python爬虫之场内ETF基金获取
目录
- 1 前言
- 2 ETF列表和简称
- 3 ETF 信息获取
- 3.1 ETF列表信获取
- 3.2 获取基金的简称
- 4 最终结果展示
1 前言
之前已经介绍了基金的变动信息,但是这些基金都是属于场外的,今天我们要介绍的是一个带门槛的投资产品-ETF。只有开立证券账户的玩家才能入局,ETF 是一种场内交易型基金,可以在盘中进行交易,交易性比场外基金强一点,那么闲言少叙,马上开始介绍正题。
2 ETF列表和简称
ETF基金变动情况和基本情况的获取方式和场外基金是一样的,怎么获取比较全面的ETF基金列表呢?
# 获取基金信息的列表 http://fund.eastmoney.com/data/fbsfundranking.html
以下是ETF信息列表所展示的信息:

ETF 在场内进行交易时,一般都有一个简称,获取简称的方式比较麻烦一点,需要访问一个页面,然后通过 bs4 去解析元素的方式去获取。
#经过分析,我们可以发现基金代码前缀就代表这其市场,5上海市场 1-深圳市场,以地产ETF和光伏ETF为例 http://quote.eastmoney.com/sz159707.html http://quote.eastmoney.com/sh515790.html

3 ETF 信息获取
3.1 ETF列表信获取
ETF 列表信息我们通过访问列表发现在访问列表数据时,是请求了一个api接口到了后台,然后返回给前端一个响应报文。

http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=fb&ft=ct&rs=&gs=0&sc=zzf&st=desc&pi=1&pn=50
看到这里就觉得很开心,不用解析 html 文件了,当通过request使用get 方式获取数据时,发现竟然没有返回无访问权限,我想可能是没有携带cookie的原因,但是我也没有登录呀,可能是请求头需要携带一些页面信息,于是,经过尝试,最终确定了需要携带的信息为:
headers = {
'Host': 'fund.eastmoney.com',
'Referer': 'http://fund.eastmoney.com/data/fbsfundranking.html'
}
最终我们获取基金列表的代码应该这样写:
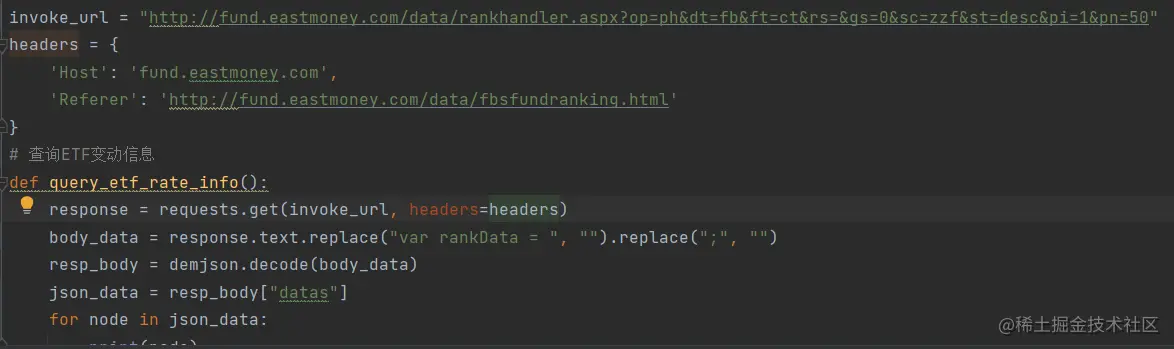
调试后获取到的结果如下图所示:

3.2 获取基金的简称
获取基金的简称相对比较简单,通过分析发现,简称所在的位置在 <span class="quote_title_0 wryh">光伏ETF</span> 中,通过访问页面获取元素即可拿到简称的描述。
具体的代码如下图所示:

4 最终结果展示
经过获取基金列表和获取基金简称两个步骤,我们获取到了最终的结果如下图所示,已经达成了需要获取信息的目的:
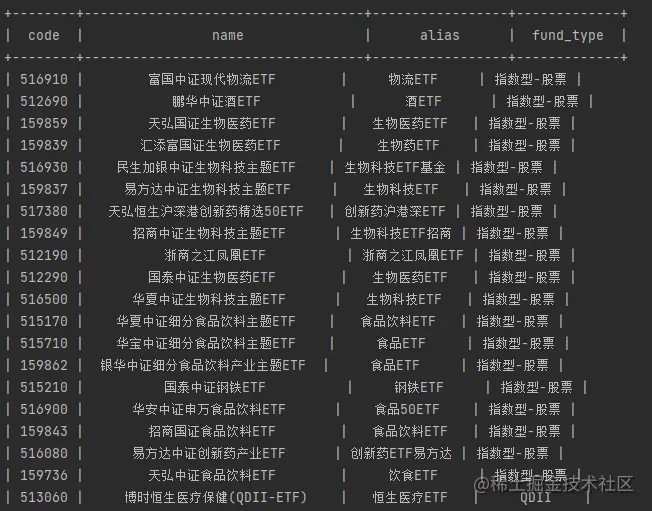
后续我们会把基金信息和ETF 信息进行合并存入数据库中,方便后续的数据分析。
到此这篇关于python爬虫之场内ETF基金获取的文章就介绍到这了,更多相关python ETF基金获取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫获取基金基本信息
目录 1 前言 2 如何抓取基本信息 3 xpath 获取数据 4 bs4 获取数据 5 最终结果展现 1 前言 上篇文章Python爬虫获取基金列表我们已经讲述了如何从基金网站上获取基金的列表信息.这一骗我们延续上一篇,继续分享如何抓取基金的基本信息做展示.展示的内容包括基金的基本信息,诸如基金公司,基金经理,创建时间以及追踪标.持仓明细等信息. 2 如何抓取基本信息 # 在这里我就直接贴地址了,这个地址的获取是从基金列表跳转,然后点基金概况就可以获取到了. http://fundf10.ea
-
Python获取基金网站网页内容、使用BeautifulSoup库分析html操作示例
本文实例讲述了Python获取基金网站网页内容.使用BeautifulSoup库分析html操作.分享给大家供大家参考,具体如下: 利用 urllib包 获取网页内容 #引入包 from urllib.request import urlopen response = urlopen("http://fund.eastmoney.com/fund.html") html = response.read(); #这个网页编码是gb2312 #print(html.decode("
-
Python批量获取基金数据的方法步骤
20年初准备投资基金,想爬取基金的业绩数据. 20年基金迎来了爆发式增长,现把代码开源以供参考. 本代码只能实现初步汇总,输出csv文件来保存基金的单位&累计净值,后期仍需要结合统计方法来筛选优质基金. 参考了网上的部分代码,实在不记得出处了,侵删. import requests import time import execjs start = time.perf_counter() # 获取所有基金编号 def getAllCode(): url = 'http://fund.eastmo
-
Python爬虫获取基金列表
目录 1 前言 2 哪里去获取数据呢 3 怎么抓取数据呢 1 前言 python爬虫用来收集数据是最直接和常用的方法,可以使用python爬虫程序获得大量的数据,从而变得非常的简单和快速:绝大多数网站使用了模板开发,使用的模板可以快速生成大量相同布局不同内容的页面,这时只需要为一个页面开发爬虫程序,因为爬虫程序也可以对同一模板生成的不同内容进行爬取内容 2 哪里去获取数据呢 这里给大家准备好了,打开这个连接,就能找看到对应的基金信息: http://fund.eastmoney.com/jzzz
-
Python爬虫获取基金变动信息
目录 1 前言 2 抓取变动信息 2.1 基金的变动信息获取 2.2 基金阶段信息的抓取 3 最终结果展现 1 前言 前面文章Python爬虫获取基金列表.Python爬虫获取基金基本信息我们已经介绍了怎么获取基金列表以及怎么获取基金基本信息,本文我们继续前面的内容,获取基金的变动信息.这次获取信息的方式将组合使用页面数据解析和api接口调用的方式进行. 2 抓取变动信息 我们通过观察基金基本信息页面,我们可以发现有关基金变动信息的页面可以包含以下4个部分: 接下来说一下我们抓取数据的思路,在第
-
python爬虫之场内ETF基金获取
目录 1 前言 2 ETF列表和简称 3 ETF 信息获取 3.1 ETF列表信获取 3.2 获取基金的简称 4 最终结果展示 1 前言 之前已经介绍了基金的变动信息,但是这些基金都是属于场外的,今天我们要介绍的是一个带门槛的投资产品-ETF.只有开立证券账户的玩家才能入局,ETF 是一种场内交易型基金,可以在盘中进行交易,交易性比场外基金强一点,那么闲言少叙,马上开始介绍正题. 2 ETF列表和简称 ETF基金变动情况和基本情况的获取方式和场外基金是一样的,怎么获取比较全面的ETF基金列表呢?
-
Python爬虫过程解析之多线程获取小米应用商店数据
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章来源于IT共享之家 ,作者IT共享者 前言 小米应用商店给用户发现最好的安卓应用和游戏,安全可靠,可是要下载东西要一个一个地搜索太麻烦了.而且速度不是很快. 今天用多线程爬取小米应用商店的游戏模块.快速获取. 二.项目目标 目标 :应用分类 - 聊天社交 应用名称, 应用链接,显示在控制台供用户下载. 三.涉及的库和网站 1.网址:百度搜 - 小米应用商店,进入官网. 2.涉及的库:re
