C语言详解如何应用模拟字符串和内存函数
目录
- 1.strlen 求字符串长度
- 使用案例:
- 1.计数法
- 2.不创建临时变量计数器-递归
- 3.指针-指针的方式
- 2.长度不受限制的字符串函数
- 1.strcpy
- 使用案例:
- 模拟实现:
- 2.strcat
- 使用案例:
- 模拟实现:
- 3.strcmp-比较字符串首字母的大小
- 使用案例:
- 模拟实现:
- 3.长度受限制的字符串函数
- 1.strncpy
- 使用案例:
- 2.strncat
- 使用案例:
- 3.strncmp
- 使用案例:
- 4.strstr-找子串
- 使用案例:
- 模拟实现:
- 5.strtok
- 用法:
- 改进:
- 6.strerror
- 展示:
- 使用方式:
- 7.memcpy-不重复内存拷贝
- 使用案例:
- 模拟实现:
- 8.memmove-可处理重复内存拷贝
- 使用案例:
- 模拟实现:
- 9.memcmp
- 10.memset
- 应用方式:
1.strlen 求字符串长度
size_t strlen ( const char * str ); //返回值是unsigned int类型
使用案例:
#include <stdio.h>
int main()
{
char arr[] = { "abcde" };
printf("%d\n",strlen(arr));
return 0;
}
我们知道在arr数组里,最后一个字符'e'后,默认是'\0',而strlen遇到'\0'则会结束运行,且返回的是在字符串中 '\0' 前面出现的字符个数(不包 含 '\0' )。
我们可以根据这个来对strlen进行模拟实现:
1.计数法
#include <stdio.h>
#include <assert.h>
int my_strlen(const char* str)
{
assert(str);
int count = 0; //计数
while (*str) //解引用判断元素是否为'\0'
{
count++;
str++; //地址++
}
return count; //返回计数
}
int main()
{
int len = my_strlen("abcdef");
printf("%d\n", len);
return 0;
}
2.不创建临时变量计数器-递归
#include <stdio.h>
#include <assert.h>
int my_strlen(const char * str)
{
assert(str);
if (*str == '\0')
return 0;
else
return 1 + my_strlen(str + 1);
}
int main()
{
char arr[] = {"abcdef"};
int ret = my_strlen(arr);
printf("%d\n", ret);
return 0;
}
3.指针-指针的方式
#include <stdio.h>
#include <assert.h>
int my_strlen(char *s)
{
char *p = s;
while (*p != '\0')
p++;
return p - s; //指针相减是长度
}
int main()
{
char arr[] = {"abcdef"};
int ret = my_strlen(arr);
printf("%d\n", ret);
return 0;
}
2.长度不受限制的字符串函数
1.strcpy
char* strcpy(char * destination, const char * source );
源字符串必须以 '\0' 结束。
会将源字符串中的 '\0' 拷贝到目标空间。
目标空间必须足够大,以确保能存放源字符串。
目标空间必须可变。
使用案例:
#include <stdio.h>
#include <assert.h>
int main()
{
char arr1[] = {'a', 'b', 'c', 'd', 'e', 'f', '\0'};
char arr2[20] = "xxxxxxxxxxxx";
strcpy(arr2, arr1);
printf("%s\n", arr2);
return 0;
}

模拟实现:
#include <stdio.h>
#include <assert.h>
char* my_strcpy(char* dest, const char* src)
{
char* ret = dest;
//保留起始地址
assert(dest && src);
while (*dest++ = *src++) //这里不打印'\0'之后的
{
;
}
return ret;
}
int main()
{
char arr1[] = {'a', 'b', 'c', 'd', 'e', 'f', '\0'};
char arr2[20] = "xxxxxxxxxxxx";
my_strcpy(arr2, arr1);
printf("%s\n", arr2);
return 0;
}
2.strcat
char * strcat ( char * destination, const char * source );
源字符串必须以 '\0' 结束。
目标空间必须有足够的大,能容纳下源字符串的内容。
目标空间必须可修改。
使用案例:
#include <stdio.h>
#include <assert.h>
int main()
{
char arr1[30] = "hello";//注意初始化方式,必须要包含'\0'
char arr2[] = "world";
strcat(arr1, arr2);
printf("%s\n", arr1);
return 0;
}


