解决Java & Idea启动tomcat的中文乱码问题
问题描述
idea启动tomcat后乱码了,并且,idea的各种编码都是设置的为UTF-8,但是中文就是乱码了。
解决方法
进入idea的安装目录, 进入bin目录下。找到idea.exe.vmoptions这个文件 和 idea64.exe.vmoptions, 在两个文件的最后一行加入
-Dfile.encoding=UTF-8。
重启idea,再次启动tomcat,乱码问题应该就解决了。

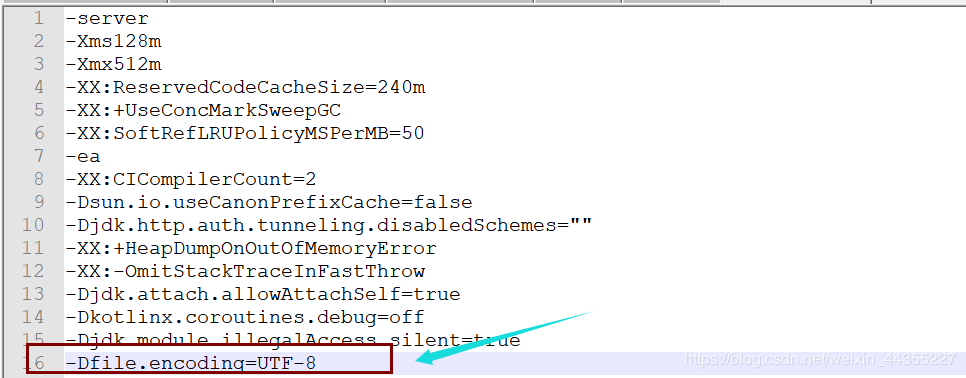
在Idea上点击我的Tomcat
我的小猫----> 选择第一个Edit Configuration
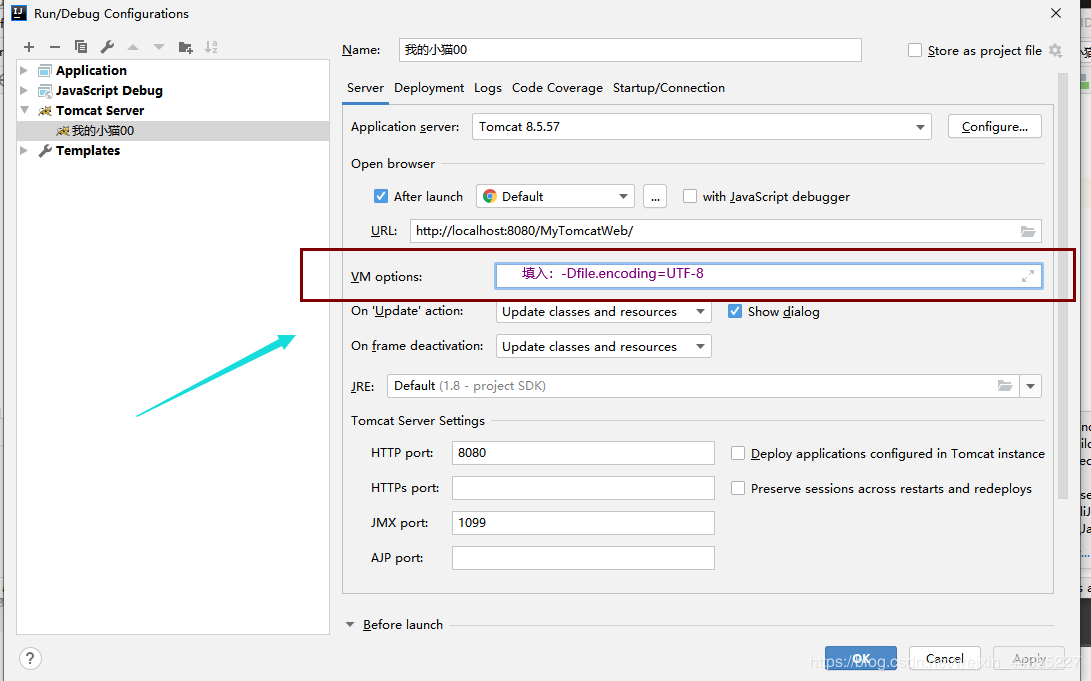
到此这篇关于Java & Idea启动tomcat的中文乱码问题的文章就介绍到这了,更多相关 Idea启动tomcat的中文乱码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
tomcat服务器如何配置字符集为utf-8彻底解决中文乱码的问题详解
什么是字符集 在介绍字符集之前,我们先了解下为什么要有字符集.我们在计算机屏幕上看到的是实体化的文字,而在计算机存储介质中存放的实际是二进制的比特流.那么在这两者之间的转换规则就需要一个统一的标准,否则把我们的U盘插到老板的电脑上,文档就乱码了:小伙伴QQ上传过来的文件,在我们本地打开又乱码了.于是为了实现转换标准,各种字符集标准就出现了.简单的说字符集就规定了某个文字对应的二进制数字存放方式(编码)和某串二进制数值代表了哪个文字(解码)的转换关系. 那么为什么会有那么多字符集标准呢?这个问题实
-
IDEA 启动 Tomcat 项目输出乱码的解决方法
刚开始碰到的时候没调试成功又放下了,老系统放在 MyEclipse 下面跑,这两天 MyEclipse 和 Tomcat 老出问题,借着这个机会又试了试,成功了. 大部分调试方法来自这里,但是有微调. 在 tomcat Server 中设置 VM options , 值为 -Dfile.encoding=UTF-8,可惜没生效 注意: 刚开始我也是设成UTF-8,但设了一圈回来,Console 窗口里日志行的信息两个字是生效了,但日志行内容还是乱码,于是试着把这一步的设置改成 GBK,居然成功了
-
解决Linux下Tomcat向MySQL插入数据中文乱码问题
一.问题 在windows上面使用eclipse开发的项目在windows上面运行一切正常,部署到腾讯云时出现向MySQL数据库中插入数据是中文乱码 二.解决办法 1.尝试一 直接在linux上面使用insert语句插入中文,正常 2.尝试二 在tomcat配置文件server.xml中加入useBodyEncodingForURI="true",不行 3.尝试三 在tomcat配置文件server.xml中再加入URIEncoding="UTF-8",不行 4.尝
-
解决IDEA 启动Tomcat控制台乱码问题
