pandas 实现分组后取第N行
目的:
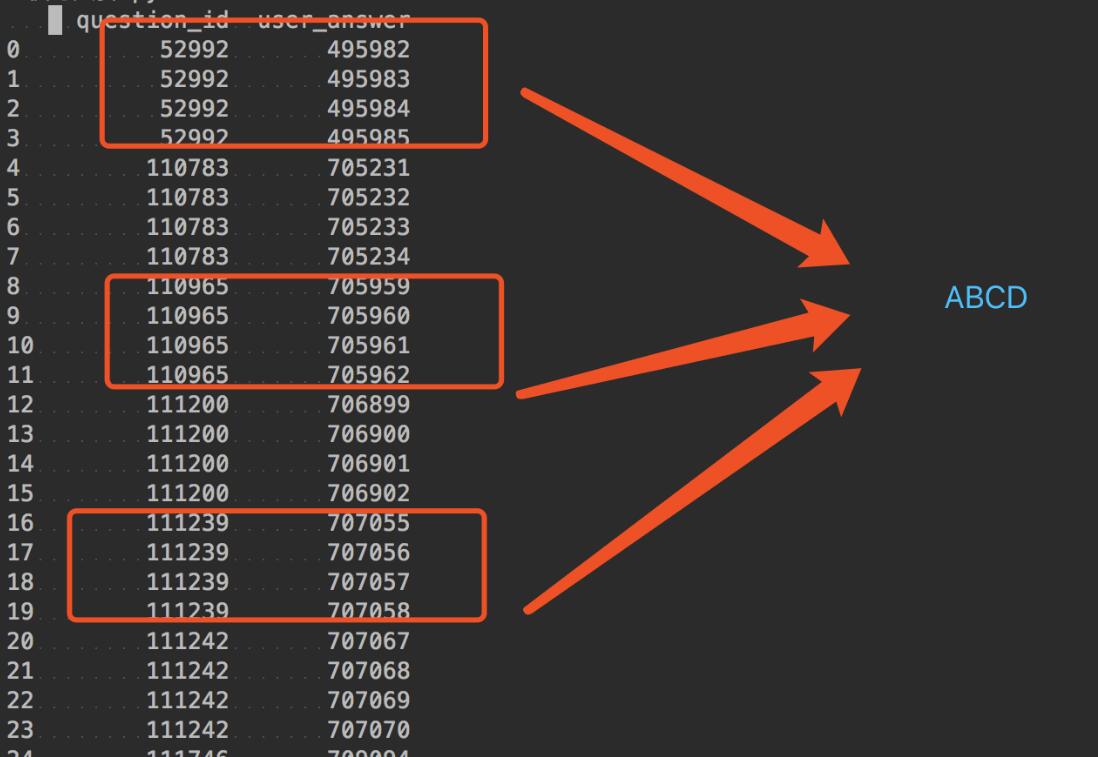
把question_id 对应的user_answer转成ABCD
solution
dfa=df.groupby('question_id').nth(0).reset_index()
dfa['flag']='A'
dfb=df.groupby('question_id').nth(1).reset_index()
dfb['flag']='B'
dfc=df.groupby('question_id').nth(2).reset_index()
dfc['flag']='C'
dfd=df.groupby('question_id').nth(3).reset_index()
dfd['flag']='D'
resdf=dfa.append([dfb,dfc,dfd])
resdf.sort_values(by='question_id')
result:
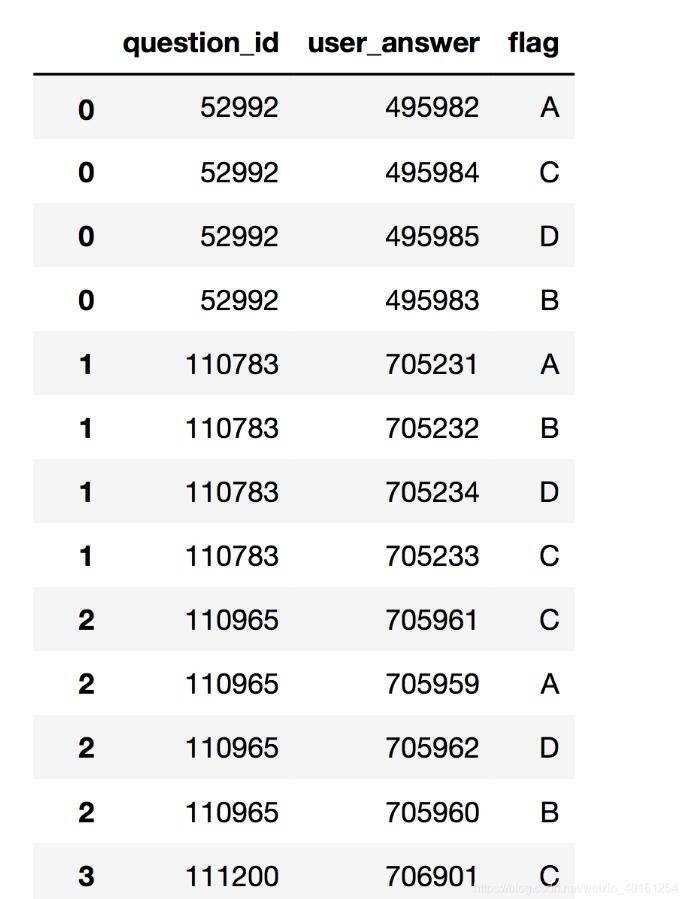
focus:
g.nth(0) #同 g.first() g.head(1) g.last() g.nth(2) g.nth(-1) g.nth(0,dropna='any') g.B.nth(0,dropna='all') g.groups g.get_group(134429) g.discribe() g.agg([np.mean,np.sum.np,std])
