通过底层源码理解YOLOv5的Backbone
目录
- YOLOv5的Backbone设计
- 1 Backbone概览及参数
- 1.1 Param
- 1.2 backbone
- 1.3 Exp
- 2 Backbone组成
- 3.1 CBS
- 3.2 CSP/C3
- 3.2.1 CSP结构
- 3.2.2 Bottleneck
- 3.3 SSPF
- YOLOv5s的Backbone总览
- 总结
YOLOv5的Backbone设计
在上一篇文章《YOLOV5的anchor设定》中我们讨论了anchor的产生原理和检测过程,对YOLOv5的网络结构有了大致的了解。接下来,我们将聚焦于YOLOv5的Backbone,深入到底层源码中体会v5的Backbone设计。
1 Backbone概览及参数
# Parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple # YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ]
yolov5s的backbone部分如上,其网络结构使用yaml文件配置,通过./models/yolo.py解析文件加了一个输入构成的网络模块。与v3和v4所使用的config设置的网络不同,yaml文件中的网络组件不需要进行叠加,只需要在配置文件中设置number即可。
1.1 Param
# Parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple
nc: 8
代表数据集中的类别数目,例如MNIST中含有0-9共10个类.
depth_multiple: 0.33
用来控制模型的深度,仅在number≠1时启用。 如第一个C3层(c3具体是什么后续介绍)的参数设置为[-1, 3, C3, [128]],其中number=3,表示在v5s中含有1个C3(3*0.33);同理,v5l中的C3个数就是3(v5l的depth_multiple参数为1)。
width_multiple: 0.50
用来控制模型的宽度,主要作用于args中的ch_out。如第一个Conv层,ch_out=64,那么在v5s实际运算过程中,会将卷积过程中的卷积核设为64x0.5,所以会输出32通道的特征图。
1.2 backbone
# YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ]
- from:-n代表是从前n层获得的输入,如-1表示从前一层获得输入
- number:表示网络模块的数目,如[-1, 3, C3, [128]]表示含有3个C3模块
- model:表示网络模块的名称,具体细节可以在./models/common.py查看,如Conv、C3、SPPF都是已经在common中定义好的模块
- args:表示向不同模块内传递的参数,即[ch_out, kernel, stride, padding, groups],这里连ch_in都省去了,因为输入都是上层的输出(初始ch_in为3)。为了修改过于麻烦,这里输入的获取是从./models/yolo.py的def parse_model(md, ch)函数中解析得到的。
1.3 Exp
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
input:3x640x640
[ch_out, kernel, stride, padding]=[64, 6, 2, 2]
故新的通道数为64x0.5=32
根据特征图计算公式:Feature_new=(Feature_old-kernel+2xpadding)/stride+1可得:
新的特征图尺寸为:Feature_new=(640-6+2x2)/2+1=320
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
input:32x320x320
[ch_out, kernel, stride]=[128, 3, 2]
同理可得:新的通道数为64,新的特征图尺寸为160
2 Backbone组成
v6.0版本的Backbone去除了Focus模块(便于模型导出部署),Backbone主要由CBL、BottleneckCSP/C3以及SPP/SPPF等组成,具体如下图所示:

3.1 CBS

CBS模块其实没什么好稀奇的,就是Conv+BatchNorm+SiLU,这里着重讲一下Conv的参数,就当复习pytorch的卷积操作了,先上CBL源码:
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
#其中nn.Identity()是网络中的占位符,并没有实际操作,在增减网络过程中,可以使得整个网络层数据不变,便于迁移权重数据;nn.SiLU()一种激活函数(S形加权线性单元)。
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):#正态分布型的前向传播
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):#普通前向传播
return self.act(self.conv(x))
由源码可知:Conv()包含7个参数,这些参数也是二维卷积Conv2d()中的重要参数。ch_in, ch_out, kernel, stride没什么好说的,展开说一下后三个参数:
padding
从我现在看到的主流卷积操作来看,大多数的研究者不会通过kernel来改变特征图的尺寸,如googlenet中3x3的kernel设定了padding=1,所以当kernel≠1时需要对输入特征图进行填充。当指定p值时按照p值进行填充,当p值为默认时则通过autopad函数进行填充:
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
#如果k是整数,p为k与2整除后向下取整;如果k是列表等,p对应的是列表中每个元素整除2。
return p
这里作者考虑到对不同的卷积操作使用不同大小的卷积核时padding也需要做出改变,所以这里在为p赋值时会首先检查k是否为int,如果k为列表则对列表中的每个元素整除。
groups
代表分组卷积,如下图所示
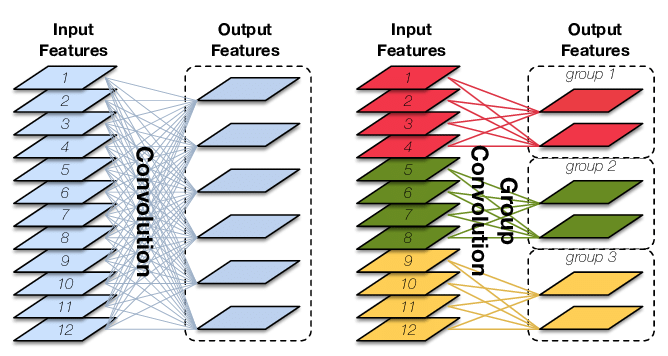
groups – Number of blocked connections from input channels to output
- At groups=1, all inputs are convolved to all outputs.
- At groups=2, the operation becomes equivalent to having two conv layers side by side, each seeing half the input channels, and producing half the output channels, and both subsequently concatenated.
- At groups= in_channels, each input channel is convolved with its own set of filters, of size: ⌊(out_channels)/(in_channels)⌋.
act
决定是否对特征图进行激活操作,SiLU表示使用Sigmoid进行激活。
one more thing:dilation
Conv2d中还有一个重要的参数就是空洞卷积dilation,通俗解释就是控制kernel点(卷积核点)间距的参数,通过改变卷积核间距实现特征图及特征信息的保留,在语义分割任务中空洞卷积比较有效。
3.2 CSP/C3
CSP即backbone中的C3,因为在backbone中C3存在shortcut,而在neck中C3不使用shortcut,所以backbone中的C3层使用CSP1_x表示,neck中的C3使用CSP2_x表示。
3.2.1 CSP结构
接下来让我们来好好梳理一下backbone中的C3层的模块组成。先上源码:
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
从源码中可以看出:输入特征图一条分支先经过.cv1,再经过.m,得到子特征图1;另一分支经过.cv2后得到子特征图2。最后将子特征图1和子特征图2拼接后输入.cv3得到C3层的输出,如下图所示。 这里的CV操作容易理解,就是前面的Conv2d+BN+SiLU,关键是.m操作。
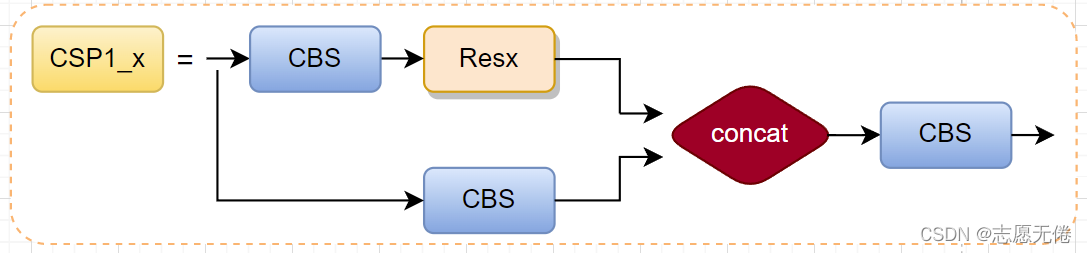
.m操作使用nn.Sequential将多个Bottleneck(图示中我以Resx命名)串接到网络中,for loop中的n即网络配置文件args中的number,也就是将number×depth_multiple个Bottleneck串接到网络中。那么,Bottleneck又是个什么玩意呢?