今天在Idea中用Tomcat跑一个Web项目,启动后,Tomcat日志在控制台打印出来都是乱码,如下图所示: 这个问题是Tomcat的编码问题引起的,解决该问题可以进行如下配置: -Dfile.encoding=UTF-8 如果还不行,就这样: 点击确定.重启TOMCAT进行调试,可以看到控制台中tomcat日志中的中文能正常显示了. 上面基本上应该不会出现乱码啦 如上述全部尝试还是乱码则需要修改配置文件 进入idea的安装目录, 进入bin目录下.找到idea.exe.vmoptions这个
-
解决Java & Idea启动tomcat的中文乱码问题
问题描述 idea启动tomcat后乱码了,并且,idea的各种编码都是设置的为UTF-8,但是中文就是乱码了. 解决方法 进入idea的安装目录, 进入bin目录下.找到idea.exe.vmoptions这个文件 和 idea64.exe.vmoptions, 在两个文件的最后一行加入 -Dfile.encoding=UTF-8. 重启idea,再次启动tomcat,乱码问题应该就解决了. 在Idea上点击我的Tomcat我的小猫----> 选择第一个Edit Configuration 到
-
IDEA启动tomcat控制台中文乱码问题的解决方法(100%有效)
目录 第一步: 第二步: 第三步: 总结 IntelliJ IDEA是很多程序员必备且在业界被公认为最好的Java开发工具,有很多小伙伴在安装完IDEA并且tomcat之后,启动tomcat会出现控制台中文乱码问题,如下图所示: 接下来,带大家一起去解决这个问题 第一步: 点击File→Settings Editor→File Encodings 第二步: 点击Run→Edit Configurations Tomcat Server→Tomcat1(Tomcat1是自己定义的名字,可以不一致)
-

idea启动Tomcat时控制台乱码的解决方法(亲测有效)
目录 前言 解决方法: 方法一: 方法二: 方法三: 方法四: 总结 前言 很多人在idea中启动项目时会出现控制台的中文乱码,其实也无伤大雅,但是本人看着不舒服所以在网上查找了一些方法和各位分享一下 解决方法: 方法一: 1.打开tomcat配置页面,Edit Configurations. 2.选择项目部署的tomcat,在配置项VM options输入框中输入-Dfile.encoding=UTF-8,点击Apply或OK即可. 3.修改idea设置里的文件编码格式为utf-8. 我修改了
-
idea启动spring项目中文乱码的解决方法
使用 tomcat8 使用idea启动spring项目(前端jsp)时,发现控制台打印日志的中文全部都乱码,页面部分乱码,从请求分析得到,从后台返回的数据是正常的,只是js里面写死的数据是乱码 从这些信息可以分析得到, 控制台日志中文乱码, 但后台返回前端的编码方式是正常的, 前端js的数据中文乱码 解决方案: 1.控制日志乱码: 这些日志都是容器打印出来的,所以需要是配置容器, tomcat>conf>logging.properties把其它编码换成GBK 2.js中文乱码: 静态js也经
-
解决Ajax加载JSon数据中文乱码问题
一.问题描述 使用zTree的异步刷新父级菜单时,服务器返回中文乱码,但项目中使用了SpringMvc,已经对中文乱码处理,为什么还会出现呢? 此处为的异步请求的配置: Java代码 async: { enable: true, url: basePath + '/sysMenu/listSysMenu', autoParam: ["id=parentId"] } SpringMvc中文字符处理: Java代码 <mvc:annotation-driven> <mvc
