五种Python转义表示法
1. 为什么要有转义?
ASCII 表中一共有 128 个字符。这里面有我们非常熟悉的字母、数字、标点符号,这些都可以从我们的键盘中输出。除此之外,还有一些非常特殊的字符,这些字符,我通常很难用键盘上的找到,比如制表符、响铃这种。
为了能将那些特殊字符都能写入到字符串变量中,就规定了一个用于转义的字符 \ ,有了这个字符,你在字符串中看的字符,print 出来后就不一定你原来看到的了。
举个例子
>>> msg = "hello\013world\013hello\013python"
>>> print(msg)
hello
world
hello
python
>>>
是不是有点神奇?变成阶梯状的输出了。
那个 \013 又是什么意思呢?
\是转义符号,上面已经说过013是 ASCII 编码的八进制表示,注意前面是0且不可省略,而不是字母o
把八进制的 13 转成 10 进制后是 11
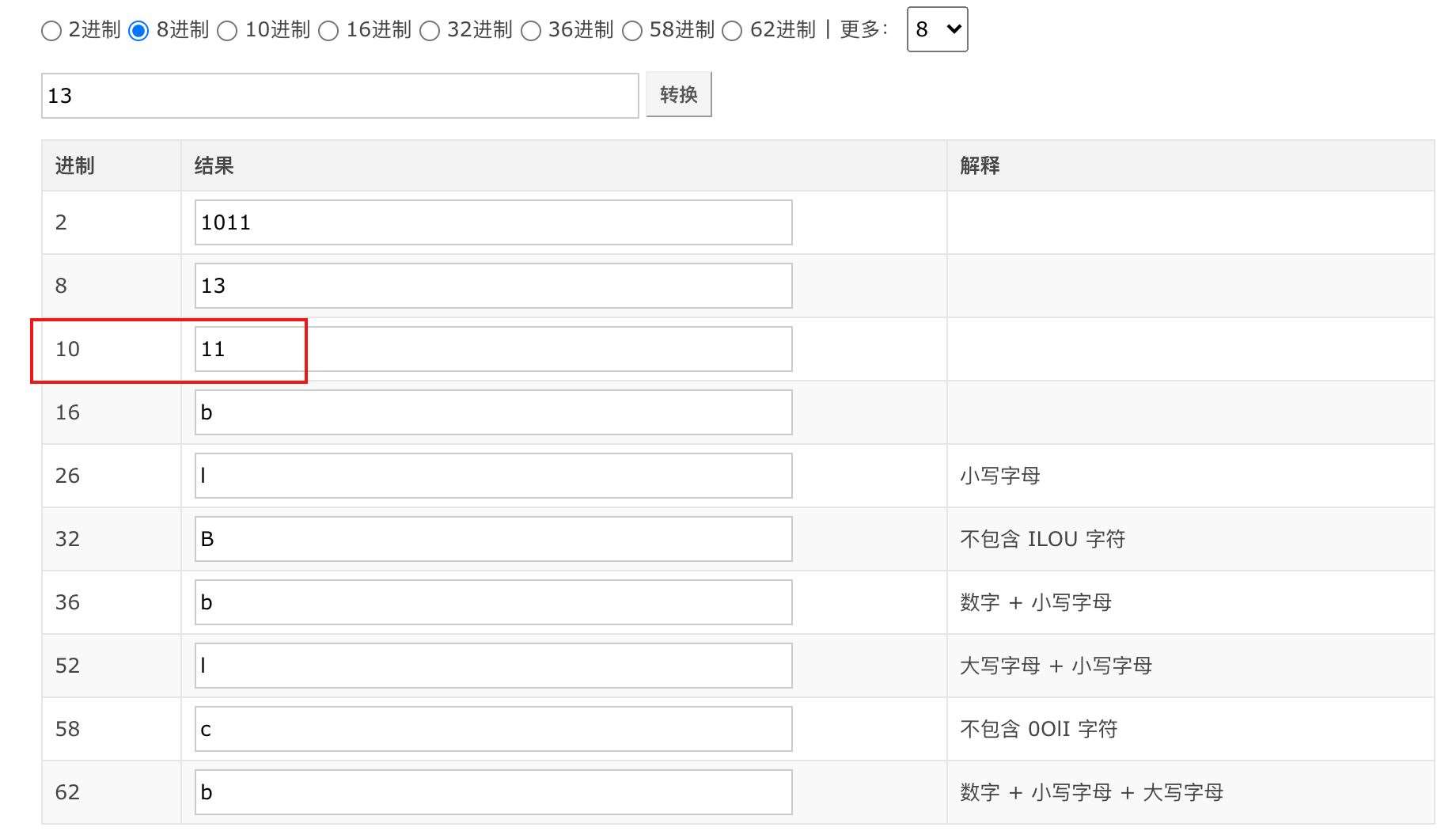
对照查看 ASCII 码表,11 对应的是一个垂直定位符号,这就能解释,为什么是阶梯状的输出字符串。

2. 转义的 5 种表示法
ASCII 有 128 个字符,如果用 八进制表示,至少得有三位数,才能将其全部表示。这就是为什么说上面的首位 0 不能省略的原因,即使现在用不上,我也得把它空出来。
而如果使用十六进制,只要两位数就其 ASCII 的字符全部表示出来。同时为了避免和八进制的混淆起来,所以在 \ 后面要加上英文字母 x 表示十六进制,后面再接两位十六进制的数值。
\开头并接三位 0-7 的数值,表示 8 进制\x开头并接两位 0-f 的数值,表示 16进制
