MySQL组提交group commit详解
目录
- 引 言
- 前提:
- 背景说明:
- 图解:
- Flush 阶段 (图中第一个渡口)
- Sync 阶段 (图中第二个渡口)
- Commit 阶段 (图中第三个渡口)
- 缺陷分析:
引 言
前提:
- 以下讨论的前提 是设置MySQL的crash safe相关参数为双1:
sync_binlog=1
innodb_flush_log_at_trx_commit=1
背景说明:
- WAL机制 (Write Ahead Log)定义: WAL指的是对数据文件进行修改前,必须将修改先记录日志。MySQL为了保证ACID中的一致性和持久性,使用了WAL。
- Redo log的作用: Redo log就是一种WAL的应用。当数据库忽然掉电,再重新启动时,MySQL可以通过Redo log还原数据。也就是说,每次事务提交时,不用同步刷新磁盘数据文件,只需要同步刷新Redo log就足够了。相比写数据文件时的随机IO,写Redo log时的顺序IO能够提高事务提交速度。
- 组提交的作用:
- 在没有开启binlog时
Redo log的刷盘操作将会是最终影响MySQL TPS的瓶颈所在。为了缓解这一问题,MySQL使用了组提交,将多个刷盘操作合并成一个,如果说10个事务依次排队刷盘的时间成本是10,那么将这10个事务一次性一起刷盘的时间成本则近似于1。
- 当开启binlog时
为了保证Redo log和binlog的数据一致性,MySQL使用了二阶段提交,由binlog作为事务的协调者。而 引入二阶段提交 使得binlog又成为了性能瓶颈,先前的Redo log 组提交 也成了摆设。为了再次缓解这一问题,MySQL增加了binlog的组提交,目的同样是将binlog的多个刷盘操作合并成一个,结合Redo log本身已经实现的 组提交,分为三个阶段(Flush 阶段、Sync 阶段、Commit 阶段)完成binlog 组提交,最大化每次刷盘的收益,弱化磁盘瓶颈,提高性能。
图解:
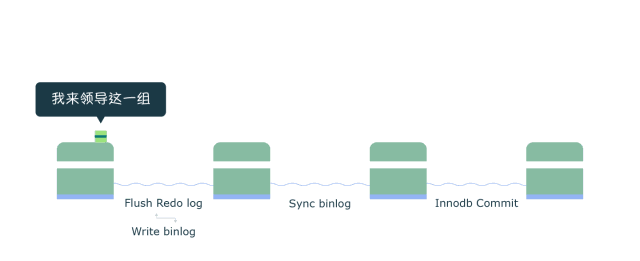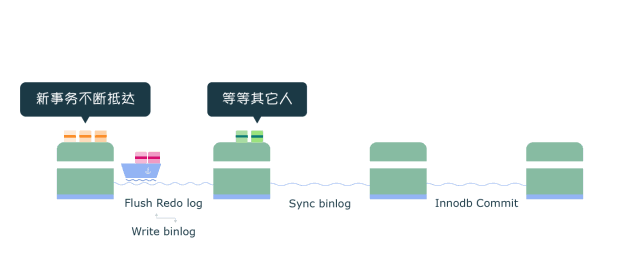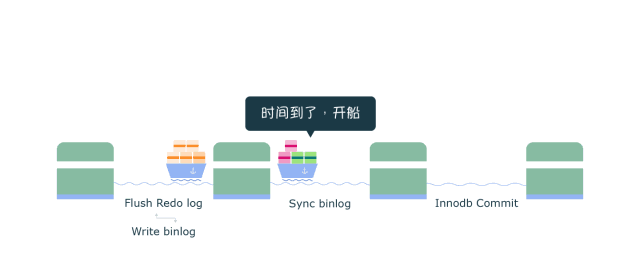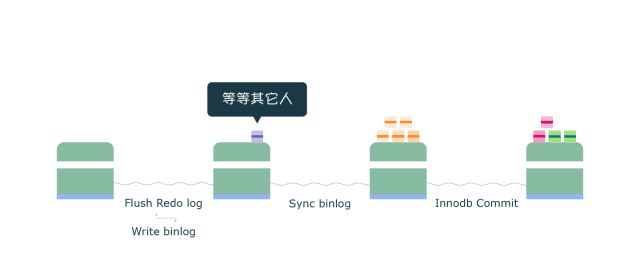
下图我们假借“渡口运输”的例子来看看binlog 组提交三个阶段的流程:

在MySQL中每个阶段都有一个队列,每个队列都有一把锁保护,第一个进入队列的事务会成为leader,leader领导所在队列的所有事务,全权负责整队的操作,完成后通知队内其他事务操作结束。
Flush 阶段 (图中第一个渡口)
- 首先获取队列中的事务组
- 将Redo log中prepare阶段的数据刷盘(图中Flush Redo log)
- 将binlog数据写入文件,当然此时只是写入文件系统的缓冲,并不能保证数据库崩溃时binlog不丢失 (图中Write binlog)
- Flush阶段队列的作用是提供了Redo log的组提交
- 如果在这一步完成后数据库崩溃,由于协调者binlog中不保证有该组事务的记录,所以MySQL可能会在重启后回滚该组事务
Sync 阶段 (图中第二个渡口)
- 这里为了增加一组事务中的事务数量,提高刷盘收益,MySQL使用两个参数控制获取队列事务组的时机:
binlog_group_commit_sync_delay=N:在等待N μs后,开始事务刷盘(图中Sync binlog)
binlog_group_commit_sync_no_delay_count=N:如果队列中的事务数达到N个,就忽视binlog_group_commit_sync_delay的设置,直接开始刷盘(图中Sync binlog)
- Sync阶段队列的作用是支持binlog的组提交
- 如果在这一步完成后数据库崩溃,由于协调者binlog中已经有了事务记录,MySQL会在重启后通过Flush 阶段中Redo log刷盘的数据继续进行事务的提交
Commit 阶段 (图中第三个渡口)
- 首先获取队列中的事务组
- 依次将Redo log中已经prepare的事务在引擎层提交(图中InnoDB Commit)
- Commit阶段不用刷盘,如上所述,Flush阶段中的Redo log刷盘已经足够保证数据库崩溃时的数据安全了
- Commit阶段队列的作用是承接Sync阶段的事务,完成最后的引擎提交,使得Sync可以尽早的处理下一组事务,最大化组提交的效率
缺陷分析:
本文最后要讨论的bug(可通过阅读原文查看)就是来源于Sync 阶段中的那个binlog参数binlog_group_commit_sync_delay,在MySQL 5.7.19中,如果该参数不为10的倍数,则会导致事务在Sync 阶段等待极大的时间,表现出来的现象就是执行的sql长时间无法返回。该bug已在MySQL 5.7.24和8.0.13被修复。