补充:pandas的分组取最大多行并求和函数nlargest()
在pandas库里面,我们常常关心的是最大的前几个,比如销售最好的几个产品,几个店,等。之前讲到的head(), 能够看到看到DF里面的前几行,如果需要看到最大或者最小的几行就需要先进行排序。max()和min()可以看到最大或者最小值,但是只能看到一个值。
所以我们可以使用nlargest()函数,nlargest()的优点就是能一次看到最大的几行,而且不需要排序。缺点就是只能看到最大的,看不到最小的。
我们来看看单价排在前十的数据:
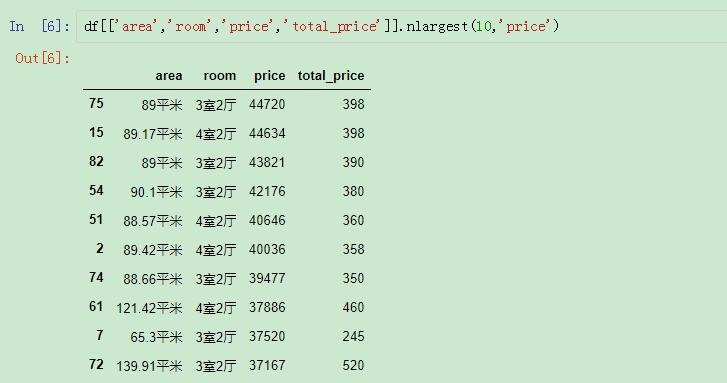
单价排在前十的数据
nlargest()的第一个参数就是截取的行数。第二个参数就是依据的列名。
这样就可以筛选出单价最高的前十行,而且是按照单价从最高到最低进行排列的,所以还是按照之前的索引。
还可以按照total_price来进行排名:
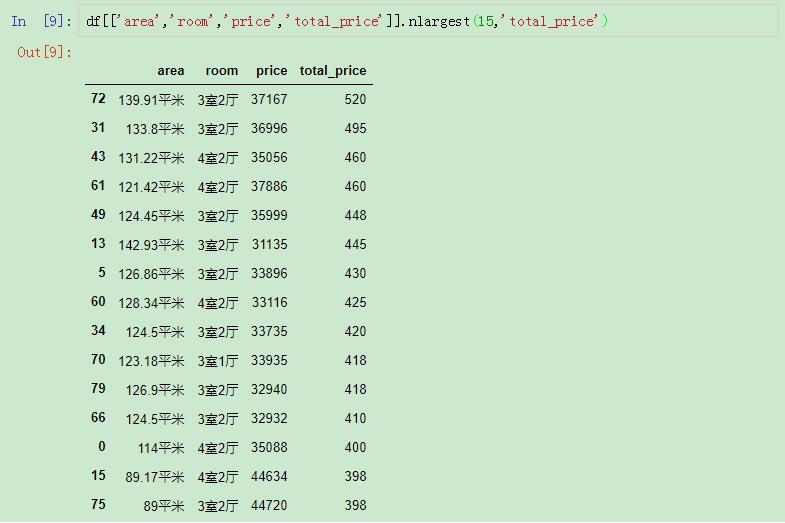
按照total_price排名
nlargest还有一个参数,keep='first'或者'last'。当出现重复值的时候,keep='first',会选取在原始DataFrame里排在前面的,keep='last'则去排后面的。
由于nlagerst()不能去最小的多个值,如果我们一定要使用这个函数进行选取也是可以的.
