Yolov5训练意外中断后如何接续训练详解
目录
- 1.配置环境
- 2.问题描述
- 3.解决方法
- 3.1设置需要接续训练的结果
- 3.2设置训练代码
- 4.原理
- 5.结束语
1.配置环境
操作系统:Ubuntu20.04
CUDA版本:11.4
Pytorch版本:1.9.0
TorchVision版本:0.7.0
IDE:PyCharm
硬件:RTX2070S*2
2.问题描述
在训练YOLOv5时由于数据集很大导致训练时间十分漫长,这期间Python、主机等可能遇到死机的情况,如果需要训练300个epoch但是训练一晚后发现在200epoch时停下是十分崩溃了,好在博主摸索到在yolov5中接续训练的方法了。
3.解决方法
首先直接上方法
3.1设置需要接续训练的结果
如果你想从上一次训练结果中回复训练,那么首先保证你的训练结果(一般都存放在/runs/train目录下)在保存目录中代号为最大的。
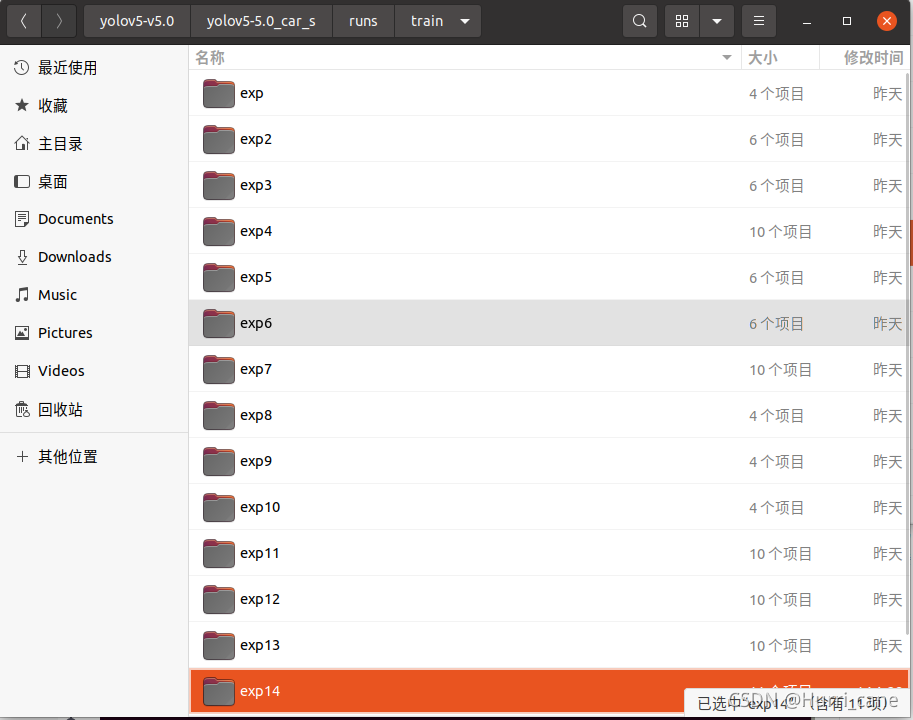
如上图所示,在train文件夹下一共有14个训练结果,假设我的第12次训练中断了,想接着第12次的结果继续训练,那么只需要将比12更大的:exp13、exp14这两个文件夹删除或者移动到其他地方,这样便设置好了需要接续训练的结果。
3.2设置训练代码
代码见yolov5代码中的train.py
if __name__ == '__main__':
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='../weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='./models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/car.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=32, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='1', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args()
注意上面patser中第9个参数resume,将其设置为default=True即可,也就是那一行代码改变为
parser.add_argument('--resume', nargs='?', const=True, default=True, help='resume most recent training')
接下来运行python train.py边不会产生新的exp而是在最新的exp上接续训练
如下图所示:
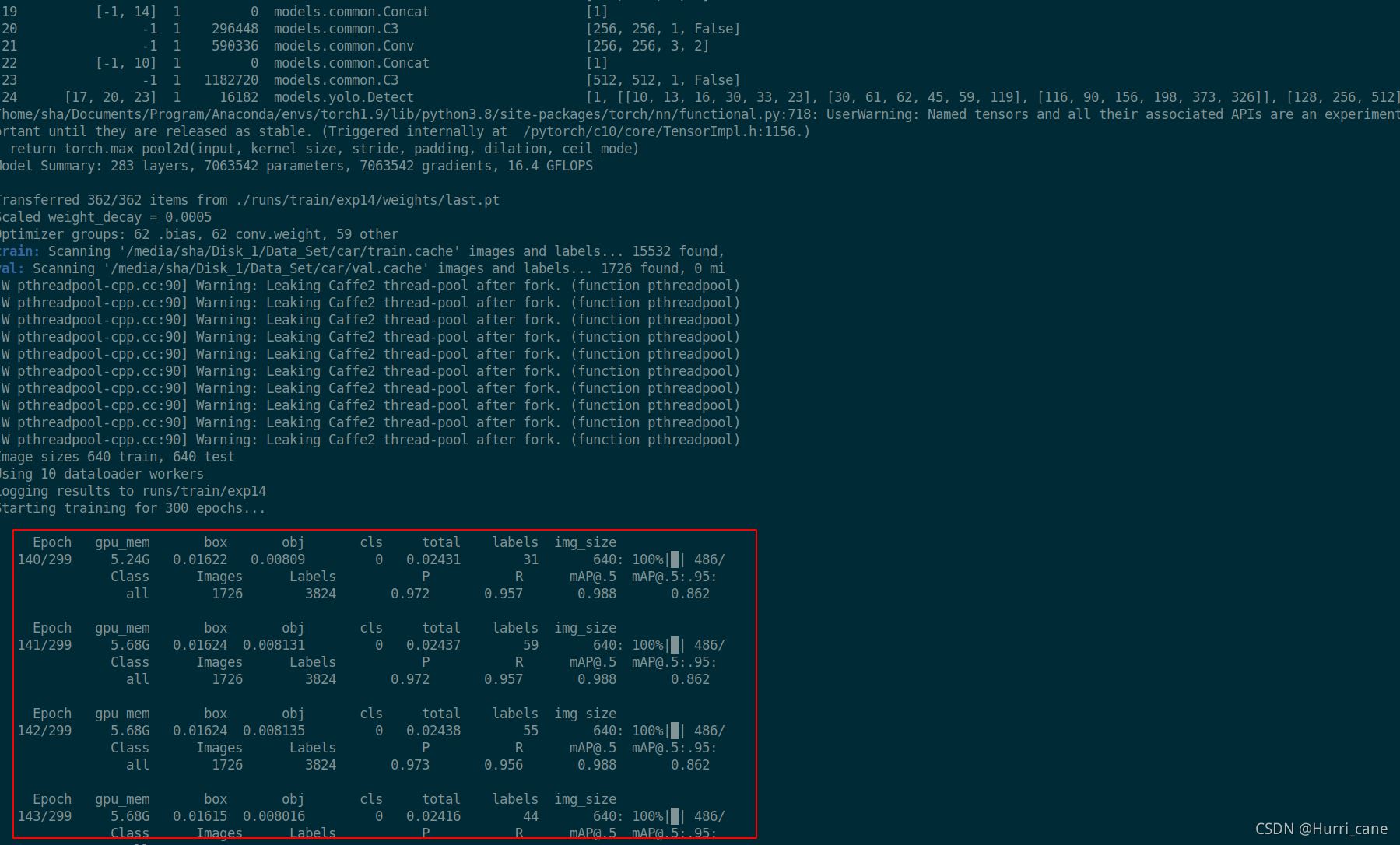
博主运行完python train.py后便是接着上一次训练完139个epoch继续训练
4.原理
其实接续训练不是什么深奥内容 ,博主在训练自己模型的时候也早会使用。
我们在使用yolov5提供的权重,也就是像yolov5s.pt之类的文件时就是使用了官方提供的模型接续训练的。
我们每次训练模型时都会生成新的模型结果,存放在/runs/train/expxxx/weights下,接续训练就是将上次训练一半得到的结果拿来和模型结合进行训练。具体来说:如果最终训练目标是300个epoch,上次训练完了139个epoch,那么就是将第139个epoch得到的权重载入到模型中再训练161个epoch便可等效为训练了300个epoch
5.结束语
到此这篇关于Yolov5训练意外中断后如何接续训练的文章就介绍到这了,更多相关Yolov5训练中断接续训练内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