3.2.2 Bottleneck
要想了解Bottleneck,还要从Resnet说起。在Resnet出现之前,人们的普遍为网络越深获取信息也越多,模型泛化效果越好。然而随后大量的研究表明,网络深度到达一定的程度后,模型的准确率反而大大降低。这并不是过拟合造成的,而是由于反向传播过程中的梯度爆炸和梯度消失。也就是说,网络越深,模型越难优化,而不是学习不到更多的特征。
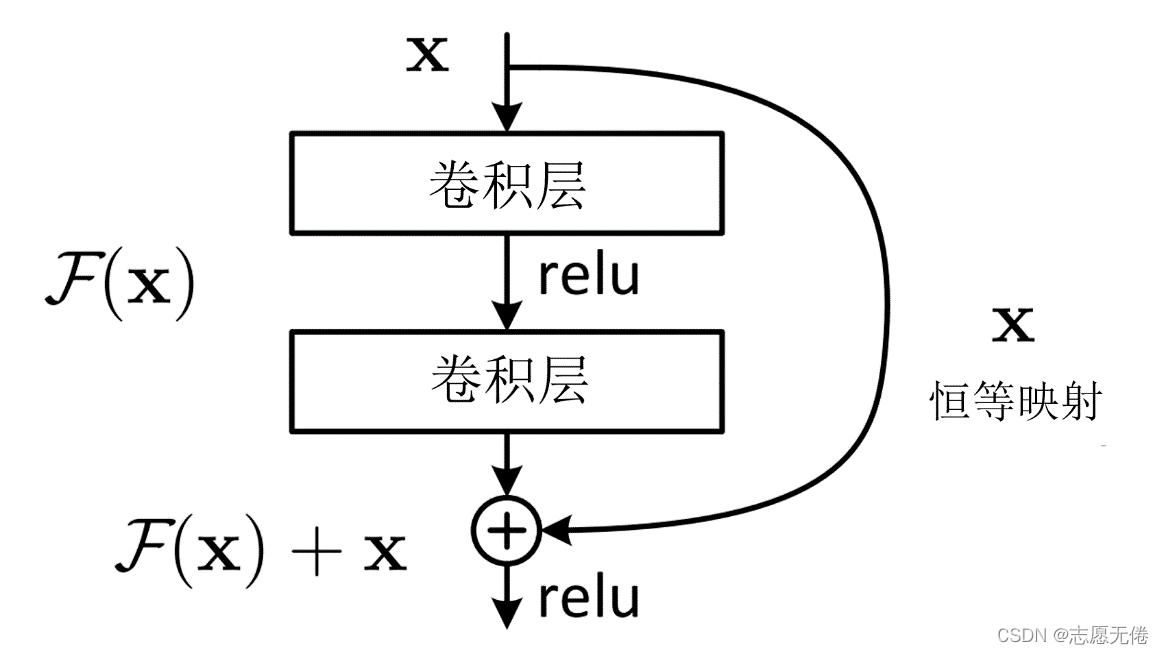
为了能让深层次的网络模型达到更好的训练效果,残差网络中提出的残差映射替换了以往的基础映射。对于输入x,期望输出H(x),网络利用恒等映射将x作为初始结果,将原来的映射关系变成F(x)+x。与其让多层卷积去近似估计H(x) ,不如近似估计H(x)-x,即近似估计残差F(x)。因此,ResNet相当于将学习目标改变为目标值H(x)和x的差值,后面的训练目标就是要将残差结果逼近于0。
残差模块有什么好处呢?
