Apache Hudi性能提升三倍的查询优化
目录
- 1. 背景
- 2. 设置
- 3. 测试
- 4. 结果
- 5. 总结
从 Hudi 0.10.0版本开始,我们很高兴推出在数据库领域中称为 Z-Order 和 Hilbert 空间填充曲线的高级数据布局优化技术的支持。
1. 背景
Amazon EMR 团队最近发表了一篇很不错的文章展示了对数据进行聚簇是如何提高查询性能的,为了更好地了解发生了什么以及它与空间填充曲线的关系,让我们仔细研究该文章的设置。
文章中比较了 2 个 Apache Hudi 表(均来自 Amazon Reviews 数据集):
未聚簇的 amazon_reviews 表(即数据尚未按任何特定键重新排序)
amazon_reviews_clustered 聚簇表。当数据被聚簇后,数据按字典顺序排列(这里我们将这种排序称为线性排序),排序列为star_rating、total_votes两列(见下图)

为了展示查询性能的改进,对这两个表执行以下查询:


这里要指出的重要考虑因素是查询指定了排序的两个列(star_rating 和 total_votes)。但不幸的是这是线性/词典排序的一个关键限制,如果添加更多列,排序的价值会会随之减少。

从上图可以看到,对于按字典顺序排列的 3 元组整数,只有第一列能够对所有具有相同值的记录具有关键的局部性属性:例如所有记录都具有以“开头的值” 1"、"2"、"3"(在第一列中)很好地聚簇在一起。但是如果尝试在第三列中查找所有值为"5"的值,会发现这些值现在分散在所有地方,根本没有局部性,过滤效果很差。
提高查询性能的关键因素是局部性:它使查询能够显着减少搜索空间和需要扫描、解析等的文件数量。
但是这是否意味着如果我们按表排序的列的第一个(或更准确地说是前缀)以外的任何内容进行过滤,我们的查询就注定要进行全面扫描?不完全是,局部性也是空间填充曲线在枚举多维空间时启用的属性(我们表中的记录可以表示为 N 维空间中的点,其中 N 是我们表中的列数)
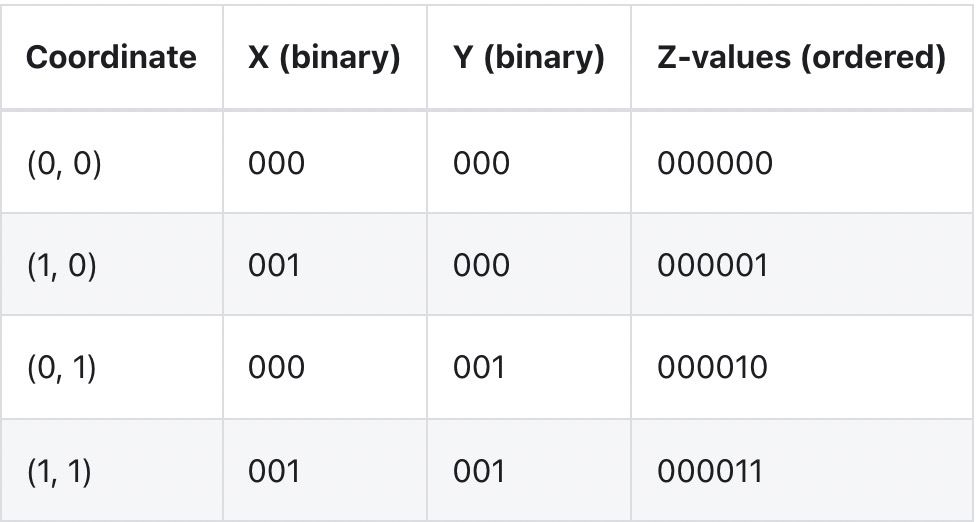
那么它是如何工作的?我们以 Z 曲线为例:拟合二维平面的 Z 阶曲线如下所示:

可以看到按照路径,不是简单地先按一个坐标 ("x") 排序,然后再按另一个坐标排序,它实际上是在对它们进行排序,就好像这些坐标的位已交织成单个值一样:
在线性排序的情况下局部性仅使用第一列相比,该方法的局部性使用到所有列。
以类似的方式,希尔伯特曲线允许将 N 维空间中的点(我们表中的行)映射到一维曲线上,基本上对它们进行排序,同时仍然保留局部性的关键属性,在此处阅读有关希尔伯特曲线的更多详细信息,到目前为止我们的实验表明,使用希尔伯特曲线对数据进行排序会有更好的聚簇和性能结果。
现在让我们来看看它的实际效果!
