Spark SQL的整体实现逻辑解析
1、sql语句的模块解析
当我们写一个查询语句时,一般包含三个部分,select部分,from数据源部分,where限制条件部分,这三部分的内容在sql中有专门的名称:

当我们写sql时,如上图所示,在进行逻辑解析时会把sql分成三个部分,project,DataSource,Filter模块,当生成执行部分时又把他们称为:Result模块、
DataSource模块和Opertion模块。
那么在关系数据库中,当我们写完一个查询语句进行执行时,发生的过程如下图所示:

整个执行流程是:query -> Parse -> Bind -> Optimize -> Execute
1、写完sql查询语句,sql的查询引擎首先把我们的查询语句进行解析,也就是Parse过程,解析的过程是把我们写的查询语句进行分割,把project,DataSource和Filter三个部分解析出来从而形成一个逻辑解析tree,在解析的过程中还会检查我们的sql语法是否有错误,比如缺少指标字段、数据库中不包含这张数据表等。当发现有错误时立即停止解析,并报错。当顺利完成解析时,会进入到Bind过程。
2、Bind过程,通过单词我们可看出,这个过程是一个绑定的过程。为什么需要绑定过程?这个问题需要我们从软件实现的角度去思考,如果让我们来实现这个sql查询引擎,我们应该怎么做?他们采用的策略是首先把sql查询语句分割,分割不同的部分,再进行解析从而形成逻辑解析tree,然后需要知道我们需要取数据的数据表在哪里,需要哪些字段,执行什么逻辑,这些都保存在数据库的数据字典中,因此bind过程,其实就是把Parse过程后形成的逻辑解析tree,与数据库的数据字典绑定的过程。绑定后会形成一个执行tree,从而让程序知道表在哪里,需要什么字段等等
3、完成了Bind过程后,数据库查询引擎会提供几个查询执行计划,并且给出了查询执行计划的一些统计信息,既然提供了几个执行计划,那么有比较就有优劣,数据库会根据这些执行计划的统计信息选择一个最优的执行计划,因此这个过程是Optimize(优化)过程。
4、选择了一个最优的执行计划,那么就剩下最后一步执行Execute,最后执行的过程和我们解析的过程是不一样的,当我们知道执行的顺序,对我们以后写sql以及优化都是有很大的帮助的.执行查询后,他是先执行where部分,然后找到数据源之数据表,最后生成select的部分,我们的最终结果。执行的顺序是:operation->DataSource->Result
虽然以上部分对SparkSQL没有什么联系,但是知道这些,对我们理解SparkSQL还是很有帮助的。
2、SparkSQL框架的架构
要想对这个框架有一个清晰的认识,首先我们要弄清楚,我们为什么需要sparkSQL呢?个人建议一般情况下在写sql能够直接解决的问题就不要使用sparkSQL,如果想刻意使用sparkSQL,也不一定能够加快开发的进程。使用sparkSQL是为了解决一般用sql不能解决的复杂逻辑,使用编程语言的优势来解决问题。我们使用sparkSQL一般的流程如下图:
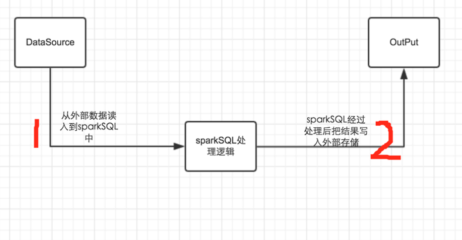
如上图所示,一般情况下分为两个部分:a、把数据读入到sparkSQL中,sparkSQL进行数据处理或者算法实现,然后再把处理后的数据输出到相应的输出源中。
1、同样我们也是从如果让我们开发,我们应该怎么做,需要考虑什么问题来思考这个问题。
a、第一个问题是,数据源有几个,我们可能从哪些数据源读取数据?现在sparkSQL支持很多的数据源,比如:hive数据仓库、json文件,.txt,以及orc文件,同时现在还支持jdbc从关系数据库中取数据。功能很强大。