yolov5 win10 CPU与GPU环境搭建过程
前言 最近实习任务为黑烟检测,想起了可以尝试用yolov5来跑下,之前一直都是用的RCNN系列,这次就试试yolo系列. 一.安装pytorch 1.创建新的环境 打开Anaconda Prompt命令行输入 创建一个新环境,并激活进入环境. # 创建了名叫yolov5的,python版本为3.8的新环境 conda create -n yolov5 python=3.8 # 激活名叫yolov5的环境 conda activate yolov5 2.下载YOLOv5 github项目 下载地址
-
win10+anaconda安装yolov5的方法及问题解决方案
对于yolo系列,应用广泛,在win10端也有很大的应用需求,所以这篇文章给出win10环境下的安装教程. 先给出系列文章win10+anacnda实现yolov3 YOLOV5-3.0/3.1版本 版本问题 python 3.7 torch 1.6.0 torchvision 0.7.0 cuda 10.1 注意:Yolov5-3.1只能使用torch 1.6.0 1.在网站下载对应版本的torch和torchvision的whl文件 https://download.pytorch.org/
-
Yolov5训练意外中断后如何接续训练详解
目录 1.配置环境 2.问题描述 3.解决方法 3.1设置需要接续训练的结果 3.2设置训练代码 4.原理 5.结束语 1.配置环境 操作系统:Ubuntu20.04 CUDA版本:11.4 Pytorch版本:1.9.0 TorchVision版本:0.7.0 IDE:PyCharm 硬件:RTX2070S*2 2.问题描述 在训练YOLOv5时由于数据集很大导致训练时间十分漫长,这期间Python.主机等可能遇到死机的情况,如果需要训练300个epoch但是训练一晚后发现在200epoch时
-
YOLOv5构建安全帽检测和识别系统使用详解
目录 引言 准备工作 安装YOLOv5 训练模型 测试模型 实际部署 总结 引言 在这篇文章中,我将介绍如何使用YOLOv5构建一个佩戴安全帽检测和识别系统.这个系统可以实时检测图像上人物是否有未佩戴安全帽,并及时进行警告.文章将介绍系统的设计过程,包括YOLOv5的训练.测试代码以及实际部署思路. 准备工作 首先,我们需要收集和准备数据集.数据集应包含各种场景.角度和光照条件下戴安全帽和不戴安全帽的员工照片.我们可以从互联网上收集这些图片,也可以在实际工地上拍摄.收集到足够数量的图片后,我们需
-
C++中约数定理的实例详解
C++中约数定理的实例详解 对于一个大于1正整数n可以分解质因数:n = p1^a1*p2^a2*......pk^ak,则n的正约数的个数就是 :(a1+1)*(a2+1)*......*(ak+1) 其中a1.a2.a3-ak是p1.p2.p3,-pk的指数. 用这个定理求一个数的约数个数是非常快的,贴出一道训练题目: hdu 1492 -求约数的个数 贴出代码: //约数定理的 #include <iostream> #include <algorithm> #includ
-
对pytorch中的梯度更新方法详解
背景 使用pytorch时,有一个yolov3的bug,我认为涉及到学习率的调整.收集到tencent yolov3和mxnet开源的yolov3,两个优化器中的学习率设置不一样,而且使用GPU数目和batch的更新也不太一样.据此,我简单的了解了下pytorch的权重梯度的更新策略,看看能否一窥究竟. 对代码说明 共三个实验,分布写在代码中的(一)(二)(三)三个地方.运行实验时注释掉其他两个 实验及其结果 实验(三): 不使用zero_grad()时,grad累加在一起,官网是使用accum
