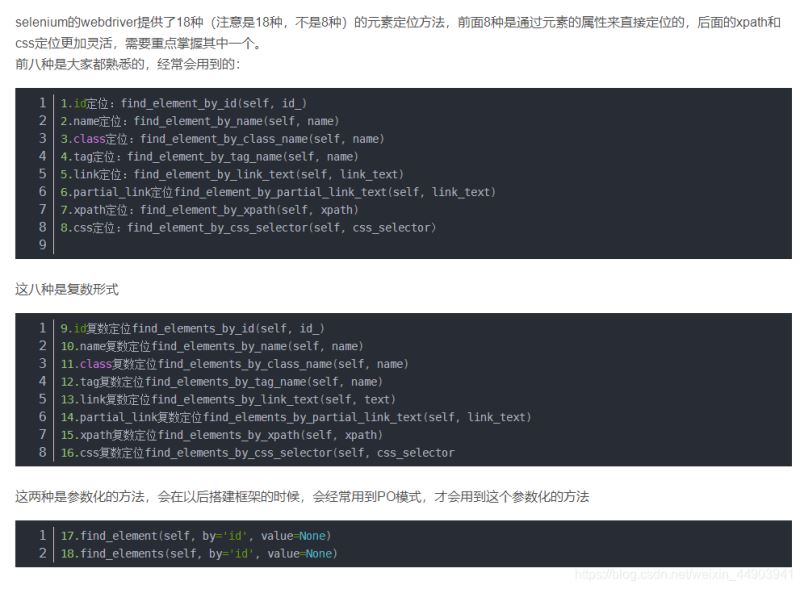
python自动化八大定位元素讲解
一、find_element_by_id()
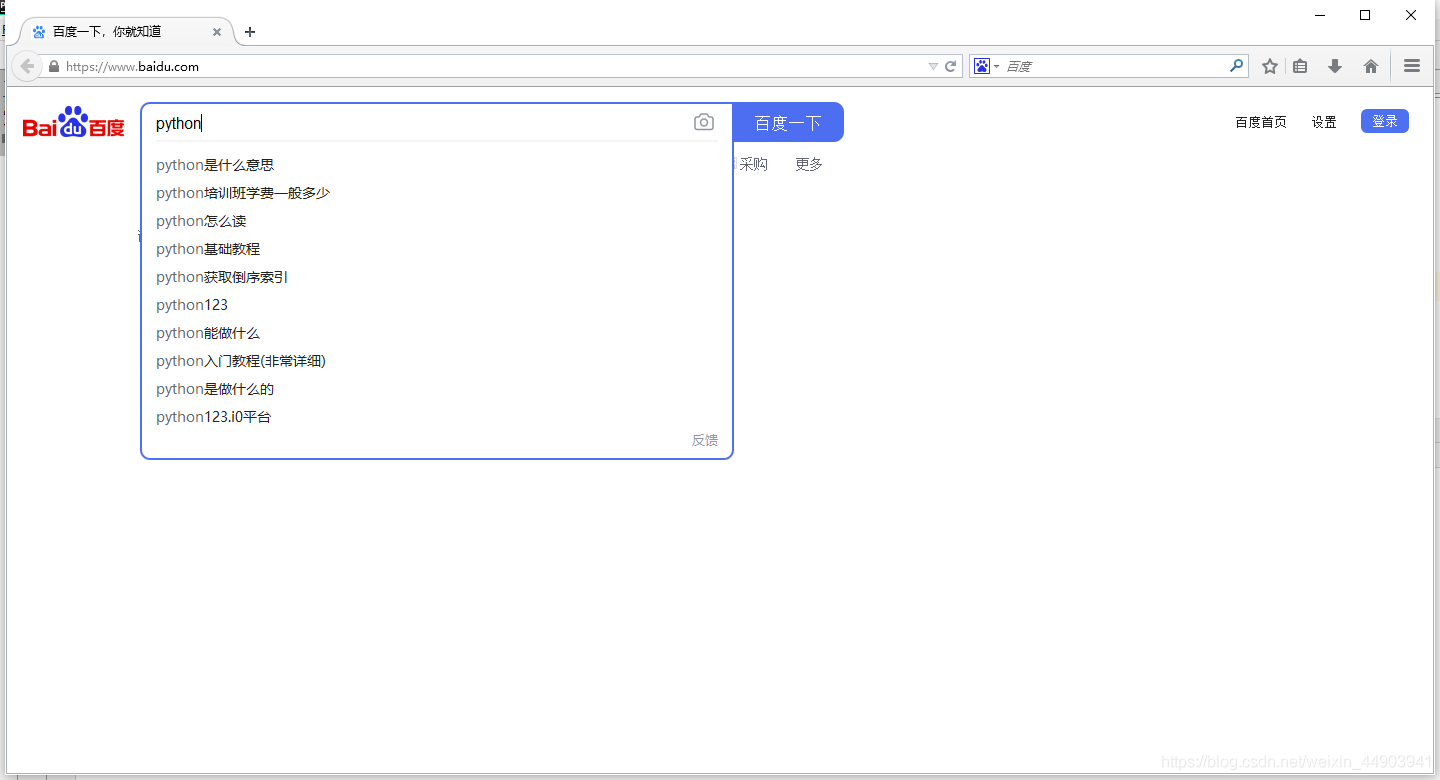
find_element_by_id()
1.从上面定位到的元素属性中,可以看到有个id属性:id=“kw”,这里可以通过它的id属性定位到这个元素。
2.定位到搜索框后,用send_keys()方法,就可以输入文本。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# 通过id定位百度输入框,并输入'python'
ss = driver.find_element_by_id('kw')
ss.send_keys('python')
二、find_element_by_name()
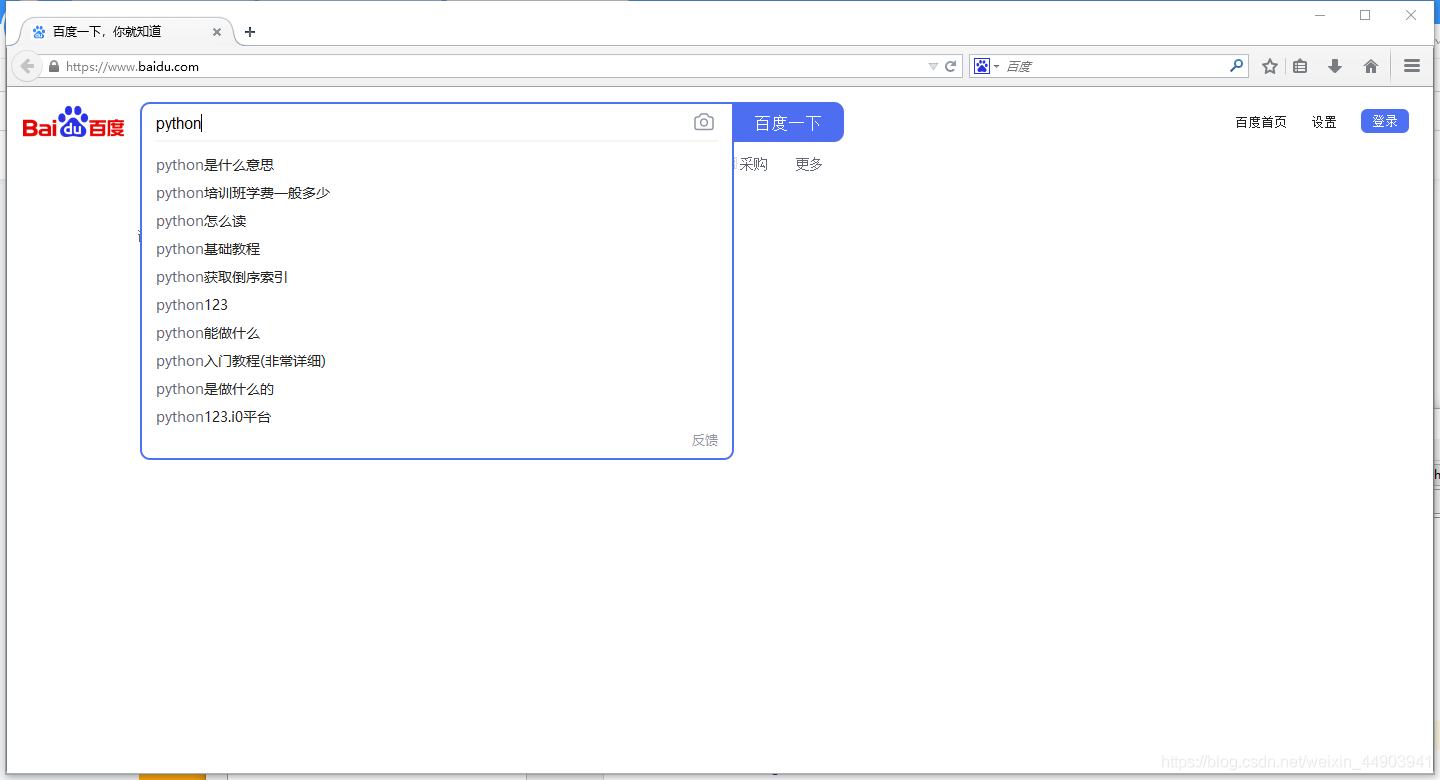
find_element_by_name()
1.从上面定位到的元素属性中,可以看到有个name属性:name=“wd”,这里可以通过它的name属性单位到这个元素。
说明:这里运行后会报错,说明这个搜索框的name属性不是唯一的,无法通过name属性直接定位到输入框
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# 通过name定位百度输入框,并输入'python'
ss = driver.find_element_by_name('wd')
ss.send_keys('python')
三、find_element_by_class_name()
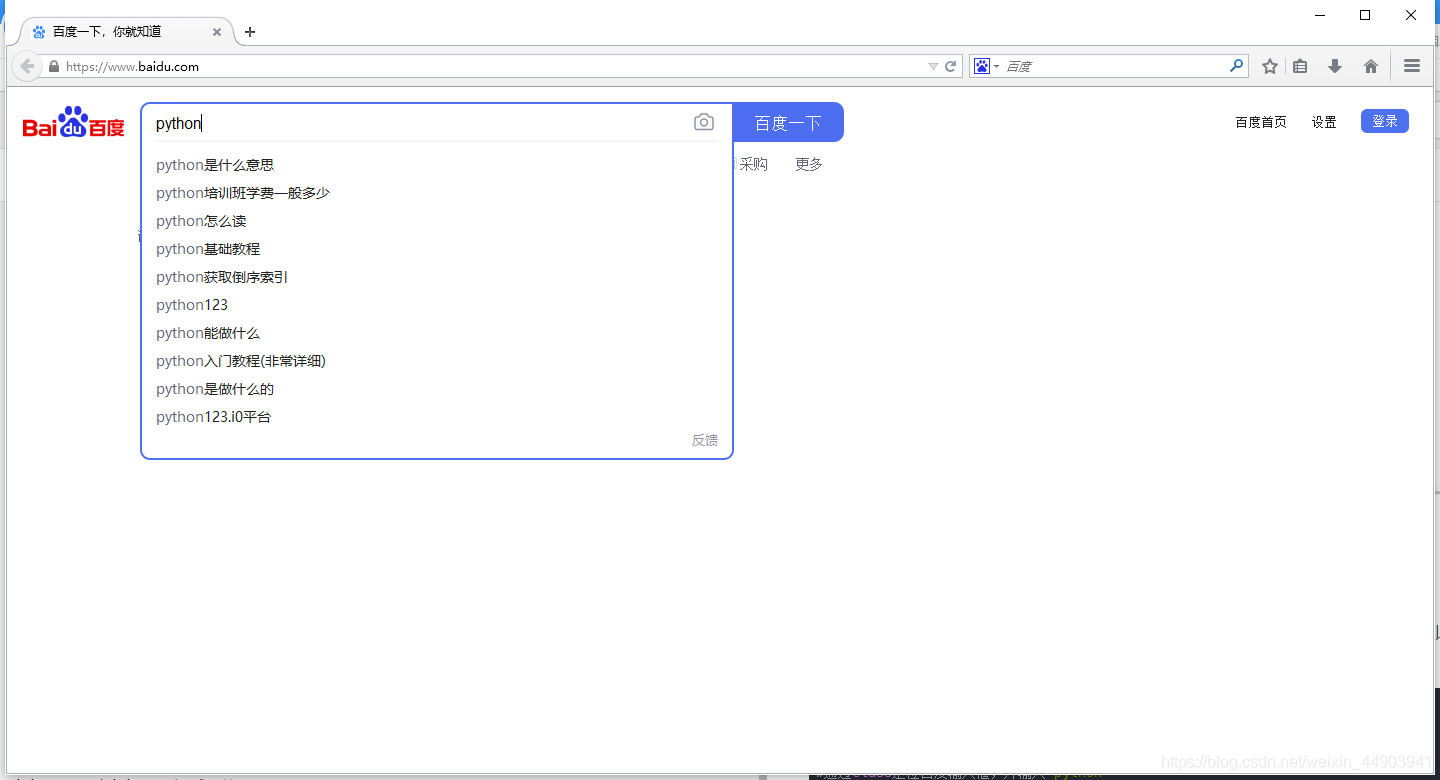
find_element_by_class_name()
1.从上面定位到的元素属性中,可以看到有个class属性:class=“s_ipt”,这里可以通过它的class属性定位到这个元素。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://www.baidu.com')
#通过class定位百度输入框,并输入'python'
driver.find_element_by_class_name('s_ipt').send_keys('python')
四、find_element_by_tag_name()
