Linux下安装Hadoop集群详细步骤
目录
- 1.在usr目录下创建Hadoop目录,将安装包导入目录中并解压文件
- 2.进入vim /etc/profile文件并编辑配置文件
- 3.使文件生效
- 4.进入Hadoop目录下
- 5.编辑配置文件
- 6.进入slaves添加主节点和从节点
- 7.将各个文件复制到其他虚拟机上
- 8.格式化hadoop (仅在主节点中进行操作)
- 9.回到Hadoop目录下(仅在主节点操作)
1.在usr目录下创建Hadoop目录,将安装包导入目录中并解压文件

2.进入vim /etc/profile文件并编辑配置文件
#hadoop export HADOOP_HOME=/usr/hadoop/hadoop-2.6.0 export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib export PATH=$PATH:$HADOOP_HOME/bin

3.使文件生效
source /etc/profile

4.进入Hadoop目录下
cd /usr/hadoop/hadoop-2.6.0/etc/hadoop

5.编辑配置文件
(1)进入vim hadoop-env.sh文件添加(java jdk文件所在位置)
export JAVA_HOME=/usr/java/jdk1.8.0_181

(2)进入 vim core-site.xml(z1:在主节点的ip或者映射名(改成自己的))
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/hadoop/tmp</value>
</property>
<!--端口号9000-->
<property>
<name>fs.default.name</name>
<value>hdfs://z1:9000</value>
</property>
<!--开启垃圾桶机制单位分钟-->
<property>
<name>fs.trash .insterval</name>
<value>10080</value>
</property>
<!--缓冲区大小,实际工作根据服务器性能-->
<property>
<name>io.file. buffer.sizei</name>
<value>4096</value>
</property>
</configuration>
39,9 底端

(3)Hadoop没有mapred-site.xml这个文件现将文件复制到这然后进入mapred-site.xml
cp mapred-site.xml.template mapred-site.xml vim mapred-site.xml
(z1:在主节点的ip或者映射名(改成自己的))
<configuration>
<property>
<!--指定Mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--开启MapReduce的小任务模式-->
<property>
<name>mapred.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>z1:9001</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>CMaster:10020</value>
</property>
</configuration>

(4)进入yarn-site.xml
vim yarn-site.xml
(z1:在主节点的ip或者映射名(改成自己的))
<configuration>
<!-- Site specific YARN configuration properties -->
<!--配置yarn主节点的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>z1</value>
</property>
<property>
<!-- mapreduce ,执行shuff1e时获取数据的方式.-->
<description>The address of the appiications manager interface inthe RM.</description>
<name>yarn.resourcemanager.address</name>
<value>z1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>z1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>z1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>z1:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>z1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>z1:8033</value>
</property>
<property><!--mapreduce执行shuff1e时获取数据的方式,-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--设置内存,yarn的内存分配-->
<name>yarn.scheduler.maximum-a11ocation-mb</name>
<value>2024</value>
<discription>每个节点可用内存,单位M,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>

(5)进入hdfs-site.xml
vim hdfs-site.xml
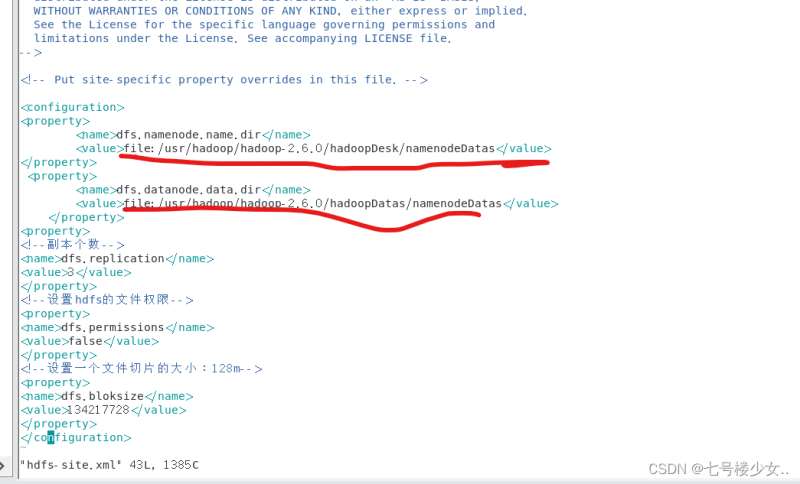
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.0/hadoopDesk/namenodeDatas</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.0/hadoopDatas/namenodeDatas</value>
</property>
<property>
<!--副本个数-->
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置hdfs的文件权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!--设置一个文件切片的大小:128m-->
<property>
<name>dfs.bloksize</name>
<value>134217728</value>
</property>
</configuration>
6.进入slaves添加主节点和从节点
vim slaves
添加自己的主节点和从节点(我的是z1,z2,z3)

7.将各个文件复制到其他虚拟机上
scp -r /etc/profile root@z2:/etc/profile #将环境变量profile文件分发到z2节点 scp -r /etc/profile root@z3:/etc/profile #将环境变量profile文件分发到z3节点 scp -r /usr/hadoop root@z2:/usr/ #将hadoop文件分发到z2节点 scp -r /usr/hadoop root@z3:/usr/ #将hadoop文件分发到z3节点
生效两个从节点的环境变量
source /etc/profile
8.格式化hadoop (仅在主节点中进行操作)
首先查看jps是否启动hadoop
hadoop namenode -format
当看到Exiting with status 0时说明格式化成功

9.回到Hadoop目录下(仅在主节点操作)
cd /usr/hadoop/hadoop-2.6.0 sbin/start-all.sh 启动Hadoop仅在主节点操作
主节点输入jps效果:

从节点输jps效果:


到此这篇关于Linux下安装Hadoop集群详细步骤的文章就介绍到这了,更多相关Linux安装Hadoop集群内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Linux中安装配置hadoop集群详细步骤
一. 简介 参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功.下面就把详细的安装步骤叙述一下.我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择2.7.1版本.(前边主要介绍单机版的配置,集群版是在单机版的基础上,主要是配置文件有所不同,后边会有详细说明) 二. 准备工作 2.1 创建用户 创建用户,并为其添加root权限,经过亲自验证下面这种方法比较好. sudo adduser hadoop sudo vim /etc/sudoers
-
Linux下安装Hadoop集群详细步骤
目录 1.在usr目录下创建Hadoop目录,将安装包导入目录中并解压文件 2.进入vim /etc/profile文件并编辑配置文件 3.使文件生效 4.进入Hadoop目录下 5.编辑配置文件 6.进入slaves添加主节点和从节点 7.将各个文件复制到其他虚拟机上 8.格式化hadoop (仅在主节点中进行操作) 9.回到Hadoop目录下(仅在主节点操作) 1.在usr目录下创建Hadoop目录,将安装包导入目录中并解压文件 2.进入vim /etc/profile文件并编辑配置文件
-
Linux下Kafka分布式集群安装教程
Kafka(http://kafka.apache.org/) 是由 LinkedIn 使用 Scala 编写的一个分布式消息系统,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础,具有高水平扩展和高吞吐量.Spack.Elasticsearch 都支持与 Kafka 集成.下面看一下几种分布式开源消息队列系统的对比: Kafka 集群架构: 一般不建议直接使用 Kafka 自带的 Zookeeper 建立 zk 集群,这里我们使用独
-
linux环境下安装jdk和Tomcat详细步骤
目录 一.安装jdk 手动安装 二.Tomcat 一.安装jdk 注意:安装tomcat需要先配置jdk 一种是yum安装 一种是手动安装(个人推荐手动安装) 手动安装 1.去Oracle官网下载需要安装的jdk版本,我这里用的是jdk-8u171-linux-x64.tar.gz 2.将该压缩包放到/usr/local/jdk目录下,jdk目录需要自己手动创建,也可以叫java,名字自己随意取(见名知意),然后解压该压缩包, 输入如下指令: tar zxvf jdk-8u172-linux-x
-
LInux下安装MySQL5.6 X64版本步骤详解
环境: 1.CentOS6.5 X64 2.mysql-5.6.34-linux-glibc2.5-x86_64.tar.gz 3.下载地址:http://dev.mysql.com/downloads/mysql/ 安装步骤 1.再安装包的存放目录下执行命令解压文件 tar -zxvf mysql-5.6.34-linux-glibc2.5-x86_64.tar.gz -C /opt/ 2.删除安装包,重命名解压后的文件 rm -rf mysql-5.6.34-linux-glibc2.5-x
-
liunx环境下安装jdk和Tomcat详细步骤
目录 一.安装jdk 手动安装 二.Tomcat 一.安装jdk 注意:安装tomcat需要先配置jdk 一种是yum安装 一种是手动安装(个人推荐手动安装) 手动安装 1.去Oracle官网下载需要安装的jdk版本,我这里用的是jdk-8u171-linux-x64.tar.gz 2.将该压缩包放到/usr/local/jdk目录下,jdk目录需要自己手动创建,也可以叫java,名字自己随意取(见名知意),然后解压该压缩包, 输入如下指令: tar zxvf jdk-8u172-linux-
-
Linux下ZooKeeper分布式集群安装教程
ZooKeeper 就是动物园管理员的意思,它是用来管理 Hadoop(大象).Hive(蜜蜂).pig(小猪)的管理员,Apache Hbase.Apache Solr.Dubbo 都用到了 ZooKeeper,其实就是一个集群管理工具,是集群的入口.ZooKeeper 是一个分布式的.开源的程序协调服务,是 Hadoop 项目下的一个子项目.ZooKeeper 主要应用场景包括集群管理(主从管理.负载均衡.高可用的管理).配置文件的集中管理.分布式锁.注册中心等.实际项目中,为了保证高可用,
-
Linux下安装与使用MySQL详细介绍
一.安装Mysql 1.下载MySQL的安装文件安装MySQL需要下面两个文件:MySQL-server-4.0.16-0.i386.rpm MySQL-client-4.0.16-0.i386.rpm下载地址为:http://dev.mysql.com/downloads/mysql-4.0.html,打开此网页,下拉网页找到"Linux x86 RPM downloads"项,找到"Server"和"Client programs"项,下载需
-
linux下安装boost库的完整步骤记录
前言 Boost库是一个可移植.提供源代码的C++库,作为标准库的后备,是C++标准化进程的开发引擎之一. Boost库由C++标准委员会库工作组成员发起,其中有些内容有望成为下一代C++标准库内容.在C++社区中影响甚大,是不折不扣的"准"标准库.Boost由于其对跨平台的强调,对标准C++的强调,与编写平台无关. 在linux安装过程如下: 去官方网站下载最新的:http://sourceforge.net/projects/boost/files/boost/1.47.0/ or
-
linux下安装Squid代理的详细配置教程
1.如果系统中还没有装squid,按以下顺序输入命令后即可完成安装 # wget http://www.squid-cache.org/Versions/v3/3.0/squid-3.0.STABLE18.tar.gz //下载Squid代理安装包 # tar -zxvf squid-3.0.STABLE18.tar.gz //解压Squid安装包 # cd squid-3.0.STABLE18 # ./configure --prefix=/usr/local/squid --sysconfd