R语言两组变量特征相关关系热图绘制画法
目录
- 准备数据
- 简单热图
- 只对列进行聚类
- 将相关系数显示在图上
- 在图上加上显著性标记
准备数据
两组变量的数据可以像下面这样处理,分别保存在两个csv文件中。
> # 导入数据及数据预处理
> setwd("D:/weixin/")
> rows <- read.csv("rows.csv")
> cols <- read.csv("cols.csv")
> str(rows)
'data.frame': 100 obs. of 6 variables:
$ r1: num 476 482 640 452 308 ...
$ r2: num 2059 1987 1952 1927 1854 ...
$ r3: num 513 601 682 497 463 ...
$ r4: num 2235 2114 2038 1945 1916 ...
$ r5: num 433 376 525 395 238 ...
$ r6: num 2028 1943 1802 1775 1748 ...
> str(cols)
'data.frame': 100 obs. of 5 variables:
$ c1: num 2387 2437 2484 2349 2198 ...
$ c2: num 540 535 706 509 359 ...
$ c3: num 472 610 465 473 471 ...
$ c4: num 74.4 57.3 49.5 51.8 47.6 ...
$ c5: num 995 915 1038 794 652 ...
简单热图
> # 构建相关关系矩阵 > library(psych) > data.corr <- corr.test(rows, cols, method="pearson", adjust="fdr") > data.r <- data.corr$r # 相关系数 > data.p <- data.corr$p # p值 > > # 画热图 > library(pheatmap) > pheatmap(data.r, clustering_method="average")
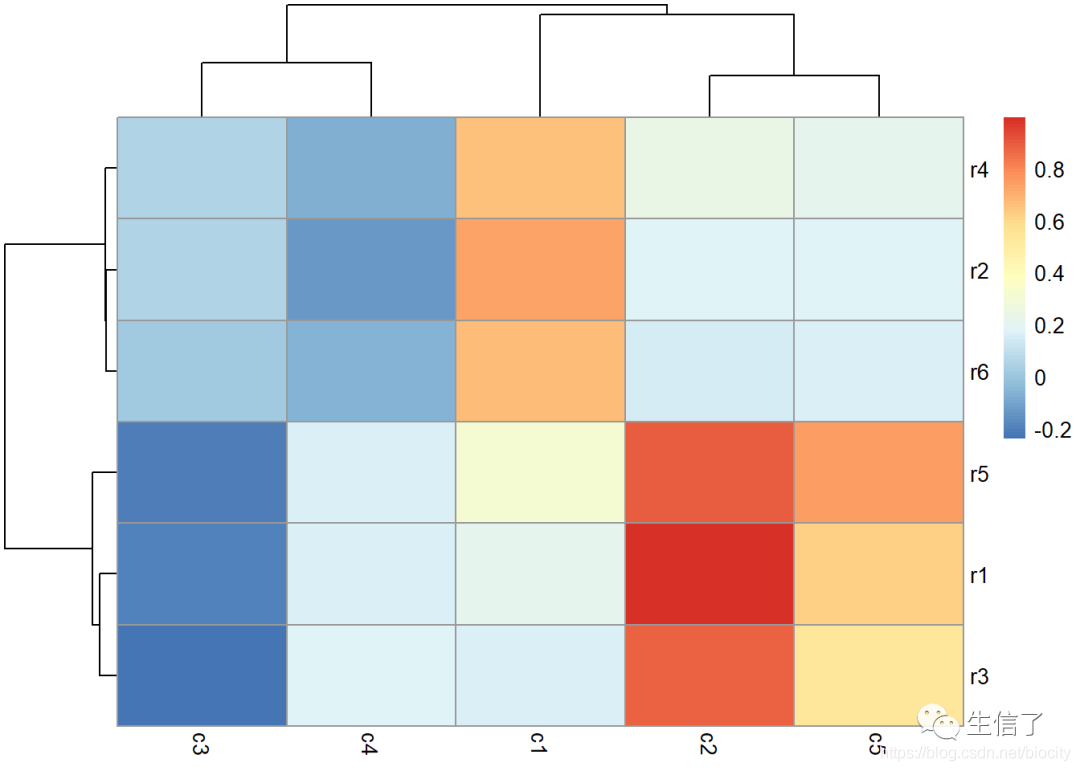
只对列进行聚类
> pheatmap(data.r, clustering_method="average", cluster_rows=F)
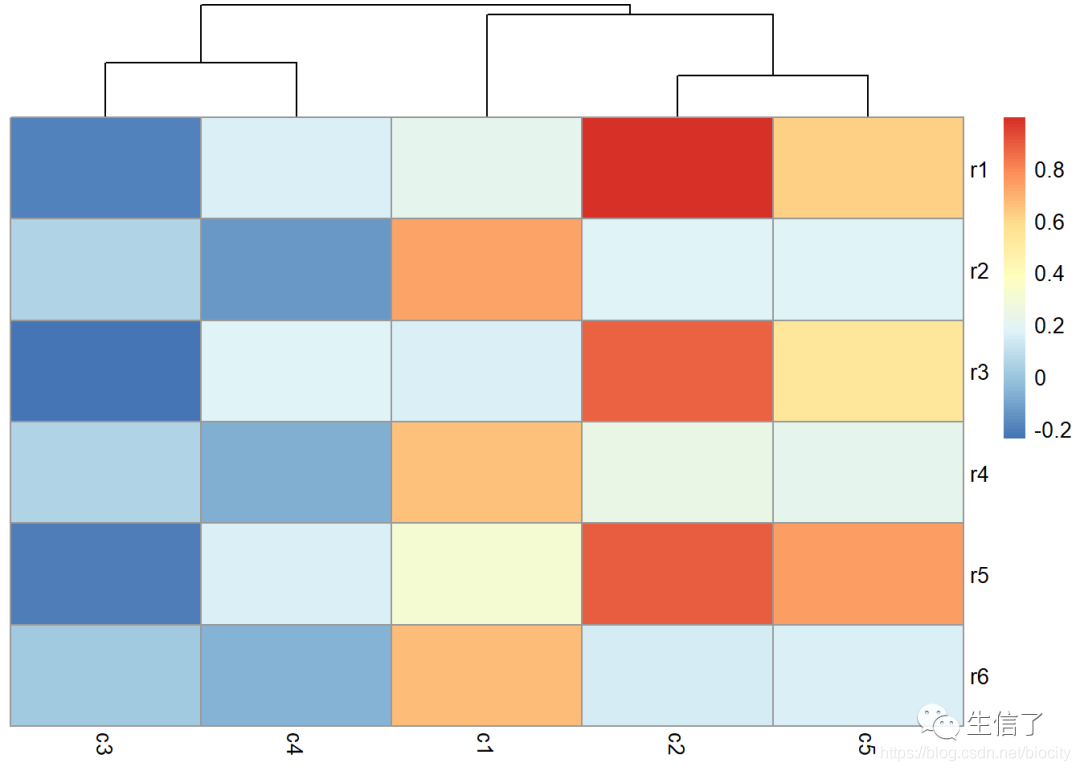
将相关系数显示在图上