模拟实现:
#include <stdio.h>
#include <assert.h>
char* my_strcat(char* dest, const char* src)
{
char* ret = dest;
//保留起始地址,方便找回打印
assert(dest && src);
//1. 找目标空间中的\0,打印的起点
while (*dest)
{
dest++;
}
//2. 追加内容到目标空间
while (*dest++ = *src++)
{
;
}
return ret;
}
int main()
{
char arr1[30] = "hello";//注意初始化方式,必须要包含'\0'
char arr2[] = "world";
printf("%s\n", my_strcat(arr1, arr2));
return 0;
}
3.strcmp-比较字符串首字母的大小
int strcmp ( const char * str1, const char * str2 );
第一个字符串大于第二个字符串,则返回大于0的数字
第一个字符串等于第二个字符串,则返回0
第一个字符串小于第二个字符串,则返回小于0的数字
使用案例:
#include <stdio.h>
#include <assert.h>
int main()
{
char arr1[] = "degh";
char arr2[] = "bcdefx";
int ret = strcmp(arr1, arr2);
if (ret<0)
{
printf("arr1<arr2");
}
else if (ret >0)
{
printf("arr1>arr2");
}
else
{
printf("arr1==arr2");
}
return 0;
}

就是根据返回的值来判断两个字符串大小
模拟实现:
//模拟实现strcmp-比较对应位置字符串大小
//相同的话地址各向后加一继续比较
//注意strcmp返回的是大于等于或小于0的整型
#include <stdio.h>
#include <assert.h>
int my_strcmp(const char* str1, const char*str2)
{
assert(str1 && str2);
while (*str1 == *str2)
{
if (*str1 == '\0')
return 0;
//若相等,各向后+1继续比较
str1++;
str2++;
}
return *str1 - *str2;
}
int main()
{
char arr1[] = "degh";
char arr2[] = "bcdefx";
int ret = my_strcmp(arr1, arr2);
if (ret<0)
{
printf("arr1<arr2");
}
else if (ret >0)
{
printf("arr1>arr2");
}
else
{
printf("arr1==arr2");
}
return 0;
}

3.长度受限制的字符串函数
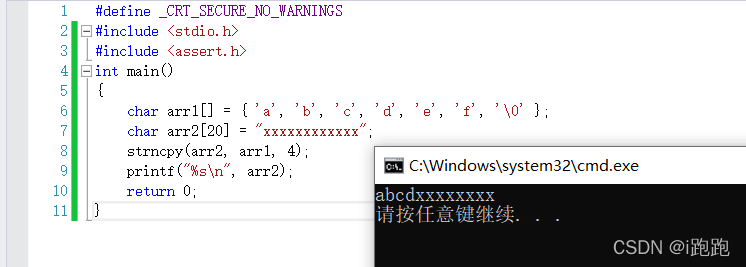
1.strncpy
char * strncpy ( char * destination, const char * source, size_t num );
相较于strcpy,strncpy函数有了对字符长度的限制,更加的灵活
使用案例:
#include <stdio.h>
#include <assert.h>
int main()
{
char arr1[] = {'a', 'b', 'c', 'd', 'e', 'f', '\0'};
char arr2[20] = "xxxxxxxxxxxx";
strncpy(arr2, arr1,4);
printf("%s\n", arr2);
return 0;
}
2.strncat
char * strncat ( char * destination, const char * source, size_t num );
使用案例:
#include <stdio.h>
#include <assert.h>
int main()
{
char arr1[30] = "hello";
char arr2[] = "world";
strncat(arr1, arr2,3);
printf("%s\n", arr1);
return 0;
}

