详解tensorflow2.x版本无法调用gpu的一种解决方法
最近学校给了一个服务器账号用来训练神经网络使用,服务器本身配置是十路titan V,然后在上面装了tensorflow2.2,对应的python版本是3.6.2,装好之后用tf.test.is_gpu_available()查看是否能调用gpu,结果返回结果是false,具体如下:
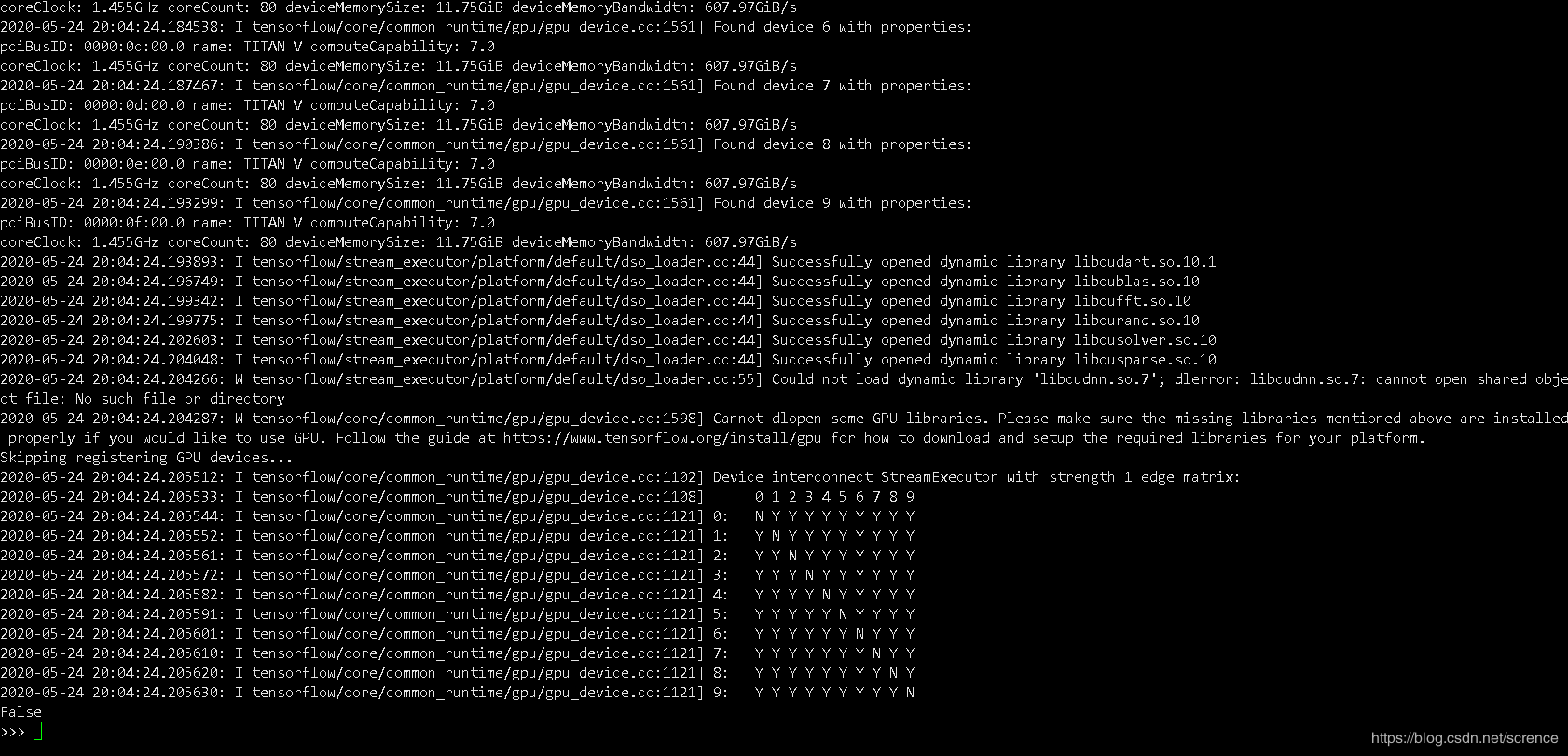
这里tensorflow应该是检测出了gpu,但是因为某些库无法打开而导致tensorflow无法调用,返回了false,详细查看错误信息可以看到一行:

可以看到上面几个文件都顺利打开了,但是最后一个libcudnn.so.7文件显示无法打开,not such file or directory。怀疑是cuda有问题,服务器本身是装的cuda10.1,跟tensorflow2.2应该是吻合的,但是一直无法调用,所以一开始我想重新安装cuda,覆盖掉服务器本来的cuda,下好安装包之后,因为我不是管理员,没有root权限,所以总是失败。但是安装过程中了解到系统的cuda安装目录,位于/usr/local/cuda下面,这个libcudnn.so.7应该是一个库文件,那应该放在cuda的安装目录下面,具体地,在/usr/local/cuda/lib64下面,之前在我的windows本地机器安装cuda时还要下载cudnn7.x,然后把文件拷贝到cuda对应的目录下面,我怀疑lib64目录下面的这个libcudnn.so.7文件有问题,因为在linux版本的cudnn中是可以看到libcudnn.so.7这个文件的。
于是,打开lib64目录,查找是否有libcudnn.so.7这个文件,结果是没有找到这个文件,这就很奇怪了,cuda10.1目录下面竟然没有cudnn的文件,我也没有权限修改/usr/local,因此想到既然是少了这个文件,那是不是把对应的文件加载在别的目录下,引导tensorflow去另一个我可以操作的目录下找这个libcudnn.so.7文件,就可以解决问题呢?我带着试验性的心态wget下载cudnn,结果在命令行下无法下载cudnn,原因是cudnn下载需要登录,而在命令行下就没办法下载。于是在本地机器上下载了linux版的cudnn,然后用scp命令把这个tar.gz文件发到服务器上,解压出来可以看到~/cudnn/cuda/lib64下面有libcudnn.so.7。接下来就是添加环境变量,让tensorflow不仅在/usr/local/cuda/lib64下找文件,还可以在我这个目录下找,添加命令:
export PATH=$PATH:/usr/local/cuda-10.1/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-10.1/lib64 export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda-10.1/lib64
这几行命令添加系统cuda的库
然后添加:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/users/cudnn/cuda/lib64 export LIBRARY_PATH=$LIBRARY_PATH:/home/users/cudnn/cuda/lib64
这里的/home/users/cudnn/cuda/lib64视自己的libcudnn.so.7文件目录而定,最后是更新:
source /etc/profile
如果tensorflow是按照在anaconda虚拟环境下的,在执行这几条命令会自动退出虚拟环境。记得重新进入:
source activate 环境名
这时重新进入python,导入tensorflow,然后运行tf.test.is_gpu_available(),可以看到:

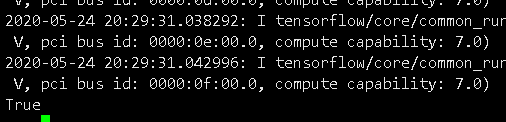
这时已经显示成功打开了libcudnn.so.7文件,说明tf根据我提供的目录成功找到了这个文件,在打开了这些库文件后,最下面也返回了True:
还可以用另一个方法tf.config.list_physical_devices(‘GPU')查看当前可用gpu:

十块gpu都显示出来了。
注意,添加这几条命令只在当前连接上有用,如果断开了服务器连接再重新连接时,需要重新输入这些命令。
这个方法只是作为一个参考,碰巧是在tensorflow2.2上这个libcudnn.so.7文件打不开,于是尝试性地试了一下,结果成功了。其他机器上如果出现同类问题,采用这个方法不一定能解决,只是提供一个思路。在tensorflow2.1上,也同样出现gpu无法调用的问题,但打印的错误信息不仅有libcudnn.so.7文件无法打开,还有其他几个文件也打不开,这些文件基本都是lib开头的,可以查看这些文件是否在cuda的lib64目录下,如果找得到这些文件,那有可能是环境变量设错了,可以试试上面那些命令:
export PATH=$PATH:/usr/local/cuda-10.1/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-10.1/lib64 export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda-10.1/lib64
如果找不到,那可以试试跟我一样先把这些文件下载到机器上面,给系统添加环境变量到对应这些文件的目录,引导tf去找。当然,这只是我一种猜测,tensorflow2.1和2.2用的应该都是cuda10.1,但是我不清楚为什么2.2只有一个文件无法打开,而2.1就有好几个文件打不开,而在1.9版本上,由于1.9似乎用的不是10.1版本的cuda,其错误原因更多,这里要区分开。
到此这篇关于详解tensorflow2.x版本无法调用gpu的一种解决方法的文章就介绍到这了,更多相关tensorflow2.x无法调用gpu内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!