貌似适应性不是很强也不易用,毕竟每个项目的目录结构可能相差很大,且不易改变.当然如果他的定位是包管理工具就别指望它来做你的项目的自动化构建工具了),ID的解析规则就需要了解透彻了.注意事项:1. 顶级标识始终相对 base 基础路径解析.2. 绝对路径和根路径始终相对当前页面解析.3. require 和
-
seajs1.3.0源码解析之module依赖有序加载
这里是seajs loader的核心部分,有些IE兼容的部分还不是很明白,主要是理解各个模块如何依赖有序加载,以及CMD规范. 代码有点长,需要耐心看: 复制代码 代码如下: /** * The core of loader */ ;(function(seajs, util, config) { // 模块缓存 var cachedModules = {} // 接口修改缓存 var cachedModifiers = {} // 编译队列 var compileStack = [] // 模
-
Sea.JS知识总结
SeaJS是一个遵循CommonJS规范的JavaScript模块加载框架.是一款现代的用于Web开发的模块加载工具,提供简单.极致的模块化体验.Sea.js 由阿里.腾讯等公司共同维护. 使用 Sea.js的好处: Sea.js 追求简单.自然的代码书写和组织方式,具有以下核心特性: 简单友好的模块定义规范:Sea.js 遵循 CMD 规范,可以像 Node.js 一般书写模块代码. 自然直观的代码组织方式:依赖的自动加载.配置的简洁清晰,可以让我们更多地享受编码的乐趣. Sea.js 还提供
-
SeaJS入门教程系列之使用SeaJS(二)
下载及安装 要在项目中使用SeaJS,你所有需要做的准备工作就是下载sea.js然后放到你项目的某个位置.SeaJS项目目前托管在GitHub上,主页为 https://github.com/seajs/seajs/ .可以到其git库的build目录下下载sea.js(已压缩)或sea-debug.js(未压缩).下载完成后放到项目的相应位置,然后在页面中通过<script>标签引入,你就可以使用SeaJS了. SeaJS基本开发原则 在讨论SeaJS的具体使用前,先介绍一下SeaJS的模块
-
Seajs的学习笔记
1.简介 Seajs,一个Web模块加载框架,追求简单.自然的代码书写和组织方式,:Sea.js 遵循 CMD 规范,模块化JS代码.依赖的自动加载.配置的简洁清晰,可以让程序员更多地专注编码. 2.优缺点 优点:1).提高可维护性.2).模块化编程.3).动态加载,前端性能优化 缺点:1).学习文档偏少且混乱,会更改团队使用JS的编写习惯,必须使用模块化编程.2).不太适合团队目前的情况,多JS文件但少改动,动态加载优势和模块化优势不明显.3). 需要配套使用SPM工具,JS的打包和管理工具.
-
seaJs的模块定义和模块加载浅析
SeaJS 是由玉伯开发的一个遵循 CommonJS 规范的模块加载框架,可用来轻松愉悦地加载任意 JavaScript 模块和css模块样式.SeaJS非常小巧,小巧在于压缩和gzip后体积只有4K,而且接口和方法也非常少,SeaJS 就两个核心:模块定义和 模块的加载及依赖关系.SeaJS非常强大,SeaJS可以加载任意 JavaScript 模块和css模块样式,SeaJS会保证你在使用一个模块时,已经将所依赖的其他模块载入到脚本运行环境中.玉伯的说法,SeaJS可以让你享受写代码的乐趣,
-
SeaJS入门教程系列之完整示例(三)
一个完整的例子上文说了那么多,知识点比较分散,所以最后我打算用一个完整的SeaJS例子把这些知识点串起来,方便朋友们归纳回顾.这个例子包含如下文件: 1.index.html--主页面.2.sea.js--SeaJS脚本.3.init.js--init模块,入口模块,依赖data.jquery.style三个模块.由主页面载入.4.data.js--data模块,纯json数据模块,由init载入.5.jquery.js--jquery模块,对 jQuery库的模块化封装,由init载入.6.s
-
seajs实现强制刷新本地缓存的方法分析
本文实例讲述了seajs实现强制刷新本地缓存的方法.分享给大家供大家参考,具体如下: 1.为什么 由于每次上传js文件到服务器后用户本机存在本地缓存,导致用户需要强制清除缓存或者等待缓存失效才能使用新功能,极其不友好. 2.原理 seajs配置参数中有map属性为文件映射功能,其作用是通过seajs加载的文件映射为一个新的名称加载,形如 var version="0.0.1"; seajs.config({//seajs配置声明 map:[ [".js","
-
SeaJS入门教程系列之SeaJS介绍(一)
前言SeaJS是一个遵循CommonJS规范的JavaScript模块加载框架,可以实现JavaScript的模块化开发及加载机制.与jQuery等JavaScript框架不同,SeaJS不会扩展封装语言特性,而只是实现JavaScript的模块化及按模块加载.SeaJS的主要目的是令JavaScript开发模块化并可以轻松愉悦进行加载,将前端工程师从繁重的JavaScript文件及对象依赖处理中解放出来,可以专注于代码本身的逻辑.SeaJS可以与jQuery这类框架完美集成.使用SeaJS可以
-
seajs模块之间依赖的加载以及模块的执行
本文介绍的是seajs模块之间依赖的加载以及模块的执行,下面话不多说直接来看详细的介绍. 入口方法 每个程序都有个入口方法,类似于c的main函数,seajs也不例外.系列一的demo在首页使用了seajs.use() ,这便是入口方法.入口方法可以接受2个参数,第一个参数为模块名称,第二个为回调函数.入口方法定义了一个新的模块,这个新定义的模块依赖入参提供的模块.然后设置新模块的回调函数,用以在loaded状态之后调用.该回调函数主要是执行所有依赖模块的工厂函数,最后在执行入口方法提供的回调.
-
把jQuery的类、插件封装成seajs的模块的方法
注:本文使用的seajs版本是2.1.1一.把Jquery封装成seajs的模块 复制代码 代码如下: define(function () { //这里放置jquery代码 把你喜欢的jquery版本放进来就好了 return $.noConflict();}); 调用方法:这样引进就可以像以前一样使用jquery 复制代码 代码如下: define(function (require, exports, module) { var $ = require('./js/jquery');