golang内存对齐的概念及案例详解
什么是内存对齐
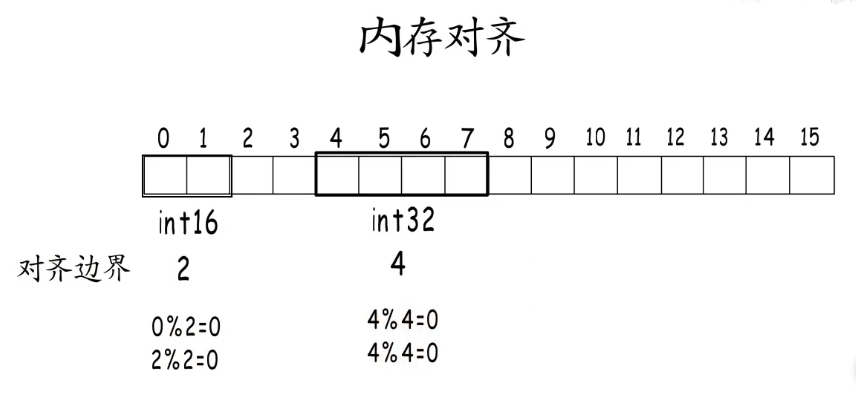
为保证程序顺利高效的运行,编译器会把各种类型的数据安排到合适的地址,并占用合适的长度,这就是内存对齐。
每种类型的对齐值就是它的对齐边界,内存对齐要求数据存储地址以及占用的字节数都要是它的对齐边界的倍数。所以下述的int32要错开两个字节,从4开始存,却不能紧接着从2开始。
也可以这样解释:
CPU把内存当成是一块一块的,块的大小可以是2,4,8,16字节大小,因此CPU在读取内存时是一块一块进行读取的。块大小成为memory access granularity(粒度)。
如果不进行内存对齐
比如我们想从地址1开始读8字节的数据:
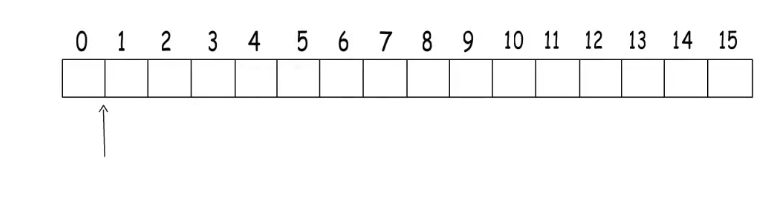
CPU会分两次读:
- 第一次从
0 - 7但只取后7字节。 - 第二次从
8 - 15但只取第1字节。
分两次读,这样势必会对性能造成影响。
为什么要内存对齐
原因主要有两点:
- 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
对齐边界
那该怎么确定每种数据的对齐边界呢?这和平台有关,go语言支持这些平台:
可以看到常见的32位平台,指针宽度和寄存器宽度都是4字节,64位平台上都是8字节。而被go语言称为寄存器宽度的这个值,就可以理解为机器字长,也是平台对应的最大对齐边界。

而数据类型的对齐边界,是取类型大小与平台最大对齐边界中较小的那个。不过要注意,同一个类型在不同平台上,大小可能不同,对齐边界也可能不同。

为什么不统一使用平台最大对齐边界呢?或者统一按各类型大小来对齐呢?
我们来试一下,假设目前是64位平台,最大对齐边界为8字节。int8只有1字节,按照1字节对齐的话,它可以放在任何位置,因为总能通过一次读取把它完整拿出来。如果统一对齐到8字节,虽然同样只要读取一次,但每个int8的变量都要浪费7字节,所以对齐到1。
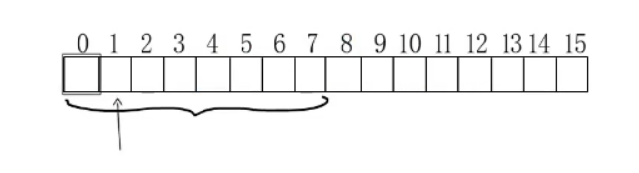
int16占2字节,按照2字节对齐,可以从这些地址开始存,而且能保证只用读取一次。

如果按1字节对齐就可能存成这样,那就要读取两次再截取拼接,会影响性能。

如果按8字节对齐,会与int8一样浪费内存,所以对齐到2。
这是小于最大对齐边界的情况,再来看看大于的情况。
假设要在32位的平台下存储一个int64类型的数据,在0和1位置被占用的情况下,就要从位置8开始存。而如果对齐到4,就可以从位置4开始,内存浪费更少,所以选择对齐到4。

因此类型对齐边界会这样选择,依然是为了减少浪费提升性能。

GO 计算对齐边界函数
在go语言中可以调用 unsafe.Alignof 来返回相应类型的对齐边界:
func main() {
fmt.Printf("bool align: %d\n", unsafe.Alignof(bool(true)))
fmt.Printf("int32 align: %d\n", unsafe.Alignof(int32(0)))
fmt.Printf("int8 align: %d\n", unsafe.Alignof(int8(0)))
fmt.Printf("int64 align: %d\n", unsafe.Alignof(int64(0)))
fmt.Printf("byte align: %d\n", unsafe.Alignof(byte(0)))
fmt.Printf("string align: %d\n", unsafe.Alignof("EDDYCJY"))
fmt.Printf("map align: %d\n", unsafe.Alignof(map[string]string{}))
}
运行结果:
bool align: 1
int32 align: 4
int8 align: 1
int64 align: 8
byte align: 1
string align: 8
map align: 8
确定结构体的对齐边界
对结构体而言,首先要确定每个成员的对齐边界,然后取其中最大的,这就是这个结构体的对齐边界。

然后来存储这个结构体变量:
内存对齐要求一:
- 存储这个结构体的起始地址,是对齐边界的倍数。
假设从0开始存,结构体的每个成员在存储时,都要把这个起始地址当作地址0,然后再用相对地址来决定自己该放在哪里。
内存对齐要求2:
- 结构体整体占用字节数需要是类型对齐边界的倍数,不够的话要往后扩张一下。
所以最终上述结构体类型的大小就是24字节。
案例
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
type Part2 struct {
a bool
c int8
e byte
b int32 // 4个字节
d int64
}
分别求以上两个结构体占用的字节:
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
fmt.Printf("part2 size: %d, align: %d\n", unsafe.Sizeof(part2), unsafe.Alignof(part2))
这里我们直接调用函数求得:
part1 size: 32, align: 8 part2 size: 16, align: 8
原因请读者来思考。
参考资料:
https://blog.csdn.net/u010853261/article/details/102557188
https://www.bilibili.com/video/BV1Ja4y1i7AF?from=search&seid=16213689667007976568&spm_id_from=333.337.0.0
到此这篇关于golang内存对齐的文章就介绍到这了,更多相关golang内存对齐内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Golang 内存模型详解(一)
开始之前 首先,这是一篇菜B写的文章,可能会有理解错误的地方,发现错误请斧正,谢谢. 为了治疗我的懒癌早期,我一次就不写得太多了,这个系列想写很久了,每次都是开了个头就没有再写.这次争取把写完,弄成一个系列. 此 nil 不等彼 nil 先声明,这个标题有标题党的嫌疑. Go 的类型系统是比较奇葩的,nil 的含义跟其它语言有些差别,这里举个例子(可以直接进入 http://play.golang.org/p/ezFhXX0dnB 运行查看结果): 复制代码 代码如下: package main
-
golang切片内存应用技巧详解
在 Go 语言中切片是使用非常频繁的一种聚合类型,它代表变长的序列,底层引用一个数组对象.一个切片由三个部分构成:指针.长度和容量.指针指向该切片自己第一个元素对应的底层数组元素的内存地址. 切片的类型声明如下: type slice struct { array unsafe.Pointer len int cap int } 多个切片之间可以共享底层数组的数据,并且引用的数组区间可能重叠.利用切片 的这个特性我们可以在原有内存空间中对切片进行反转.筛选和去重等操作,这样就不用声明一个指向新内
-
解决golang内存溢出的方法
最近在项目中出现golang内存溢出的问题,master刚开始运行时只有10多M,运行几天后,竟然达到了10多个G.而且到凌晨流量变少内存也没有明显降低,内存状态呈现一种很不健康的曲线. 像这种情况肯定是golang内存溢出了,为此我持续排查了两天,终于找到问题所在,特此记录下. 准备工作 一台较好的环境测试机,单台运行无污染. 压测工具,无论服务是http还是websocket服务,都必须准备好压测工具模拟最真实的用户场景. 将master引入net/http/pprof包,通过http访问获
-
golang内存对齐的概念及案例详解
什么是内存对齐 为保证程序顺利高效的运行,编译器会把各种类型的数据安排到合适的地址,并占用合适的长度,这就是内存对齐. 每种类型的对齐值就是它的对齐边界,内存对齐要求数据存储地址以及占用的字节数都要是它的对齐边界的倍数.所以下述的int32要错开两个字节,从4开始存,却不能紧接着从2开始. 也可以这样解释: CPU把内存当成是一块一块的,块的大小可以是2,4,8,16字节大小,因此CPU在读取内存时是一块一块进行读取的.块大小成为memory access granularity(粒度). 如果
-
webpack-dev-server核心概念案例详解
webpack-dev-server 核心概念 Webpack 的 ContentBase vs publicPath vs output.path webpack-dev-server 会使用当前的路径作为请求的资源路径(所谓 当前的路径 就是运行 webpack-dev-server 这个命令的路径,如果对 webpack-dev-server 进行了包装,比如 wcf,那么当前路径指的就是运行 wcf命令的路径,一般是项目的根路径),但是读者可以通过指定 content-base 来修改这
-
Golang Protocol Buffer案例详解
Golang Protocol Buffer教程 本文介绍如何在Go应用中利用Protocol Buffer数据格式.主要包括什么是Protocol Buffer数据格式,其超越传统数据格式XML或JSON的优势是什么. 1. Protocol Buffer数据格式 Protocol Buffer,本质就是一种数据格式,和JSON或XML一样,不同的语言用于结构化数据序列化或反序列化.该数据格式的优势是较xml或json更小,源于Google.假如我们有一个对象,我们用三种数据结构进行表示: <
-
二叉树的概念案例详解
二叉树简介 关于树的介绍,请参考:https://blog.csdn.net/weixin_43790276/article/details/104033482 一.二叉树简介 二叉树是每个节点最多有两个子树的树结构,是一种特殊的树,如下图,就是一棵二叉树. 二叉树是由n(n>=0)个节点组成的数据集合.当 n=0 时,二叉树中没有节点,称为空二叉树.当 n=1 时,二叉树只有根节点一个节点.当 n>1 时,二叉树的每个节点都最多只能有两个子树,递归地构建成一棵完整的二叉树. 二叉树的两个子树
-
Python 二叉树的概念案例详解
二叉树简介 关于树的介绍,请参考:https://www.jb51.net/article/222488.htm 一.二叉树简介 二叉树是每个节点最多有两个子树的树结构,是一种特殊的树,如下图,就是一棵二叉树. 二叉树是由n(n>=0)个节点组成的数据集合.当 n=0 时,二叉树中没有节点,称为空二叉树.当 n=1 时,二叉树只有根节点一个节点.当 n>1 时,二叉树的每个节点都最多只能有两个子树,递归地构建成一棵完整的二叉树. 二叉树的两个子树被称为左子树(left subtree)和右子树
-
C语言指针数组案例详解
指针与数组是 C 语言中很重要的两个概念,它们之间有着密切的关系,利用这种 关系,可以增强处理数组的灵活性,加快运行速度,本文着重讨论指针与数组之 间的联系及在编程中的应用. 1.指针与数组的关系 当一个指针变量被初始化成数组名时,就说该指针变量指向了数组.如: char str[20], *ptr; ptr=str; ptr 被置为数组 str 的第一个元素的地址,因为数组名就是该数组的首地址, 也是数组第一个元素的地址.此时可以认为指针 ptr 就是数组 str(反之不成立), 这样原来对数
-
JavaWeb之会话技术案例详解
会话技术 1. 会话:一次会话中包含多次请求和响应. 一次会话:浏览器第一次给服务器资源发送请求,会话建立,直到有一方断开为止 2. 功能:在一次会话的范围内的多次请求间,共享数据 3. 方式: 1. 客户端会话技术:Cookie 2. 服务器端会话技术:Session Cookie: 1. 概念:客户端会话技术,将数据保存到客户端 2. 快速入门: 1. 创建Cookie对象,绑定数据
-
Java ConcurrentHashMap用法案例详解
一.概念 哈希算法(hash algorithm):是一种将任意内容的输入转换成相同长度输出的加密方式,其输出被称为哈希值. 哈希表(hash table):根据设定的哈希函数H(key)和处理冲突方法将一组关键字映象到一个有限的地址区间上,并以关键字在地址区间中的象作为记录在表中的存储位置,这种表称为哈希表或散列,所得存储位置称为哈希地址或散列地址. 二.HashMap与HashTable 1,线程不安全的HashMap 因为多线程环境下,使用HashMap进行put操作会引起死循环,导致CP
-
C语言 指针的初始化赋值案例详解
目录 1.指针的初始化 2.指针的赋值 3.指针常量 4.指针初始化补充 5.void *型指针 6.指向指针的指针 1.指针的初始化 指针初始化时,"="的右操作数必须为内存中数据的地址,不能够是变量,也不能够直接用整型地址值(可是int*p=0;除外,该语句表示指针为空).此时,*p仅仅是表示定义的是个指针变量,并没有间接取值的意思. 比如: int a = 25; int *ptr = &a; int b[10]; int *point = b; int *p = &am
-
C++指针与引用的区别案例详解
C++中指针和引用的区别 从概念上讲.指针从本质上讲就是存放变量地址的一个变量,在逻辑上是独立的,它可以被改变,包括其所指向的地址的改变和其指向的地址中所存放的数据的改变. 而引用是一个别名,它在逻辑上不是独立的,它的存在具有依附性,所以引用必须在一开始就被初始化,而且其引用的对象在其整个生命周期中是不能被改变的(自始至终只能依附于同一个变量). 在C++中,指针和引用经常用于函数的参数传递,然而,指针传递参数和引用传递参数是有本质上的不同的: 指针传递参数本质上是值传递的方式,它所传递的是一个