到此这篇关于MySQL组提交(group commit)的文章就介绍到这了,更多相关MySQL组提交内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

浅谈MySQL中的group by
目录 1.前言 2.准备user表 2.1 group by规则 2.2 group by使用 2.3 having使用 2.4 order by与limit 2.5 with rollup 1.前言 MySQL的group by用于对查询的数据进行分组:此外MySQL提供having子句对分组内的数据进行过滤. MySQL提供了许多select子句关键字, 它们在语句中的顺序如下所示: 子句 作用 是否必须/何时使用 select 查询要返回的数据或者表达式 是 from 指定查询的表 否 w
-
MySQL 事务autocommit自动提交操作
MySQL默认操作模式就是autocommit自动提交模式.这就表示除非显式地开始一个事务,否则每个查询都被当做一个单独的事务自动执行.我们可以通过设置autocommit的值改变是否是自动提交autocommit模式. 通过以下命令可以查看当前autocommit模式 mysql> show variables like 'autocommit'; +---------------+-------+ | Variable_name | Value | +---------------+----
-
MySQL Group by的优化详解
一个标准的 Group by 语句包含排序.分组.聚合函数,比如 select a,count(*) from t group by a ; 这个语句默认使用 a 进行排序.如果 a 列没有索引,那么就会创建临时表来统计 a和 count(*),然后再通过 sort_buffer 按 a 进行排序. 标准的执行流程 结构: create table t1(id int primary key, a int, b int, index(a)); delimiter ;; create proce
-
MySQL数据库分组查询group by语句详解
一:分组函数的语句顺序 1 SELECT ... 2 FROM ... 3 WHERE ... 4 GROUP BY ... 5 HAVING ... 6 ORDER BY ... 二:WHERE和HAVING筛选条件的区别 数据源 位置 关键字 WHERE 原始表 ORDER BY语句之前 WHERE HAVING 分组后的结果集 ORDER BY语句之后 HAVING 三:举例说明 #1.查询每个班学生的最大年龄 SELECT MAX(age),class FROM STU_CLASS GR
-
MySql是否需要commit详解
mysql在进行如插入(insert)操作的时候需不需要commit,这得看你的存储引擎, 如果是不支持事务的引擎,如myisam,则是否commit都没有效的. 如果是支持事务的引擎,如innodb,则得知道你事物支持是否自动提交事务(即commit) 看自己的数据库是否是自动commit,可以使用mysql> show variables like '%autocommit%';来进行查看,如果是OFF即不自动commit,需要手动commit操作(命令行可以直接"commit:&qu
-
MySQL group by语句如何优化
在MySQL中,新建立一张表,该表有三个字段,分别是id,a,b,插入1000条每个字段都相等的记录,如下: mysql> show create table t1\G *************************** 1. row *************************** Table: t1 Create Table: CREATE TABLE `t1` ( `id` int(11) NOT NULL, `a` int(11) DEFAULT NULL, `b` int(1
-
MySQL组提交group commit详解
目录 引 言 前提: 背景说明: 图解: Flush 阶段 (图中第一个渡口) Sync 阶段 (图中第二个渡口) Commit 阶段 (图中第三个渡口) 缺陷分析: 引 言 前提: 以下讨论的前提 是设置MySQL的crash safe相关参数为双1: sync_binlog=1 innodb_flush_log_at_trx_commit=1 背景说明: WAL机制 (Write Ahead Log)定义: WAL指的是对数据文件进行修改前,必须将修改先记录日志.MySQL为了保证ACID中
-
mysql获取分组后每组的最大值实例详解
mysql获取分组后每组的最大值实例详解 1. 测试数据库表如下: create table test ( `id` int not null auto_increment, `name` varchar(20) not null default '', `score` int not null default 0, primary key(`id`) )engine=InnoDB CHARSET=UTF8; 2. 插入如下数据: mysql> select * from test; +---