若给的数字超过了arr2的长度,如:
strncat(arr1, arr2,7);
则

只会追加到arr2元素中的'\0'结束。
3.strncmp
int strncmp ( const char * str1, const char * str2, size_t num );
使用案例:
#include <stdio.h>
#include <assert.h>
int main()
{
char arr1[] = "degh";
char arr2[] = "bcdefx";
int ret = strncmp(arr1, arr2,3);
if (ret<0)
{
printf("arr1<arr2");
}
else if (ret >0)
{
printf("arr1>arr2");
}
else
{
printf("arr1==arr2");
}
return 0;
}

这里的数字3表明比较的是前3个 字符串的大小。
4.strstr-找子串
char * strstr ( const char *str2, const char * str1);
在字符串里找子串,返回找到子串的起始地址
找不到则返回空指针
使用案例:
#include <stdio.h>
int main()
{
char arr1[] = "abbbcdef";
char arr2[] = "bbcq";
char* ret = strstr(arr1, arr2); //因为返回的是地址,要用指针接收
if (NULL == ret)
printf("没找到\n");
else
printf("%s\n", ret);
return 0;
}

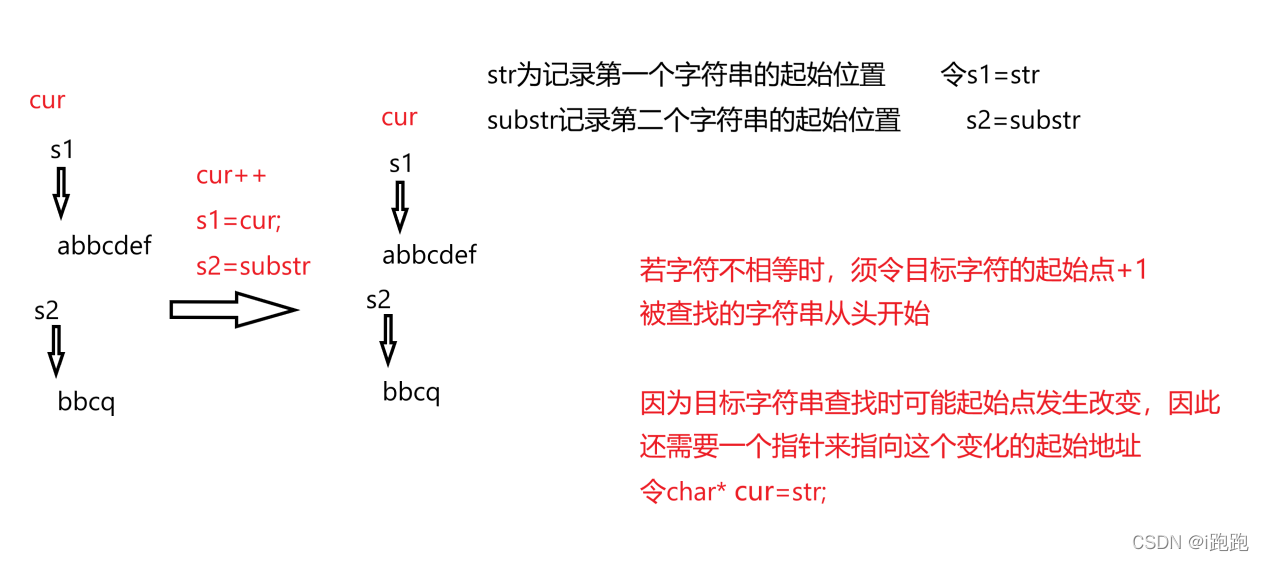
模拟实现:
#include <stdio.h>
#include <assert.h>
char* my_strstr(const char* str, const char* substr)
{
const char* s1 = str;
const char* s2 = substr;
const char* cur = str; //记录字符串起始位置,在改变
assert(str && substr);
if (*substr == '\0')
{
return (char*)str;
}
while (*cur) //如果*cur为'\0',则找不到,返回空指针
{
s1 = cur;
s2 = substr;
while (*s1 && *s2 && *s1 == *s2) //*s1 *s2不为'\0'
{
s1++;
s2++;
}
if (*s2 == '\0') //找到了
return (char*)cur; //返回起始位置
cur++;
}
return NULL;
}
int main()
{
char arr1[] = "abbbcdef";