2. 设置
我们将再次使用 Amazon Reviews 数据集,但这次我们将使用 Hudi 按 product_id、customer_id 列元组进行 Z-Order排序,而不是聚簇或线性排序。
数据集不需要特别的准备,可以直接从 S3 中以 Parquet 格式下载并将其直接用作 Spark 将其摄取到 Hudi 表。
启动spark-shell
./bin/spark-shell --master 'local[4]' --driver-memory 8G --executor-memory 8G \ --jars ../../packaging/hudi-spark-bundle/target/hudi-spark3-bundle_2.12-0.10.0.jar \ --packages org.apache.spark:spark-avro_2.12:2.4.4 \ --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
导入Hudi表
import org.apache.hadoop.fs.{FileStatus, Path}
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.{DataSourceReadOptions, DataSourceWriteOptions}
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.common.fs.FSUtils
import org.apache.hudi.common.table.HoodieTableMetaClient
import org.apache.hudi.common.util.ClusteringUtils
import org.apache.hudi.config.HoodieClusteringConfig
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.spark.sql.DataFrame
import java.util.stream.Collectors
val layoutOptStrategy = "z-order"; // OR "hilbert"
val inputPath = s"file:///${System.getProperty("user.home")}/datasets/amazon_reviews_parquet"
val tableName = s"amazon_reviews_${layoutOptStrategy}"
val outputPath = s"file:///tmp/hudi/$tableName"
def safeTableName(s: String) = s.replace('-', '_')
val commonOpts =
Map(
"hoodie.compact.inline" -> "false",
"hoodie.bulk_insert.shuffle.parallelism" -> "10"
)
////////////////////////////////////////////////////////////////
// Writing to Hudi
////////////////////////////////////////////////////////////////
val df = spark.read.parquet(inputPath)
df.write.format("hudi")
.option(DataSourceWriteOptions.TABLE_TYPE.key(), COW_TABLE_TYPE_OPT_VAL)
.option("hoodie.table.name", tableName)
.option(PRECOMBINE_FIELD.key(), "review_id")
.option(RECORDKEY_FIELD.key(), "review_id")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD.key(), "product_category")
.option("hoodie.clustering.inline", "true")
.option("hoodie.clustering.inline.max.commits", "1")
// NOTE: Small file limit is intentionally kept _ABOVE_ target file-size max threshold for Clustering,
// to force re-clustering
.option("hoodie.clustering.plan.strategy.small.file.limit", String.valueOf(1024 * 1024 * 1024)) // 1Gb
.option("hoodie.clustering.plan.strategy.target.file.max.bytes", String.valueOf(128 * 1024 * 1024)) // 128Mb
// NOTE: We're increasing cap on number of file-groups produced as part of the Clustering run to be able to accommodate for the
// whole dataset (~33Gb)
.option("hoodie.clustering.plan.strategy.max.num.groups", String.valueOf(4096))
.option(HoodieClusteringConfig.LAYOUT_OPTIMIZE_ENABLE.key, "true")
.option(HoodieClusteringConfig.LAYOUT_OPTIMIZE_STRATEGY.key, layoutOptStrategy)
.option(HoodieClusteringConfig.PLAN_STRATEGY_SORT_COLUMNS.key, "product_id,customer_id")
.option(DataSourceWriteOptions.OPERATION.key(), DataSourceWriteOptions.BULK_INSERT_OPERATION_OPT_VAL)
.option(BULK_INSERT_SORT_MODE.key(), "NONE")
.options(commonOpts)
.mode(ErrorIfExists)
3. 测试
每个单独的测试请在单独的 spark-shell 中运行,以避免缓存影响测试结果。
////////////////////////////////////////////////////////////////
// Reading
///////////////////////////////////////////////////////////////
// Temp Table w/ Data Skipping DISABLED
val readDf: DataFrame =
spark.read.option(DataSourceReadOptions.ENABLE_DATA_SKIPPING.key(), "false").format("hudi").load(outputPath)
val rawSnapshotTableName = safeTableName(s"${tableName}_sql_snapshot")
readDf.createOrReplaceTempView(rawSnapshotTableName)
// Temp Table w/ Data Skipping ENABLED
val readDfSkip: DataFrame =