因此,当我定义一个字符串的值为 hello + 回车 + world 时,就有了多种方法:
# 第一种方法:8进制 >>> msg = "hello\012world" >>> print(msg) hello world >>> # 第二种方法:16 进制 >>> msg = "hello\x0aworld" >>> print(msg) hello world >>>
通常我们很难记得住一个字符的 ASCII 编号,即使真记住了,也要去转换成八进制或者16进制,实在是太难了。
因此对于一些常用并且比较特殊字符,我们习惯用另一种类似别名的方式,比如使用 \n 表示换行,它与 \012 、\x0a 是等价的。
与此类似的表示法,还有如下这些
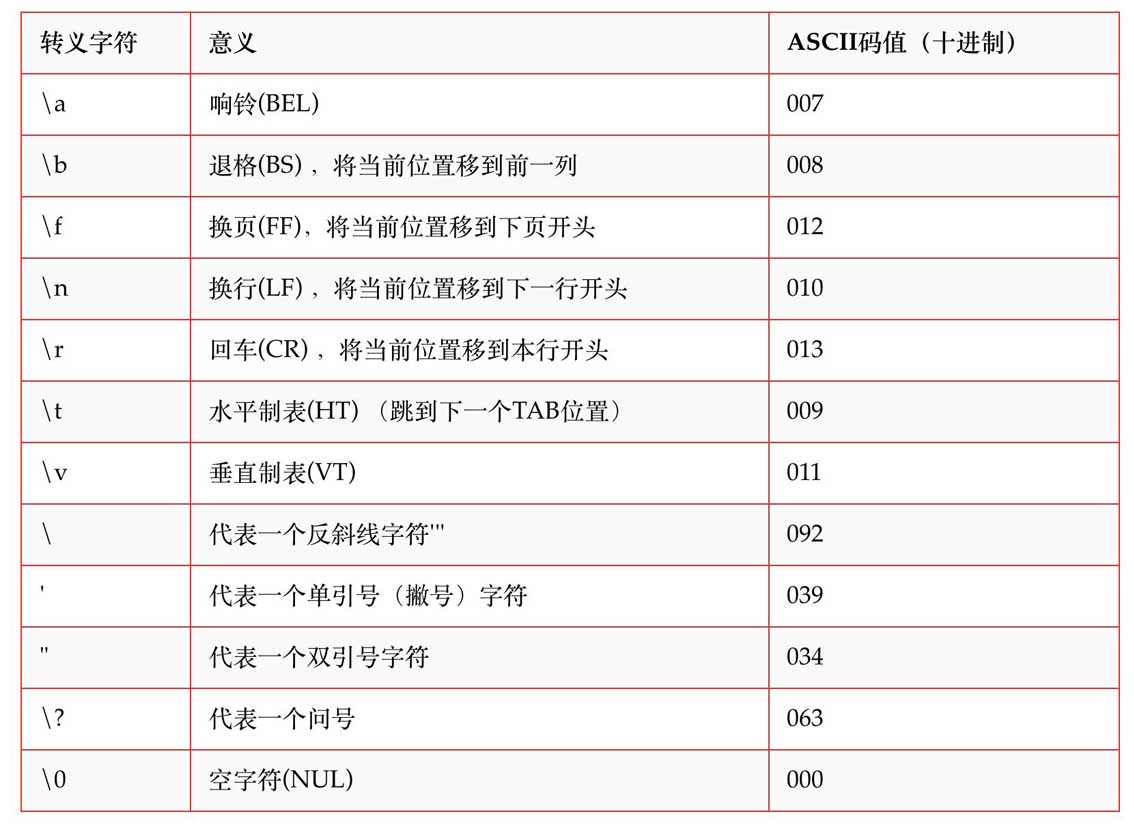
于是,要实现 hello + 回车 + world ,就有了第三种方法
# 第三种方法:使用类似别名的方法 >>> msg = "hello\nworld" >>> print(msg) hello world >>>
到目前为止,我们掌握了 三种转义的表示法。
已经非常难得了,让我们的脑洞再大一点吧,接下来再介绍两种。
ASCII 码表所能表示字符实在太有限了,想打印一个中文汉字,抱歉,你得借助 Unicode 码。
Unicode 编码由 4 个16进制数值组合而成
>>> print("\u4E2D")
中
什么?我为什么知道 中 的 unicode 是 \u4E2D?像下面这样打印就知道啦
# Python 2.7 >>> a = u"中" >>> a u'\u4e2d'
由此,要实现 hello + 回车 + world ,就有了第四种方法。