-
基于Java创建XML(无中文乱码)过程解析
这篇文章主要介绍了基于Java创建XML(无中文乱码)过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 package com.zyb.xml; import java.io.FileOutputStream; import java.io.OutputStream; import java.io.OutputStreamWriter; import java.io.Writer; import org.dom4j.Document; i
-
解决MySQL客户端输出窗口显示中文乱码问题的办法
最近发现,在MySQL的dos客户端输出窗口中查询表中的数据时,表中的中文数据都显示成乱码,如下图所示: 上网查了一下原因:之所以会显示乱码,就是因为MySQL客户端输出窗口显示中文时使用的字符编码不对造成的,可以使用如下的命令查看输出窗口使用的字符编码:show variables like 'char%'; 命令执行完成之后显示结果如下所示: 可以看到,现在是使用utf8字符编码来显示中文数据的,但是因为操作系统是中文操作系统,默认使用的字符集是GB2312,所以需要把输出窗口使用的字符编码
-
解决python使用open打开文件中文乱码的问题
代码如下: 先在D盘下新建一个html文档,然后在里面输入含有中文的Html字符如下图,然后我们首先使用中文格式对读取的字符进行解码再用utf-8的模式对字符进行进行编码,然后就能正确输出中文字符 # -*- coding: UTF-8 -*- file1 = open("D:/1.html", mode='rb+') data = file1.read().decode('gbk').encode('utf-8') print data 以上这篇解决python使用open打开文件中
-
解决python中使用PYQT时中文乱码问题
如题,解决Python中用PyQt时中文乱码问题的解决方法: 在中文字符串前面加上u,如u'你好,世界',其他网上的方法没有多去探究,Python的版本也会影响解决方法,故这里只推荐这种. (有人说用toLocal8bit函数也可以,我试了下,貌似不行)请看例子: #coding=utf-8 from PyQt4 import QtGui, QtCore s = QtCore.QString(u'你好(hello)世界(world)') t = s.toLocal8Bit() u = unico
-
解决python ogr shp字段写入中文乱码的问题
首先,先确认一下你的字段值是不是乱码,如果是,按照以下方法: 我的字段值是来自于一个geojson字符串,我在对它解析时做了如下处理: properties = fea.get("properties") pro_json=json.dumps(properties) pro_json.replace('u\'','\'')#将unicode编码转化为中文先处理一下 pro_json=pro_json.decode("unicode-escape") #将unico