python爬虫实战项目之爬取pixiv图片
自从接触python以后就想着爬pixiv,之前因为梯子有点问题就一直搁置,最近换了个梯子就迫不及待试了下。
爬虫无非request获取html页面然后用正则表达式或者beautifulsoup之类现成工具截取我们想要的页面,pixiv也不例外。
首先我们来实现模拟登陆,虽然大多数情况不需要我们实现模拟登录,但如果你是会员之类的,登录和不登录网页就有区别。思路是登录时抓包抓到post请求,看pixiv构建的post的数据表格是什么格式,我们根据这个格式构建form,然后调用post方法去请求,再保存到session中,之后访问相关页面用session替代requests即可。
可以看到pixiv登录的网址如下,直接复制:

抓包找到提交数据的请求:


可以看到表单数据主要是这几个,经过几次尝试,我们在模拟的时候只需要构建password、pixiv_id、post_key再加上一个return_to(第二张)即可。pixiv_id就是我们的账号,password是密码,return_to照着填就行,但这个post_key却是随机的。
但我们也有办法,它是我们每次访问登录页面时动态生成的,这就好办了,再登录前先爬取一次登录前的页面,找到postkey。
看到下图红圈里面:
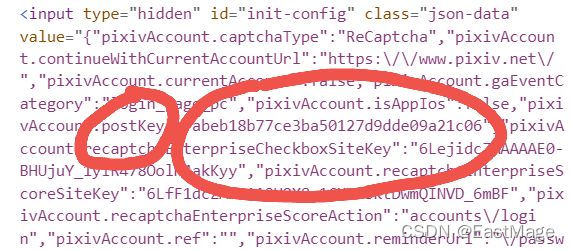
那就可以直接正则爬取:
def get_postkey():
login_url='https://accounts.pixiv.net/login?return_to=https%3A%2F%2Fwww.pixiv.net%2F&lang=zh&source=pc&view_type=page'
response=requests.get(url=login_url,headers=headers,verify=False)
html=response.text
# print(html)
postkey=re.findall('"pixivAccount.postKey":"(.*?)","pixivAccount.recaptchaEnterpriseCheckboxSiteKey"',html)
return postkey[0]
然后我们就可以构建数据包:
pixiv_id="账号" # 你的pixiv账号 password='xxxxx' # 你的pixiv密码 return_to='https://www.pixiv.net/' post_key=get_postkey()
实例化一个session对象,然后post提交就能完成模拟登陆:
session=requests.Session()
form_data={
'pixiv_id':pixiv_id,
'password':password,
'return_to':return_to,
'post_key':post_key
}
login_url1='https://accounts.pixiv.net/login?return_to=https%3A%2F%2Fwww.pixiv.net%2F&lang=zh&source=pc&view_type=page'
res=session.post(url=login_url1,headers=headers,data=form_data)
# 至此模拟登录成功
到此模拟登录就成功了,接下来就是爬我们想要的图片,以爬排行榜为例:
打开排行榜页面,鼠标悬停图片,右键检查,可以找到对应的代码位置:

找到每张图片的相似结构,我们可以用BeautifulSoup 找到节点,然后正则爬我们想要的网址:

先找到包含每张图片各种信息的节点,通过类名查找,然后对于每一个节点进行正则提取,提取出对应图片的下载链接,不过需要特别注意的是,pixiv直接显示的图片源是骗你的,真正的图片链接的形式应该是:
https://i.pximg.net/img-original/img/xxxx/xx/xx/xx/xx/xx/xxxxxxxx_p0.png
这样的,直接把这个网址复制网页栏访问会显示403,因为pixiv限制了必须从pixiv网页点进这个网址,所以我们首先必须headers构建refer-to,然后通过排行榜提取到信息后还需要自己手动构建正确的网址:
headers = {'Referer': 'https://www.pixiv.net/',
}
def get_accurate_url(url):
urll='https://i.pximg.net/img-original/img/' + str(url) + "_p0.jpg"
return urll
这里的代码偷了个懒,全部当作jpg来处理,下载的时候再处理png的情况
下载的具体函数,我们对每一个网址的后续部分提取出来作名字,随机睡眠1到4秒防止pixiv认出我们是爬虫把我们ip给封了,之后就是对网址进行访问下载,这里如果访问返回的状态码是404说明它其实是个png格式的图片,所以对png格式的文件重新构建正确的网址即可:
def download(list,filename):
i=1
for url in list:
pic_name=re.findall("https://i.pximg.net/img-original/img/(.*?)_p0.jpg",str(url))
pic_name1=str(pic_name[0]).replace("/",".")
r = random.randint(1, 4)
time.sleep(r)
response=requests.get(url=url,headers=headers,verify=False)
if(response.status_code==404):
the_url='https://i.pximg.net/img-original/img/' + str(pic_name[0]) + "_p0.png"
response = requests.get(url=the_url, headers=headers, verify=False)
with open(path + filename + '/' + str(pic_name1) + '.png', 'wb') as f:
f.write(response.content)
print("第" + str(i) + "张图片已下载成功!!")
else:
with open(path + filename + '/' + str(pic_name1) + '.jpg', 'wb') as f:
f.write(response.content)
print("第" + str(i) + "张图片已下载成功!!")
i+=1
最后就是成功下载排行榜的图片:

另外我在爬的时候发现pixiv很多网页获取时会隐藏body部分的内容,包括但不限于各个tag的网页和单个id图片的网页,一开始以为是没有登录的原因,但是实现登录后发现依然如此,推测可能是body部分内容是子网页或者javsscript生成之类的,反正前端有一万种方法达成这个目的,这个之后再研究怎么爬。
总结
到此这篇关于python爬虫实战项目之爬取pixiv图片的文章就介绍到这了,更多相关python爬取pixiv图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫爬取网站图片
此次python3主要用requests,解析图片网址主要用beautiful soup,可以基本完成爬取图片功能, 爬虫这个当然大多数人入门都是爬美女图片,我当然也不落俗套,首先也是随便找了个网址爬美女图片 from bs4 import BeautifulSoup import requests if __name__=='__main__': url='http://www.27270.com/tag/649.html' headers = { "U
-
Python爬取网页中的图片(搜狗图片)详解
前言 最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 本地下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片http://pic.sogou.com/,进入壁纸分类(当然只是个例子Q_Q),因为如果需要爬取某网站资料,那么就要初步的了解它- 进去后就是这个啦,然后F12进入开发人员选项,笔者用的是Chrome. 右键图片>>检查 发现我们需要的图片src是在img标签下的,于是先试着用
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
Python 爬虫批量爬取网页图片保存到本地的实现代码
其实和爬取普通数据本质一样,不过我们直接爬取数据会直接返回,爬取图片需要处理成二进制数据保存成图片格式(.jpg,.png等)的数据文本. 现在贴一个url=https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg 请复制上面的url直接在某个浏览器打开,你会看到如下内容: 这就是通过网页访问到的该网站的该图片,于是我们可以直接利用requests模块,进行这个图片的请求,于是这个网站便会返回给我们该图片的数据,我们
-
python3 爬取图片的实例代码
具体代码如下所示: #coding=utf8 from urllib import request import re import urllib,os url='http://tieba.baidu.com/p/3840085725' def get_image(url): #获取页面源码 page = urllib.request.urlopen(url) html = page.read() #解码,否则报错 html = html.decode('utf8') #正则匹配获取()的内容
-
Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界面如下则安装成功 2.集成Scrapy框架----输入命令行:pip install Scrapy 安装成功界面如下: 失败的情况很多,举例一种: 解决方案: 其余错误可百度搜索. 二.开始编程. 1.爬取无反爬虫措施的静态网站.例如百度贴吧,豆瓣读书. 例如-<桌面吧>的一个帖子https:
-
Python使用爬虫爬取静态网页图片的方法详解
本文实例讲述了Python使用爬虫爬取静态网页图片的方法.分享给大家供大家参考,具体如下: 爬虫理论基础 其实爬虫没有大家想象的那么复杂,有时候也就是几行代码的事儿,千万不要把自己吓倒了.这篇就清晰地讲解一下利用Python爬虫的理论基础. 首先说明爬虫分为三个步骤,也就需要用到三个工具. ① 利用网页下载器将网页的源码等资源下载. ② 利用URL管理器管理下载下来的URL ③ 利用网页解析器解析需要的URL,进而进行匹配. 网页下载器 网页下载器常用的有两个.一个是Python自带的urlli
-
python实现爬取百度图片的方法示例
本文实例讲述了python实现爬取百度图片的方法.分享给大家供大家参考,具体如下: import json import itertools import urllib import requests import os import re import sys word=input("请输入关键字:") path="./ok" if not os.path.exists(path): os.mkdir(path) word=urllib.parse.quote(w
-
python爬虫爬取图片的简单代码
Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现.只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求. 1.spider原理 spider就是定义爬取的动作及分析网站的地方. 以初始的URL**初始化Request**,并设置回调函数. 当该request**下载完毕并返回时,将生成**response ,并作为参数传给该回调函数. 2.实现python爬虫爬取图片 第一步
-
Python3直接爬取图片URL并保存示例
有时候我们会需要从网络上爬取一些图片,来满足我们形形色色直至不可描述的需求. 一个典型的简单爬虫项目步骤包括两步:获取网页地址和提取保存数据. 这里是一个简单的从图片url收集图片的例子,可以成为一个小小的开始. 获取地址 这些图片的URL可能是连续变化的,如从001递增到099,这种情况可以在程序中将共同的前面部分截取,再在最后递增并字符串化后循环即可. 抑或是它们的URL都保存在某个文件中,这时可以读取到列表中: def getUrls(path): urls = [] with open(