# 第四种方法:使用 unicode ,\u000a 表示换行
>>> print('hello\u000aworld')
hello
world
看到这里,你是不是以为要结束啦?
不,还没有。下面还有一种。
Unicode 编码其实还可以由 8 个32进制数值组合而成,为了以前面的区分开来,这里用 \U 开头。
# 第五种方法:使用 unicode ,\U0000000A 表示换行
>>> print('hello\U0000000Aworld')
hello
world
好啦,目前我们掌握了五种转义的表示法。
总结一下:
\开头并接三位 0-7 的数值(八进制) — 可以表示所有ASCII 字符\x开头并接两位 0-f 的数值(十六进制) — 可以表示所有ASCII 字符\u开头并接四位 0-f 的数值(十六进制) — 可以表示所有 Unicode 字符\U开头并接八位 0-f 的数值(三十二进制)) — 可以表示所有 Unicode 字符\开头后接除 x、u、U 之外的特定字符 — 仅可表示部分字符
为什么标题说,转义也可以炫技呢?
试想一下,假如你的同事,在打印日志时,使用这种 unicode 编码,然后你在定位问题的时候使用这个关键词去搜,却发现什么都搜不到?这就扑街了。

虽然这种行为真的很 sb,但在某些人看来也许是非常牛逼的操作呢?
五种转义的表示法到这里就介绍完成,接下来是更多转义相关的内容,也是非常有意思的内容,有兴趣的可以继续往下看。
3. raw 字符串
当一个字符串中具有转义的字符时,我们使用 print 打印后,正常情况下,输出的不是我们原来在字符串中看到的那样子。
那如果我们需要输出 hello\nworld ,不希望 Python 将 \n 转义成 换行符呢?