find_element_by_tag_name()
1.从上面定位到的元素属性中,可以看到每个元素都有tag(标签)属性,如搜索框的标签属性,就是最前面的input。
2.很明显,在一个页面中,相同的标签有很多,所以一般不用标签来定位。以下例子,仅供参考和理解,运行肯定报错。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://www.baidu.com')
#通过tag(标签)定位百度输入框,并输入'python'
ss = driver.find_element_by_tag_name('input')
ss.send_keys('python')
五、find_element_by_link_text()
1.定位百度页面上"hao123"这个按钮
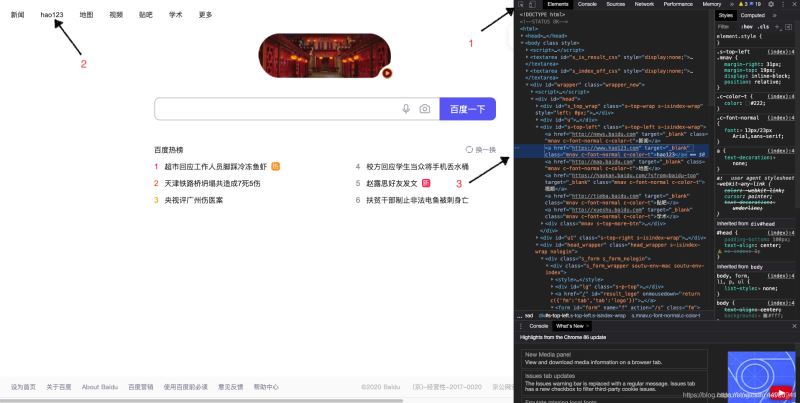
查看页面元素:
<a class="mnav" target="_blank" href="http://www.hao123.com" rel="external nofollow" >hao123</a>
2.从元素属性可以分析出,有个href = "http://www.hao123.com
说明它是个超链接,对于这种元素,可以用以下方法:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过tlink(超链接)定位百度输入框,并点击
driver.find_element_by_link_name('hao123').click()
六、find_element_by_partial_link_text()
1.有时候一个超链接它的字符串可能比较长,如果输入全称的话,会显示很长,这时候可以用一模糊匹配方式,截取其中一部分字符串就可以了
2.如“hao123”,只需输入“ao123”也可以定位到
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过partial_link定位百度输入框,并点击(partial_link是一种模糊匹配的方式)
driver.find_element_by_partial_link_name('hao123').click()
七、find_element_by_xpath()
