JMeter参数化4种实现方式(小结)
目录
- 1 参数化释义
- 2 参数化实现
- 2.1 CSV Data Set Config
- CSV简介
- CSV实例
- 注意事项
- 2.2 User Parameters
- 2.3 用户定义的变量
- 2.4 Random
1 参数化释义
什么是参数化?从字面上去理解的话,就是事先准备好数据(广义上来说,可以是具体的数据值,也可以是数据生成规则),而非在脚本中写死,脚本执行时从准备好的数据中取值。
参数化:是自动化测试脚本的一种常用技巧,可将脚本中的某些输入使用参数来代替,如登录时利用GET/POST请求方式传递参数的场景,在脚本运行时指定参数的取值范围和规则。
脚本在运行时,根据需要选取不同的参数值作为输入,该方式称为数据驱动测试(Data Driven Test),而参数的取值范围被称为数据池(Data Pool)。
JMeter提供了多种参数化方式,下面就其中常用的4种展开阐述。
| 方式 | 适用场景 |
|---|---|
| CSV Data Set Config | 我们通常所指的参数化。数据存储在文件中,参数化取值范围大,灵活性强 |
| User Parameter | 适用于参数取值范围很小时 |
| 函数助手 | _Random等函数,生成随机数字和随机字符串实现参数化 |
| User Defined Variables | 用户自定义变量,更多用于设置全局变量 |
2 参数化实现
2.1 CSV Data Set Config
在JMeter中提起参数化,我们默认就想到CSV Data Set Config(以下简称CSV),CSV能够读取文件中的数据并生成变量,被JMeter脚本引用,从而实现参数化。下面我们来详细探究一下。
CSV简介
线程组右键–>添加–>配置元件–>CSV Data Set Config,就创建了一个CSV,界面是这个样子的:
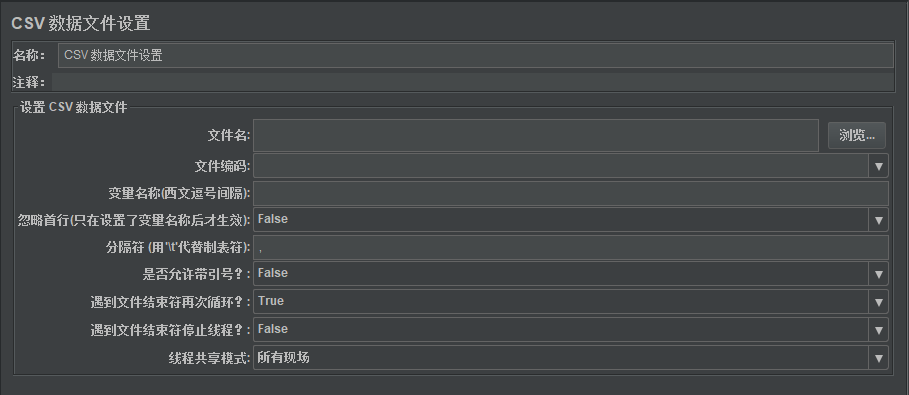
各项参数详解如下:
| 参 数 | 描 述 | 必 须 |
|---|---|---|
| Name | 脚本中显示的这个元件的描述性名称 | 是 |
| Filename | 文件名。待读取文件的名称。可以写入绝对路径,也可以写入相对路径(相对于bin目录),如果直接写文件名,则该文件要放在bin目录中。对于分布式测试,主机和远程机中相应目录下应该有相同的CSV文件 | 是 |
| File Encoding | 文件编码。文件读取时的编码格式,不填则使用操作系统的编码格式 | 否 |
| Variable Names | 变量名称。多个变量名之间必须用分隔符分隔。如果该项为空,则文件首行会被读取并解析为列名列表 | 否 |
| Ignore first line | 是否忽略首行?如果csv文件中没有表头,则选择false | 是 |
| Delimiter | 分隔符。将一行数据分隔成多个变量,默认为逗号,也可以使用“\t”。如果一行数据分隔后的值比Vairable Names中定义的变量少,这些变量将保留以前的值(如果有值的话) | 是 |
| Allow quoted data? | 是否允许变量使用双引号?允许的话,变量将可以括在双引号内,并且这些变量名可以包含分隔符 | 否 |
| Recycle on EOF? | 遇到文件结束符是否再次循环?默认为 true | 是 |
| Stop thread on EOF? | 遇到文件结束符是否停止线程?默认为 true | 是 |
| Recycle on EOF? | 当Recycle on EOF为False时,停止线程,当Recycle on EOF为True时,此项无意义,默认为 false | 是 |
| Sharing mode | 线程共享模式。1、All threads(默认):一个线程组内,各个线程(用户)唯一顺序取值;2、current thread:一个线程组内,各个线程(用户)各自顺序取值;3、线程组各自独立,但每个线程组内各个线程(用户)唯一顺序取值; | 是 |
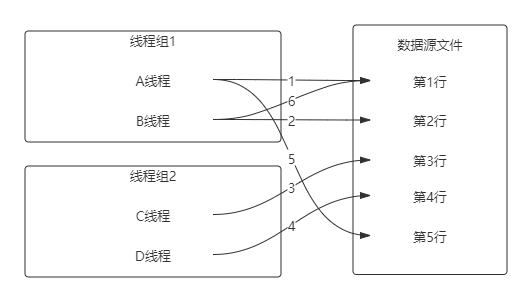
需要着重说明一下的是Sharing mode,也就是线程共享模式。线程共享模式,是指多个线程对文件数据取值顺序模式,JMeter提供了3种模式:
All threads:所有线程。如果脚本有多个线程组,在这种模式下,各线程组的所有线程也要依次唯一顺序取值。例如,脚本有2个线程组,各有2个线程,文件内有5行数据,脚本运行时,将如下图一样循环往复取值:
Current thread group:当前线程组。各个线程组之间隔离,线程组内的线程顺序唯一取值。
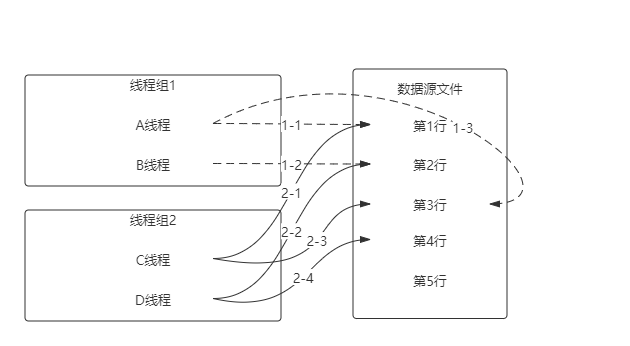
Current thread:当前线程。这种模式下,每个线程独立,顺序唯一取值。