1.梯度弥散方面。加入ResNet中的shortcut结构之后,在反传时,每两个block之间不仅传递了梯度,还加上了求导之前的梯度,这相当于把每一个block中向前传递的梯度人为加大了,也就会减小梯度弥散的可能性。
2.特征冗余方面。正向卷积时,对每一层做卷积其实只提取了图像的一部分信息,这样一来,越到深层,原始图像信息的丢失越严重,而仅仅是对原始图像中的一小部分特征做提取。这显然会发生类似欠拟合的现象。加入shortcut结构,相当于在每个block中又加入了上一层图像的全部信息,一定程度上保留了更多的原始信息。
在resnet中,人们可以使用带有shortcut的残差模块搭建几百层甚至上千层的网络,而浅层的残差模块被命名为Basicblock(18、34),深层网络所使用的的残差模块,就被命名为了Bottleneck(50+)。
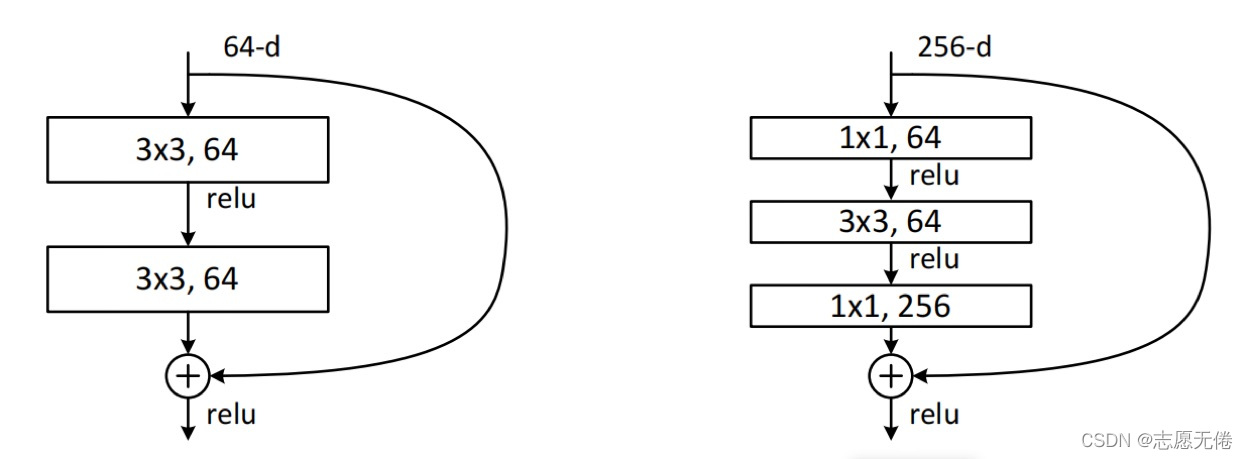
Bottleneck与Basicblock最大的区别是卷积核的组成。 Basicblock由两个3x3的卷积层组成,Bottleneck由两个1x1卷积层夹一个3x3卷积层组成:其中1x1卷积层降维后再恢复维数,让3x3卷积在计算过程中的参数量更少、速度更快。
第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
Bottleneck减少了参数量,优化了计算,保持了原有的精度。
说了这么多,都是为了给CSP中的Bottleneck做前情提要,我们再回头看CSP中的Bottleneck其实就更清楚了:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
可以看到,CSP中的Bottleneck同resnet模块中的类似,先是1x1的卷积层(CBS),然后再是3x3的卷积层,最后通过shortcut与初始输入相加。但是这里与resnet的不通点在于:CSP将输入维度减半运算后并未再使用1x1卷积核进行升维,而是将原始输入x也降了维,采取concat的方法进行张量的拼接,得到与原始输入相同维度的输出。其实这里能区分一点就够了:resnet中的shortcut通过add实现,是特征图对应位置相加而通道数不变;而CSP中的shortcut通过concat实现,是通道数的增加。二者虽然都是信息融合的主要方式,但是对张量的具体操作又不相同.