先设置一个辅助列:
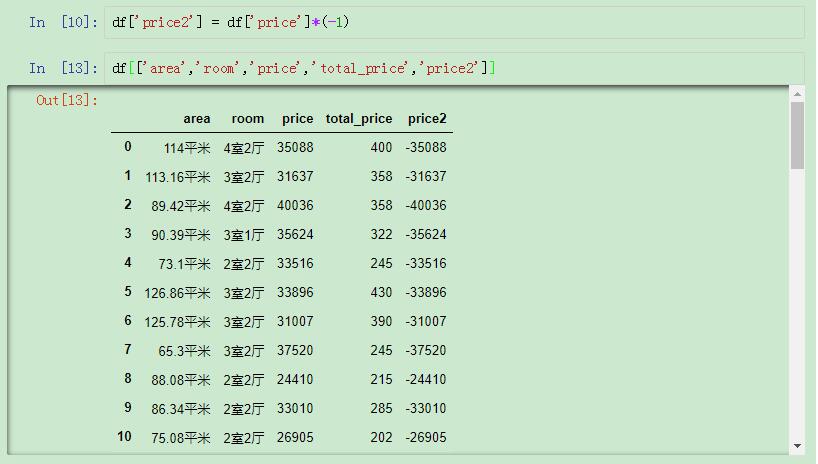
先设置一个辅助列
然后在进行选取:
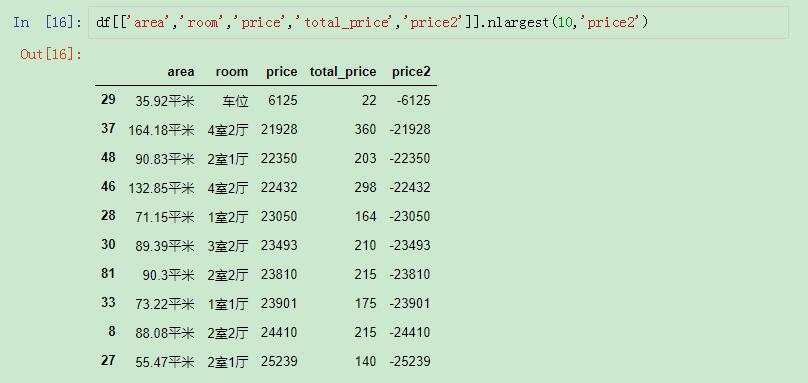
以辅助列进行选取
当然了,也可以通过head()加上排序进行选取的。
那以前这些操作都可以通过其它函数来进行替代的话,nlargest()有什么必要介绍吗?或者说学不学这个函数有什么关系吗?
这就是我们今天要重点介绍的,如果说要选择不同location_road下的前五名要怎么操作呢?
很多人可能第一反应会想到先分组然后进行max()操作,但是这样的操作只能选择最大的一列:
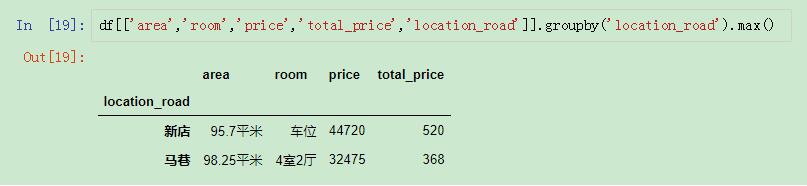
使用max()
但是使用max有一个问题,就是选取的是每一列的最大值,而不是选取最大值的那一行,也就是说只能在选取单列的最大值的时候才是准确的。
这个时候我们就要想到apply和lambda的自定义函数了:
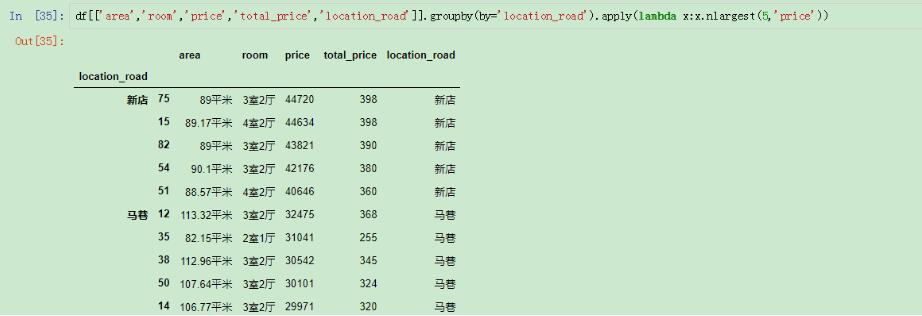
选取多个指标的TOP(N)
这样就选出了不同loaction_road的price排在前五的行了。
nlargest()函数在这种场景下使用是非常方便的,而且结果也已经默认排好顺序了。
还有一些场景下需要计算分组的前几名,然后在进行求和的,这个我们也可以使用nlargest进行操作:
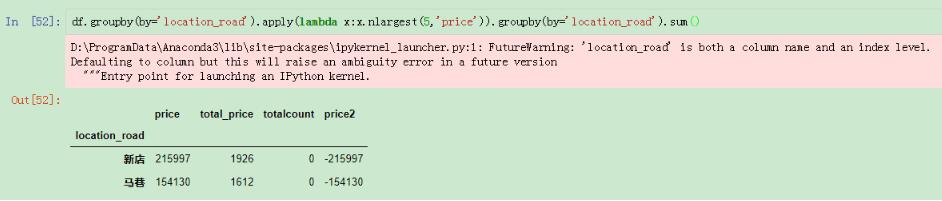
分组之后进行求和
使用这种方法会出现报错提示,这个因为在列和索引都存在loaction_road,有重复,系统有警告,在实际使用时可以先改列名再操作。我们也可以换一种方式直接按照索引进行求和,这样就没有警告了:

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
pandas分组排序 如何获取第二大的数据
Python用来做数据分析很方便,网上很多关于找数据中第二大的方法,但是大多数都是关于SQL的,于是我挑战一下用Python来做这件事(主要是SQL写的不好>_<),上代码. 1.数据我是自己编的 在实际工作中应该从数据库中导入数据,如何从数据库导出数据,我之后会补充. import pandas as pd df = pd.DataFrame([ {"class": 1, "name": "aa", "english&qu
-
pandas groupby分组对象的组内排序解决方案
问题: 根据数据某列进行分组,选择其中另一列大小top-K的的所在行数据 解析: 求解思路很清晰,即先用groupby对数据进行分组,然后再根据分组后的某一列进行排序,选择排序结果后的top-K结果 案例: 取一下dataframe中B列各对象中C值最高所在的行 df = pd.DataFrame({"A": [2, 3, 5, 4], "B": ['a', 'b', 'b', 'a'], "C": [200801, 200902, 200704
-

pandas 实现某一列分组,其他列合并成list
pandas列转换为字典,但将相同第一列(键)的所有值合并为一个键 形式一: import pandas as pd # data data = pd.DataFrame({'column1':['key1','key1','key2','key2'], 'column2':['value1','value2','value3','value3']}) print(data) # Grouped dict data_dict = data.groupby('column1').column2.a
-
pandas group分组与agg聚合的实例
