Python实现CAN报文转换工具教程
一、CAN报文简介
CAN是控制器局域网络(Controller Area Network, CAN)的简称,是由以研发和生产汽车电子产品著称的德国BOSCH公司开发的,并最终成为国际标准(ISO 11898),是国际上应用最广泛的现场总线之一。 在北美和西欧,CAN总线协议已经成为汽车计算机控制系统和嵌入式工业控制局域网的标准总线,并且拥有以CAN为底层协议专为大型货车和重工机械车辆设计的J1939协议。
CAN总线以报文为单位进行数据传送。CAN报文按照帧格式可分为标准帧和扩展帧,标准帧是具有11位标识符的CAN帧,扩展帧是具有29位标识符的CAN帧。按照帧类型可分为:1.从发送节点向其它节点发送数据;2.远程帧:向其它节点请求发送具有同一识别符的数据帧;3.错误帧:指明已检测到总线错误;4.过载帧:过载帧用以在数据帧(或远程帧)之间提供一附加的延时。共有两种编码格式:Intel格式和Motorola格式,在编码优缺点上,Motorola格式与Intel格式并没有孰优孰劣之分,只不过根据设计者的习惯,由用户自主选择罢了。当然,对于使用者来讲,在进行解析之前,就必须要知道编码的格式是哪一种,否则,就不能保证正确地解析信号的含义。以下就以8位字节编码方式的CAN总线信号为例,详细分析一下两者之间的区别。
Intel编码格式
当一个信号的数据长度不超过1个字节(8位)并且信号在一个字节内实现(即该信号没有跨字节实现):该信号的高位(S_msb)将被放在该字节的高位,信号的低位(S_lsb)将被放在该字节的低位。
当一个信号的数据长度超过1个字节(8位)或者数据长度不超过一个字节但是采用跨字节方式实现时:该信号的高位(S_msb)将被放在高字节(MSB)的高位,信号的低位(S_lsb)将被放在低字节(LSB)的低位。
Motorola编码格式
当一个信号的数据长度不超过1个字节(8位)并且信号在一个字节内实现(即该信号没有跨字节实现):该信号的高位(S_msb)将被放在该字节的高位,信号的低位(S_lsb)将被放在该字节的低位。
当一个信号的数据长度超过1个字节(8位)或者数据长度不超过一个字节但是采用跨字节方式实现时:该信号的高位(S_msb)将被放在低字节(MSB)的高位,信号的低位(S_lsb)将被放在高字节(LSB)的低位。
可以看出,当一个信号的数据长度不超过1Byte时,Intel与Motorola两种格式的编码结果没有什么不同,完全一样。当信号的数据长度超过1Byte时,两者的编码结果出现了明显的不同。
二、CAN报文转换工具需求分析
1、 支持标准帧的CAN报文的转换,扩展帧暂不支持
2、 CAN报文支持Intel、motorola两种编码,先支持motorola格式,后期追加Intel格式
3、 工具具有一定的容错处理能力、报告生成能力
4、 制定统一格式,方便使用者修改测试脚本
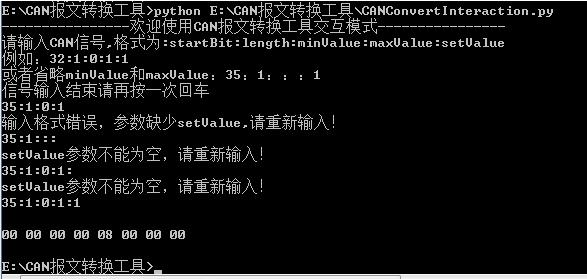
5、增加交互模式,键盘输入,控制台输出;例如:
提示语:startBit:length:minValue:maxValue:setValue
输入:35:1:0:1:1
或:35:1:::1
控制台输出:00 00 00 00 08 00 00 00
Intel和Motorola编码举例:

三、交互模式
代码如下:
import sys
print("----------------欢迎使用CAN报文转换工具交互模式----------------")
print("请输入CAN信号,格式为:startBit:length:minValue:maxValue:setValue")
print("例如:32:1:0:1:1")
print("或者省略minValue和maxValue:35:1:::1")
print("信号输入结束请再按一次回车")
#十进制转换成二进制list
def octToBin(octNum, bit):
while(octNum != 0):
bit.append(octNum%2)
octNum = int(octNum/2)
for i in range(64-len(bit)):
bit.append(0)
sig = []
startBit = []
length = []
setValue = []
#输入CAN信号
while True:
input_str = input()
if not len(input_str):
break
if(input_str.count(":")<4):
print("输入格式错误,参数缺少setValue,请重新输入!")