spark.read.option(DataSourceReadOptions.ENABLE_DATA_SKIPPING.key(), "true").format("hudi").load(outputPath)
val dataSkippingSnapshotTableName = safeTableName(s"${tableName}_sql_snapshot_skipping")
readDfSkip.createOrReplaceTempView(dataSkippingSnapshotTableName)
// Query 1: Total votes by product_category, for 6 months
def runQuery1(tableName: String) = {
// Query 1: Total votes by product_category, for 6 months
spark.sql(s"SELECT sum(total_votes), product_category FROM $tableName WHERE review_date > '2013-12-15' AND review_date < '2014-06-01' GROUP BY product_category").show()
}
// Query 2: Average star rating by product_id, for some product
def runQuery2(tableName: String) = {
spark.sql(s"SELECT avg(star_rating), product_id FROM $tableName WHERE product_id in ('B0184XC75U') GROUP BY product_id").show()
}
// Query 3: Count number of reviews by customer_id for some 5 customers
def runQuery3(tableName: String) = {
spark.sql(s"SELECT count(*) as num_reviews, customer_id FROM $tableName WHERE customer_id in ('53096570','10046284','53096576','10000196','21700145') GROUP BY customer_id").show()
}
//
// Query 1: Is a "wide" query and hence it's expected to touch a lot of files
//
scala> runQuery1(rawSnapshotTableName)
+----------------+--------------------+
|sum(total_votes)| product_category|
+----------------+--------------------+
| 1050944| PC|
| 867794| Kitchen|
| 1167489| Home|
| 927531| Wireless|
| 6861| Video|
| 39602| Digital_Video_Games|
| 954924|Digital_Video_Dow...|
| 81876| Luggage|
| 320536| Video_Games|
| 817679| Sports|
| 11451| Mobile_Electronics|
| 228739| Home_Entertainment|
| 3769269|Digital_Ebook_Pur...|
| 252273| Baby|
| 735042| Apparel|
| 49101| Major_Appliances|
| 484732| Grocery|
| 285682| Tools|
| 459980| Electronics|
| 454258| Outdoors|
+----------------+--------------------+
only showing top 20 rows
scala> runQuery1(dataSkippingSnapshotTableName)
+----------------+--------------------+
|sum(total_votes)| product_category|
+----------------+--------------------+
| 1050944| PC|
| 867794| Kitchen|
| 1167489| Home|
| 927531| Wireless|
| 6861| Video|
| 39602| Digital_Video_Games|
| 954924|Digital_Video_Dow...|
| 81876| Luggage|
| 320536| Video_Games|
| 817679| Sports|
| 11451| Mobile_Electronics|
| 228739| Home_Entertainment|
| 3769269|Digital_Ebook_Pur...|
| 252273| Baby|
| 735042| Apparel|
| 49101| Major_Appliances|
| 484732| Grocery|
| 285682| Tools|
| 459980| Electronics|
| 454258| Outdoors|
+----------------+--------------------+
only showing top 20 rows
//
// Query 2: Is a "pointwise" query and hence it's expected that data-skipping should substantially reduce number
// of files scanned (as compared to Baseline)
//
// NOTE: That Linear Ordering (as compared to Space-curve based on) will have similar effect on performance reducing
// total # of Parquet files scanned, since we're querying on the prefix of the ordering key
//
scala> runQuery2(rawSnapshotTableName)
+----------------+----------+
|avg(star_rating)|product_id|
+----------------+----------+
| 1.0|B0184XC75U|
+----------------+----------+
scala> runQuery2(dataSkippingSnapshotTableName)
+----------------+----------+
|avg(star_rating)|product_id|
+----------------+----------+
| 1.0|B0184XC75U|
+----------------+----------+
//
// Query 3: Similar to Q2, is a "pointwise" query, but querying other part of the ordering-key (product_id, customer_id)
// and hence it's expected that data-skipping should substantially reduce number of files scanned (as compared to Baseline, Linear Ordering).