如下: import pandas as pd df = pd.DataFrame({'Country':['China','China', 'India', 'India', 'America', 'Japan', 'China', 'India'], 'Income':[10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000], 'Age':[5000, 4321, 1234, 4010, 250, 250, 4500, 4321]}) 构造的数
-
Pandas中DataFrame的分组/分割/合并的实现
学习<Python3爬虫.数据清洗与可视化实战>时自己的一些实践. DataFrame分组操作 注意分组后得到的就是Series对象了,而不再是DataFrame对象. import pandas as pd # 还是读取这份文件 df = pd.read_csv("E:/Data/practice/taobao_data.csv", delimiter=',', encoding='utf-8', header=0) # 计算'成交量'按'位置'分组的平均值 groupe
-
pandas组内排序,并在每个分组内按序打上序号的操作
问题: pandas组内排序,并在每个分组内按序打上序号 描述: pandas dataframe 对dep_id组内的salary排序.希望给下面原本只有前三列的dataframe,添加上第四列. 等价于sql里的排序函数 row_number() over() 功能 假设我已经建好了仅有前三列的dataframe,数据集命名为 MyData, 解决方案如下: MyData['sort_id'] = MyData['salary'].groupby(MyData['dep_id']).rank
-
pandas 实现分组后取第N行
目的: 把question_id 对应的user_answer转成ABCD solution dfa=df.groupby('question_id').nth(0).reset_index() dfa['flag']='A' dfb=df.groupby('question_id').nth(1).reset_index() dfb['flag']='B' dfc=df.groupby('question_id').nth(2).reset_index() dfc['flag']='C' df
-
分组后分组合计以及总计SQL语句(稍微整理了一下)
今天看到了这个文章感觉内容挺多的,就是比较乱,实在不好整理,我们小编就简单整理了一下,希望大家能凑合看吧 分组后分组合计以及总计SQL语句 1)想一次性得到分组合计以及总计,sql: SELECT 分组字段 FROM 表 GROUP BY 分组字段 compute sum(COUNT(*)) 2)分组合计1: SELECT COUNT(*) FROM (SELECT 分组字段 FROM 表 GROUP BY 分组字段 )别名 3)分组合计2: SELECT COUNT(*) FROM (SE
-
pandas groupby 分组取每组的前几行记录方法
直接上例子. import pandas as pd df = pd.DataFrame({'class':['a','a','b','b','a','a','b','c','c'],'score':[3,5,6,7,8,9,10,11,14]}) df: class score 0 a 3 1 a 5 2 b 6 3 b 7 4 a 8 5 a 9 6 b 10 7 c 11 8 c 14 df.sort_values(['class','score'],ascending=[1,0],inp
-
pandas获取groupby分组里最大值所在的行方法
