Java dom4j创建解析xml文档过程解析
DOM4J解析
特征:
1、JDOM的一种智能分支,它合并了许多超出基本XML文档表示的功能。
2、它使用接口和抽象基本类方法。
3、具有性能优异、灵活性好、功能强大和极端易用的特点。
4、是一个开放源码的文件
jar包:dom4j-1.6.1.jar

创建 book.xml:
package com.example.xml.dom4j;
import java.io.FileWriter;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
/**
* dom4j创建xml文档示例
*
*/
public class Dom4JTest4 {
public static void main(String[] args) throws Exception {
// 第二种方式:创建文档并设置文档的根元素节点
Element root2 = DocumentHelper.createElement("bookstore");
Document document2 = DocumentHelper.createDocument(root2);
// 添加一级子节点:add之后就返回这个元素
Element book1 = root2.addElement("book");
book1.addAttribute("id", "1");
book1.addAttribute("name", "第一本书");
// 添加二级子节点
book1.addElement("name").setText("遇见未知的自己");
book1.addElement("author").setText("张德芬");
book1.addElement("year").setText("2014");
book1.addElement("price").setText("109");
// 添加一级子节点
Element book2 = root2.addElement("book");
book2.addAttribute("id", "2");
book2.addAttribute("name", "第二本书");
// 添加二级子节点
book2.addElement("name").setText("双城记");
book2.addElement("author").setText("狄更斯");
book2.addElement("year").setText("2007");
book2.addElement("price").setText("29");
// 设置缩进为4个空格,并且另起一行为true
OutputFormat format = new OutputFormat(" ", true);
// 另一种输出方式,记得要调用flush()方法,否则输出的文件中显示空白
XMLWriter xmlWriter3 = new XMLWriter(new FileWriter("book.xml"),format);
xmlWriter3.write(document2);
xmlWriter3.flush();
// close()方法也可以
}
}
运行结果:
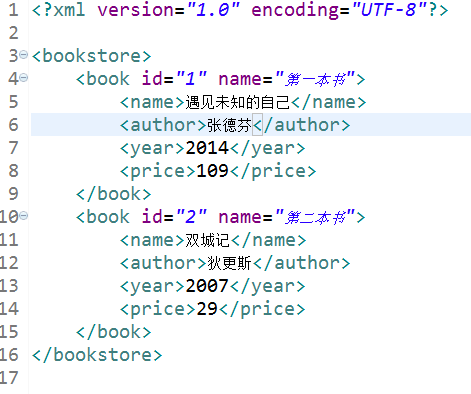
解析 book.xml:
package com.example.xml.dom4j;
import java.io.File;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/**
* dom4j解析xml文档示例
*
*/
public class Dom4JTest3 {
public static void main(String[] args) {
// 解析books.xml文件
// 创建SAXReader的对象reader
SAXReader reader = new SAXReader();
try {
// 通过reader对象的read方法加载books.xml文件,获取docuemnt对象。
Document document = reader.read(new File("book.xml"));
// 通过document对象获取根节点bookstore
Element bookStore = document.getRootElement();
System.out.println("根节点名:"+bookStore.getName());
// 通过element对象的elementIterator方法获取迭代器
Iterator it = bookStore.elementIterator();
// 遍历迭代器,获取根节点中的信息(书籍)
while (it.hasNext()) {
System.out.println("=====开始遍历子节点=====");
Element book = (Element) it.next();
System.out.println("子节点名:"+book.getName());
// 获取book的属性名以及 属性值
List<Attribute> bookAttrs = book.attributes();
for (Attribute attr : bookAttrs) {
System.out.println("属性名:" + attr.getName() + "--属性值:"
+ attr.getValue());
}
Iterator itt = book.elementIterator();
while (itt.hasNext()) {
Element bookChild = (Element) itt.next();
System.out.println("节点名:" + bookChild.getName() + "--节点值:" + bookChild.getStringValue());
}
System.out.println("=====结束遍历该节点=====");