这种情况下,你可以在定义时将字符串定义成 raw 字符串,只要在字符串前面加个 r 或者 R 即可。
>>> print(r"hello\nworld") hello\nworld >>> >>> print(R"hello\nworld") hello\nworld
然而,不是所有时候都可以加 r 的,比如当你的字符串是由某个程序/函数返回给你的,而不是你自己生成的
# 假设这个是外来数据,返回 "hello\nworld" >>> body = spider() >>> print(body) hello world
这个时候打印它,\n 就是换行打印。
4. 使用 repr
对于上面那种无法使用 r 的情况,可以试一下 repr 来解决这个需求:
>>> body = repr(spider()) >>> print(body) 'hello\nworld'
经过 repr 函数的处理后,为让 print 后的结果,接近字符串本身的样子,它实际上做了两件事
- 将
\变为了\\ - 在字符串的首尾添加
'或者"
你可以在 Python Shell 下敲入 变量 回车,就可以能看出端倪。
首尾是添加 ' 还是 " ,取决于你原字符串。
>>> body="hello\nworld" >>> repr(body) "'hello\\nworld'" >>> >>> >>> body='hello\nworld' >>> repr(body) "'hello\\nworld'"
5. 使用 string_escape
如果你还在使用 Python 2 ,其实还可以使用另一种方法。
那就是使用 string.encode('string_escape') 的方法,它同样可以达到 repr 的效果
>>> "hello\nworld".encode('string_escape')
'hello\\nworld'
>>>
6. 查看原生字符串
综上,想查看原生字符串有两种方法:
- 如果你在 Python Shell 交互模式下,那么敲击变量回车
- 如果不在 Python Shell 交互模式下,可先使用
repr处理一下,再使用 print 打印
>>> body="hello\nworld" >>> >>> body 'hello\nworld' >>> >>> print(repr(body)) 'hello\nworld' >>>
7. 恢复转义:转成原字符串
经过 repr 处理过或者 \\ 取消转义过的字符串,有没有办法再回退出去,变成原先的有转义的字符串呢?
答案是:有。
如果你使用 Python 2,可以这样:
>>> body="hello\\nworld"
>>>
>>> body
'hello\\nworld'
>>>
>>> body.decode('string_escape')
'hello\nworld'
>>>
如果你使用 Python 3 ,可以这样:
>>> body="hello\\nworld"
>>>
>>> body
'hello\\nworld'
>>>
>>> bytes(body, "utf-8").decode("unicode_escape")
'hello\nworld'
>>>
什么?还要区分 Python 2 和 Python 3?太麻烦了吧。
明哥教你用一种可以兼容 Python 2 和 Python 3 的写法。
首先是在 Python 2 中的输出
>>> import codecs >>> body="hello\\nworld" >>> >>> codecs.decode(body, 'unicode_escape') u'hello\nworld' >>>
然后再看看 Python 3 中的输出
>>> import codecs >>> body="hello\\nworld" >>> >>> codecs.decode(body, 'unicode_escape') 'hello\nworld' >>>
可以看到 Pyhton 2 中的输出 有一个 u ,而 Python 3 的输出没有了 u,但无论如何 ,他们都取消了转义。
到此这篇关于五种Python转义表示法的文章就介绍到这了,更多相关Python转义内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
一篇文章搞懂python的转义字符及用法
什么是转义字符 转义字符是一个计算机专业词汇.在计算机当中,我们可以写出123 ,也可以写出字母abcd,但有些字符我们无法手动书写,比如我们需要对字符进行换行处理,但不能写出来换行符,当然我们也看不见换行符.像这种情况,我们需要在字符中使用特殊字符时,就需要用到转义字符,在python里用反斜杠\转义字符. 在交互式解释器中,输出的字符串用引号引起来,特殊字符用反斜杠\转义.虽然可能和输入看上去不太一样,但是两个字符串是相等的. 在python里,转义字符\可以转义很多字符,比如\n表示换行,
-
Python 正则表达式(转义问题)