> data.r.fmt <- matrix(sprintf("%.2f", data.r), nrow=nrow(data.p)) # 只保留小数点后两位
> pheatmap(data.r, clustering_method="average", cluster_rows=F, display_numbers=data.r.fmt)
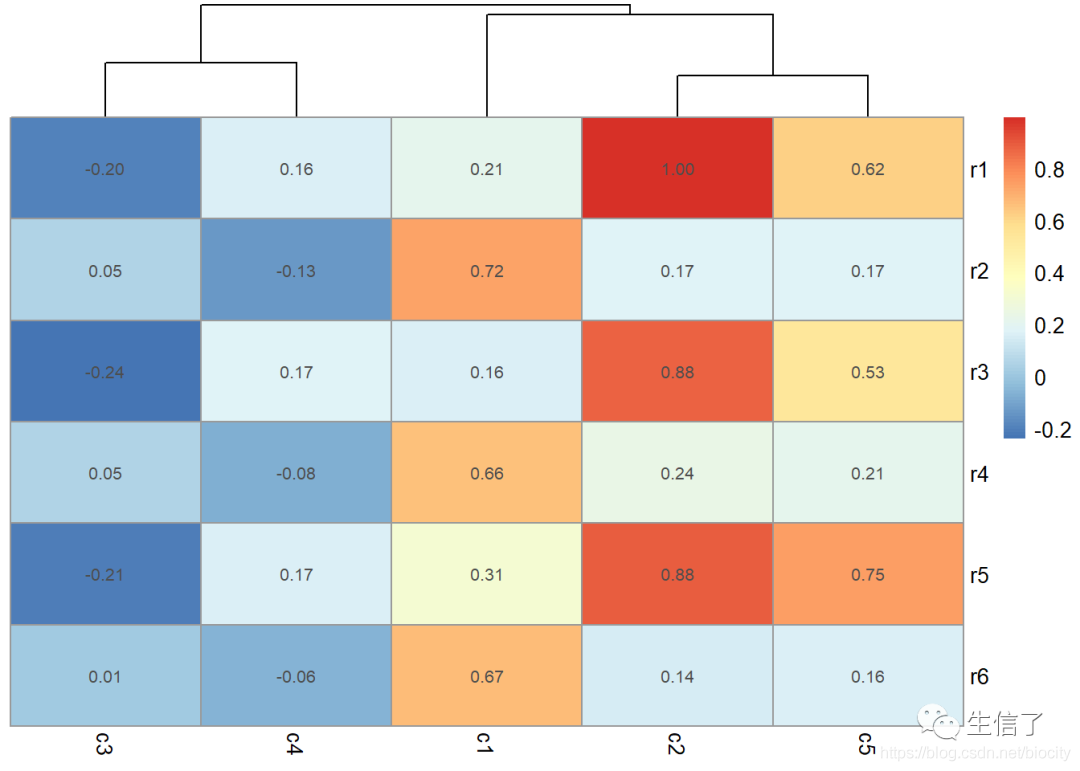
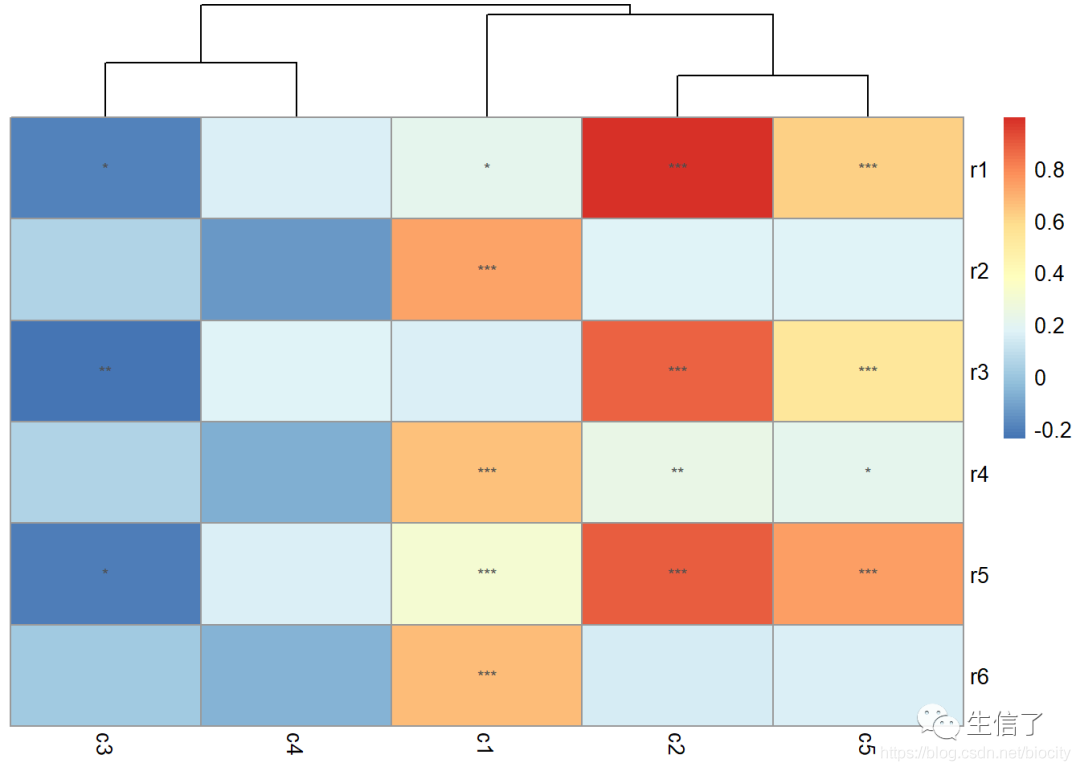
在图上加上显著性标记
> getSig <- function(dc) {
+ sc <- ''
+ if (dc < 0.01) sc <- '***'
+ else if (dc < 0.05) sc <- '**'
+ else if (dc < 0.1) sc <- '*'
+ sc
+ }
> sig.mat <- matrix(sapply(data.p, getSig), nrow=nrow(data.p))
> str(sig.mat)
chr [1:6, 1:5] "*" "***" "" "***" "***" "***" "***" "" "***" "**" ...
> pheatmap(data.r, clustering_method="average", cluster_rows=F, display_numbers=sig.mat)
如果想进一步改变图形效果,可以参考pheatmap函数的用法,修改相应的参数。比如:聚类方式改为complete,加上标题等。
> pheatmap(data.r, clustering_method="complete", cluster_rows=F, display_numbers=sig.mat, main="Corr Heatmap")
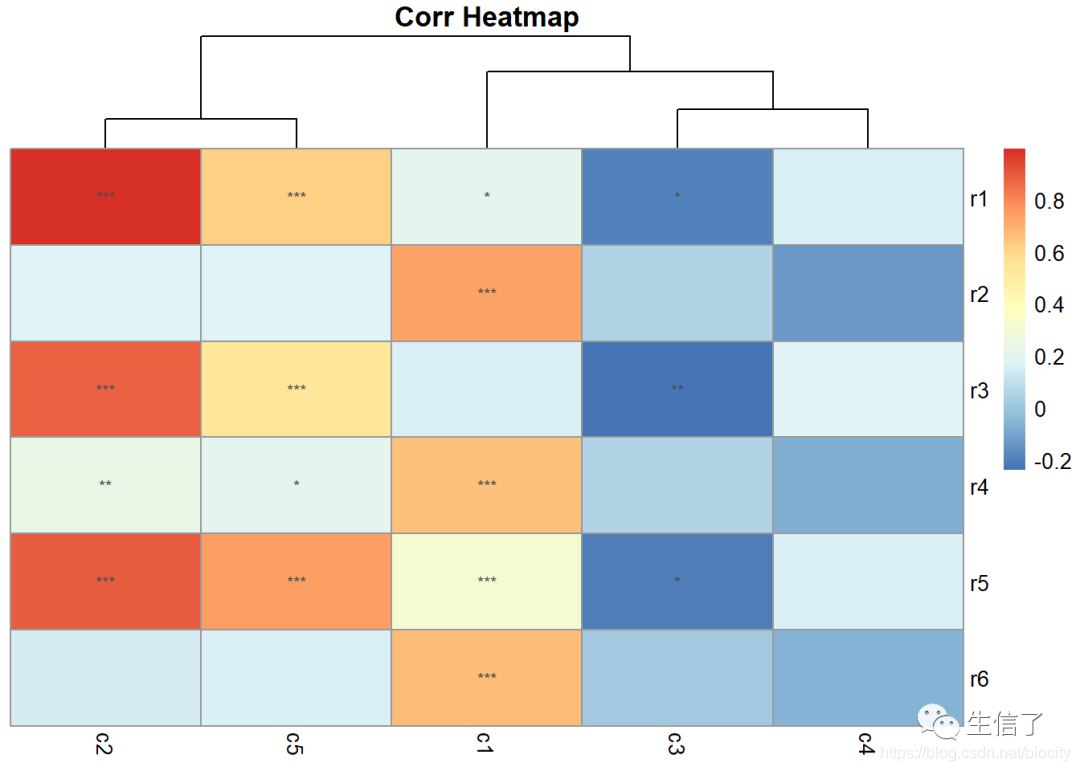
以上就是R语言两组变量特征相关关系热图绘制画法的详细内容,更多关于R语言绘制相关关系热图的资料请关注我们其它相关文章!
相关推荐
-

R语言数可视化Split violin plot小提琴图绘制方法
最近小仙同学在好几篇文献里看到了这种小提琴图,暂时就肤浅地认为这是作者为了更好地比较对照组与实验组的差别,所以将同一个基因的小提琴图各画了一半,放在一起.为了跟上可视化的潮流,小仙也来尝试画一下这个没查到正经名字的图. Step1. 绘图数据的准备 首先要把你想要绘图的数据调整成R语言可以识别的格式,建议大家在excel中保存成csv格式.作图数据格式如下: Step2. 绘图数据的读取 data<-read.csv("your file path", header = T) #
-
R语言数据可视化绘图Lollipop chart棒棒糖图
目录 Step1.绘图数据的准备 Step2.绘图数据的读取 Step3.绘图所需package的调用 Step4.因子水平排序 Step5.绘图 今天给大家分享的是Lollipop chart(棒棒糖图)的画法.棒棒糖图的用途跟条形图的用法类似,只是看起来更加美观一些,图表形式更加丰富(数据不够.拿图来凑,啥也不能阻止我优秀 ). 为了跟之前画的柱状图更好的比较,今天画图使用了相同的数据. 作图思路:棒棒糖图实际上是在散点图的基础上增加了辅助线. 不过在作图过程中还是遇到了和之前一样的问题,数
-
R语言绘制小提琴图violin plot实现示例
目录 Step1.绘图数据的准备 Step2.绘图数据的读取 Step3.绘图所需package的安装.调用 Step4.绘图 Step5.美化 即便小仙同学决定学习R语言来提升自己作图的“逼格”的时候,心中还有有些疑虑的(嘿嘿,我这么懒,可不愿意做无用功了?).仔细想了想,貌似又找到了两个学习R的理由. 一是R可以帮助我们避免重复劳动,实现“一劳永逸”的终极梦想.尽管非常不想承认这一事实,在科研的过程中,小仙同学制造出了大量“无效”的数据(sign…),但也不得不“绞尽脑汁”.“竭尽全力”地进
-
R语言绘制Radar chart雷达图
目录 更新前原文 作图方法: Step1. 绘图数据的准备 Step2. 绘图数据的读取 Step3.绘图所需package的安装.调用 Step4.绘图数据格式调整 Step5.绘图 填充透明度调整方法如下: 1.取消编组 2.选中线条,对象—实时上色—建立 3.选中线条,对象—拓展 4.更改填充颜色,输入相应颜色RGB数值 5.删掉图形白色背景 6.外观—填色—不透明度—调整数值 对于导出带有透明度的高清图,小仙又发现了更懒的办法,特来更新 再Rstudio里调整好透明度之后,直接导出pdf
-
R语言绘制数据可视化小提琴图画法示例
目录 Step1. 绘图数据的准备 Step2. 绘图数据的读取 Step3. 绘图所需package的安装.调用 Step4. 绘图 小提琴图之前已经画过了,不过最近小仙又看到一种貌美的画法,决定复刻一下.文献中看到的图如下: Step1. 绘图数据的准备 首先要把你想要绘图的数据调整成R语言可以识别的格式,建议大家在excel中保存成csv格式.作图数据如下: Step2. 绘图数据的读取 data<-read.csv("your file path", header = T
-
R语言绘制Facet violin plot小提琴刻面图实现示例
目录 Step1.绘图数据的准备 Step2.绘图数据的读取 Step3.绘图所需package的安装.调用 Step4.绘图 Step5.美化 老铁们,许久未见啦.顺便说一下,最近可不是小仙同学偷懒哟,电脑上个月送修今天刚刚拿回来(想买联想Yoga的同学先问问自己会不会拆电脑换排线,我买的这台用了一个月,送修也用了一个月 ).最近我可攒了个大招呢,先来看看下面这张图,有没有很眼熟呢? 这张图在开始介绍R语言的时候就出现过啦,不过小仙同学当时并不知道怎么画.今天可以秀一把啦. Step1. 绘图
-
R语言两组变量特征相关关系热图绘制画法
目录 准备数据 简单热图 只对列进行聚类 将相关系数显示在图上 在图上加上显著性标记 准备数据 两组变量的数据可以像下面这样处理,分别保存在两个csv文件中. > # 导入数据及数据预处理 > setwd("D:/weixin/") > rows <- read.csv("rows.csv") > cols <- read.csv("cols.csv") > str(rows) 'data.frame':
-
R语言数据可视化包ggplot2画图之散点图的基本画法
目录 前言 下面以一个简单的例子引入: 首先介绍第一类常用的图像类型:散点图 给原始数据加上分类标签: 按z列分类以不同的颜色在图中画出散点图: 按z列分类以不同的形状在图中画出散点图: 多面化(将ABC三类分开展示): 自定义颜色: 添加拟合曲线: 更换主题 : 总结 前言 ggplot2的功能很强大,并因为其出色的画图能力而闻名,下面来介绍一下它的基本画图功能,本期介绍散点图的基本画法. 在ggplot2里,所有图片由6个基本要素组成: 1. 数据(Data) 2. 层次(Layers),包
-
R语言-如何截取变量中指定位置的若干个字符
例如,某数据库如下,需要把第二个变量里面的ID号码(格式为T-20-252-02)提取出来作为一个新变量. 命令如下: b=readWorksheetFromFile(temp[11],sheet=1) 读入excel数据,命名为数据库b,这里temp[11]是读入temp中第11个文件名对应的文件 attach(b) attach数据库,之后即可直接用变量名file, 否则要用b$file b$id=substr(File,regexpr("T",File),regexpr(&quo
-
R语言关于变量的知识点总结
变量为我们提供了我们的程序可以操作的命名存储. R语言中的变量可以存储原子向量,原子向量组或许多Robject的组合. 有效的变量名称由字母,数字和点或下划线字符组成. 变量名以字母或不以数字后跟的点开头. 变量名 合法性 原因 var_name2. 有效 有字母,数字,点和下划线 VAR_NAME% 无效 有字符'%'.只有点(.)和下划线允许的. 2var_name 无效 以数字开头 .var_name, var.name 有效 可以用一个点(.),但启动点(.),不应该后跟一个数字. .2
-
R语言实现将分类变量转换为哑变量(dummy vairable)
生成测试数据 a1 <- c("f","f","b","b","c,"c") 利用nnet包中的函数class.ind > class.ind(a1) b c f [1,] 0 0 1 [2,] 0 0 1 [3,] 1 0 0 [4,] 1 0 0 [5,] 0 1 0 [6,] 0 1 0 class.ind代码 class.ind <- function(cl) { n &
-
R语言-修改(替换)因子变量的元素操作
因子变量的核心是水平,通过指定水平来修改. x<-c(1,1,1,1,2,2,2,3,3,3,3,4) xx<-factor(x);xx levels(xx) #得到水平为3的位置 level_3<-which(levels(xx)==3) #重新赋值 levels(xx)[level_3]<-03 xx #由于新值是03,0开头,所以把03当成3处理 levels(xx)[level_3]<-c("03") xx #字符串会自动转换成因子 levels(
-
R语言 如何删除指定变量或对象
R语言中删除指定变量或对象,可以直接删除某名字的变量或对象,也可以删除以字符串形式表示的变量和对象. 例如: 1.直接删除 >a<-c(1,2,3) >rm(a) 2.以字符串形式的方式删除 >a<-c(1,2,3) >rm('a') 3.删除不再需要的对象 在使用R语言的过程中,除了要保留特定的对象外,其他的对象不再需要 >a<-ls() > rm(list=a[which(a!='c2' & a !='m2' & a !='cpu1
-
R语言中的五种常用统计分析方法
1.分组分析aggregation 根据分组字段,将分析对象划分为不同的部分,以进行对比分析各组之间差异性的一种分析方法. 常用统计指标: 计数 length 求和 sum 平均值 mean 标准差 var 方差 sd 分组统计函数 aggregate(分组表达式,data=需要分组的数据框,function=统计函数) 参数说明 formula:分组表达式,格式:统计列~分组列1+分组列2+... data=需要分组的数据框 function:统计函数 aggregate(name ~ cla
-
R语言线性回归知识点总结
回归分析是一种非常广泛使用的统计工具,用于建立两个变量之间的关系模型. 这些变量之一称为预测变量,其值通过实验收集. 另一个变量称为响应变量,其值从预测变量派生. 在线性回归中,这两个变量通过方程相关,其中这两个变量的指数(幂)为1.数学上,线性关系表示当绘制为曲线图时的直线. 任何变量的指数不等于1的非线性关系将创建一条曲线. 线性回归的一般数学方程为 y = ax + b 以下是所使用的参数的描述 y是响应变量. x是预测变量. a和b被称为系数常数. 建立回归的步骤 回归的简单例子是当人的
-
R语言学习ggplot2绘制统计图形包全面详解
目录 一.序 二.ggplot2是什么? 三.ggplot2能画出什么样的图? 四.组装机器 五.设计图纸 六.机器的零件 1. 零件--散点图 1) 变换颜色 2) 拟合曲线 3) 变换大小 4) 修改透明度 5) 分层 6) 改中文 2. 零件--直方图与条形图 1) 直方图 2) 润色 3) 条形图 3. 零件--饼图 4. 零件--箱线图 5. 零件--小提琴图 6. 零件打磨 7. 超级变变变 8. 其他常用零件 七.实践出真知 八.学习资源 九.参考资料 一.序 作为一枚统计专业的学