b、还一个需要思考的问题是数据类型怎么映射啊?我们知道当我们从一个数据库表中读入数据时,我们定义的表结构的字段的类型和编程语言比如scala中的数据类型映射关系是怎样的一种映射关系?在sparkSQL中有一种来解决这个问题的方法,来实现数据表中的字段类型到编程语言数据类型的映射关系。这个以后详细介绍,先了解有这个问题就行。
c、数据有了,那么在sparkSQL中我们应该怎么组织这些数据,需要什么样的数据结构呢,同时我们对这些数据都可以进行什么样的操作?sparkSQL采用的是DataFrame数据结构来组织读入到sparkSQL中的数据,DataFrame数据结构其实和数据库的表结构差不多,数据是按照行来进行存储,同是还有一个schema,就相当于数据库的表结构,记录着每一行数据属于哪个字段。
d、当数据处理完以后,我们需要把数据放入到什么地方,并切以什么样的格式进行对应,这个a和b要解决的问题是相同的。
2、sparkSQL对于以上问题的实现逻辑也很明确,从上图已经很清楚,主要分为两个阶段,每个阶段都对应一个具体的类来实现。
a、 对于第一个阶段,sparkSQL中存在两个类来解决这些问题:HiveContext,SQLContext,同时hiveContext继承了SQLContext的所有方法,同时又对其进行了扩展。因为我们知道, hive和mysql的查询还是有一定的差别的。HiveContext只是用来处理从hive数据仓库中读入数据的操作,SQLContext可以处理sparkSQL能够支持的剩下的所有的数据源。这两个类处理的粒度是限制在对数据的读写上,同时对表级别的操作上,比如,读入数据、缓存表、释放缓存表表、注册表、删除注册的表、返回表的结构等的操作。
b、sparkSQL处理读入的数据,采用的是DataFrame中提供的方法。因为当我们把数据读入到sparkSQL中,这个数据就是DataFrame类型的。同时数据都是按照Row进行存储的。其中 DataFrame中提供了很多有用的方法。以后会细说。
c、在spark1.6版本以后,又增加了一个类似于DataFrame的数据结构Dataset,增加此数据结构的目的是DataFrame有软肋,他只能处理按照Row进行存储的数据,并且只能使用DataFrame中提供的方法,我们只能使用一部分RDD提供的操作。实现Dataset的目的就是让我们能够像操作RDD一样来操作sparkSQL中的数据。
d、其中还有一些其他的类,但是现在在sparkSQL中最主要的就是上面的三个类,其他类以后碰到了会慢慢想清楚。
3、sparkSQL的hiveContext和SQLContext的运行原理
hiveContext和SQLContext与我第一部分讲到的sql语句的模块解析实现的原理其实是一样的,采用了同样的逻辑过程,并且网上有好多讲这一块的,就直接粘贴复制啦!!
sqlContext总的一个过程如下图所示:
1.SQL语句经过SqlParse解析成UnresolvedLogicalPlan;
2.使用analyzer结合数据数据字典(catalog)进行绑定,生成resolvedLogicalPlan;
3.使用optimizer对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan;
4.使用SparkPlan将LogicalPlan转换成PhysicalPlan;
5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
6.使用execute()执行可执行物理计划;
7.生成SchemaRDD。
在整个运行过程中涉及到多个SparkSQL的组件,如SqlParse、analyzer、optimizer、SparkPlan等等