-
python爬虫 线程池创建并获取文件代码实例
本实例主要进行线程池创建,多线程获取.存储视频文件 梨视频:利用线程池进行视频爬取 #爬取梨视频数据 import requests import re from lxml import etree from multiprocessing.dummy import Pool import random # 定义获取视频数据方法 def getVideoData(url): # url为列表中的视频url return requests.get(url=url,headers=headers).
-
Python爬虫回测股票的实例讲解
股票和基金一直是热门的话题,很多周围的人都选择不同种类的理财方式.就股票而言,肯定是短时间内收益最大化,这里我们需要用python爬虫的方法,来帮助我们获取一些股票的数据,这样才能更好的买到相应的股票.下面我们就python爬虫获取股票数据的方法带来详细的讲解. 1.生成上证与深证所有股票的代码: #上证代码 shanghaicode = [] for i in range(600000, 604000, 1): shanghaicode.append(str(i)) #深证代码 shenzhe
-
Python爬虫之Selenium实现关闭浏览器
前言:WebDriver提供了两个关闭浏览器的方法,一个是前边使用quit()方法,另一个是close()方法 close():关闭当前窗口 quit():关闭所有窗口 quit()是关闭所有窗口,就不过多说了,测试一下close() from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver = webdriver.Chrome() driver.get("h
-
Python爬虫之Selenium实现窗口截图
前言:由程序去执行的操作不允许有任何误差,有些时候在测试的时候未出现问题,但是放到服务器上就会报错,而且打印的错误信息并不十分明确.这时,我在想如果在脚本执行出错的时候能对当前窗口截图保存,那么通过图片就可以非常直观地看出出错的原因.WebDriver提供了截图函数get_screenshot_as_file()来截取当前窗口. 本章中用到的关键方法如下: get_screenshot_as_file():截图 from selenium import webdriver driver = we
-
Python爬虫之Selenium设置元素等待的方法
一.显式等待 WebDriverWait类是由WebDirver 提供的等待方法.在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间检测不到则抛出异常(TimeoutException) from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from seleniu
-
Python爬虫中Selenium实现文件上传
前言:大部分的文件上传功能都是用input标签实现,这样就完全可以把它看作一个输入框,可以通过send_keys()指定文件进行上传了. 本章中用到的关键方法如下: send_keys():上传文件或者输入文本 from selenium import webdriver import time driver = webdriver.Chrome() driver.get('http://file.yiyuen.com/file/') # 定位上传按钮,添加本地文件 driver.find_el
-
Python爬虫之Selenium下拉框处理的实现
在我们浏览网页的时候经常会碰到下拉框,WebDriver提供了Select类来处理下拉框,详情请往下看: 本章中用到的关键方法如下: select_by_value():设置下拉框的值 switch_to.alert.accept():定位并接受现有警告框(详情请参考Python爬虫 - Selenium(9)警告框(弹窗)处理) click():鼠标点击事件(其他鼠标事件请参考Python爬虫 - Selenium(5)鼠标事件) move_to_element():鼠标悬停(详情请参考Pyt
-
Python爬虫之Selenium警告框(弹窗)处理
JavaScript 有三种弹窗 Alert (只有确定按钮), Confirmation (确定,取消等按钮), Prompt (有输入对话框),而且弹出的窗口是不能通过前端工具对其进行定位的,这个时候就可以通过switch_to.alert方法来定位这个弹窗,并进行一系列的操作. 本章中用到的关键方法如下: switch_to.alert:定位到警告框 text:获取警告框中的文字信息 accept():接受现有警告框(相当于确认) dismiss():解散现有警告框(相当于取消) send