continue
if(input_str.split(":")[4]==""):
print("setValue参数不能为空,请重新输入!")
continue
sig.append(input_str)
#解析CAN信号
for i in range(len(sig)):
startBit.append(int(sig[i].split(":")[0]))
length.append(int(sig[i].split(":")[1]))
setValue.append(int(sig[i].split(":")[4]))
#CAN数组存放CAN报文值
CAN = []
for i in range(64):
CAN.append(-1)
for i in range(len(startBit)):
#长度超过1Byte的情况,暂不支持
if(length[i]>16):
print("CAN信号长度超过2Byte,暂不支持!!!")
sys.stdin.readline()
sys.exit()
#长度未超过1Byte的情况且未跨字节的信号
if((startBit[i]%8 + length[i])<=8):
for j in range(length[i]):
bit = []
#setValue的二进制值按字节位从低到高填
octToBin(setValue[i],bit)
#填满字节长度值
if(CAN[startBit[i]+j]==-1):
CAN[startBit[i]+j] = bit[j]
#字节存在冲突
else:
print(sig[i] + "字节位存在冲突,生成CAN报文失败!!!")
sys.stdin.readline()
sys.exit()
#跨字节的信号
else:
#高位位数和低位位数
highLen = 8 - startBit[i]%8
lowLen = length[i] - highLen
bit = []
#setValue的二进制值按字节位从低到高填
octToBin(setValue[i],bit)
#先填进信号的高位
for j1 in range(highLen):
if(CAN[startBit[i]+j1]==-1):
CAN[startBit[i]+j1] = bit[j1]
#字节存在冲突
else:
print(sig[i] + "字节位存在冲突,生成CAN报文失败!!!")
sys.stdin.readline()
sys.exit()
#再填进信号的低位
for j2 in range(lowLen):
if(CAN[(int(startBit[i]/8)-1)*8+j2]==-1):
CAN[(int(startBit[i]/8)-1)*8+j2] = bit[highLen+j2]
#字节存在冲突
else:
print(sig[i] + "字节位存在冲突,生成CAN报文失败!!!")