hiveContext总的一个过程如下图所示:
1.SQL语句经过HiveQl.parseSql解析成Unresolved LogicalPlan,在这个解析过程中对hiveql语句使用getAst()获取AST树,然后再进行解析;
2.使用analyzer结合数据hive、源数据Metastore(新的catalog)进行绑定,生成resolved LogicalPlan;
3.使用optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan,优化前使用了ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))进行预处理;
4.使用hivePlanner将LogicalPlan转换成PhysicalPlan;
5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
6.使用execute()执行可执行物理计划;
7.执行后,使用map(_.copy)将结果导入SchemaRDD。

到此这篇关于Spark SQL的整体实现逻辑的文章就介绍到这了,更多相关Spark SQL实现逻辑内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
浅谈DataFrame和SparkSql取值误区
1.DataFrame返回的不是对象. 2.DataFrame查出来的数据返回的是一个dataframe数据集. 3.DataFrame只有遇见Action的算子才能执行 4.SparkSql查出来的数据返回的是一个dataframe数据集. 原始数据 scala> val parquetDF = sqlContext.read.parquet("hdfs://hadoop14:9000/yuhui/parquet/part-r-00004.gz.parquet") df: or
-

Spark SQL数据加载和保存实例讲解
一.前置知识详解 Spark SQL重要是操作DataFrame,DataFrame本身提供了save和load的操作, Load:可以创建DataFrame, Save:把DataFrame中的数据保存到文件或者说与具体的格式来指明我们要读取的文件的类型以及与具体的格式来指出我们要输出的文件是什么类型. 二.Spark SQL读写数据代码实战 import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD;
-
Spark学习笔记之Spark SQL的具体使用
1. Spark SQL是什么? 处理结构化数据的一个spark的模块 它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用 2. Spark SQL的特点 多语言的接口支持(java python scala) 统一的数据访问 完全兼容hive 支持标准的连接 3. 为什么学习SparkSQL? 我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执
-
Spark SQL操作JSON字段的小技巧
前言 介绍Spark SQL的JSON支持,这是我们在Databricks中开发的一个功能,可以在Spark中更容易查询和创建JSON数据.随着网络和移动应用程序的普及,JSON已经成为Web服务API以及长期存储的常用的交换格式.使用现有的工具,用户通常会使用复杂的管道来在分析系统中读取和写入JSON数据集.在Apache Spark 1.1中发布Spark SQL的JSON支持,在Apache Spark 1.2中增强,极大地简化了使用JSON数据的端到端体验. 很多时候,比如用struct
-
Spark SQL常见4种数据源详解
通用load/write方法 手动指定选项 Spark SQL的DataFrame接口支持多种数据源的操作.一个DataFrame可以进行RDDs方式的操作,也可以被注册为临时表.把DataFrame注册为临时表之后,就可以对该DataFrame执行SQL查询. Spark SQL的默认数据源为Parquet格式.数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作. 修改配置项spark.sql.sources.default,可修改默认数据源格式. scala> val
-
pyspark.sql.DataFrame与pandas.DataFrame之间的相互转换实例
代码如下,步骤流程在代码注释中可见: # -*- coding: utf-8 -*- import pandas as pd from pyspark.sql import SparkSession from pyspark.sql import SQLContext from pyspark import SparkContext #初始化数据 #初始化pandas DataFrame df = pd.DataFrame([[1, 2, 3], [4, 5, 6]], index=['row1
-
Spark SQL的整体实现逻辑解析
1.sql语句的模块解析 当我们写一个查询语句时,一般包含三个部分,select部分,from数据源部分,where限制条件部分,这三部分的内容在sql中有专门的名称: 当我们写sql时,如上图所示,在进行逻辑解析时会把sql分成三个部分,project,DataSource,Filter模块,当生成执行部分时又把他们称为:Result模块. DataSource模块和Opertion模块. 那么在关系数据库中,当我们写完一个查询语句进行执行时,发生的过程如下图所示: 整个执行流程是:query
-
教你如何让spark sql写mysql的时候支持update操作
目录 1.首先了解背景 2.如何让sparkSQL支持update 3.改造源码前,需要了解整体的代码设计和执行流程 4.改造源码 如何让sparkSQL在对接mysql的时候,除了支持:Append.Overwrite.ErrorIfExists.Ignore:还要在支持update操作 1.首先了解背景 spark提供了一个枚举类,用来支撑对接数据源的操作模式 通过源码查看,很明显,spark是不支持update操作的 2.如何让sparkSQL支持update 关键的知识点就是: 我们正常
-
SQL 联合查询与XML解析实例详解
SQL 联合查询与XML解析实例 这里举例说明如何实现该功能: (select a.EBILLNO, a.EMPNAME, a.APPLYDATE, b.HS_NAME, replace(replace(a.SUMMARY,char(10), ''),char(13),'') as SUMMARY, cast(c.XmlData as XML).value('(/List/item/No/text())[1]','NVARCHAR(300)') as No, cast(c.X
-
Spark SQL配置及使用教程
目录 SparkSQL版本: SparkSQL DSL语法 SparkSQL和Hive的集成 Spark应用依赖第三方jar包文件解决方案 SparkSQL的ThriftServer服务 SparkSQL的ThriftServer服务测试 Spark中beeline的使用 通过jdbc来访问spark的ThriftServer接口 SparkSQL案例 案例一:SparkSQL读取HDFS上Json格式的文件 案例二:DataFrame和Dataset和RDD之间的互相转换
-
Spark SQL配置及使用教程
目录 SparkSQL版本: SparkSQL DSL语法 SparkSQL和Hive的集成 Spark应用依赖第三方jar包文件解决方案 SparkSQL的ThriftServer服务 SparkSQL的ThriftServer服务测试 Spark中beeline的使用 通过jdbc来访问spark的ThriftServer接口 SparkSQL案例 案例一:SparkSQL读取HDFS上Json格式的文件 案例二:DataFrame和Dataset和RDD之间的互相转换
-
ORACLE SQL语句优化技术要点解析
操作符优化: IN 操作符 用IN写出来的SQL的优点是比较容易写及清晰易懂,这比较适合现代软件开发的风格. 但是用IN的SQL性能总是比较低的,从ORACLE执行的步骤来分析用IN的SQL与不用IN的SQL有以下区别: ORACLE试图将其转换成多个表的连接,如果转换不成功则先执行IN里面的子查询,再查询外层的表记录,如果转换成功则直接采用多个表的连接方式查询. 由此可见用IN的SQL至少多了一个转换的过程.一般的SQL都可以转换成功,但对于含有分组统计等方面的SQL就不能转换了. 推荐方案: