Python爬虫获取基金列表
目录
- 1 前言
- 2 哪里去获取数据呢
- 3 怎么抓取数据呢
1 前言
python爬虫用来收集数据是最直接和常用的方法,可以使用python爬虫程序获得大量的数据,从而变得非常的简单和快速;绝大多数网站使用了模板开发,使用的模板可以快速生成大量相同布局不同内容的页面,这时只需要为一个页面开发爬虫程序,因为爬虫程序也可以对同一模板生成的不同内容进行爬取内容
2 哪里去获取数据呢
这里给大家准备好了,打开这个连接,就能找看到对应的基金信息:
http://fund.eastmoney.com/jzzzl.html
有了基金连接,我们要做的就是怎么把它抓取下来,123 开始,我恰巧发现了后台访问的接口,是不是很神奇,该是上图的时候了,大家可以看到如下图:
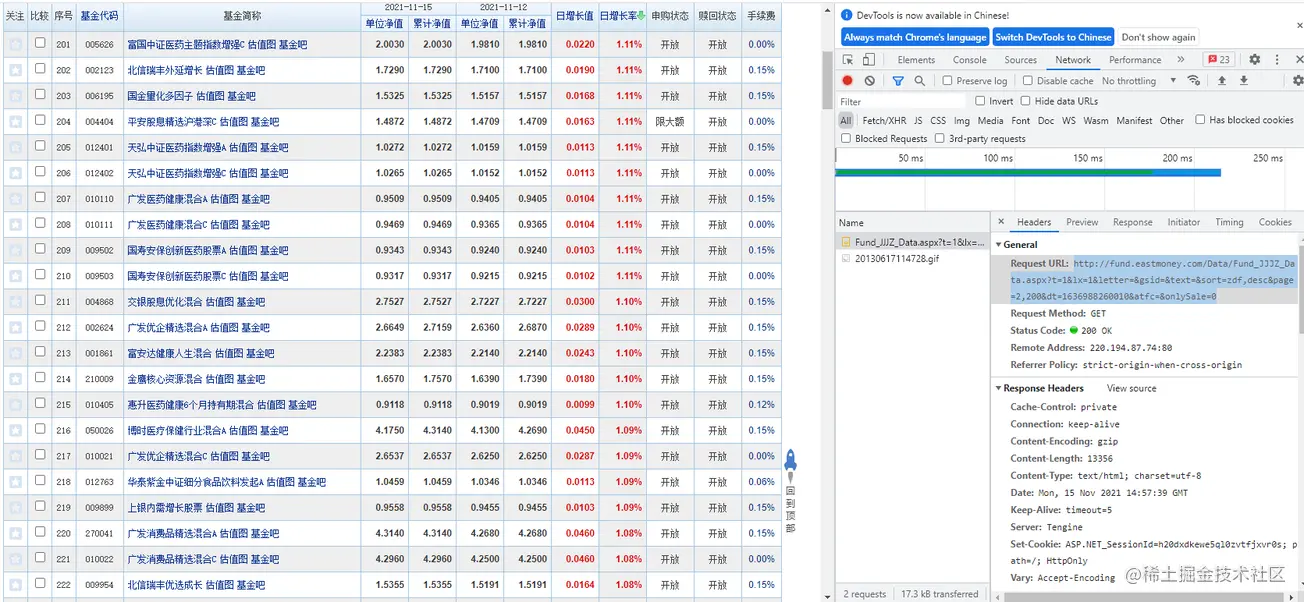
# 这是原始的连接 http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?lx=1&sort=zdf,desc&page=2,200&onlySale=0 # 经过我使用postman 删减掉一些参数发现精简的连接如下,我不能不吐槽一下,这个时候了还有参数传递使用中文首字母拼写的, # lx分明就是类型的简写。sort 是对某些字段排序可以忽略。分页的话2,200就是第二页,每页200条,onlySale就是可以卖出的条件。 http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?lx=1&sort=zdf,desc&page=2,100&onlySale=0
3 怎么抓取数据呢
这里我们使用python,需要安装的类库有 requests/demjson/prettytable/json,有没有特别简单呢?
# 安装命令如下 # 发起请求 pip install requests # 将不是那么严格的json 格式转换为json pip install demjson # 格式化打印数据 pip install prettytable # 将json 格式化的文本转换为json pip install json
这里我可以上代码了,简单的逻辑就是先抓取api接口返回的信息,然后解析报文,将返回结果转换成json 格式后只选择需要获取的内容,最后将获取的结果进行输出即可。
import requests
import json
import demjson
from prettytable import PrettyTable
# 数据表格的列表表头字段
title_list = ["code", "name", "value"]
# 查询基金列表信息
def query_fund_list(page= 1):
req_url = "http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?lx=1&sort=zdf,desc&page={},20&onlySale=0".format(page)
response = requests.get(req_url)
# 输出响应头
# print(response.headers)
# 获取请求结果并替换,否则结果不能进行格式化json
resp_body = response.text.replace("var db=", "")
# 本来首选是这个json, 因为json 不支持 {a :"1"} 这样的转换,因此使用了 demojson
# json_data = json.loads(resp_body)
# 转换对象为 json 对象,使不规则的json格式化为json对象
resp_body = demjson.decode(resp_body)
# 获取结果数组
fund_list = resp_body["datas"]
body_list = []
for node in fund_list:
tmp = []
tmp.append(node[0])
tmp.append(node[1])
tmp.append(node[3])
body_list.append(tmp)
# 创建一个对象 PrettyTable 用于打印输出结果
bt = PrettyTable()
# 将表头信息信息放入bt 中
bt.field_names = title_list
# 将表格内容放置在 bt 中
bt.add_rows(body_list)
# 打印结果
print(bt)
if __name__ == "__main__":
# 这里只打印了第一页,循环打印结果就不写了,大家都会的
query_fund_list(1)
最终输出的结果如图所示 :
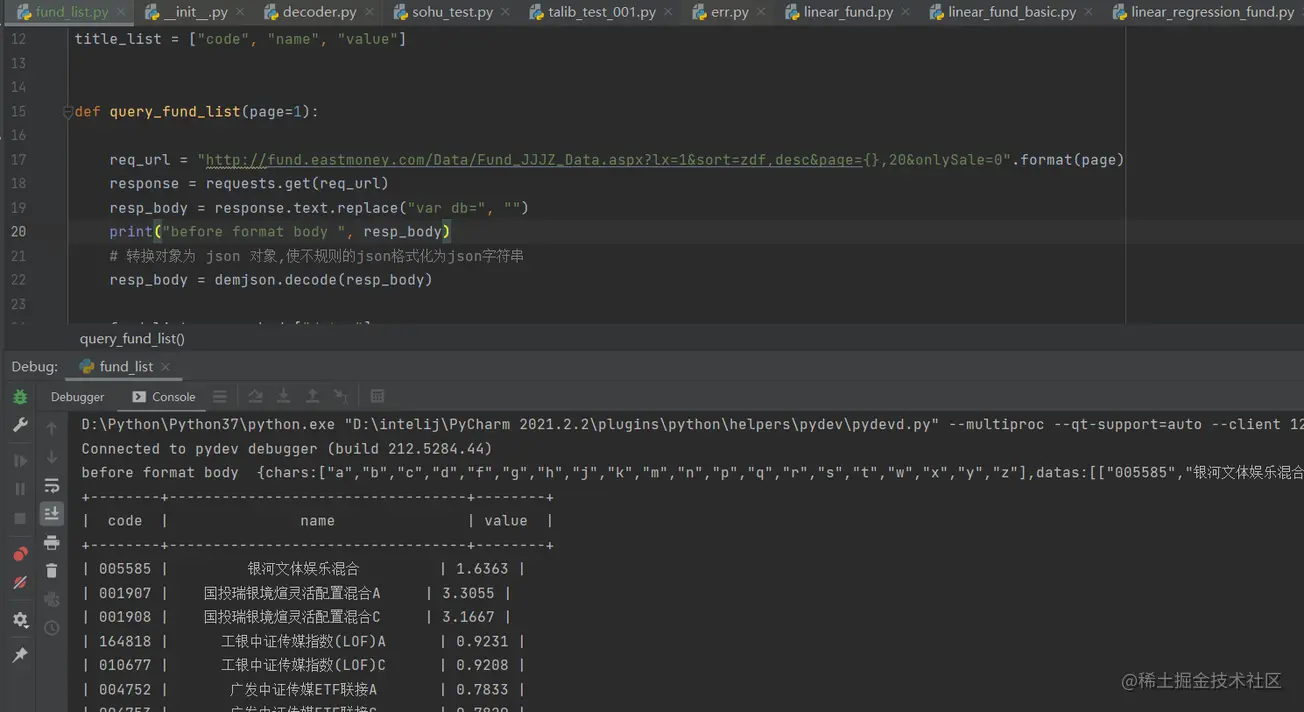
最终我们达到的结果就是这样的结果,有了这些结果,我们可以进行结构化存储,放进数据库中方面查询和使用。
| 基金代码 | 基金名称 | 最新净值 |
|---|---|---|
| 005585 | 银河文体娱乐混合 | 1.6363 |
| 001907 | 国投瑞银境煊灵活配置混合A | 3.3055 |
| 001908 | 国投瑞银境煊灵活配置混合C | 3.1667 |
| 164818 | 工银中证传媒指数(LOF)A | 0.9231 |
| ... | ... | ... |
这是一个简单的开始,我们获取到了基金的列表。后续我们会抓取基金的基本信息和变动信息,建立模型去展现。
到此这篇关于Python爬虫获取基金列表的文章就介绍到这了,更多相关Python获取列表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python如何获取列表中每个元素的下标位置
Git是编程中的基本技能之一,互联网公司几乎都在使用Git进行协作编程,昨天还有位禅友在微信上专门告诉我说星期五面试的时候刚好被问到 Git,幸好在这几天学了一下.Git并不难,但会Git至少可以说明一个人的学习能力或者说对技术的嗅觉能跟上主流,如果面试问你GitHub是什么都不知道,面试官就会对你打一个大的问号. 简单点评这一道题. 在使用 for 循环迭代一个列表时,有时我们需要获取列表中每个元素所在的下标位置是多少,例如 numbers = [10, 29, 30, 41],要求输出 (0
-
python切片(获取一个子列表(数组))详解
切片: 切片指从现有列表中,获取一个子列表 返回一个新列表,不影响原列表. 下标以 0 开始: list = ['红','绿','蓝','白','黑','黄','青'] # 下标 0 1 2 3 4 5 6 取单个值 语法:列表[n] n为下标,n=0表示第一个 , n=1表示第二个 以此类推 n=-1 表示倒数第一个, n=-2表示倒数第二个 以此类推 list = ['红','绿','蓝','白','黑','黄','青'] print(list[0]) # 红 print(list[1])
-
Python随机函数random随机获取数字、字符串、列表等使用详解
在python中用于生成随机数的模块是random,在使用前需要import, 下面看下它的用法. Python随机生成一个浮点数 random.random random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0 注意: 以下代码在Python3.5下测试通过, python2版本可稍加修改 描述 random() 方法返回随机生成的一个实数,它在(0,1)范围内. 语法 以下是 random() 方法的语法: import random random.ra
-
Python获取抖音关注列表封号账号的实现代码
最近抖音关注到达上限5000个了,所以就导致很多漂亮小姐姐没办法关注了,那么这里就通过python获取已经被封号的帐号取消关注就可以了 实现代码 import requests import json import time # 抖音创作者平台cookie header = {'Cookie': '你的COOKIE'} shijian = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) sbdy = str(0) sl = 0
-
python 中如何获取列表的索引
1.index方法 list_a= [12,213,22,2,32] for a in list_a: print(list_a.index(a)) 结果: 0 1 2 3 4 如果列表的没有重复的话那么用index完全可以的,那么如果列表中的元素有重复的呢? list_a= [12,213,22,2,2,22,2,2,32] for a in list_a: print(list_a.index(a)) 结果:0 1 2 3 3 2 3 3 8<br><br> 很显然结果不是你想
-
Python 如何获取目录下的文件列表,并自然排序
在实际的算法与程序开发中,经常需要面对的场景就是对同一目录内的文件进行批量操作. 并且很多时候目录中的文件明明是有规律的,同时希望程序在进行处理时也是按照一定的顺序进行. 方法 1 >>> import os >>> fileList = os.listdir('TestDir') >>> fileList ['test1.txt', 'test10.txt', 'test11.txt', 'test2.txt', 'test23.txt', 'tes
-

Python爬虫获取基金列表
目录 1 前言 2 哪里去获取数据呢 3 怎么抓取数据呢 1 前言 python爬虫用来收集数据是最直接和常用的方法,可以使用python爬虫程序获得大量的数据,从而变得非常的简单和快速:绝大多数网站使用了模板开发,使用的模板可以快速生成大量相同布局不同内容的页面,这时只需要为一个页面开发爬虫程序,因为爬虫程序也可以对同一模板生成的不同内容进行爬取内容 2 哪里去获取数据呢 这里给大家准备好了,打开这个连接,就能找看到对应的基金信息: http://fund.eastmoney.com/jzzz
-
Python爬虫获取基金基本信息
目录 1 前言 2 如何抓取基本信息 3 xpath 获取数据 4 bs4 获取数据 5 最终结果展现 1 前言 上篇文章Python爬虫获取基金列表我们已经讲述了如何从基金网站上获取基金的列表信息.这一骗我们延续上一篇,继续分享如何抓取基金的基本信息做展示.展示的内容包括基金的基本信息,诸如基金公司,基金经理,创建时间以及追踪标.持仓明细等信息. 2 如何抓取基本信息 # 在这里我就直接贴地址了,这个地址的获取是从基金列表跳转,然后点基金概况就可以获取到了. http://fundf10.ea
-
Python爬虫获取基金变动信息