pandas获取groupby分组里最大值所在的行方法 如下面这个DataFrame,按照Mt分组,取出Count最大的那行 import pandas as pd df = pd.DataFrame({'Sp':['a','b','c','d','e','f'], 'Mt':['s1', 's1', 's2','s2','s2','s3'], 'Value':[1,2,3,4,5,6], 'Count':[3,2,5,10,10,6]}) df Count Mt Sp Value 0 3 s1
-
Python在groupby分组后提取指定位置记录方法
在进行数据分析.数据建模时,我们首先要做的就是对数据进行处理,提取我们需要的信息.下面为大家介绍一些groupby的用法,以便能够更加方便地进行数据处理. 我们往往在使用groupby进行信息提取时,往往是求分组后样本的一些统计量(max.min,var等).如果现在我们希望取一下分组后样本的第二条记录,倒数第三条记录,这个该如何操作呢?我们可以通过first.last来提取分组后第一条和最后一条样本.但如果我们要取指定位置的样本,就没有现成的函数.需要我们自己去写了.下面我就为大家介绍如何实现
-
pandas之分组groupby()的使用整理与总结
前言 在使用pandas的时候,有些场景需要对数据内部进行分组处理,如一组全校学生成绩的数据,我们想通过班级进行分组,或者再对班级分组后的性别进行分组来进行分析,这时通过pandas下的groupby()函数就可以解决.在使用pandas进行数据分析时,groupby()函数将会是一个数据分析辅助的利器. groupby的作用可以参考 超好用的 pandas 之 groupby 中作者的插图进行直观的理解: 准备 读入的数据是一段学生信息的数据,下面将以这个数据为例进行整理grouby()函数的
-
pandas数据分组groupby()和统计函数agg()的使用
数据分组 使用 groupby() 方法进行分组 group.size()查看分组后每组的数量 group.groups 查看分组情况 group.get_group('名字') 根据分组后的名字选择分组数据 准备数据 # 一个Series其实就是一条数据,Series方法的第一个参数是data,第二个参数是index(索引),如果没有传值会使用默认值(0-N) # index参数是我们自定义的索引值,注意:参数值的个数一定要相同. # 在创建Series时数据并不一定要是列表,也可以将一个字典
-
pandas数据分组和聚合操作方法
<Python for Data Analysis> GroupBy 分组运算:split-apply-combine(拆分-应用-合并) DataFrame可以在其行(axis=0)或列(axis=1)上进行分组.然后,将一个函数应用到各个分组并产生新值.最后,所有这些函数的执行结果会被合并到最终的结果对象中去. GroupBy的size方法可以返回一个含有分组大小的Series. 对分组进行迭代 for (k1,k2), group in df.groupby(['key1','key2'
-
pandas多级分组实现排序的方法
pandas有groupby分组函数和sort_values排序函数,但是如何对dataframe分组之后排序呢? In [70]: df = pd.DataFrame(((random.randint(2012, 2016), random.choice(['tech', 'art', 'office']), '%dk-%dk'%(random.randint(2,10), random.randint(10, 20)), '') for _ in xrange(10000)), column