char arr2[] = "bbcq";
char* ret = my_strstr(arr1, arr2);
if (NULL == ret)
printf("没找到\n");
else
printf("%s\n", ret);
return 0;
}
5.strtok
应用:将字符串里面除了分隔符外的其他内容提出来
char * strtok ( char * str, const char * sep );
第一个参数指定一个字符串,包含了字符串和分隔符
sep参数是个字符串,定义了用作分隔符的字符集合
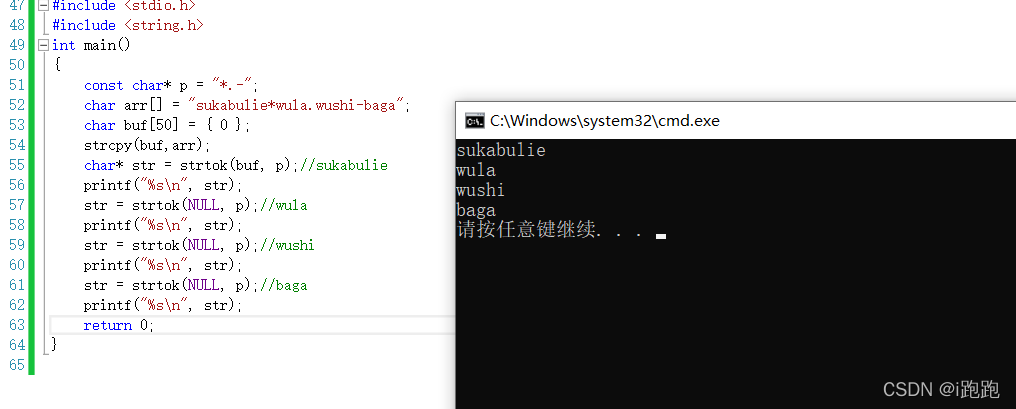
例如:
const char* p = "*.-"; char arr[] = "sukabulie*wula.wushi-baga";
sep=p str=arr
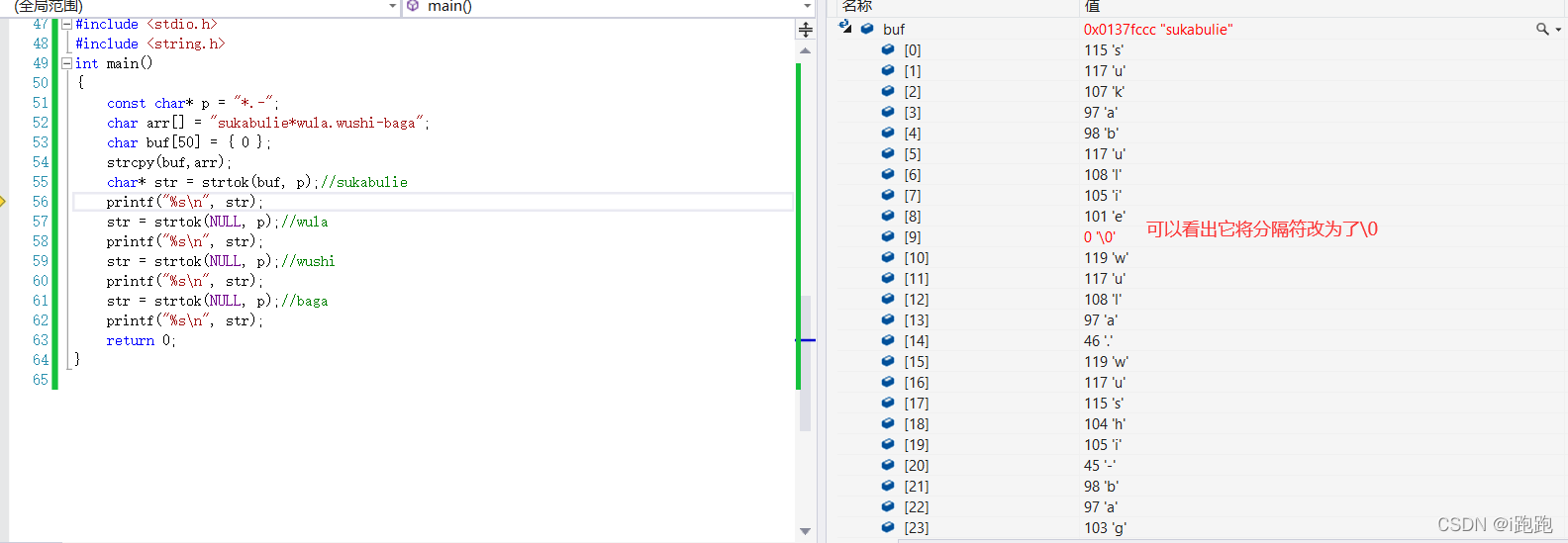
注:strtok会改变第一个字符串里的内容(将分隔符改为\0),因此不能直接将源字符串传过去,可以临时拷贝一份
char buf[50] = { 0 };
strcpy(buf,arr);
那么接下来要传参时第一个参数用buf就好。
注:strtok函数的第一个参数不为空指针 ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
strtok函数的第一个参数为空指针 ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
如果字符串中不存在更多的标记,则返回空指针。
用法:
char* str = strtok(buf, p);//sukabulie
printf("%s\n", str);
str = strtok(NULL, p);//wula
printf("%s\n", str);
str = strtok(NULL, p);//wushi
printf("%s\n", str);
str = strtok(NULL, p);//baga
printf("%s\n", str);
打印效果:
我们发现这样的写法很笨,当我们不知道一个字符串它有多少分段时就很麻烦,我们可以用for循环来解决这个问题。
改进:
#include <stdio.h>
#include <string.h>
int main()
{
const char* p = "*.-";
char arr[] = "sukabulie*wula.wushi-baga";
char buf[50] = { 0 };
strcpy(buf, arr);
for (char* str = strtok(buf, p); str != NULL; str = strtok(NULL, p))
{
printf("%s\n",str);
}
return 0;
}