先说一个比较囧的事情:在写虾米音乐试听下载器的时候遇到一个问题,因为保存的文件都是用音乐的标题命名的,所以碰到一些诸如「対峙/out border」等含有非法字符(哼哼,说的就是你 →_→ Windows)的标题的时候,就会保存失败.于是我想起了迅雷的解决方法:把所有的非法字符替换成下划线. 于是就引入了正则表达式的使用.一番搜索囫囵吞枣后,我写下了这样的函数: 复制代码 代码如下: def sanitize_filename(filename): return re.sub('[\/:*?<>
-
Python文件读取的3种方法及路径转义
1.文件的读取和显示 方法1: 复制代码 代码如下: f=open(r'G:\2.txt') print f.read() f.close() 方法2: 复制代码 代码如下: try: t=open(r'G:\2.txt') print t.read() finally: if t: t.close() 方法3: 复制代码 代码如下: with open(r'g:\2.txt') as g: for line in g:
-
Python 转义字符详细介绍
Python 转义字符 在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符.如下表: 原始字符串 有时我们并不想让转义字符生效,我们只想显示字符串原来的意思,这就要用r和R来定义原始字符串.如: print r'\t\r' 实际输出为 "\t\r" 转义字符 描述 \(在行尾时) 续行符 \\ 反斜杠符号 \' 单引号 \" 双引号 \a 响铃 \b 退格(Backspace) \e 转义 \000 空 \n 换行 \v 纵向制表符 \t 横向制表符 \r 回车
-
详解用Python处理HTML转义字符的5种方式
写爬虫是一个发送请求,提取数据,清洗数据,存储数据的过程.在这个过程中,不同的数据源返回的数据格式各不相同,有 JSON 格式,有 XML 文档,不过大部分还是 HTML 文档,HTML 经常会混杂有转移字符,这些字符我们需要把它转义成真正的字符. 什么是转义字符 在 HTML 中 <.>.& 等字符有特殊含义(<,> 用于标签中,& 用于转义),他们不能在 HTML 代码中直接使用,如果要在网页中显示这些符号,就需要使用 HTML 的转义字符串(Escape Se
-
详解Python中的各种转义符\n\r\t
Python中的各种转义符\n\r\t 转义符 描述 \ 续行符(在行尾时) \\ 反斜杠符号 ' 单引号 " 双引号 \a 响铃 \b 退格(Backspace) \e 转义 \000 空 \n 换行 \v 纵向制表符 \t 横向制表符 \r 回车 \f 换页 \oyy 八进制数yy代表的字符,例如:\o12代表换行 \xyy 十进制数yy代表的字符,例如:\x0a代表换行 \other 其它的字符以普通格式输出 Python中的正斜杠与反斜杠 首先,"/"左倾斜是正斜杠,
-

Python对HTML转义字符进行反转义的实现方法
什么是转义字符 在 HTML 中 <.>.& 等字符有特殊含义(<,> 用于标签中,& 用于转义),他们不能在 HTML 代码中直接使用,如果要在网页中显示这些符号,就需要使用 HTML 的转义字符串(Escape Sequence),例如 < 的转义字符是 <,浏览器渲染 HTML 页面时,会自动把转移字符串换成真实字符. 转义字符(Escape Sequence)由三部分组成:第一部分是一个 & 符号,第二部分是实体(Entity)名字,第三
-
python处理html转义字符的方法详解
本文实例讲述了python处理html转义字符的方法.分享给大家供大家参考,具体如下: 最近在用Python处理网页数据时,经常遇到一些html转义字符(也叫html字符实体),例如<> 等.字符实体一般是为了表示网页中的预留字符,比如>用>表示,防止被浏览器认为是标签,具体参考w3school的HTML 字符实体.虽然很有用,但是它们会极度影响对于网页数据的解析.为了处理这些转义字符,有如下解决方案: 1.使用HTMLParser处理 import HTMLParser html
-
五种Python转义表示法
1. 为什么要有转义? ASCII 表中一共有 128 个字符.这里面有我们非常熟悉的字母.数字.标点符号,这些都可以从我们的键盘中输出.除此之外,还有一些非常特殊的字符,这些字符,我通常很难用键盘上的找到,比如制表符.响铃这种. 为了能将那些特殊字符都能写入到字符串变量中,就规定了一个用于转义的字符 \ ,有了这个字符,你在字符串中看的字符,print 出来后就不一定你原来看到的了. 举个例子 >>> msg = "hello\013world\013hello\013pyt
-
Python中隐藏的五种实用技巧分享
目录 1. ... 对象 2.解压迭代对象 3.展开的艺术 4.下划线 _ 变量 5.多种用途的else 循环 异常处理 1. ... 对象 没错,你没看错,就是 "..." 在Python中 ... 代表着一个名为 Ellipsis 的对象.根据官方说明,它是一个特殊值,通常可以作为空函数的占位符,或是用于Numpy中的切片操作. 如: def my_awesome_function(): ... 等同于: def my_awesome_function(): Ell