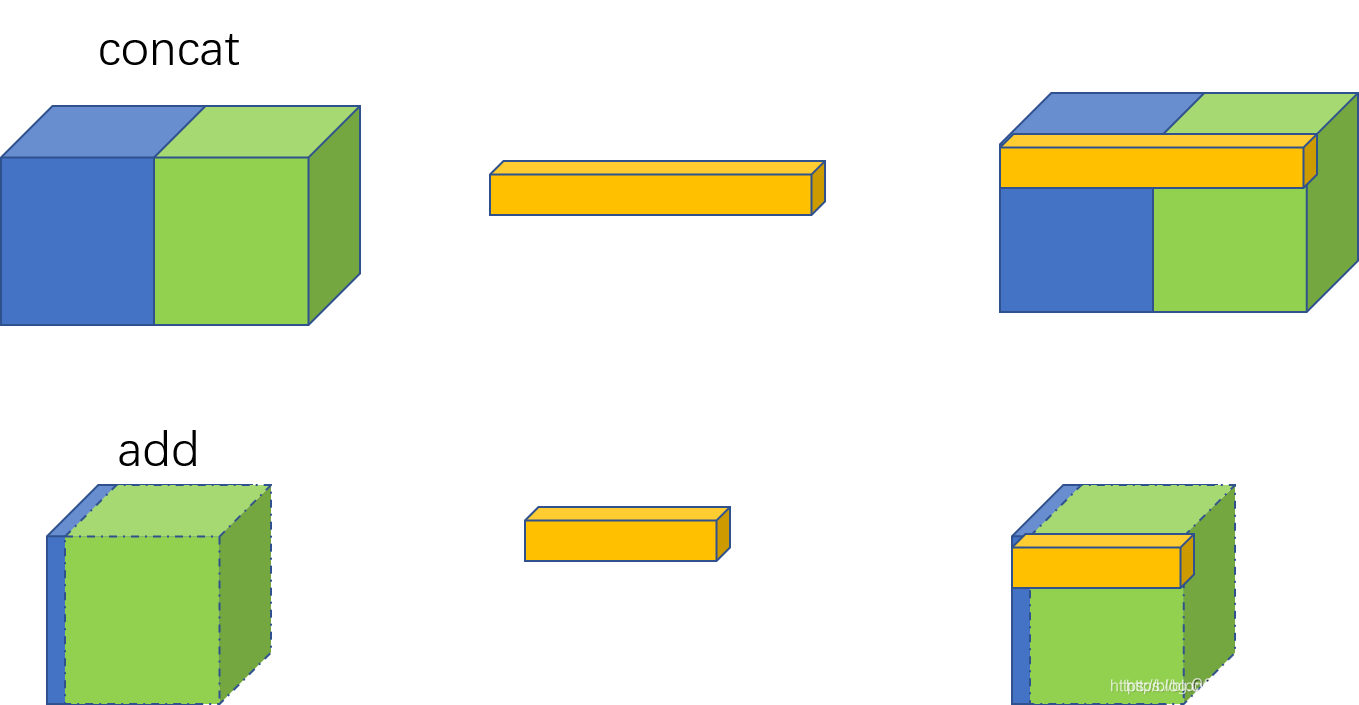
其次,对于shortcut是可根据任务要求设置的,比如在backbone中shortcut=True,neck中shortcut=False。
当shortcut=True时,Resx如图:

当shortcut=False时,Resx如图:

这其实也是YOLOv5为人称赞的地方,代码更体系、代码冗余更少,仅需要指定一个参数便可以将Bottleneck和普通卷积联合在一起使用,减少了代码量的同时也使整体感观得到提升。
3.3 SSPF
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
SSPF模块将经过CBS的x、一次池化后的y1、两次池化后的y2和3次池化后的self.m(y2)先进行拼接,然后再CBS提取特征。 仔细观察不难发现,虽然SSPF对特征图进行了多次池化,但是特征图尺寸并未发生变化,通道数更不会变化,所以后续的4个输出能够在channel维度进行融合。这一模块的主要作用是对高层特征进行提取并融合,在融合的过程中作者多次运用最大池化,尽可能多的去提取高层次的语义特征。

YOLOv5s的Backbone总览
最后,结合上述的讲解应该就不难理解v5s的backbone了

总结
到此这篇关于通过底层源码理解YOLOv5中Backbone的文章就介绍到这了,更多相关YOLOv5 Backbone详解内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Pytorch搭建YoloV5目标检测平台实现过程
目录 学习前言 源码下载 YoloV5改进的部分(不完全) YoloV5实现思路 一.整体结构解析 二.网络结构解析 2.构建FPN特征金字塔进行加强特征提取 三.预测结果的解码 1.获得预测框与得分 2.得分筛选与非极大抑制 四.训练部分 1.计算loss所需内容 2.正样本的匹配过程 a.匹配先验框 b.匹配特征点 3.计算Loss 训练自己的YoloV5模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 学习前言 这个很久都没有学,最终还是决定看看,复现的是Yol
-
Yolov5服务器环境搭建详细过程
目录 1 服务器搭建yolov5环境 1.1 创建环境 1.2 跟随官方指引 2 下载预训练权重 3 推理 4 测试 1 服务器搭建yolov5环境 1.1 创建环境 首先先的在本地环境下搭建一个我们的环境,名字设为yolo5-6 conda create -n yolov5-6 python=3.7#创建环境 conda activate yolov5-6#切换yolov5-6环境 创建包完成后,我们需要查看conda环境下是否有我们刚才创建的环境,通过以下的指令可以查看所有的环境. cond
-
Qt结合OpenCV部署yolov5的实现
目录 一.新建项目 UI设计 二.代码部分 mainwindow 类 三.效果演示 分别使用了openvino,opencv_cuda进行加速. 关于演示视频及代码讲解请查看:https://www.bilibili.com/video/BV13S4y1c7ea/https://www.bilibili.com/video/BV1Dq4y1x7r6/https://www.bilibili.com/video/BV1kT4y1S7hz/ 一.新建项目 UI设计 二.代码部分 mainwindow