6.strerror
返回错误码所对应的错误信息
C语言中规定了一些错误码及它所对应的意思(错误信息)
char * strerror ( int errnum );
int errnum 是错误码 函数返回的是错误信息的起始地址
展示:
#include <stdio.h>
int main()
{
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%s\n", strerror(i));
}
return 0;
}

使用方式:
当我们运行一个程序遇到错误,跑不过去时,可以在他执行错误代码段的下一行用
printf("%s\n",strerror(errno));
//注意要引用头文件
#include <errno.h>
errno是c语言提供的一个全局变量,可直接使用,当程序发生错误时,他会改变为相对应的错误码,我们就可以用strerror函数得到相对应的错误信息。
7.memcpy-不重复内存拷贝
void * memcpy ( void * destination, const void * source, size_t num );
将source里的元素通过字节数来拷贝到destination中
使用案例:
#include <stdio.h>
#include <string.h>
int main()
{
int arr1[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int arr2[5] = { 0 };
memcpy(arr2,arr1,5*sizeof(arr2[0]));
int i = 0;
for (i=0;i<5;i++)
{
printf("%d\n",arr2[i]);
}
return 0;
}
模拟实现:
#include <stdio.h>
#include <string.h>
#include <assert.h>
void* my_memcpy(void* dest, const void*src, size_t num)
{
void* ret = dest; //保留要返回的起始地址
assert(dest&&src);
while (num--) //先使用后--,一个字节一个字节的覆盖
{
*(char*)dest = *(char*)src;//强制类型转换是临时的
dest = (char*)dest+1; //因此改变地址时也要强制类型转换
src = (char*)src+1;
}
return ret;
}
int main()
{
int arr1[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int arr2[5] = { 0 };
my_memcpy(arr2, arr1, 5 * sizeof(arr2[0]));
int i = 0;
for (i = 0; i<5; i++)
{
printf("%d\n", arr2[i]);
}
return 0;
}