-
Python实现求解最大公约数的五种方法总结
目录 方法一:短除法 方法二:欧几里得算法(辗转相除法) 方法三:更相减损术 方法四:穷举法(枚举法) 方法五:Stein算法 求最大公约数是习题中比较常见的类型,下面小编会给大家提供五种比较常见的算法,记得帮忙点个赞哦! 一般来说,最大公约数的求法大概有5种 方法一:短除法 短除法是求最大公因数的一种方法,也可用来求最小公倍数.求几个数最大公因数的方法,开始时用观察比较的方法,即:先把每个数的因数找出来,然后再找出公因数,最后在公因数中找出最大公因数.后来,使用分解质因数法来分别分解两个数的因
-
Python实现将内容写入文件的五种方法总结
目录 一.write()方法 二.writelines() 方法 三.print() 函数 四.使用 csv 模块 五.使用 json 模块 一.write()方法 使用 write() 方法:使用 open() 函数打开文件,然后使用 write() 方法将内容写入文件.例如: with open('example.txt', 'w') as f: f.write('Hello, world!') open() 函数是 Python 内置的用于打开文件的函数,其常用的参数及其含义如下: 1.f
-
python中的五种异常处理机制介绍
从几年前开始学习编程直到现在,一直对程序中的异常处理怀有恐惧和排斥心理.之所以这样,是因为不了解.这次攻python,首先把自己最畏惧和最不熟悉的几块内容列出来,里面就有「异常处理」这一项. <Dive into Python>并没有专门介绍异常处理,只是例子中用到的时候略微说明了一下.今天下载<Learn Python>,直接进异常处理这块.这一部分有四章,第一章讲解异常处理的一般使用方法,后面的章节深入地讨论其机制.我目前只看了第一章,先学会用,以后有必要的时候再扩展阅读. p
-
详解python解压压缩包的五种方法
这里讨论使用Python解压例如以下五种压缩文件: .gz .tar .tgz .zip .rar 简单介绍 gz: 即gzip.通常仅仅能压缩一个文件.与tar结合起来就能够实现先打包,再压缩. tar: linux系统下的打包工具.仅仅打包.不压缩 tgz:即tar.gz.先用tar打包,然后再用gz压缩得到的文件 zip: 不同于gzip.尽管使用相似的算法,能够打包压缩多个文件.只是分别压缩文件.压缩率低于tar. rar:打包压缩文件.最初用于DOS,基于window操作系统. 压缩
-
python中调试或排错的五种方法示例
前言 本文主要给大家介绍了关于python中调试或排错的五种方法,分享出来供大家参考学习,下面话不多说了,来一起看看详细的的介绍吧 python调试或排错的五种方法 1.print,直接打印,比较简单而且粗暴 在代码中直接输入print+需要输出的结果,根据打印的内容判断即可 2.assert断言,很方便,测试人员常常在写自动化用例的时候用的比较多 如下,直接将预期结果和实际结果做判断 def true_code(): x = 3 y = 2 z = x + y assert(5==z), "z
-
对python中list的五种查找方法说明
Python中是有查找功能的,五种方式:in.not in.count.index,find 前两种方法是保留字,后两种方式是列表的方法. 下面以a_list = ['a','b','c','hello'],为例作介绍: string类型的话可用find方法去查找字符串位置: a_list.find('a') 如果找到则返回第一个匹配的位置,如果没找到则返回-1,而如果通过index方法去查找的话,没找到的话会报错. 补充知识:Python中查找包含它的列表元素的索引,index报错!!! 对于
-
Python 字符串去除空格的五种方法
在处理Python代码字符串的时候,我们常会遇到要去除空格的情况,所以就总结了多种方法供大家参考. 1.strip()方法 去除字符串开头或者结尾的空格 str = " Hello world " str.strip() 输出: "Hello world" 2.lstrip()方法 去除字符串开头的空格 str = " Hello world " str.lstrip() 输出: 'Hello world ' 3.rstrip()方法 去除字符串
-
Python中移除List重复项的五种方法
本文列些处几种去除在Python 列表中(list)可能存在的重复项,这在很多应用程序中都会遇到的需求,作为程序员最好了解其中的几种方法 以备在用到时能够写出有效的程序. 方法1:朴素方法 这种方式是在遍历整个list的基础上,将第一个出现的元素添加在新的列表中. 示例代码: # Python 3 code to demonstrate # removing duplicated from list # using naive methods # initializing list test_l