Scrapy框架介绍之Puppeteer渲染的使用
1、Scrapy框架
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted'twɪstɪd异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
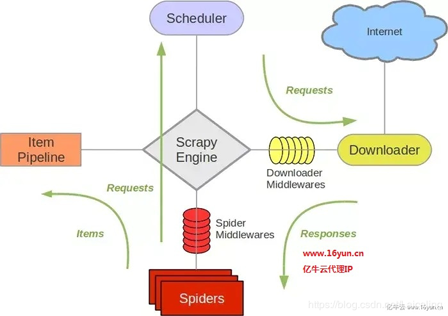
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
2、Puppeteer渲染
Puppeteer 是 Chrome 开发团队在 2017 年发布的一个 Node.js 包,用来模拟 Chrome 浏览器的运行。
为了爬取js渲染的html页面,我们需要用浏览器来解析js后生成html。在scrapy中可以利用pyppeteer来实现对应功能。
完整代码 📎scrapy-pyppeteer.zip
我们需要新建项目中middlewares.py文件(./项目名/middlewares.py)
import websockets
from scrapy.http import HtmlResponse
from logging import getLogger
import asyncio
import pyppeteer
import logging
from concurrent.futures._base import TimeoutError
import base64
import sys
import random
pyppeteer_level = logging.WARNING
logging.getLogger('websockets.protocol').setLevel(pyppeteer_level)
logging.getLogger('pyppeteer').setLevel(pyppeteer_level)
PY3 = sys.version_info[0] >= 3
def base64ify(bytes_or_str):
if PY3 and isinstance(bytes_or_str, str):
input_bytes = bytes_or_str.encode('utf8')
else:
input_bytes = bytes_or_str
output_bytes = base64.urlsafe_b64encode(input_bytes)
if PY3:
return output_bytes.decode('ascii')
else:
return output_bytes
class ProxyMiddleware(object):
USER_AGENT = open('useragents.txt').readlines()
def process_request(self, request, spider):
# 代理服务器
proxyHost = "t.16yun.cn"
proxyPort = "31111"
# 代理隧道验证信息
proxyUser = "username"
proxyPass = "password"
request.meta['proxy'] = "http://{0}:{1}".format(proxyHost, proxyPort)
# 添加验证头
encoded_user_pass = base64ify(proxyUser + ":" + proxyPass)
request.headers['Proxy-Authorization'] = 'Basic ' + encoded_user_pass
# 设置IP切换头(根据需求)
tunnel = random.randint(1, 10000)
request.headers['Proxy-Tunnel'] = str(tunnel)
request.headers['User-Agent'] = random.choice(self.USER_AGENT)
class PyppeteerMiddleware(object):
def __init__(self, **args):
"""
init logger, loop, browser
:param args:
"""
self.logger = getLogger(__name__)
self.loop = asyncio.get_event_loop()
self.browser = self.loop.run_until_complete(
pyppeteer.launch(headless=True))
self.args = args
def __del__(self):
"""
close loop
:return:
"""
self.loop.close()
def render(self, url, retries=1, script=None, wait=0.3, scrolldown=False, sleep=0,
timeout=8.0, keep_page=False):
"""
render page with pyppeteer
:param url: page url
:param retries: max retry times
:param script: js script to evaluate
:param wait: number of seconds to wait before loading the page, preventing timeouts
:param scrolldown: how many times to page down
:param sleep: how many long to sleep after initial render
:param timeout: the longest wait time, otherwise raise timeout error
:param keep_page: keep page not to be closed, browser object needed
:param browser: pyppetter browser object
:param with_result: return with js evaluation result
:return: content, [result]
"""
# define async render
async def async_render(url, script, scrolldown, sleep, wait, timeout, keep_page):
try:
# basic render
page = await self.browser.newPage()