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
运行结果:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
java dom4j解析xml文件代码实例分享
解析xml文件有两种方式,一种是利用Dom去解析,这种方式写起代码比较麻烦,对于刚入手的程序员来说比较容易出问题:第二种就是使用Dom4j包去解析在要使用Dom4j包的时候,肯定要先引入包 复制代码 代码如下: import java.io.File;import java.io.FileWriter;import java.io.IOException;import java.io.Writer;import java.util.Iterator; import org.dom4j.Docum
-
java dom4j解析xml用到的几个方法
1. 读取并解析XML文档: 复制代码 代码如下: SAXReader reader = new SAXReader(); Document document = reader.read(new File(fileName)); reader的read方法是重载的,可以从InputStream, File, Url等多种不同的源来读取.得到的Document对象就带表了整个XML. 读取的字符编码是按照XML文件头定义的编码来转换.如果遇到乱码问题,注意要把各处的编码名称保持一致即可. 2. 取
-

在java中使用dom4j解析xml(示例代码)
虽然Java中已经有了Dom和Sax这两种标准解析方式 但其操作起来并不轻松,对于我这么一个初学者来说,其中部分代码是活生生的恶心 为此,伟大的第三方开发组开发出了Jdom和Dom4j等工具 鉴于目前的趋势,我们这里来讲讲Dom4j的基本用法,不涉及递归等复杂操作 Dom4j的用法很多,官网上的示例有那么点儿晦涩,这里就不写了 首先我们需要出创建一个xml文档,然后才能对其解析 xml文档: 复制代码 代码如下: <?xml version="1.0" encoding=&quo
-
java中利用Dom4j解析和生成XML文档
一.前言 dom4j是一套非常优秀的Java开源api,主要用于读写xml文档,具有性能优异.功能强大.和非常方便使用的特点. 另外xml经常用于数据交换的载体,像调用webservice传递的参数,以及数据做同步操作等等, 所以使用dom4j解析xml是非常有必要的. 二.准备条件 dom4j.jar 下载地址:http://sourceforge.net/projects/dom4j/ 三.使用Dom4j实战 1.解析xml文档 实现思路: <1>根据读取的xml路径,传递给SAX
-
java使用xpath和dom4j解析xml
1 XML文件解析的4种方法 通常解析XML文件有四种经典的方法.基本的解析方式有两种,一种叫SAX,另一种叫DOM.SAX是基于事件流的解析,DOM是基于XML文档树结构的解析.在此基础上,为了减少DOM.SAX的编码量,出现了JDOM,其优点是,20-80原则(帕累托法则),极大减少了代码量.通常情况下JDOM使用时满足要实现的功能简单,如解析.创建等要求.但在底层,JDOM还是使用SAX(最常用).DOM.Xanan文档.另外一种是DOM4J,是一个非常非常优秀的Java XML API,
-
java使用dom4j操作xml示例代码
dom4j是一个非常优秀的Java XML API,具有性能优异.功能强大和极端易用使用的特点,同时它也是一个开放源工具.可以在这个地址http://dom4j.sourceforge.net进行下载.这里我们使用到的dom4j是dom4j-1.6.1这个版本,我们只需要使用到如下两个jar包: 复制代码 代码如下: dom4j-1.6.1.jarcommons-io-2.4.jar 1.dom4j读取xml字符串 复制代码 代码如下: import org.dom4j.Document;imp
-
java使用dom4j解析xml配置文件实现抽象工厂反射示例
逻辑描述: 现在我们想在B层和D层加上接口层,并使用工厂.而我们可以将创建B和创建D看作是两个系列,然后就可以使用抽象工厂进行创建了. 配置文件:beans-config.xml.service-class与dao-class分别对应两个系列的产品.子菜单中id对应接口的命名空间,class对应实现类的命名空间. 复制代码 代码如下: [html] view plaincopyprint? <?xml version="1.0" encoding="UTF-8"
-
java操作(DOM、SAX、JDOM、DOM4J)xml方式的四种比较与详解
1)DOM(JAXP Crimson解析器) DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准.DOM是以层次结构组织的节点或信息片断的集合.这个层次结构允许开发人员在树中寻找特定信息.分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作.由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的.DOM以及广义的基于树的处理具有几个优点.首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改.它还可以在任何时候在树中上下导航,而不是像SAX那
-
java中使用dom4j解析XML文件的方法教程
前言 dom4j是一个java的XML api,性能优异.功能强大.易于使用.以前听说过来解析xml文件的几种标准方式:但是从来的没有应用过来,所以可以在google中搜索dmo4j解析xml文件的方式,学习一下dom4j解析xml的具体操作.下面话不多说了,来一起看看详细的介绍吧 官网下载Dom4j地址:https://dom4j.github.io/ 注意:使用Dom4j开发,需下载dom4j相应的jar文件 题目:后台利用dom4j解析student.xml文件,并返回List<Stude