sys.stdin.readline()
sys.exit()
#剩余位默认值设为0
for i in range(64):
if(CAN[i]==-1):
CAN[i] = 0
#----------------将二进制list每隔8位转换成十六进制输出----------------
#其中,map()将list中的数字转成字符串,按照Motorola格式每隔8位采用了逆序
# ''.join()将二进制list转换成二进制字符串,int()将二进制字符串转换成十进制
#hex()再将十进制转换成十六进制,upper()转换成大写,两个lstrip()将"0X"删除,
#zfill()填充两位,输出不换行,以空格分隔
print(hex(int(''.join(map(str,CAN[7::-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[15:7:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[23:15:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[31:23:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[39:31:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[47:39:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[55:47:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[63:55:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2))
运行截图:

错误提示:
四、配置项模式
配置文件如下:
##注释 ::start #编码格式:0=Intel;1=Motorola encodeType=1 #帧格式:0=标准帧;1=扩展帧; canMode=0 #帧类型:0=数据帧;... canType=0 #默认初始值(0~1) defaultValue=0 #MSG定义 msgName=BCM_FrP01 msgID=0x2CD #长度(BYTE) msgLength=8 #signal定义 #sigName=name:startBit:length:minValue:maxValue:setValue #sigName=ReverseSw:25:6:0:1:13 #sigName=Trunk_BackDoor_Sts:33:2:0:1:2 #sigName=DRVUnlockState:37:2:0:1:3 #sigName=HeadLampLowBeam:40:8:0:1:60 #sigName=HoodStatus:51:1:0:1:0 #sigName=HeadLampHighBeam:52:1:0:1:0 #sigName=RLDoorStatus:59:1:0:1:0 #sigName=RRDoorStatus:58:1:0:1:0 #sigName=PsgDoorStatus:57:2:0:1:0 sigName=One:0:8:0:255:165 sigName=Two:24:12:0:4095:1701 sigName=Three:54:5:0:31:25 ::end ::start #编码格式:0=Intel;1=Motorola encodeType=1 #帧格式:0=标准帧;1=扩展帧; canMode=0 #帧类型:0=数据帧;... canType=0 #默认初始值(0~1) defaultValue=0 #MSG定义 msgName=BCM_FrP msgID=0x2CD #长度(BYTE) msgLength=8 #signal定义 #sigName=name:startBit:length:minValue:maxValue:setValue #sigName=ReverseSw:25:6:0:1:13 #sigName=Trunk_BackDoor_Sts:33:2:0:1:2 #sigName=DRVUnlockState:37:2:0:1:3 #sigName=HeadLampLowBeam:40:8:0:1:60 #sigName=HoodStatus:51:1:0:1:0 #sigName=HeadLampHighBeam:52:1:0:1:0 #sigName=RLDoorStatus:59:1:0:1:0 #sigName=RRDoorStatus:58:1:0:1:0 #sigName=PsgDoorStatus:57:2:0:1:0 sigName=One:35:1:0:1:1 ::end
代码如下:
#!/usr/bin/python
defaultValue = 0
sigName = []
startBit = []
length = []
minValue = []
maxValue = []
setValue = []
#CAN数组存放CAN报文值
CAN = []
logFile = open("log.txt","w")
def parseConfig():
config = open("Config.txt","r")
count = 0
isError = False
for line in config:
line = line.strip()
#注释
if(line.find("#")>=0):
continue
#开始标记
elif(line.find("::start")>=0):
count = count + 1
isError = False
if(count>1):
sigName.clear()
startBit.clear()
length.clear()
setValue.clear()
continue
else:
continue
elif(isError == True):
continue
#编码格式
elif(line.find("encodeType")>=0):
encodeType = line.split("=")[1]
if(encodeType != "1"):
isError = True
print(str(count) + ". CAN报文生成失败!!!目前仅支持Motorola编码格式,暂不支持Intel编码格式!")
logFile.write("%d. CAN报文生成失败!!!目前仅支持Motorola编码格式,暂不支持Intel编码格式!\n" % count)
continue
#帧格式
elif(line.find("canMode")>=0):
canMode = line.split("=")[1]
if(canMode != "0"):
isError = True
print(str(count) + ". CAN报文生成失败!!!目前仅支持标准帧,暂不支持扩展帧!")
logFile.write("%d. CAN报文生成失败!!!目前仅支持标准帧,暂不支持扩展帧!\n" % count)
continue
#帧类型
elif(line.find("canType")>=0):
canType = line.split("=")[1]
if(canType != "0"):
isError = True
print(str(count) + ". CAN报文生成失败!!!目前仅支持数据帧,暂不支持其他帧!")