//
// NOTE: That Linear Ordering (as compared to Space-curve based on) will _NOT_ have similar effect on performance reducing
// total # of Parquet files scanned, since we're NOT querying on the prefix of the ordering key
//
scala> runQuery3(rawSnapshotTableName)
+-----------+-----------+
|num_reviews|customer_id|
+-----------+-----------+
| 50| 53096570|
| 3| 53096576|
| 25| 10046284|
| 1| 10000196|
| 14| 21700145|
+-----------+-----------+
scala> runQuery3(dataSkippingSnapshotTableName)
+-----------+-----------+
|num_reviews|customer_id|
+-----------+-----------+
| 50| 53096570|
| 3| 53096576|
| 25| 10046284|
| 1| 10000196|
| 14| 21700145|
+-----------+-----------+
4. 结果
我们总结了以下的测试结果

可以看到多列线性排序对于按列(Q2、Q3)以外的列进行过滤的查询不是很有效,这与空间填充曲线(Z-order 和 Hilbert)形成了非常明显的对比,后者将查询时间加快多达 3倍 。值得注意的是性能提升在很大程度上取决于基础数据和查询,在我们内部数据的基准测试中,能够实现超过 11倍 的查询性能改进!
5. 总结
Apache Hudi v0.10 为开源带来了新的布局优化功能 Z-order 和 Hilbert。 使用这些行业领先的布局优化技术可以为用户查询带来显着的性能提升和成本节约!
以上就是Apache Hudi性能提升三倍的查询优化的详细内容,更多关于Apache Hudi查询优化的资料请关注我们其它相关文章!
相关推荐
-

Apache Hudi灵活的Payload机制硬核解析
1.摘要 Apache Hudi 的Payload是一种可扩展的数据处理机制,通过不同的Payload我们可以实现复杂场景的定制化数据写入方式,大大增加了数据处理的灵活性.Hudi Payload在写入和读取Hudi表时对数据进行去重.过滤.合并等操作的工具类,通过使用参数 "hoodie.datasource.write.payload.class"指定我们需要使用的Payload class.本文我们会深入探讨Hudi Payload的机制和不同Payload的区别及使用场景. 2
-
Apache Pulsar集群搭建部署详细过程
目录 一.集群组成说明 二.安装前置条件 三.ZooKeeper集群搭建 四.BookKeeper集群搭建 五.Broker集群搭建 六.docker安装pulsar-dashboard 一.集群组成说明 1.搭建Pulsar集群至少需要3个组件:ZooKeeper集群.BookKeeper集群和Broker集群(Broker是Pulsar的自身实例).这三个集群组件如下:ZooKeeper集群(3个ZooKeeper节点组成)Bookie集群(也称为BookKeeper集群,3个BookKee
-
Apache Tomcat如何高并发处理请求
目录 介绍 接收Socket请求 Socket请求轮询 请求具体处理 总结 参考: 介绍 作为常用的http协议服务器,tomcat应用非常广泛.tomcat也是遵循Servelt协议的,Servelt协议可以让服务器与真实服务逻辑代码进行解耦.各自只需要关注Servlet协议即可.对于tomcat是如何作为一个高性能的服务器的呢?你是不是也会有这样的疑问? tomcat是如何接收网络请求? 如何做到高性能的http协议服务器? tomcat从8.0往后开始使用了NIO非阻塞io模型,提高了吞吐