CSV实例
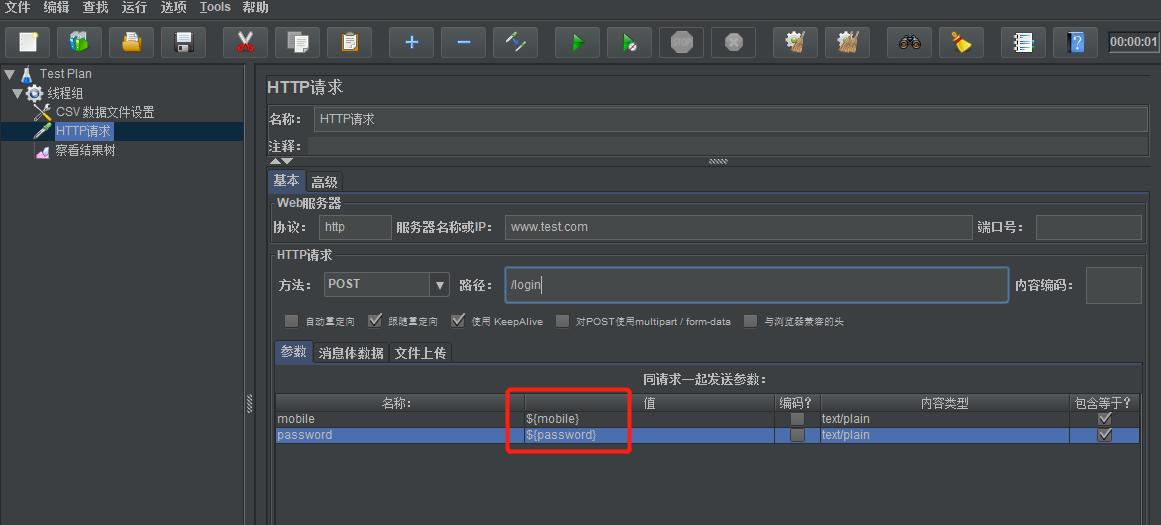
下面看一个实例。首先有userInfo.txt的文件,放置在bin目录中,内容如下:


- 文件名:文件在bin目录中,使用相对目录
- 变量名称:两列数据分别属于mobile和password两个变量
- 分隔符:以逗号分割
在HTTP请求中引用CSV生成的变量的方式是${变量名}的方式:
运行脚本,察看结果树:

可以看到,文件中的数据被脚本成功引用。JMeter使用CSV实现参数化就是这么简单。
注意事项
CSV使用中最常见的一个问题是文件路径不对。当遇到这种问题时,因为运行脚本没有明显提示,许多人遇到后会感觉很懵,不知道问题在哪。其实,仔细观察会发现右上角黄色三角处数字在增加,点击该区域便打开了日志,日志里记录了相应错误:File userInfo2.txt must exist and be readable,也就是提示参数化文件不存在或路径不可达。

2.2 User Parameters
User Parameters,也就是用户参数,也能实现参数化。
创建方式:HTTP请求上右键–>添加–>前置处理器(Pre processors)–>用户参数。
通过【添加变量】添加mobile和password两个变量,通过【添加用户】添加3组数据:

在HTTP请求中引用参数化的数据:

运行脚本,设置好的数据被成功引用。

这种方式相对来说简易一些,数据范围有限,适用场景也少。而且,每个线程会一直使用一组数据。例如,设置4个线程并发,那么线程1使用用户_1的数据,线程2使用用户_2的数据,线程3使用用户_3的数据,线程4使用用户_1的数据,无论各个线程循环多少次。
2.3 用户定义的变量
用户自定义的变量,也可以实现请求参数的参数化。
创建方式:线程组上右键–>配置元件(config element)–>用户定义的变量。

如上图,用起来也很简单,添加变量名和相对应的值就可以了。后面引用变量和前面一样,使用${mobile}的方式。
【用户定义的变量】一般并非用来做HTTP请求参数化,而是用来定义全局变量,比如参数化文件路径、host、url等。
【用户定义的变量】创建在【线程组】上,则在线程组内生效,如果创建在【Test Plan】上,则对所有线程组生效。
2.4 Random
函数助手中的Random函数,
创建方式:Tools–>函数助手对话框–>选择一个功能–>_Random:

上图中,生成了一个表达式:${__Random(8000,9000,)},我们用这个表达式替换想要参数化的变量值,例如下图中的price变量:

运行脚本,察看结果树,可以看到效果:

这种方式适用于值在一定区间无规律随机取值的变量参数化,例如价格、数量等,并不适用于有较强规则的变量进行参数化,例如手机号。
到此这篇关于JMeter参数化4种实现方式(小结)的文章就介绍到这了,更多相关JMeter参数化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Jmeter参数化实现原理及过程解析
背景: 在实际的测试工作中,我们经常需要对多组不同的输入数据,进行同样的测试操作步骤,以验证我们的软件的功能.这种测试方式在业界称为数据驱动测试,而在实际测试工作中,测试工具中实现不同数据输入的过程称为参数化设置. jmeter提供多种参数化设置的方式,常用的有: 1.使用 用户定义的变量元件 实现 2.使用 用户参数元件 实现 3.使用 函数助手 实现 4.使用 CSV 数据文件设置元件 实现 5.其它方式(数据库数据.beanshell等)实现 一.用户定义的变量元件实现 假如设置如下: 调
-
Jmeter关联实现及参数化使用解析
前言 一.Jmeter介绍 一款融合接口.性能都能完成的测试工具 纯JAVA开发的工具 开源工具 支持多种协议 应该是测试业界目前应用最多的工具之一 二.接口执行实现 添加HTTP取样器:右击测试计划--新建并右击线程组--添加--取样器--新增HTTP请求 在HTTP请求元件中添加相应请求信息(请求行.请求头.请求正文) 添加察看结果树:右击线程组--添加--监听器--新增察看结果树 保存刚设置的接口脚本,点击执行 三.关联实现 3.1 关联的概念 关联也称为串行传参或数据依赖,即上一个接口返
-
Jmeter 中 CSV 如何参数化测试数据并实现自动断言示例详解
当我们使用Jmeter工具进行接口测试,可利用CSV Data Set Config配置元件,对测试数据进行参数化,循环读取csv文档中每一行测试用例数据,来实现接口自动化.此种情况下,很多测试工程师只会人工地查看响应结果来判断用例是否通过. 其实我们同样可利用CSV Data Set Config来帮助我们实现自动断言. 思路:将每一条用例的预期结果一并保存在csv文档中,循环读取文档中的期望结果,来跟实际运行的结果进行一致性判断,高效实现接口自动化. 示例: 1.整理测试数据及预期结果的CS
-
Jmeter参数化实现方法及应用实例
当使用JMeter进行测试时,测试数据的准备是一项重要的工作.若要求每次迭代的数据不一样时,则需进行参数化,然后从参数化的文件中来读取测试数据. 参数化:是自动化测试脚本的一种常用技巧,可将脚本中的某些输入使用参数来代替,如登录时利用GET/POST请求方式传递参数的场景,在脚本运行时指定参数的取值范围和规则. 脚本在运行时,根据需要选取不同的参数值作为输入,该方式称为数据驱动测试(Data Driven Test),而参数的取值范围被称为数据池(Data Pool). 1.CVS参数化 应用:
-
Jmeter参数化获取序列数据实现过程
一.序列数据是什么 很简单,就是利用参数化能产生顺序值,比如 1,2,3,4,5,6 或者约定格式 001,002,003,004等. 二.jmeter 产生序列数据 2.1 利用函数助手对话框实现 在jmeter菜单处点击 工具 -- 函数助手对话框 -- 下拉框选择 counter -- 进入如下界面: mac系统点击生成时会自动复制生成的函数,直接可以在需要的地方粘贴.如: 这样设置后,可以通过线程组设置界面的循环次数输入比如 5 来进行测试. 2.2 利用配置元件--计数器元件实现 st
-