await asyncio.sleep(wait)
response = await page.goto(url, options={'timeout': int(timeout * 1000)})
if response.status != 200:
return None, None, response.status
result = None
# evaluate with script
if script:
result = await page.evaluate(script)
# scroll down for {scrolldown} times
if scrolldown:
for _ in range(scrolldown):
await page._keyboard.down('PageDown')
await asyncio.sleep(sleep)
else:
await asyncio.sleep(sleep)
if scrolldown:
await page._keyboard.up('PageDown')
# get html of page
content = await page.content()
return content, result, response.status
except TimeoutError:
return None, None, 500
finally:
# if keep page, do not close it
if not keep_page:
await page.close()
content, result, status = [None] * 3
# retry for {retries} times
for i in range(retries):
if not content:
content, result, status = self.loop.run_until_complete(
async_render(url=url, script=script, sleep=sleep, wait=wait,
scrolldown=scrolldown, timeout=timeout, keep_page=keep_page))
else:
break
# if need to return js evaluation result
return content, result, status
def process_request(self, request, spider):
"""
:param request: request object
:param spider: spider object
:return: HtmlResponse
"""
if request.meta.get('render'):
try:
self.logger.debug('rendering %s', request.url)
html, result, status = self.render(request.url)
return HtmlResponse(url=request.url, body=html, request=request, encoding='utf-8',
status=status)
except websockets.exceptions.ConnectionClosed:
pass
@classmethod
def from_crawler(cls, crawler):
return cls(**crawler.settings.get('PYPPETEER_ARGS', {}))
然后修改项目配置文件 (./项目名/settings.py)
DOWNLOADER_MIDDLEWARES = {
'scrapypyppeteer.middlewares.PyppeteerMiddleware': 543,
'scrapypyppeteer.middlewares.ProxyMiddleware': 100,
}
然后我们运行程序

到此这篇关于Scrapy框架介绍之Puppeteer渲染的使用的文章就介绍到这了,更多相关Scrapy Puppeteer渲染内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Puppeteer 爬取动态生成的网页实战
Puppeteer 相关介绍与安装不过多介绍,可通过以下链接进行学习 一.Puppeteer 开源地址 英文文档 中文社区 二.爬取动态网页 1. 需求 首先,了解下我们的需求: 爬取zoomcharts文档中 Net Chart 目录下所有访问连接对应的页面,并保存到本地 2. 研究 ZoomCharts 文档页面结构 首先,我们得研究透 ZoomCharts 页面如何加载,以及左侧导航的 DOM 树结构,才好进行下一步操作 页面首次加载 页面首次加载,左侧导航第一个目录 Introducti
-
详解pyppeteer(python版puppeteer)基本使用
一.前言 以前使用selenium的无头浏览器,自从phantomjs2016后慢慢不更新了之后,selenium也开始找下家,这时候谷歌的chrome率先搞出来无头浏览器并开放了各种api,随后firefox也开始做. 现在selenium的测试也都支持这两个浏览器的无头模式了,只需要在引入的时候配置一下就可以了.之所以要采用谷歌chrome官方无头框架puppeteer的python版本pyppeteer,是因为有些网页是可以检测到是否是使用了selenium.并且selenium所谓的保护
-
Puppeteer环境搭建的详细步骤
简介 Puppeteer是Google开发并开源的一款工具,可用代码驱动浏览器操作. 由于诸多优秀的特性,Puppeteer常被用在爬虫与自动化测试上.详细介绍参见官方 README. Puppeteer本身是个NodeJS的库,自动化脚本也需要使用NodeJS编写,如果对JS不了解建议先学习JavaScript基础语法,或者使用Selenium等其他工具去实现. 对于一个陌生的工具,应当先检查是否适合自己,再去尝试使用,切莫盲目从众. Puppeteer 用处 利用网页生成PDF.图片 爬取S
-
使用puppeteer破解极验的滑动验证码
基本的流程: 1. 打开前端网,点击登录. 2. 填写账号,密码. 3. 点解验证按钮,通过滑动验证,最后成功登陆. 代码实现: github上可以checkout. 具体代码如下所示: run.js const puppeteer = require('puppeteer'); const devices = require('puppeteer/DeviceDescriptors'); const iPhone = devices['iPhone 6 Plus']; let timeout