logFile.write("%d. CAN报文生成失败!!!目前仅支持数据帧,暂不支持其他帧!\n" % count)
continue
#默认初始值
elif(line.find("defaultValue")>=0):
global defaultValue
defaultValue = int(line.split("=")[1])
#MSG名称
elif(line.find("msgName")>=0):
msgName = line.split("=")[1]
#MSGID
elif(line.find("msgID")>=0):
msgID = line.split("=")[1]
#MSG长度
elif(line.find("msgLength")>=0):
msgLength = line.split("=")[1]
#signal定义
elif(line.find("sigName")>=0):
sigName.append(line.split(":")[0].split("=")[1])
startBit.append(int(line.split(":")[1]))
length.append(int(line.split(":")[2]))
#minValue.append(int(line.split(":")[3]))
#maxValue.append(int(line.split(":")[4]))
setValue.append(int(line.split(":")[5]))
elif(line.find("::end")>=0):
rV,errMsg = getCANMessage()
if(rV == "-1"):
isError = True
print(str(count) + ". CAN报文生成失败!!!" + errMsg)
logFile.write("%d. CAN报文生成失败!!!%s\n" % (count,errMsg))
continue
print(str(count) + ". CAN报文生成成功!!!")
logFile.write("%d. CAN报文生成成功!!!\n" % count)
#----------------------------输出标题信息----------------------------
print("msgName\t\tmsgID\t\tmsgLen\t\tmsgData")
logFile.write("msgName\t\tmsgID\t\tmsgLen\t\tmsgData\n")
if(len(msgName)<8):
print(msgName + "\t\t",end="")
logFile.write("%s\t\t" % msgName)
else:
print(msgName + "\t",end="")
logFile.write("%s\t" % msgName)
print(msgID + "\t\t",end="")
logFile.write("%s\t\t" % msgID)
print(msgLength + "\t\t",end="")
logFile.write("%s\t\t" % msgLength)
#----------------将二进制list每隔8位转换成十六进制输出----------------
#其中,map()将list中的数字转成字符串,按照Motorola格式每隔8位采用了逆序
# ''.join()将二进制list转换成二进制字符串,int()将二进制字符串转换成十进制
#hex()再将十进制转换成十六进制,upper()转换成大写,两个lstrip()将"0X"删除,
#zfill()填充两位,输出不换行,以空格分隔
print(hex(int(''.join(map(str,CAN[7::-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[15:7:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[23:15:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[31:23:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[39:31:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[47:39:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[55:47:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2) + " ",end="")
print(hex(int(''.join(map(str,CAN[63:55:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2))
logFile.write("%s " % hex(int(''.join(map(str,CAN[7::-1])),2)).upper().lstrip("0").lstrip("X").zfill(2))
logFile.write("%s " % hex(int(''.join(map(str,CAN[15:7:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2))
logFile.write("%s " % hex(int(''.join(map(str,CAN[23:15:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2))
logFile.write("%s " % hex(int(''.join(map(str,CAN[31:23:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2))
logFile.write("%s " % hex(int(''.join(map(str,CAN[39:31:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2))
logFile.write("%s " % hex(int(''.join(map(str,CAN[47:39:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2))
logFile.write("%s " % hex(int(''.join(map(str,CAN[55:47:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2))
logFile.write("%s\n" % hex(int(''.join(map(str,CAN[63:55:-1])),2)).upper().lstrip("0").lstrip("X").zfill(2))
config.close()
#十进制转换成二进制list
def octToBin(octNum, bit):
while(octNum != 0):
bit.append(octNum%2)
octNum = int(octNum/2)
for i in range(64-len(bit)):
bit.append(0)
#获取CAN报文值
def getCANMessage():
CAN.clear()
for i in range(64):
CAN.append(-1)
for i in range(len(startBit)):
#长度超过1Byte的情况,暂不支持
if(length[i]>16):
errMsg = " CAN信号长度超过2Byte,暂不支持!!!"
#print(sigName[i] + errMsg)
return "-1",errMsg
#长度未超过1Byte的情况且未跨字节的信号
if((startBit[i]%8 + length[i])<=8):
for j in range(length[i]):
bit = []
#setValue的二进制值按字节位从低到高填
octToBin(setValue[i],bit)
#填满字节长度值
if(CAN[startBit[i]+j]==-1):
CAN[startBit[i]+j] = bit[j]
#字节存在冲突
else:
errMsg = " 字节位存在冲突,生成CAN报文失败!!!"