1.以上定位方式都是通过元素的某个属性来定位的,如果一个元素它既没有id、name、class属性也不是超链接,这么办呢?或者说它的属性很多重复的。这个时候就可以用xpath解决。
2.xpath是一种路径语言,跟上面的定位原理不太一样,首先第一步要先学会查看一个元素的xpath。
- 对于谷歌浏览器来说,有自己 的xpath解析工具:鼠标移到需要查看的html源码上,右击
- 选择copycopy
- xpath,就是源码的xpath路径

from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过xpath地址定位百度输入框,并点击(xpath地址即为赋值过来的地址)
driver.find_element_by_xpath('//*[@id="s-top-left"]/a[2]').click()
八、find_element_by_css_selector()
1.css是另外一种语法,比xpath更为简洁,但是不太好理解。这里先学会如何用工具查看,后续的教程再深入讲解
对于谷歌浏览器来说,同样有自己 的css解析工具:鼠标移到需要查看的html源码上,右击
选择copy
copy selector,就是源码的css路径
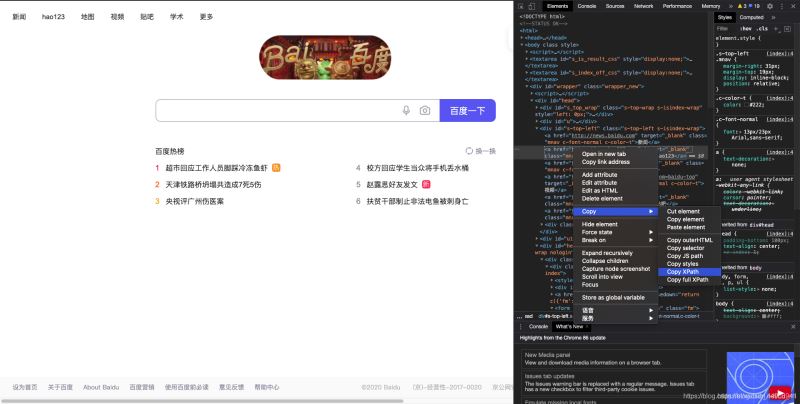
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过css地址定位百度输入框,并点击
driver.find_element_by_xpath('#s-top-left > a:nth-child(2)').click()
总结:
到此这篇关于python自动化八大定位元素讲解的文章就介绍到这了,更多相关python自动化八大定位元素内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python办公自动化之教你用Python批量识别发票并录入到Excel表格中
一.场景描述 这里有以四张发票为例(辰哥网上搜的),将发票图片放到pic文件夹下. 随便打开一张发票 提取目标:金额.名称.纳税人识别号.开票人. 最后将每一张发票的这四个内容保存到excel中: 二.准备环境 需要用到的库如下: from PIL import Image as PI import pyocr import pyocr.builders from cnocr import CnOcr 安装的命令如下: pip install pyocr pip install cnocr 发票