-
详解Puppeteer 入门教程
1.Puppeteer 简介 Puppeteer 是一个node库,他提供了一组用来操纵Chrome的API, 通俗来说就是一个 headless chrome浏览器 (当然你也可以配置成有UI的,默认是没有的).既然是浏览器,那么我们手工可以在浏览器上做的事情 Puppeteer 都能胜任, 另外,Puppeteer 翻译成中文是"木偶"意思,所以听名字就知道,操纵起来很方便,你可以很方便的操纵她去实现: 1) 生成网页截图或者 PDF 2) 高级爬虫,可以爬取大量异步渲染内容的网页
-
Scrapy框架介绍之Puppeteer渲染的使用
1.Scrapy框架 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便. Scrapy 使用了 Twisted'twɪstɪd异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求. Scrapy Engine(引擎): 负责Spider.ItemPipeline.Do
-

Scrapy框架CrawlSpiders的介绍以及使用详解
在Scrapy基础--Spider中,我简要地说了一下Spider类.Spider基本上能做很多事情了,但是如果你想爬取知乎或者是简书全站的话,你可能需要一个更强大的武器.CrawlSpider基于Spider,但是可以说是为全站爬取而生. CrawlSpiders是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则(rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合. 一.我们先
-
python入门之scrapy框架中Request对象和Response对象的介绍
目录 一.Request对象 二.发送POST请求 三.Response对象 一.Request对象 Request对象主要是用来请求数据,爬取一页的数据重新发送一个请求的时候调用,其源码类的位置如 下图所示: 这里给出其的源码,该方法有很多参数: class Request(object_ref): def __init__(self, url, callback=None, method='GET', headers=None, body=None,
-
scrapy爬虫遇到js动态渲染问题
目录 一.传统爬虫的问题 1.实际案例 二.scrapy解决动态网页渲染问题的策略 三.安装使用scrapy-splash 1.安装Docker 2.安装splash镜像 3.安装scrapy-splash 四.项目实践 五.总结与思考 一.传统爬虫的问题 scrapy爬虫与传统爬虫一样,都是通过访问服务器端的网页,获取网页内容,最终都是通过对于网页内容的分析来获取数据,这样的弊端就在于他更适用于静态网页的爬取,而面对js渲染的动态网页就有点力不从心了,因为通过js渲染出来的动态网页的内容与网页
-
Python:Scrapy框架中Item Pipeline组件使用详解
Item Pipeline简介 Item管道的主要责任是负责处理有蜘蛛从网页中抽取的Item,他的主要任务是清晰.验证和存储数据. 当页面被蜘蛛解析后,将被发送到Item管道,并经过几个特定的次序处理数据. 每个Item管道的组件都是有一个简单的方法组成的Python类. 他们获取了Item并执行他们的方法,同时他们还需要确定的是是否需要在Item管道中继续执行下一步或是直接丢弃掉不处理. Item管道通常执行的过程有 清理HTML数据 验证解析到的数据(检查Item是否包含必要的字段) 检查是
-
浅谈Scrapy框架普通反爬虫机制的应对策略
简单低级的爬虫速度快,伪装度低,如果没有反爬机制,它们可以很快的抓取大量数据,甚至因为请求过多,造成服务器不能正常工作.而伪装度高的爬虫爬取速度慢,对服务器造成的负担也相对较小. 爬虫与反爬虫,这相爱相杀的一对,简直可以写出一部壮观的斗争史.而在大数据时代,数据就是金钱,很多企业都为自己的网站运用了反爬虫机制,防止网页上的数据被爬虫爬走.然而,如果反爬机制过于严格,可能会误伤到真正的用户请求;如果既要和爬虫死磕,又要保证很低的误伤率,那么又会加大研发的成本. 简单低级的爬虫速度快,伪装度低,如果
-
Python利用Scrapy框架爬取豆瓣电影示例
本文实例讲述了Python利用Scrapy框架爬取豆瓣电影.分享给大家供大家参考,具体如下: 1.概念 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包 pip install scrapy scrapy的组成结构如下图所示 引擎Scrapy Engine,用于中转调度其他部分的信号和数据
-
scrapy框架携带cookie访问淘宝购物车功能的实现代码
scrapy框架简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便 scrapy架构图 crapy Engine(引擎): 负责Spider.ItemPipeline.Downloader.Scheduler中间的通讯,信号.数据传递等. Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整
-
Python爬虫Scrapy框架CrawlSpider原理及使用案例
提问:如果想要通过爬虫程序去爬取"糗百"全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpider的自动爬去进行实现(更加简洁和高效) 一.简单介绍CrawlSpider CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能.其中最显著的功能就是"LinkExtractors链接提取器&qu
-
Python爬虫scrapy框架Cookie池(微博Cookie池)的使用
下载代码Cookie池(这里主要是微博登录,也可以自己配置置其他的站点网址) 下载代码GitHub:https://github.com/Python3WebSpider/CookiesPool 下载安装过后注意看网页下面的相关基础配置和操作!!!!!!!!!!!!! 自己的设置主要有下面几步: 1.配置其他设置 2.设置使用的浏览器 3.设置模拟登陆 源码cookies.py的修改(以下两处不修改可能会产生bug): 4.获取cookie 随机获取Cookies: http://localho