注意:c语言中要求memcpy只要可以拷贝没有重复的内存就可以了,但是在vs下memcpy也可以处理重复的内存。
若按我们写的来举例,我们的memcpy是不支持重复内存的处理:
int main()
{
int arr1[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int arr2[5] = { 0 };
my_memcpy(arr1+2, arr1, 5 * sizeof(arr1[0]));
int i = 0;
for (i = 0; i<9; i++)
{
printf("%d\n", arr1[i]);
}
return 0;
}
如若是这样拷贝,那么我们想的打印出来的应该是1 2 1 2 3 4 5 8 9
实际上是:1 2 1 2 1 2 1 8 9

用memcpy来实现:
int main()
{
int arr1[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int arr2[5] = { 0 };
memcpy(arr1+2, arr1, 5 * sizeof(arr1[0]));
int i = 0;
for (i = 0; i<9; i++)
{
printf("%d\n", arr1[i]);
}
return 0;
}

在vs下库函数memcpy功能更加强大,可处理重复内存,c语言只要求它能处理不重复的内存即可,处理重复内存时用库函数memmove,因此我们模拟的memcpy正确。
8.memmove-可处理重复内存拷贝
void * memcpy ( void * destination, const void * source, size_t num );
类型与memcpy相同
使用案例:
#include <stdio.h>
#include <string.h>
int main()
{
int arr1[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int arr2[5] = { 0 };
memmove(arr1 + 2, arr1, 5 * sizeof(arr1[0]));
int i = 0;
for (i = 0; i<9; i++)
{
printf("%d\n", arr1[i]);
}
return 0;
}

模拟实现:
分析:

#include <stdio.h>
#include <string.h>
#include <assert.h>
void* my_memmove(void* dest,const void* src,size_t num)
{
void* ret = dest;
assert(dest&&src);
if (dest < src) //前向后
{
while (num--)
{
*(char*)dest = *(char*)src;
dest = *(char*)dest+1;
src = *(char*)src + 1;
}
}
else //后向前
{
while (num--)
{
*((char*)dest+num)=*((char*)src + num); // //根据图来分析
}
}
}
int main()
{
int arr1[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int arr2[5] = { 0 };
my_memmove(arr1 + 2, arr1, 5 * sizeof(arr1[0]));
int i = 0;
for (i = 0; i<9; i++)
{
printf("%d\n", arr1[i]);
}
return 0;
}
9.memcmp
int memcmp ( const void * ptr1, const void * ptr2, size_t num );
比较字节中数的大小
返回的是大于等于或小于0的无符号整型
使用方式与strncmp相似,但是比较的类型不局限于字符串,更加广泛
案例:
#include <stdio.h>
#include <string.h>
int main()
{
int arr1[] = { 1,2,7,4,5 };
int arr2[] = { 1,2,3,4,5 };
int ret = memcmp(arr1, arr2, 9); //比较arr1和arr2前九个字节中数的大小
printf("%d\n", ret);
return 0;
}

10.memset
void* memset(void* dest,int c,size_t count)
第一个参数是目标地址,第二个参数是要被设置的内容,第三个参数是个数
以字节为单位修改
应用方式:
#include <stdio.h>
#include <string.h>
int main()
{
char arr[20] = { 0 };
memset(arr, 'x', 10);
return 0;
}