-
python ansible自动化运维工具执行流程
ansible 简介 ansible 是什么? ansible是新出现的自动化运维工具,基于Python开发,集合了众多运维工具(puppet.chef.func.fabric)的优点,实现了批量系统配置.批量程序部署.批量运行命令等功能. ansible是基于 paramiko 开发的,并且基于模块化工作,本身没有批量部署的能力.真正具有批量部署的是ansible所运行的模块,ansible只是提供一种框架.ansible不需要在远程主机上安装client/agents,因为它们是基于ssh来
-
python+opencv+selenium自动化登录邮箱并解决滑动验证的问题
前言 大家做自动化登录时可能都遇到过滑块验证码需要手动验证的问题,这次我们就来解决他 如下: 在我们做自动化登录时,总会遇到各种奇奇怪怪的验证码,滑块验证码就是其中最常见的一种.若我们的程序自动输入账号密码之后,还需要我们人工去滑动验证码那还能称得上是自动化吗? 那么先给大家说一下我的'解题步骤'. 1.使用selenium打开邮箱首页. 2.定位到账号密码框,键入账号密码. 3.获取验证图片,使用opencv处理返回滑块应拖动的距离. 4.创建鼠标事件,模拟拖动滑块完成验证. 需要解
-
Python办公自动化之教你如何用Python将任意文件转为PDF格式
一.word转PDF 这里借助Python的docx2pdf去完成转换操作,该库的安装命令如下: pip install docx2pdf 目标:读取文件夹下的全部word文件,然后进行转换,最后保存到对应的文件夹中. 这里辰哥新建两个word文件作为演示,打开其中一个word看看 里面不仅有文字,同时包含有图片 import os from docx2pdf import convert word_path = 'word_path' word_to_pdf = 'word_to_pdf' f
-
Python+Appium自动化测试的实战
目录 一.环境准备 二.真机测试 一.环境准备 1.脚本语言:Python3.x IDE:安装Pycharm 2.安装Java JDK .Android SDK 3.adb环境,path添加E:\Software\Android_SDK\platform-tools 4.安装Appium for windows,官网地址http://appium.io/ 点击下载按钮会到GitHub的下载页面,选择对应平台下载 安装完成后,启动Appium,host和port默认的即可,然后设置Android