#print(sigName[i] + errMsg)
return "-1",errMsg
#跨字节的信号
else:
#高位位数和低位位数
highLen = 8 - startBit[i]%8
lowLen = length[i] - highLen
bit = []
#setValue的二进制值按字节位从低到高填
octToBin(setValue[i],bit)
#先填进信号的高位
for j1 in range(highLen):
if(CAN[startBit[i]+j1]==-1):
CAN[startBit[i]+j1] = bit[j1]
#字节存在冲突
else:
errMsg = " 字节位存在冲突,生成CAN报文失败!!!"
#print(sigName[i] + errMsg)
return "-1",errMsg
#再填进信号的低位
for j2 in range(lowLen):
if(CAN[(int(startBit[i]/8)-1)*8+j2]==-1):
CAN[(int(startBit[i]/8)-1)*8+j2] = bit[highLen+j2]
#字节存在冲突
else:
errMsg = " 字节位存在冲突,生成CAN报文失败!!!"
#print(sigName[i] + errMsg)
return "-1",errMsg
#剩余位设为默认值
for i in range(64):
if(CAN[i]==-1):
CAN[i] = defaultValue
#若无错误则返回正确值
return "0","success!"
if __name__ == "__main__":
#调用parseConfig()函数开始执行程序
parseConfig()
运行结果:
1. CAN报文生成成功!!! msgName msgID msgLen msgData BCM_FrP01 0x2CD 8 A5 00 06 A5 00 06 40 00 2. CAN报文生成成功!!! msgName msgID msgLen msgData BCM_FrP 0x2CD 8 00 00 00 00 08 00 00 00
以上这篇Python实现CAN报文转换工具教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python通过tcp发送xml报文的方法
如下所示: # -*- coding: utf-8 -*- import socket # 使用tcp发送请求报文 def tcpsend(ip, port, xmlbw): address = (ip, port) client = socket.socket(socket.AF_INET, socket.SOCK_STREAM) client.connect(address) by = xmlbw.encode('utf8') # 转为字节数组 # print by client.send(
-
python构造IP报文实例
我就废话不多说了,大家还是直接看代码吧! import socket import sys import time import struct HOST, PORT = "10.60.66.66", 10086 def make_forward_iphdr(source_ip = '1.0.0.1', dest_ip = '2.0.0.2', proto = socket.IPPROTO_UDP) : # ip header fields ip_ihl = 5 ip_ver = 4 i
-
Python实现CAN报文转换工具教程
一.CAN报文简介 CAN是控制器局域网络(Controller Area Network, CAN)的简称,是由以研发和生产汽车电子产品著称的德国BOSCH公司开发的,并最终成为国际标准(ISO 11898),是国际上应用最广泛的现场总线之一. 在北美和西欧,CAN总线协议已经成为汽车计算机控制系统和嵌入式工业控制局域网的标准总线,并且拥有以CAN为底层协议专为大型货车和重工机械车辆设计的J1939协议. CAN总线以报文为单位进行数据传送.CAN报文按照帧格式可分为标准帧和扩展帧,标准帧是具
-

基于Python制作一个多进制转换工具
目录 前言 主要步骤 完整代码 前言 学习资料下载链接 提取码:tha8 进制转换计算工具含源文件 主要步骤 导入模块 import tkinter from tkinter import * import tkinter as tk from tkinter.ttk import * 整个框架的主结构 root = Tk() root.title('贱工坊-进制转换计算') # 程序的标题名称 root.geometry("580x400+512+288") # 窗口的大小及页面的
-
基于Python实现简单的汉字拼音转换工具