-
Vertica集成Apache Hudi重磅使用指南
目录 1. 摘要 2. Apache Hudi介绍 3. 环境准备 4. Vertica和Apache Hudi集成 4.1 在 Apache Spark 上配置 Apache Hudi 和 AWS S3 4.2 配置 Vertica 和 Apache HUDI 集成 4.3 如何让 Vertica 查看更改的数据 4.3.1 写入数据 4.3.2 更新数据 4.3.3 创建和查看数据的历史快照 1. 摘要 本文演示了使用外部表集成 Vertica 和 Apache Hudi. 在演示中我们使用
-
Apache Log4j2 报核弹级漏洞快速修复方法
Apache Log4j2 报核弹级漏洞,栈长的朋友圈都炸锅了,很多程序猿都熬到半夜紧急上线,昨晚你睡了吗?? Apache Log4j2 是一个基于Java的日志记录工具,是 Log4j 的升级,在其前身Log4j 1.x基础上提供了 Logback 中可用的很多优化,同时修复了Logback架构中的一些问题,是目前最优秀的 Java日志框架之一. 此次 Apache Log4j2 漏洞触发条件为只要外部用户输入的数据会被日志记录,即可造成远程代码执行. 影响版本 2.0 <= Apache
-
Apache log4j2-RCE 漏洞复现及修复建议(CVE-2021-44228)
目录 Apache log4j2-RCE 漏洞复现 0x01 漏洞简介 0x02 环境准备 0x03 漏洞验证(DNSLOG篇) 0x04 漏洞验证(远程代码执行弹计算器&记事本篇) 0x05 漏洞深度利用(反弹shell) 0x06 影响范围及排查方法 0x07 修复建议 0x08 涉及资源 Apache log4j2-RCE 漏洞复现 0x01 漏洞简介 Apache Log4j2是一个基于Java的日志记录工具.由于Apache Log4j2某些功能存在递归解析功能,攻击者可直接构造恶意请
-
Apache Hudi性能提升三倍的查询优化
目录 1. 背景 2. 设置 3. 测试 4. 结果 5. 总结 从 Hudi 0.10.0版本开始,我们很高兴推出在数据库领域中称为 Z-Order 和 Hilbert 空间填充曲线的高级数据布局优化技术的支持. 1. 背景 Amazon EMR 团队最近发表了一篇很不错的文章展示了对数据进行聚簇是如何提高查询性能的,为了更好地了解发生了什么以及它与空间填充曲线的关系,让我们仔细研究该文章的设置. 文章中比较了 2 个 Apache Hudi 表(均来自 Amazon Reviews 数据集)
-
Apache Hudi结合Flink的亿级数据入湖实践解析
目录 1. 实时数据落地需求演进 2. 基于Spark+Hudi的实时数据落地应用实践 3. 基于Flink自定义实时数据落地实践 4. 基于Flink + Hudi的落地数据实践 5. 后续应用规划及展望 5.1 取代离线报表,提高报表实时性及稳定性 5.2 完善监控体系,提升落数据任务稳定性 5.3 落数据中间过程可视化探索 本次分享分为5个部分介绍Apache Hudi的应用与实践 1. 实时数据落地需求演进 实时平台上线后,主要需求是开发实时报表,即抽取各类数据源做实时etl后,吐出实时
-
Apache Hudi基于华米科技应用湖仓一体化改造
目录 1. 应用背景及痛点介绍 2. 技术方案选型 3. 问题与解决方案 3.1.增量数据字段对齐问题 3.2 全球存储兼容性问题 3.3 云主机时区统一问题 3.4 升级新版本问题 3.5 多分区Upsert性能问题 3.6 数据特性适应问题 4. 上线收益 4.1 成本方面 4.2 效率方面 4.3 稳定性层面 4.4 查询性能层面 5. 总结与展望 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术.在华米科技,数据建设主要围绕两类数据:设备数据和
-
OnZoom基于Apache Hudi的一体架构实践解析