-
MySQL之高可用架构详解
目录 引言 MySQL高可用 一主一备: MySQL主从同步的几种模式: 总结 引言 "高可用"是互联网一个永恒的话题,先避开MySQL不谈,为了保证各种服务的高可用有几种常用的解决方案. 服务冗余:把服务部署多份,当某个节点不可用时,切换到其他节点.服务冗余对于无状态的服务是相对容易的. 服务备份:有些服务是无法同时存在多个运行时的,比如说:Nginx的反向代理,一些集群的leader节点.这时可以存在一个备份服务,处于随时待命状态. 自动切换:服务冗余之后,当某个节点不可用时,要做
-
MYSQL大量写入问题优化详解
摘要:大家提到Mysql的性能优化都是注重于优化sql以及索引来提升查询性能,大多数产品或者网站面临的更多的高并发数据读取问题.然而在大量写入数据场景该如何优化呢? 今天这里主要给大家介绍,在有大量写入的场景,进行优化的方案. 总的来说MYSQL数据库写入性能主要受限于数据库自身的配置,以及操作系统的性能,磁盘IO的性能.主要的优化手段包括以下几点: 1.调整数据库参数 (1) innodb_flush_log_at_trx_commit 默认为1,这是数据库的事务提交设置参数,可选值如下: 0
-
mysql语法之DQL操作详解
目录 简单查询 运算符查询 排序查询 聚合查询 分组查询 分页查询 一张表查询结果插入到另一张表 SQL语句分析 DQL小练习1 DQL小练习2 正则表达式 总结 DQL(Data Query Language),数据查询语言,主要是用来查询数据的,这也是SQL中最重要的部分! 简单查询 #DQL操作之基本查询 #创建数据库 CREATE DATABASE IF NOT EXISTS mydb2; #使用数据库 USE mydb2; #创建表 CREATE TABLE IF NOT EXISTS
-
MySQL事务管理的作用详解
目录 1.为何使用事务管理 2.数据库事务的原理 3.什么是事务 3.1 事务的特性ACID 3.2 事务的并发问题 3.3 隔离级别 4.Spring事务管理 1.为何使用事务管理 可以保证数据的完整性.事务(Transaction),就是将一组SQL语句放在同一批次内去执行,如果一个SQL语句出错,则该批次内 的所有SQL都将被取消执行. 例子: 转账为例. 金庸向张无忌转账1000元.----在数据库中修改两个账号的余额. 发生意外情况,则出现金庸减钱成功,而张无忌加钱失败. 如何解决?
-
redhat7.1 安装mysql 5.7.10步骤详解(图文详解)
在redhat下安装MySQL,步骤如下 Mysql目录安装位置:/usr/local/mysql 数据库保存位置:/data/mysql 日志保存位置:/data/log/mysql 下载安装包 http://downloads.mysql.com/archives/community/ 1. 获取mysql安装包,mysql-5.7.10-Linux-glibc2.5-x86_64.tar解压后目录如下. 2. 解压mysql-5.7.10-linux-glibc2.5-x86_64.tar
-
Git 创建分支提交远程分支详解
Git 创建分支提交远程分支详解 1.创建本地分支 git branch 分支名,例如:git branch 2.0.1.20120806 注:2.0.1.20120806是分支名称,可以随便定义. 2.切换本地分支 git checkout 分支名,例如从master切换到分支:git checkout 2.0.1.20120806 3.远程分支就是本地分支push到服务器上.比如master就是一个最典型的远程分支(默认). git push origin 2.0.1.20120806 4.
-
CentOS 6.6 源码编译安装MySQL 5.7.18教程详解
一.添加用户和组 1.添加mysql用户组 # groupadd mysql 2.添加mysql用户 # useradd -g mysql -s /bin/nologin mysql -M 二.查看系统中是否安装mysql,如果安装需要卸载 # rpm -qa | grep mysql mysql-libs-5.1.73-3.el6_5.x86_64 # rpm -e mysql-libs-5.1.73-3.el6_5.x86_64 --nodeps 三.安装所需依赖包 # yum -y ins
-
MySQL 去除重复数据实例详解
MySQL 去除重复数据实例详解 有两个意义上的重复记录,一是完全重复的记录,也即所有字段均都重复,二是部分字段重复的记录.对于第一种重复,比较容易解决,只需在查询语句中使用distinct关键字去重,几乎所有数据库系统都支持distinct操作.发生这种重复的原因主要是表设计不周,通过给表增加主键或唯一索引列即可避免. select distinct * from t; 对于第二类重复问题,通常要求查询出重复记录中的任一条记录.假设表t有id,name,address三个字段,id是主键,有重