目录 1.准备 2.基本使用 3.高级使用 将汉字转为拼音,可以用于批量汉字注音.文字排序.拼音检索文字等常见场景. 现在互联网上有许多拼音转换工具,基于Python的开源模块也不少,今天给大家介绍一个功能特性最多的模块: pypinyin ,它支持以下特性: 1. 根据词组智能匹配最正确的拼音. 2. 支持多音字. 3. 简单的繁体支持, 注音支持. 4. 支持多种不同拼音/注音风格. 5. 命令行工具一键转化 1.准备 开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,
-
Python实现将罗马数字转换成普通阿拉伯数字的方法
本文实例讲述了Python实现将罗马数字转换成普通阿拉伯数字的方法.分享给大家供大家参考,具体如下: 罗马数字,我们在某些电视中或者现实生活中都曾经看到过,近日,学习Python时,也遇到了罗马数字的解说,于是顺便写了一个小程序来练习罗马数字到我们日常生活普通数字之间的转换的小函数. 首先,咱们了解一下,罗马数字的潜在法则, 在罗马数字中,利用7个不同字母进行重复或者组合来表达各式各样的数字. I = 1 V = 5 X = 10 L = 50 C = 100 D = 500 M = 1000
-
Python时间和字符串转换操作实例分析
本文实例讲述了Python时间和字符串转换操作.分享给大家供大家参考,具体如下: 例子: #!/usr/bin/python # -*- coding: UTF-8 -*- import time # 格式化成2016-03-20 11:45:39形式 print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 格式化成Sat Mar 28 22:24:24 2016形式 print time.strftime("
-
Python实现将Excel转换成xml的方法示例
本文实例讲述了Python实现将Excel转换成xml的方法.分享给大家供大家参考,具体如下: 最近写了个小工具 用于excel转成xml 直接贴代码吧: #coding=utf-8 import xlrd import datetime import time import sys import xml.dom.minidom import os print sys.getdefaultencoding() reload(sys) #就是这么坑爹,否则下面会报错 sys.setdefaulte
-
Python安装Jupyter Notebook配置使用教程详解
为什么要用Jupyter Notebook 推荐新手写python用什么编辑器就有有人问:为什么没有Jupyter Notebook.本来想数据分析和可视化的时候才介绍的,所以没有加上.最近要截图比较多,用Jupyter Notebook可以很好看到代码和结果. Jupyter Notebook是什么 Jupyter Notebook是一个开源的web应用程序,一个交互式笔记本,支持运行 40 多种编程语言.它允许您创建和共享文档,包含代码,方程,可视化和叙事文本.用途包括:数据清洗和转换,数值
-
python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)
[python爬虫基础入门]系列是对python爬虫的一个入门练习实践,旨在用最浅显易懂的语言,总结最明了,最适合自己的方法,本人一直坚信,总结才会使人提高 1. BeautifulSoup库简介 BeautifulSoup库在python中被美其名为"靓汤",它和和 lxml 一样也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,若在没用安装此库的情况下
-
python编程Flask框架简单使用教程
目录 基础知识 使用框架的优点: Flask常用扩展包: 基本格式: 拓展: return 重定向 取网址参数 content-type cookie\session flask路由 request属性 上下文 注册路由 基础知识 使用框架的优点: 稳定性和可扩展性强 可以降低开发难度,提高了开发效率 Flask诞生于2010年,是Armin ronacher用Python语言基于Werkzeug工具箱编写的轻量级Web开发框架 Flask本身相当于一个内核,其他几乎所有的功能都要用到扩展(邮件
-
Python格式化字符串f-string的使用教程
目录 楔子 实现 repr 打印 整数的进制转换 整数的填充 浮点数的小数保留 任意字符的填充 日期的截取 f-string 的注意事项 小结 楔子 在 Python3.6 之前,格式化字符串一般会使用百分号占位符或者 format 函数,举个例子: name = "古明地觉" address = "地灵殿" # 使用百分号占位符格式化字符串 print( "我是 %s, 来自 %s" % (name, address) ) # 我是