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创建.主持和盈利的活动,如健身课.音乐会.站立表演或即兴表演,以及Zoom会议平台上的音乐课程. 在OnZoom data platform中,source数据主要分为MySQL DB数据和Log数据. 其中Kafka数据通过Spark Streaming job实时消费,MySQL数据通过Spark
-
Apache Hudi基于华米科技应用湖仓一体化改造
目录 1. 应用背景及痛点介绍 2. 技术方案选型 3. 问题与解决方案 3.1.增量数据字段对齐问题 3.2 全球存储兼容性问题 3.3 云主机时区统一问题 3.4 升级新版本问题 3.5 多分区Upsert性能问题 3.6 数据特性适应问题 4. 上线收益 4.1 成本方面 4.2 效率方面 4.3 稳定性层面 4.4 查询性能层面 5. 总结与展望 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术.在华米科技,数据建设主要围绕两类数据:设备数据和
-
优化Apache服务器性能的方法小结
测试与提高性能 Apache服务器已经被设计得尽可能的快,即使你用一台配置不高的机器,用不着进行太复杂的设置,它的响应内容就足以塞满以前的各种窄带连接.但随网站内容日益复杂和带宽的增加,对Apache进行优化以取得更好的性能变得日益重要起来. 如果优化的结果仅仅是极小的性能提升那真是浪费时间.试想一下,你花了好几个小时甚至几天调整Apache的各种参数但结果仅是几个百分点的性能提升?因此,在优化前你做的第一步应该是测试你目前的服务器的性能水平以便决定如何优化你的服务器并衡量优化的效果. 关于对A
-
Apache Hudi数据布局黑科技降低一半查询时间
目录 1. 背景 2. Clustering架构 2.1 调度Clustering 2.2 运行Clustering 2.3 Clustering配置 3. 表查询性能 3.1 进行Clustering之前 3.2 进行Clustering之后 4. 总结 1. 背景 Apache Hudi将流处理带到大数据,相比传统批处理效率高一个数量级,提供了更新鲜的数据.在数据湖/仓库中,需要在摄取速度和查询性能之间进行权衡,数据摄取通常更喜欢小文件以改善并行性并使数据尽快可用于查询,但很多小文件会导致查
-
Apache Hudi异步Clustering部署操作的掌握
目录 1. 摘要 2. 介绍 3. Clustering策略 3.1 计划策略 3.2 执行策略 3.3 更新策略 4. 异步Clustering 4.1 HoodieClusteringJob 4.2 HoodieDeltaStreamer 4.3 Spark Structured Streaming 5. 总结和未来工作 1. 摘要 在之前的一篇博客中,我们介绍了Clustering(聚簇)的表服务来重新组织数据来提供更好的查询性能,而不用降低摄取速度,并且我们已经知道如何部署同步Clust
-
深入解析Apache Hudi内核文件标记机制
目录 1. 摘要 2. 为何引入Markers机制 3. 现有的直接标记机制及其局限性 4. 基于时间线服务器的标记机制提高写入性能 5. 标记相关的写入选项 6. 性能 7. 总结 1. 摘要 Hudi 支持在写入时自动清理未成功提交的数据.Apache Hudi 在写入时引入标记机制来有效跟踪写入存储的数据文件. 在本博客中,我们将深入探讨现有直接标记文件机制的设计,并解释了其在云存储(如 AWS S3.Aliyun OSS)上针对非常大批量写入的性能问题. 并且演示如何通过引入基于时间轴服
-
Apache Hudi异步Clustering部署操作的掌握
目录 1. 摘要 2. 介绍 3. Clustering策略 3.1 计划策略 3.2 执行策略 3.3 更新策略 4. 异步Clustering 4.1 HoodieClusteringJob 4.2 HoodieDeltaStreamer 4.3 Spark Structured Streaming 5. 总结和未来工作 1. 摘要 在之前的一篇博客中,我们介绍了Clustering(聚簇)的表服务来重新组织数据来提供更好的查询性能,而不用降低摄取速度,并且我们已经知道如何部署同步Clust