JMeter参数化4种实现方式(小结)
目录 1 参数化释义 2 参数化实现 2.1 CSV Data Set Config CSV简介 CSV实例 注意事项 2.2 User Parameters 2.3 用户定义的变量 2.4 Random 1 参数化释义 什么是参数化?从字面上去理解的话,就是事先准备好数据(广义上来说,可以是具体的数据值,也可以是数据生成规则),而非在脚本中写死,脚本执行时从准备好的数据中取值. 参数化:是自动化测试脚本的一种常用技巧,可将脚本中的某些输入使用参数来代替,如登录时利用GET/POST请求方式传递
-
Python 脚本的三种执行方式小结
1.交互模式下执行 Python,这种模式下,无需创建脚本文件,直接在 Python解释器的交互模式下编写对应的 Python 语句即可. 1)打开交互模式的方式: Windows下: 在开始菜单找到"命令提示符",打开,就进入到命令行模式: 在命令行模式输入: python 即可进入 Python 的交互模式 Linux 下: 直接在终端输入 python,如果是按装了 python3 ,则根据自己建的软连接的名字进入对应版本的 Python 交互环境,例如我建立软连接使用的 pyt
-
Python第三方库的几种安装方式(小结)
对于python开发用户而言,经常需要安装一些python的第三方库,但是第三方库的安装经常出错,以下给大家介绍一下python安装第三方库的几种常用方式: pip安装 无论是Windows.Linux还是Mac,都可以通过pip这个包管理工具来安装第三方库.最简单的安装方式就是: pip install requests pip默认是通过国外的源进行下载,速度太慢,且经常容易报错:因此推荐大家几个国内常用的安装源: 新版ubuntu要求使用https源,要注意. 清华:https://pypi
-
git pull时冲突的几种解决方式(小结)
仅结合本人使用场景,方法可能不是最优的 1. 忽略本地修改,强制拉取远程到本地 主要是项目中的文档目录,看的时候可能多了些标注,现在远程文档更新,本地的版本已无用,可以强拉 git fetch --all git reset --hard origin/dev git pull 关于commit和pull的先后顺序,commit-->pull-->push 和 pull-->commit-->push的顺序,两种情况都遇到过代码冲突.解决方法如下: 2. 未commit先pull,
-
mybatis plus的3种查询方式(小结)
本文是基于springboot框架下的查询. 一:基本配置: 1.仓库依赖 <repositories> <repository> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <releases> <enabled>
-
Selenium Webdriver元素定位的八种常用方式(小结)
在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合By类返回的元素句柄来定位元素.其中By类的常用定位方式共八种,现分别介绍如下. 1. By.name() 假设我们要测试的页面源码如下: <button id="gbqfba" aria-label="Google Search" name="btnK" class="gbqfba"><
-
C#多态的三种实现方式(小结)
C#实现多态主要有3种方法,虚方法,抽象类,接口 1 虚方法 在父类的方法前面加关键字virtual, 子类重写该方法时在方法名前面加上override关键字,例如下面的Person类的SayHello方法 class Person { public Person(string name) { this.Name = name; } string _name; public string Name { get => _name; set => _name = value; } //父类方法加v
-
python里读写excel等数据文件的6种常用方式(小结)
下面整理下python有哪些方式可以读取数据文件. 1. python内置方法(read.readline.readlines) read() : 一次性读取整个文件内容.推荐使用read(size)方法,size越大运行时间越长 readline() :每次读取一行内容.内存不够时使用,一般不太用 readlines() :一次性读取整个文件内容,并按行返回到list,方便我们遍历 2. 内置模块(csv) python内置了csv模块用于读写csv文件,csv是一种逗号分隔符文件,是数据科学
-
springboot集成本地缓存Caffeine的三种使用方式(小结)
目录 第一种方式(只使用Caffeine) 第二种方式(使用Caffeine和spring cache) 第三种方式(使用Caffeine和spring cache) 第一种方式(只使用Caffeine) gradle添加依赖 dependencies { implementation 'org.springframework.boot:spring-boot-starter-jdbc' implementation 'org.springframework.boot:spring-boot-s
-
java异步编程的7种实现方式小结
目录 同步编程 一.线程 Thread 二.Future 三.FutureTask 四.异步框架 CompletableFuture 五. SpringBoot 注解 @Async 六.Spring ApplicationEvent 事件 七.消息队列 最近有很多小伙伴给我留言,能不能总结下异步编程,今天就和大家简单聊聊这个话题. 早期的系统是同步的,容易理解,我们来看个例子 同步编程 当用户创建一笔电商交易订单时,要经历的业务逻辑流程还是很长的,每一步都要耗费一定的时间,那么整体的RT就会比较