-
Java dom4j创建解析xml文档过程解析
DOM4J解析 特征: 1.JDOM的一种智能分支,它合并了许多超出基本XML文档表示的功能. 2.它使用接口和抽象基本类方法. 3.具有性能优异.灵活性好.功能强大和极端易用的特点. 4.是一个开放源码的文件 jar包:dom4j-1.6.1.jar 创建 book.xml: package com.example.xml.dom4j; import java.io.FileWriter; import org.dom4j.Document; import org.dom4j.Document
-
java + dom4j.jar提取xml文档内容
本文实例为大家分享了java + dom4j.jar提取xml文档内容的具体代码,供大家参考,具体内容如下 资源下载页:点击下载 本例程主要借助几个遍历的操作对xml格式下的内容进行提取,操作不是最优的方法,主要是练习使用几个遍历操作. xml格式文档内容: <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE nitf SYSTEM "http://www.nitf.org/IPTC/NITF
-
dom4j创建和解析xml文档的实现方法
DOM4J解析 特征: 1.JDOM的一种智能分支,它合并了许多超出基本XML文档表示的功能. 2.它使用接口和抽象基本类方法. 3.具有性能优异.灵活性好.功能强大和极端易用的特点. 4.是一个开放源码的文件 jar包:dom4j-1.6.1.jar 创建 book.xml: package com.example.xml.dom4j; import java.io.FileWriter; import org.dom4j.Document; import org.dom4j.Document
-
java使用dom4j生成与解析xml文档的方法示例
本文实例讲述了java使用dom4j生成与解析xml文档的方法.分享给大家供大家参考,具体如下: xml是一种新的数据格式,主要用于数据交换.我们所用的框架都有涉及到xml.因此解析或生成xml对程序员也是一个技术难点.这里就用dom4j来生成一个文档,需要注意的是每个xml文档只有一个根节点. package org.lxh; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutput
-
java中四种生成和解析XML文档的方法详解(介绍+优缺点比较+示例)
众所周知,现在解析XML的方法越来越多,但主流的方法也就四种,即:DOM.SAX.JDOM和DOM4J 下面首先给出这四种方法的jar包下载地址 DOM:在现在的Java JDK里都自带了,在xml-apis.jar包里 SAX:http://sourceforge.net/projects/sax/ JDOM:http://jdom.org/downloads/index.html DOM4J:http://sourceforge.net/projects/dom4j/ 一.介绍及优缺点分析
-
Java编程中更新XML文档的常用方法
本文简要的讨论了Java语言编程中更新XML文档的四种常用方法,并且分析这四种方法的优劣.其次,本文还对如何控制Java程序输出的XML文档的格式做了展开论述. JAXP是Java API for XML Processing的英文字头缩写,中文含义是:用于XML文档处理的使用Java语言编写的编程接口.JAXP支持DOM.SAX.XSLT等标准.为了增强JAXP使用上的灵活性,开发者特别为JAXP设计了一个Pluggability Layer,在Pluggability Layer的支持之下,
-
java使用DOM对XML文档进行增删改查操作实例代码
本文研究的主要是java使用DOM对XML文档进行增删改查操作的相关代码,具体实例如下所示. 源代码: package com.zc.homeWork18; import java.io.File; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.transform.Transformer; import javax.xml.tr
-
PHP4和PHP5版本下解析XML文档的操作方法实例分析
本文实例讲述了PHP4和PHP5版本下解析XML文档的操作方法.分享给大家供大家参考,具体如下: 在PHP网站开发与建设过程中,时常会碰到需要对XML文档进行解析,PHP4版本自带了XML解析器(sax),PHP5版本增加了SimpleXML(基于dom)的XML扩展,对XML的解析更是非常方便,今天和大家分享下在不同环境下对XML文档进行解析的方法. XML文档 <?xml version="1.0" encoding="gbk"?> <Leap
-
Android XmlPullParser 方式解析 Xml 文档
Android XmlPullParser 方式解析 Xml 文档 xml 文件格式 <?xml version="1.0" encoding="UTF-8"?> <persons> <person id="1"> <name>张三</name> <age>22</age> </person> <person id="2"&g
-
JS实现兼容各浏览器解析XML文档数据的方法
本文实例讲述了JS实现兼容各浏览器解析XML文档数据的方法.分享给大家供大家参考.具体分析如下: 网站上很多用JS解析XML文档的资料或多或少都有点问题, 以下是自己总结的代码,用来解析XML文档,兼容各个浏览器. parseXMLDOM.js代码: /* * 纯JS解析XML文档(兼容各个浏览器) */ function parseXMLDOM(){ var _browserType = ""; var _xmlFile = ""; var _XmlDom = n