-
python实现自动化办公邮件合并功能
经常使用word办公的小伙伴们经常会遇到邮件合并的任务,通常会将数量有限的表格中的信息通过word的邮件合并功能,自动生成word文档,操作熟练的技术员通常不到十分钟就可以合并几十份邮件.那么如果遇到成千上万份的邮件需要合并并且需要各自生成文件呢?一个excel大佬也需要很长时间吧!既然我们很难在excel上追上大佬的脚步,何不另辟蹊径,找一条更适合自己的方法呢? 我是一年多前接触到python自动化办公的,通过进一步的学习,发现平时我们的办公效率可以通过使用python的自动化办公方法从而进一
-
python自动化八大定位元素讲解
一.find_element_by_id() find_element_by_id() 1.从上面定位到的元素属性中,可以看到有个id属性:id="kw",这里可以通过它的id属性定位到这个元素. 2.定位到搜索框后,用send_keys()方法,就可以输入文本. from selenium import webdriver driver = webdriver.Firefox() driver.get("http://www.baidu.com") # 通过id定
-
Python自动化之定位方法大杀器xpath
一.xpath:基本属性定位 上一篇文章讲了通过元素的id.name.class这些属性定位的用户,使用xpath方法结合元素属性也可以很准确的定位元素,如下图 于是可以用以下xpath方法定位 二.xpath:其他属性定位 在实际工作过程中,往往会遇到一个元素id.name.class属性都没有,这时候也可以通过其它属性定位到 三.xpath:标签定位 在实际工作中,还会遇到一种情况就是相同属性具有同一个名字,这时就需要通过标签筛选,定位更准一点 如果不想制定标签名称,可以用*号表示任意标签
-
selenium+python自动化测试之页面元素定位