到此这篇关于C语言详解如何应用模拟字符串和内存函数的文章就介绍到这了,更多相关C语言 字符串 内存函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C语言的字符串函数,内存函数笔记详解
目录 strlen strlen模拟实现 strcpy strcpy的模拟实现 strcat strcat的模拟实现 strcmp strcmp模拟实现 strstr strstr模拟实现 strncpy strncat strncmp strtok memcpy memcpy模拟实现 memmove memmove模拟实现 memcmp 字符分类函数 字符串换函数 总结 strlen 此函数接收一个char*类型参数,返回字符串\0前字符数,注意返回类型是size_t型的 //关于strlen
-
一篇文章带你了解C语言的一些重要字符串与内存函数
目录 一.字符串函数 1. 求字符串长度的strlen 2.比较字符串大小的strcmp 3.复制字符串的strcpy 4.追加字符串的strcat 5.查找字符串函数的strstr 二.内存函数 1.复制 memcpy,memmove 2.比较 memcmp 总结 一.字符串函数 1. 求字符串长度的strlen size_t strlen ( const char * str ); 字符串以 '\0' 作为结束标志,strlen函数返回的是在字符串中 '\0' 前面出现的字符个数(不包含 '
-
c语言重要的字符串与内存函数
目录 一.字符串函数 1. 求字符串长度的strlen 2.比较字符串大小的strcmp 3.复制字符串的strcpy 4.追加字符串的strcat 5.查找字符串函数的strstr 二.内存函数 1.复制 memcpy,memmove 2.比较 memcmp 一.字符串函数 1. 求字符串长度的strlen size_t strlen ( const char * str ); 字符串以 '\0' 作为结束标志,strlen函数返回的是在字符串中 '\0' 前面出现的字符个数(不包含 '\0'
-