-
Python3爬虫中关于中文分词的详解
原理 中文分词,即 Chinese Word Segmentation,即将一个汉字序列进行切分,得到一个个单独的词.表面上看,分词其实就是那么回事,但分词效果好不好对信息检索.实验结果还是有很大影响的,同时分词的背后其实是涉及各种各样的算法的. 中文分词与英文分词有很大的不同,对英文而言,一个单词就是一个词,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,需要人为切分.根据其特点,可以把分词算法分为四大类: ·基于规则的分词方法 ·基于统计的分词方法 ·基于语义的分词方法 ·基于理解
-
Python类中的装饰器在当前类中的声明与调用详解
我的Python环境:3.7 在Python类里声明一个装饰器,并在这个类里调用这个装饰器. 代码如下: class Test(): xx = False def __init__(self): pass def test(func): def wrapper(self, *args, **kwargs): print(self.xx) return func(self, *args, **kwargs) return wrapper @test def test_a(self,a,b): pr
-
Go语言中的数据竞争模式详解
目录 前言 Go在goroutine中通过引用来透明地捕获自由变量 切片会产生难以诊断的数据竞争 并发访问Go内置的.不安全的线程映射会导致频繁的数据竞争 Go开发人员常在pass-by-value时犯错并导致non-trivial的数据竞争 消息传递(通道)和共享内存的混合使用使代码变得复杂且易受数据竞争的影响 Add和Done方法的错误放置会导致数据竞争 并发运行测试会导致产品或测试代码中的数据竞争 小结 前言 本文主要基于在Uber的Go monorepo中发现的各种数据竞争模式,分析了其
-
基于python中的TCP及UDP(详解)
python中是通过套接字即socket来实现UDP及TCP通信的.有两种套接字面向连接的及无连接的,也就是TCP套接字及UDP套接字. TCP通信模型 创建TCP服务器 伪代码: ss = socket() # 创建服务器套接字 ss.bind() # 套接字与地址绑定 ss.listen() # 监听连接 inf_loop: # 服务器无限循环 cs = ss.accept() # 接受客户端连接 comm_loop: # 通信循环 cs.recv()/cs.send() # 对话(接收/发
-
Oracle中游标Cursor基本用法详解
查询 SELECT语句用于从数据库中查询数据,当在PL/SQL中使用SELECT语句时,要与INTO子句一起使用,查询的 返回值被赋予INTO子句中的变量,变量的声明是在DELCARE中.SELECT INTO语法如下: SELECT [DISTICT|ALL]{*|column[,column,...]} INTO (variable[,variable,...] |record) FROM {table|(sub-query)}[alias] WHERE............ PL/SQL
-
JDBC中resutset接口操作实例详解
本文主要向大家展示JDBC接口中resutset接口的用法实例,下面我们看看具体内容. 1. ResultSet细节1 功能:封锁结果集数据 操作:如何获得(取出)结果 package com.sjx.a; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; import org.junit.Test; //1. next方