目录 1 前言 2 抓取变动信息 2.1 基金的变动信息获取 2.2 基金阶段信息的抓取 3 最终结果展现 1 前言 前面文章Python爬虫获取基金列表.Python爬虫获取基金基本信息我们已经介绍了怎么获取基金列表以及怎么获取基金基本信息,本文我们继续前面的内容,获取基金的变动信息.这次获取信息的方式将组合使用页面数据解析和api接口调用的方式进行. 2 抓取变动信息 我们通过观察基金基本信息页面,我们可以发现有关基金变动信息的页面可以包含以下4个部分: 接下来说一下我们抓取数据的思路,在第
-
python爬虫之基金信息存储
目录 1 前言 2 信息存储 2.1 基金基本信息存储 2.2 基金变动信息获取 3 需要改进的地方 3.1 基金类型 3.2 基金的更新顺序 4 总结 1 前言 前面已经讲了很多次要进行数据存储,终于在上一篇中完成了数据库的设计,在这一篇就开始数据的存储操作,在数据存储的这个部分,会将之前抓取到的基金列表,基金基本信息和基金变动信息以及ETF信息进行存储. 2 信息存储 2.1 基金基本信息存储 在这里获取基金信息包括两个部分,一部分是场外基金另外一部分是场外基金信息.之在前的文章中,我们已经
-
python爬虫获取淘宝天猫商品详细参数
首先我是从淘宝进去,爬取了按销量排序的所有(100页)女装的列表信息按综合.销量分别爬取淘宝女装列表信息,然后导出前100商品的 link,爬取其详细信息.这些商品有淘宝的,也有天猫的,这两个平台有些区别,处理的时候要注意.比如,有的说"面料".有的说"材质成分",其实是一个意思,等等.可以取不同的链接做一下测试. import re from collections import OrderedDict from bs4 import BeautifulSoup
-
Python爬虫获取op.gg英雄联盟英雄对位胜率的源码
通过第三方BeautifulSoup库来爬取op.gg网页静态数据 主要思路 op.gg网站 网站以出场率高低排名,并且列出对位胜率,在高出场率的前提下,胜率有很大的参考意义,在counter位很有帮助 通过开发者工具找到对应部位源码,发现数据就在源码中,证明这是一个静态数据,确定使用BeautifulSoup库. 源码 import requests from bs4 import BeautifulSoup championname={'阿卡丽 ':'akali','牛头':'alistar
-
Python爬虫获取数据保存到数据库中的超详细教程(一看就会)
目录 1.简介介绍 2.Xpath获取页面信息 3.通过Xpath爬虫实操 3-1.获取xpath 完整代码展示: 总结 1.简介介绍 -网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫.-一般在浏览器上可以获取到的,通过爬虫也可以获取到,常见的爬虫语言有PHP,JAVA,C#,C++,Python,为啥我们经常听到说的都是Python爬虫,这是
-
Python爬虫获取整个站点中的所有外部链接代码示例
收集所有外部链接的网站爬虫程序流程图 下例是爬取本站python绘制条形图方法代码详解的实例,大家可以参考下. 完整代码: #! /usr/bin/env python #coding=utf-8 import urllib2 from bs4 import BeautifulSoup import re import datetime import random pages=set() random.seed(datetime.datetime.now()) #Retrieves a list
-
python爬虫获取小区经纬度以及结构化地址
本文实例为大家分享了python爬虫获取小区经纬度.地址的具体代码,供大家参考,具体内容如下 通过小区名称利用百度api可以获取小区的地址以及经纬度,但是由于api返回的值中的地址形式不同,所以可以首先利用小区名称进行一轮爬虫,获取小区的经纬度,然后再利用经纬度Reverse到小区的结构化的地址.另外小区名称如果是'...号',可以在爬虫开始之前在'号'之后加一个'院',得到的精确度更高.这次写到程序更加便于二次利用,只需要给程序传递一个dataframe就可以坐等结果了.现在程序已经写好了,就
-
python爬虫获取新浪新闻教学
一提到python,大家经常会提到爬虫,爬虫近来兴起的原因我觉得主要还是因为大数据的原因,大数据导致了我们的数据不在只存在于自己的服务器,而python语言的简便也成了爬虫工具的首要语言,我们这篇文章来讲下爬虫,爬取新浪新闻 1. 大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现 大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现 2.首先,我们要写爬虫,可以借鉴