C语言进阶教程之字符串&内存函数
目录 前言: 一.求字符串长度 strlen strlen函数的模拟实现 二.长度不受限制的字符串函数 strcpy strcpy函数的模拟实现 strcat strcat函数的模拟实现 strcmp strcmp函数的模拟实现 三.长度受限制的字符串函数 strncpy strncpy函数的模拟实现 strncat strncat函数的模拟实现 strncmp strncmp函数的模拟实现 四.字符串查找 strstr strstr函数的模拟实现 strtok strtok函数的模拟实现 五.
-
C语言详解如何应用模拟字符串和内存函数
目录 1.strlen 求字符串长度 使用案例: 1.计数法 2.不创建临时变量计数器-递归 3.指针-指针的方式 2.长度不受限制的字符串函数 1.strcpy 使用案例: 模拟实现: 2.strcat 使用案例: 模拟实现: 3.strcmp-比较字符串首字母的大小 使用案例: 模拟实现: 3.长度受限制的字符串函数 1.strncpy 使用案例: 2.strncat 使用案例: 3.strncmp 使用案例: 4.strstr-找子串 使用案例: 模拟实现: 5.strtok 用法:
-
C语言 详解字符串基础
目录 一.字符串的概念 二.字符数组与字符串 三.字符串字面量的秘密 四.字符串的长度 五.小结 一.字符串的概念 字符串是有序字符的集合 字符串是程序中的基本元素之一 C 语言中没有字符串的概念 C 语言中通过特殊的字符数组模拟字符串 C 语言中的字符串是以 ‘\0’ 结尾的字符数组 二.字符数组与字符串 在C语言中,双引号引用的单个或多个字符是—种特殊的字面量 存储于程序的全局只读存诸区 本质为字符数组,编译器自动在结尾加上 ‘\0' 字符 下面看一段字符数组与字符串的代码: #includ
-
C语言详解数据结构与算法中枚举和模拟及排序
目录 枚举 连号区间数 递增三元组 二分 双指针 前缀和 模拟 特别数的和 错误票据 排序 快速排序 归并排序 枚举 连号区间数 来源:第四届蓝桥杯省赛C++B组,第四届蓝桥杯省赛JAVAB组 小明这些天一直在思考这样一个奇怪而有趣的问题: 在 1∼N 的某个排列中有多少个连号区间呢? 这里所说的连号区间的定义是: 如果区间 [L,R] 里的所有元素(即此排列的第 L 个到第 R 个元素)递增排序后能得到一个长度为 R−L+1 的“连续”数列,则称这个区间连号区间. 当 N 很小的时候,小明可以
-
C语言详解Z字形变换排列的实现
目录 方法一 方法二 题目链接:Z 字形变换 方法一 ——找规律模拟数组 题目要求构造一个从左到右的Z型矩阵. 通过分析,可以看出这个Z型矩阵的特点 Z型矩阵就是如图中的橙色,绿色这样部分组合在一起的,Z型矩阵就是由一个个这样相同周期组成的. 这里有一种情况需要特殊讨论,当矩阵只有一行时,直接返回原字符. 其余情况均可满足. 其周期的构成满足这样一个规律: 在第一列向下填写矩阵行数r个字符,接着向其右上部分共(r-2)列分别填写一个字符.Z型矩阵的周期t=r+r-2=2*r-2,每个周期会占用矩
-
C语言详解strcmp函数的分析及实现
目录 1.函数介绍 1.1.函数接口 1.2.函数分析 1.3.函数的简单使用 1.4.函数使用结果分析 2.库函数strcmp源代码 2.1.库函数源代码 2.2.库函数分析 3.模拟实现 strcmp 函数 3.1.模拟实现 3.2.模拟实现分析 1.函数介绍 1.1.函数接口 int __cdecl strcmp (const char * src,const char * dst); 这里是库函数里面的函数定义接口.这个函数是将 src 和 dst 两个字符串进行比较,即为字符串比较函数
-
C语言详解实现链式二叉树的遍历与相关接口
目录 前言 一.二叉树的链式结构 二.二叉树的遍历方式 1.1 遍历方式的规则 1.2 前序遍历 1.3 中序遍历 1.4 后序遍历 1.5 层序遍历 三.二叉树的相关接口实现 3.1 二叉树节点个数 3.2 二叉树叶子节点个数 3.3 二叉树第 k 层节点个数 3.4 二叉树的深度(高度) 3.5 二叉树查找值为 x 的节点 3.6 总结 & 注意 四.二叉树的创建和销毁 4.1 通过前序遍历的字符串来构建二叉树 4.2 二叉树销毁 4.3 判断二叉树是否是完全二叉树 前言 二叉树的顺序结构就
-
详解C++中十六进制字符串转数字(数值)
详解C++中十六进制字符串转数字(数值) 主要有两个方法,其实都是对现有函数的使用: 方法1: sscanf() 函数名: sscanf 功 能: 从字符串格式化输入 用 法: int sscanf(char *string, char *format[,argument,...]); 以上的 format 为 %x 就是将字符串格式化为 16 进制数 例子: #include <stdio.h> void main() { char* p = "0x1a"; i
-
详解使用IDEA模拟git命令使用的常见场景
大家好,最近白泽第一次开始参与小组合作开发,以前都是自己用git保存自己的代码,自己维护,用git的场景也比较单一,没有遇到过拉取代码合并出现冲突的问题.但是小组开发拉取远程仓库的代码时,遇到他人所提交代码与自己的本地代码出现冲突在所难免,所以白泽特意去学习了一下git的冲突处理,接下来用一个小demo复现一下我学习的过程 前期准备 新建一个远程仓库 在一个文件夹内建立两个子文件夹作为两个本地仓库的存放位置 之所以建立两个文件夹,这样做的目的是为了模拟两个用户对同一个项目进行合作开发,假设dem
-
C语言 详解如何删除有序数组中的重复项
目录 删除有序数组中的重复项Ⅰ a.思路 b.图解 c.代码 d.思考 删除有序数组中的重复项Ⅱ a.思路 b.图解 c.代码 d.思考 删除有序数组中的重复项Ⅰ a.思路 定义变量 int dest=0,cur=1,nums[cur]与nums[dest]逐一比较. nums[cur]!=nums[dest],将nums[cur]放入dest下一个位置,更新dest. nums[cur]!=nums[dest],cur移动. cur==numsSize,结束.返回dest+1. b.图解 c.
-
C语言详解float类型在内存中的存储方式
目录 1.例子 2.浮点数存储规则 1.例子 int main() { int n = 9; float *pFloat = (float *)&n; printf("n的值为:%d\n",n); printf("*pFloat的值为:%f\n",*pFloat); *pFloat = 9.0; printf("num的值为:%d\n",n); printf("*pFloat的值为:%f\n",*pFloat); re