-
YOLOv5目标检测之anchor设定
目录 前言 anchor的检测过程 anchor产生过程 总结 前言 yolo算法作为one-stage领域的佼佼者,采用anchor-based的方法进行目标检测,使用不同尺度的anchor直接回归目标框并一次性输出目标框的位置和类别置信度. 为什么使用anchor进行检测? 最初的YOLOv1的初始训练过程很不稳定,在YOLOv2的设计过程中,作者观察了大量图片的ground truth,发现相同类别的目标实例具有相似的gt长宽比:比如车,gt都是矮胖的长方形:比如行人,gt都是瘦高的长方形
-
通过底层源码理解YOLOv5的Backbone
目录 YOLOv5的Backbone设计 1 Backbone概览及参数 1.1 Param 1.2 backbone 1.3 Exp 2 Backbone组成 3.1 CBS 3.2 CSP/C3 3.2.1 CSP结构 3.2.2 Bottleneck 3.3 SSPF YOLOv5s的Backbone总览 总结 YOLOv5的Backbone设计 在上一篇文章<YOLOV5的anchor设定>中我们讨论了anchor的产生原理和检测过程,对YOLOv5的网络结构有了大致的了解.接下来,我
-
详谈HashMap和ConcurrentHashMap的区别(HashMap的底层源码)
HashMap本质是数组加链表,根据key取得hash值,然后计算出数组下标,如果多个key对应到同一个下标,就用链表串起来,新插入的在前面. ConcurrentHashMap在HashMap的基础上将数据分为多个segment,默认16个,然后每次操作对一个segment加锁,避免多线程锁的几率,提高并发效率. 1. HashMap的数据结构 HashMap底层就是一个数组结构,数组中存放的是一个Entry对象,如果产生的hash冲突,这时候该位置存储的就是一个链表了. HashMap中En
-
Spring AOP底层源码详解
ProxyFactory的工作原理 ProxyFactory是一个代理对象生产工厂,在生成代理对象之前需要对代理工厂进行配置.ProxyFactory在生成代理对象之前需要决定到底是使用JDK动态代理还是CGLIB技术. // config就是ProxyFactory对象 // optimize为true,或proxyTargetClass为true,或用户没有给ProxyFactory对象添加interface if (config.isOptimize() || config.isProxy
-
Java同步锁Synchronized底层源码和原理剖析(推荐)
目录 1 synchronized场景回顾 2 反汇编寻找锁实现原理 3 synchronized虚拟机源码 3.1 HotSpot源码Monitor生成 3.2 HotSpot源码之Monitor竞争 3.3 HotSpot源码之Monitor等待 3.4 HotSpot源码之Monitor释放 1 synchronized场景回顾 目标:synchronized回顾(锁分类–>多线程)概念synchronized:是Java中的关键字,是一种同步锁.Java中锁分为以下几种:乐观锁.悲观锁(
-
基于Spring Boot的Environment源码理解实现分散配置详解