上一篇博客selenium+python自动化测试(二)–使用webdriver操作浏览器讲解了使用webdriver操作浏览器的各种方法,可以实现对浏览器进行操作了,接下来就是对浏览器页面中的元素进行操作,操作页面元素,首先要找到操作的元素,对元素进行定位 查看页面源码 要定位页面元素,需要找到页面的源码,IE浏览器中,打开页面后,在页面上点击鼠标右键,会有"查看源代码"的选项,点击后就会进入页面源码页面,在这里就可以找到页面的所有元素 使用Chrome浏览器打开页面后,在浏览器的地
-
详解Python自动化中这八大元素定位
一.find_element_by_id() find_element_by_id() 1.从上面定位到的元素属性中,可以看到有个id属性:id="kw",这里可以通过它的id属性定位到这个元素. 2.定位到搜索框后,用send_keys()方法,就可以输入文本. from selenium import webdriver driver = webdriver.Firefox() driver.get("http://www.baidu.com") # 通过id定
-
python 获取list特定元素下标的实例讲解
在平时开发过程中,经常遇到需要在数据中获取特定的元素的信息,如到达目的地最近的车站,橱窗里面最贵的物品等等.怎么办?看下面 方法一: 利用数组自身的特性 a.index(target), 其中a是你的目标list,target是你需要的下标对应的值 a=[72, 56, 76, 84, 80, 88] print(a.index(76)) output: 2 但是,如果a中有多个76呢? 我们发现,这种方法仅仅能获取都第一个匹配的value的下标(可以试试o_o) 所以,我们看看我们的第二种方案
-
python自动化发送邮件实例讲解
在python中,通过如下两个模块可以实现邮件的自动化操作 smtplib email smtplib模块是对SMTP协议的封装,用于发送邮件:email模块用于构建邮件内容,支持以下3种形式的邮件 纯文本 html 带附件 首先来看下邮件的构建,对于一封邮件,需要指定发件人,收件人,主题,正文等内容,以最简单的纯文本邮件为例,构建方式如下 >>> from email.mime.text import MIMEText >>> from email.header im
-
Python BeautifulSoup基本用法详解(通过标签及class定位元素)
如下: 将html文件下载后,使用BeauifulSoup读取文件,并且使用html.parser tmp_soup.select里面的参数为: div标签中class中带有listbg 下面 span标签中带有title,这种意思: 并且他们的类型如下: 都是ResultSet类型. 可以通过下面这种方式获取, find('某个标签')['中包含的域'] 当为li标签的时候,可以通过这样的方式获取: 到此这篇关于Python BeautifulSoup基本用法(通过标签及class定位元素)的
-
Python selenium 八种定位元素的方式
目录 前言 1:id定位 2:name定位 3:class_name定位 4:tag_name定位 5:link_text定位 6:partial_link_text定位 7:xpath定位 8:css定位 前言 八种定位方式: id,name,class name,tag name,link text,partial link text,xpath,css selector.其中id,name,class name,tag name是根据元素的标签或元素的属性来进行定位:link text,p
-
Python实现八大排序算法
如何用Python实现八大排序算法 1.插入排序 描述 插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的.个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为 O(n^2).是稳定的排序方法.插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插 入的位置),而第二部分就只包含这一个元素(即待插入元素).在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中. 代码实现 def insert_
-
Selenium+Python 自动化操控登录界面实例(有简单验证码图片校验)
从最简单的Web浏览器的登录界面开始,登录界面如下: 进行Web页面自动化测试,对页面上的元素进行定位和操作是核心.而操作又是以定位为前提的,因此,对页面元素的定位是进行自动化测试的基础. 页面上的元素就像人一样,有各种属性,比如元素名字,元素id,元素属性(class属性,name属性)等等.webdriver就是利用元素的这些属性来进行定位的. 可以用于定位的常用的元素属性: id name class name tag name link text partial link text xp