前提 org.springframework.core.env.Environment是当前应用运行环境的公开接口,主要包括应用程序运行环境的两个关键方面:配置文件(profiles)和属性.Environment继承自接口PropertyResolver,而PropertyResolver提供了属性访问的相关方法.这篇文章从源码的角度分析Environment的存储容器和加载流程,然后基于源码的理解给出一个生产级别的扩展. 本文较长,请用一个舒服的姿势阅读. Environment类体系 Pr
-
初学者从源码理解MySQL死锁问题
通过好多个深夜艰难的单步调试,终于找到了一个理想的断点,可以看到大部分获取锁的过程 代码在lock0lock.c的static enum db_err lock_rec_lock() 函数中,这个函数会显示,获取锁的过程,以及获取锁成功与否. 场景1:通过主键进行删除 表结构 CREATE TABLE `t1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(10) NOT NULL DEFAULT '', PRIMARY KEY (
-
解决java 查看JDK中底层源码的实现方法
1.点 "window"-> "Preferences" -> "Java" -> "Installed JRES"2.此时"Installed JRES"右边是列表窗格,列出了系统中的 JRE 环境,选择你的JRE,然后点边上的 "Edit...", 会出现一个窗口(Edit JRE)3.选中rt.jar文件的这一项:"c:\program files\ja
-
Java源码解析之Gateway请求转发
Gateway请求转发 本期我们主要还是讲解一下Gateway,上一期我们讲解了一下Gateway中进行路由转发的关键角色,过滤器和断言是如何被加载的,上期链接://www.jb51.net/article/211824.htm 好了我们废话不多说,开始今天的Gateway请求转发流程讲解,为了在讲解源码的时候,以防止大家可能会迷糊,博主专门画了一下源码流程图,链接地址://www.jb51.net/article/211824.htm 上一期我们已经知道了相关类的加载,今天直接从源码开始,大家
-
Springboot基于Redisson实现Redis分布式可重入锁源码解析
目录 一.前言 二.为什么使用Redisson 1.我们打开官网 2.我们可以看到官方让我们去使用其他 3.打开官方推荐 4.找到文档 三.Springboot整合Redisson 1.导入依赖 2.以官网为例查看如何配置 3.编写配置类 4.官网测试加锁例子 5.根据官网简单Controller接口编写 6.测试 四.lock.lock()源码分析 1.打开RedissonLock实现类 2.找到实现方法 3.按住Ctrl进去lock方法 4.进去尝试获取锁方法 5.查看tryLockInne
-
Java面试Socket编程常用参数设置源码问题分析
目录 引导语 1.Socket整体结构 2.初始化 3.connect连接服务端 4.Socket常用设置参数 4.1.setTcpNoDelay 4.2.setSoLinger 4.3.setOOBInline 4.4.setSoTimeout 4.5.setSendBufferSize 4.6.setReceiveBufferSize 4.7.setKeepAlive 4.8.setReuseAddress 5.总结 引导语 Socket 中文翻译叫套接字,可能很多工作四五年的同学都没有用过